







source :
数据库基础
1.关系型数据库和非关系型数据库的区别 ?
source : Sql Or NoSql,看完这一篇你就懂了 - 五月的仓颉 - 博客园
source2: 关系型数据库与非关系型数据库区别 - 灬菜鸟灬 - 博客园
关系型数据库: 适合处理一般量级的数据. (Mysql 和 Oracle)
- 表&表 ; 表&字段 ; 数据&数据 之间存在着关系.
- 优点: 数据之间有关系, 增删改查方便 ; 且关系型数据库是有事务操作的(ACID), 保证了数据的完整性和一致性.
- 缺点: 数据量大时操作效率低, 增删改查慢, 维护困难.
非关系型数据库: 处理海量数据, 出发点是为了代替关系型数据库 (Redis 和 MangoDB)
- 优点 : 易扩展, 数据间没有联系; 对于海量数据的处理比较有优势; 可用性高
- 缺点 : 数据间没有关系, 单独存在; 且没有事务关系, 无法保证数据的完整性和安全性. 且不具备分词功能.
Nosql : 非关系型数据库 Not only sql
Nosql 数据库四大分类 :
- 键值对存储 : (key-value)形式, Redis 键值存储, 优 : 适合结构查询; 缺 :存储缺少结构化
- 列存储 : (Hbase). 优 :快速查询,扩展性强 ; 缺 : 功能局限
- 文档数据存储 : MongoDB. 优 : 要求不严格, 缺 :查询效率不高
- 图形数据库存储 : 应用于社交网络, 优 : 有图型结构相关算法, 缺 : 需要整个图计算结果,不容易做分布式集群方案
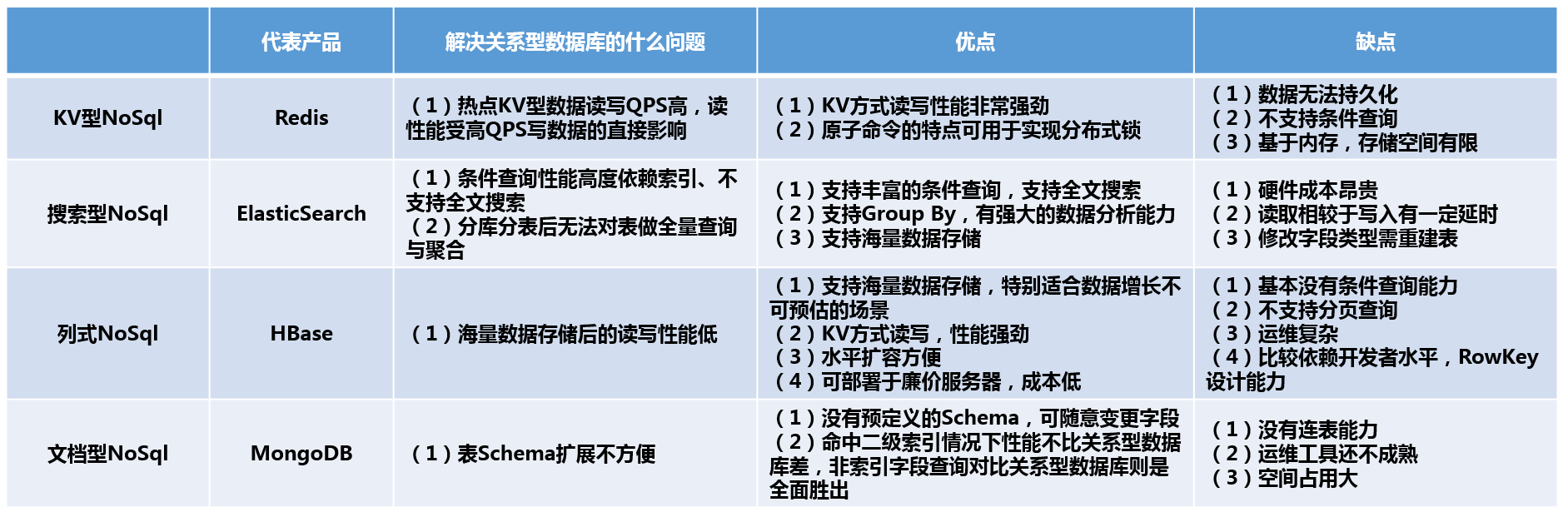
1. KV型NoSql(代表----Redis)
KV型NoSql顾名思义就是 以键值对形式存储的非关系型数据库。Redis、MemCache是其中的代表,Redis又是KV型NoSql中应用最广泛的NoSql,KV型数据库以Redis为例,最大的优点我总结下来就两点:
- 数据基于内存,读写效率高
- KV型数据,时间复杂度为O(1),查询速度快
因此,KV型NoSql最大的优点就是高性能,利用Redis自带的BenchMark做基准测试,TPS可达到10万的级别,性能非常强劲。同样的Redis也有所有KV型NoSql都有的比较明显的缺点:
- 只能根据K查V,无法根据V查K
- 查询方式单一,只有KV的方式,不支持条件查询,多条件查询唯一的做法就是数据冗余,但这会极大的浪费存储空间
- 内存是有限的,无法支持海量数据存储
- 同样的,由于KV型NoSql的存储是基于内存的,会有丢失数据的风险
综上所述,KV型NoSql最合适的场景就是缓存的场景:
- 读远多于写
- 读取能力强
- 没有持久化的需求,可以容忍数据丢失,反正丢了再查询一把写入就是了
