







MySQL索引B+Tree优化实战
环境说明
Centos版本: CentOS Linux release 7.7.1908 (Core)
Linux连接工具:SecureCRT
MySQL Version: 5.7.28
MySQL连接工具:Navicate
- 知识扩展
Mysql中的UTF8是0-3个字节,Java中的UTF8是0-4个字节 ,在MySQL中设置字符集UTF8mb4才是0-4个字节
在MySQL4.0版本一下varchar代表的是字节
在MySQL4.0版本之后varchar代表的是字符
思考:
char(10)能存储多少个中文?多少个英文?
varchar(10)能存储多少个中文?多少个英文?
参考文档:https://dev.mysql.com/doc/refman/5.7/en/char.html
索引概念
- 索引是什么?
索引是帮助MySQL高效获取数据的数据结构!
官方解释:索引用于快速查找具有特定列值的行。没有索引,MySQL必须从第一行
开始,然后通 读整个表以找到相关的行。表越大,花费时间越长。如果表中有相关
列的索 引 MySQL可以快速确定要在数据文件中间查找的位置,而不必查看所有
数据。这比顺序读取每一行要快得多。
- 索引能干什么?
高数据查询的效率。
索引会影响where后面 的查找和order by 后面的排序。
索引的种类
- 存储结构上来划分索引:
BTree索引(B-Tree或B+Tree索引)
Hash索引
full-index全文索引
R-Tree索引
- 从应用层次来分:
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
- 根据中数据的物理顺序与键值的逻辑(索引)顺序关系:
非聚簇索引:不是聚簇索引,就是非聚簇索引
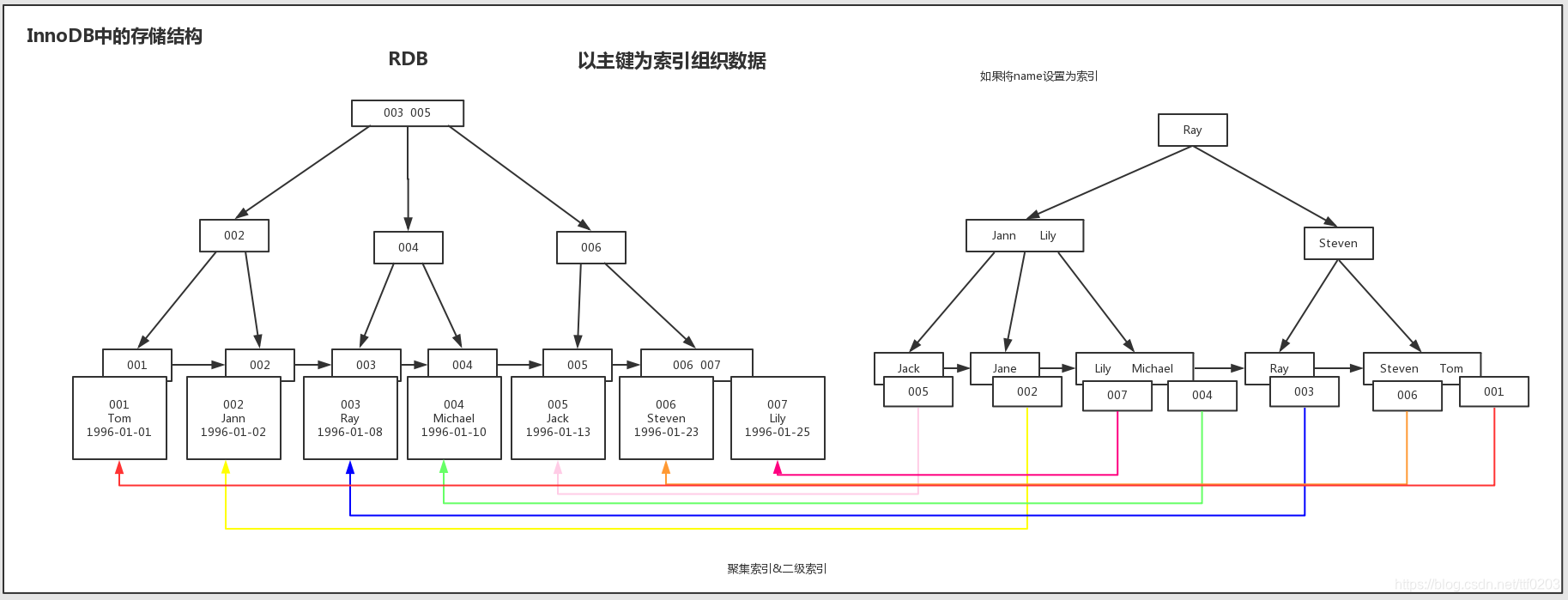
聚簇索引:并不是一种单独的索引类型,而是一种数据存储方式。
聚簇索引的特点:
- 按主键值的大小进行记录和页的排序:数据页(叶子节点)里的记录是按照主键值从小到大排序的一个单向链表。
数据页(叶子节点)之间也是是按照主键值从小到大排序的一个双向链表。
B+树中同一个层的页目录也是按照主键值从小到大排序的一个双向链表。- B+树的叶子节点存储的是完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
具有这两种特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引
并不需要我们在MySQL语句中显式的使用INDEX语句去创建。InnoDB存储引擎会自动的为我们创建聚簇索引。
在InnoDB存储引擎中,聚簇索引就是数据的存储方式(所有的用户记录都存储在了叶子节点),也就是所谓的索
引即数据,数据即索引。
- 全文索引
全文索引:只有在MyISAM引擎上才能使用,只能在
CHAR,VARCHAR,TEXT类型字段上使用全文索引,
全文索引,就是在一堆文字中,通过其中的某个关键字等,
就能找到该字段所属的记录行,比如有 “你是个靓仔,靓女
…” 通过靓仔,可能就可以找到该条 记录。这里说的是可
能,因为全文索引的使用涉及了很多细节,我们只需要知
道这个大概意思就可以了。
知识扩展:B-Tree和B+Tree的区别
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,
数据分布在各个节点之中
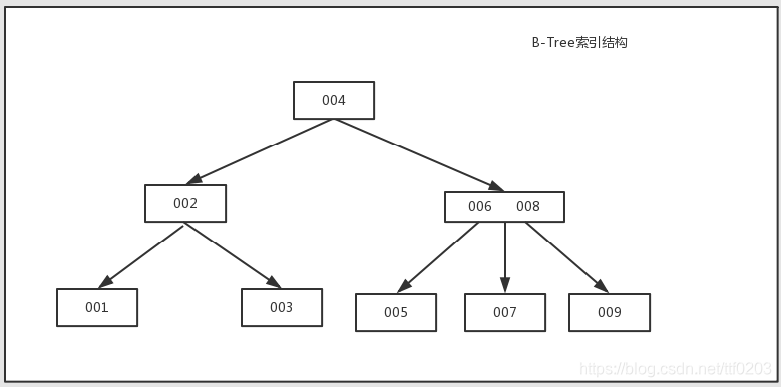
B+Tree是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子
节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。