例如根据用户id查询用户信息,每次根据用户id去缓存中查询一把,查到数据直接返回,查不到去关系型数据库里面根据id查询一把数据写到缓存中去。
2. 搜索型NoSql(代表--ElasticSearch )
它的优点为:
- 支持分词场景、全文搜索,这是区别于关系型数据库最大特点
- 支持条件查询,支持聚合操作,类似关系型数据库的Group By,但是功能更加强大,适合做数据分析
- 数据写文件无丢失风险,在集群环境下可以方便横向扩展,可承载PB级别的数据
- 高可用,自动发现新的或者失败的节点,重组和重新平衡数据,确保数据是安全和可访问的
同样,ElasticSearch也有比较明显的缺点:
性能全靠内存来顶,也是使用的时候最需要注意的点,非常吃硬件资源、吃内存,大数据量下64G + SSD基本是标配,算得上是数据库中的爱马仕了。至于ElasticSearch内存用在什么地方,大概有如下这些:
- Indexing Buffer----ElasticSearch基于Luence,Lucene的倒排索引是先在内存里生成,然后定期以Segment File的方式刷磁盘的,每个Segment File实际就是一个完整的倒排索引
- Segment Memory----倒排索引前面说过是基于关键字的,Lucene在4.0后会将所有关键字以FST这种数据结构的方式将所有关键字在启动的时候全量加载到内存,加快查询速度,官方建议至少留系统一半内存给Lucene
- 各类缓存----Filter Cache、Field Cache、Indexing Cache等,用于提升查询分析性能,例如Filter Cache用于缓存使用过的Filter的结果集
- Cluter State Buffer----ElasticSearch被设计为每个Node都可以响应用户请求,因此每个Node的内存中都包含有一份集群状态的拷贝,一个规模很大的集群这个状态信息可能会非常大
- 读写之间有延迟,写入的数据差不多1s样子会被读取到,这也正常,写入的时候自动加入这么多索引肯定影响性能
- 数据结构灵活性不高,ElasticSearch这个东西,字段一旦建立就没法修改类型了,假如建立的数据表某个字段没有加全文索引,想加上,那么只能把整个表删了再重建
因此,搜索型NoSql最适用的场景就是有条件搜索尤其是全文搜索的场景,作为关系型数据库的一种替代方案。
3. 文档型NoSql(代表----MongoDB)
文档型NoSql的出现是解决关系型数据库表结构扩展不方便的问题的。
因此,对于MongDB,我们只要理解成一个Free-Schema的关系型数据库就完事了,它的优缺点比较一目了然,优点:
- 没有预定义的字段,扩展字段容易
- 相较于关系型数据库,读写性能优越,命中二级索引的查询不会比关系型数据库慢,对于非索引字段的查询则是全面胜出
缺点在于:
- 不支持事务操作,虽然Mongodb4.0之后宣称支持事务,但是效果待观测
- 多表之间的关联查询不支持(虽然有嵌入文档的方式),join查询还是需要多次操作
- 空间占用较大,这个是MongDB的设计问题,空间预分配机制 + 删除数据后空间不释放,只有用db.repairDatabase()去修复才能释放
- 目前没发现MongoDB有关系型数据库例如MySql的Navicat这种成熟的运维工具
总之,MongoDB的使用场景很大程度上可以对标关系型数据库,但是比较适合处理那些没有join、没有强一致性要求且表Schema会常变化的数据。
4. Memcache 与 Redis 的区别都有哪些?
| Memcache | Redis | |
| 存储方式 | Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 | Redis有部份存在硬盘上,这样能保证数据的持久性。 |
| value大小 | memcache只有1MB | redis最大可以达到1GB |
| 支持数据类型 | Memcache对数据类型支持相对简单:文本+二进制类型 | Redis有复杂的数据类型:String List Hash Set ZSet. |
| 持久化支持 | 无持久化机制 | Redis有 RDB 和 AOF 持久化机制 |
| 查询【操作】类型 | Memecache : 1.常用的CRUD 2. 少量的其他命令 | Redis : 1. 批量操作 2. 事务支持 3. 每个类型不同的CRUD |
| 使用底层模型不同 |
(6)它们之间 底层实现方式 、与客户端之间通信的应用协议 不一样。
Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。

5. 数据库与NoSql及各种NoSql间的对比
本文归根到底是两个话题:
- 何时选用关系型数据库,何时选用非关系型数据库
- 选用非关系型数据库,使用哪种非关系型数据库
首先是第一个话题,关系型数据库与非关系型数据库的选择,在我理解里面无非就是两点考虑:
第一点,不多解释应该都理解,非关系型数据库都是通过牺牲了ACID特性来获取更高的性能的,假设两张表之间有比较强的一致性需求,那么这类数据是不适合放在非关系型数据库中的。
第二点,核心数据不走非关系型数据库,例如用户表、订单表,但是这有一个前提,就是这一类核心数据会有多种查询模式,例如用户表有ABCD四个字段,可能根据AB查,可能根据AC查,可能根据D查,假设核心数据,但是就是个KV形式,比如用户的聊天记录,那么HBase一存就完事了。
这几年的工作经验来看,非核心数据尤其是日志、流水一类中间数据千万不要写在关系型数据库中,这一类数据通常有两个特点:
- 写远高于读
- 写入量巨大
一旦使用关系型数据库作为存储引擎,将大大降低关系型数据库的能力,正常读写QPS不高的核心服务会受这一类数据读写的拖累。
接着是第二个问题,如果我们使用非关系型数据库作为存储引擎,那么如何选型?其实上面的文章基本都写了,这里只是做一个总结(所有的缺点都不会体现事务这个点,因为这是所有NoSql相比关系型数据库共有的一个问题):
常用的SQL 语句
通常把表的“列”称为字段(Field),把表的“行”称为记录(Record)
1. 增加字段 语句
source : MySQL数据表添加字段(三种方式)
使用ALTER TABLE向MySQL数据库的表中添加字段,
1. 在末尾添加字段
ALTER TABLE <表名> ADD <新字段名><数据类型>[约束条件];2. 在开头添加字段
ALTER TABLE <表名> ADD <新字段名> <数据类型> [约束条件] FIRST;3. 在中间位置添加字段
#向buildBaseInfo中添加字段
alter table 表名 ADD column 字段名 VARCHAR(100) default NULL comment '新加字段'
after old_column;
语句内容:
table_name :表名;
column_name:需要添加的字段名;
VARCHAR(100):字段类型为varchar,长度100;
DEFAULT NULL:默认值NULL;
AFTER old_column:新增字段添加在old_column字段后面。实际问题中的一个注意事项:
尝试使用date_format(create_time,‘yyyy-MM-dd’)在mysql中查出结果导致create_time被格式化成字符串’yyyy-MM-dd’但是在hive中查询没有问题,而date_format(create_time,’%Y-%m-%d’)在mysql中查询没有问题,在hive会报错。
Hive中查询
select * from test where date_format(create_time,'yyyy-MM-dd') = '2020-11-04' ;
Mysql查询
select * from test where date_format(create_time,'%Y-%m-%d') = '2020-11-04' ;
MySQL删除表
总结:
-
希望删除表结构时,用 drop;
-
希望保留表结构,但要删除所有记录时, 用 truncate;
-
希望保留表结构,但要删除部分记录时, 用 delete
drop table 是直接删除表信息,速度最快,但是无法找回数据;
例如删除 user 表:drop table user;
truncate (table) 是删除表数据,不删除表的结构,速度排第二,但不能与where一起使用;
例如删除 user 表:truncate table user;
delete from 是删除表中的数据,不删除表结构,速度最慢,但可以与where连用,可以删除指定的行;
例如删除user表的所有数据 delete from user;
删除user表的指定记录 delete from user where user_id = 1;
sql字段去重
- distinct
- group by
- row_number() over()
distinct方法
ditinct方法适合于单字段去重,但是单字段去重还要保留其他字段数据,就无法完成了;
distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的;
distinct应用到多个字段的时候,distinct必须放在开头,其应用的范围是其后面的所有字段
group by 方法
- 对group by 后面所有字段去重,并不能只对一列去重;
- sql语句写成只对一列去重,保留其他字段,在hive上会报错
row_number() over()(该方法是hive sql去重的最佳方法)
group by 和distinct 的区别:
其实二者没有什么可比性,但是对于不包含聚集函数的GROUP BY操作来说,和DISTINCT操作是等价的。不过虽然二者的结果是一样的,但是二者的执行计划并不相同。
distinct只是将重复的行从结果中出去; 把不同的记录显示出来。
group by是在查询时先把纪录按照类别分出来再查询。指定的列分组,一般这时在select中会用到聚合函数。group by 必须在查询结果中包含一个聚集函数,而distinct不用。














 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