相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree
需要获取所有节点,相比之下B+Tree效率更高。
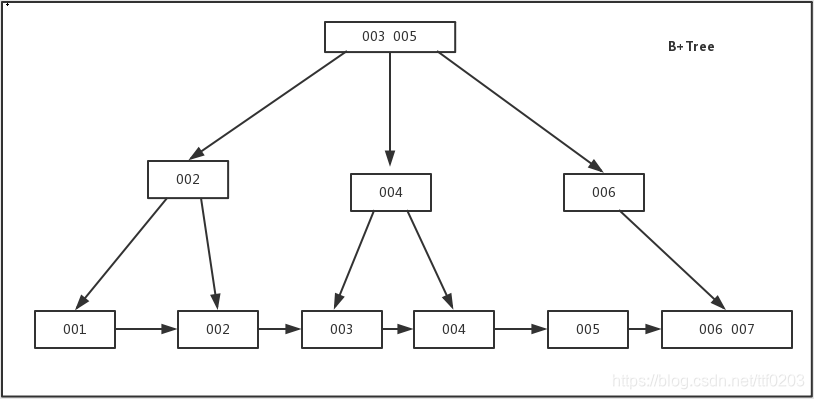
索引在InnoDB中的实现方式
索引的操作
- 索引的命名规约
主键索引名为 pk_字段名;
唯一索引名为 uk_字段名;
普通索引名则为 idx_字段名。
说明:
pk_ 即 primary key;
uk_ 即 unique key;
idx_ 即 index 的简称
- 初始化数据库命令
--创建订单表:tb_order
DROP TABLE IF EXISTS `tb_order`;
CREATE TABLE `tb_order` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT,
`order_no` varchar(50) DEFAULT NULL,
`user_id` bigint(20) DEFAULT NULL,
`order_settlement_status` int(11) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
`order_no2` varchar(200) DEFAULT NULL,
`order_no3` varchar(200) DEFAULT NULL,
PRIMARY KEY (`order_id`),
KEY `idx_order_no_2_3` (`order_no`,`order_no2`,`order_no3`),
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10000001 DEFAULT CHARSET=utf8;
--创建用户表:tb_user
DROP TABLE IF EXISTS `tb_user`;
CREATE TABLE `tb_user` (
`user_id` int(11) NOT NULL AUTO_INCREMENT,
`user_name` varchar(50) DEFAULT NULL,
`register_date` datetime DEFAULT NULL,
`test_char_length` char(10) DEFAULT NULL,
`test_varchar_length` varchar(10) DEFAULT NULL,
PRIMARY KEY (`user_id`),
KEY `INDEX_USER_NAME` (`user_name`)
) ENGINE=InnoDB AUTO_INCREMENT=150001 DEFAULT CHARSET=utf8;
--创建生成用户数据的存储过程:pro_gen_user_datas
DROP PROCEDURE IF EXISTS `pro_gen_user_datas`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` PROCEDURE `pro_gen_user_datas`()
BEGIN
#用户姓名
DECLARE new_user_name VARCHAR(50) ;
#循环次数
DECLARE v_cnt DECIMAL (10) DEFAULT 0;
cnt_loop:LOOP
SET new_user_name = fun_gen_name();
INSERT INTO tb_user(user_name,register_date) VALUES ( new_user_name,NOW());
COMMIT;
SET v_cnt = v_cnt+1;
IF v_cnt = 150000 THEN
LEAVE cnt_loop;
END IF;
END LOOP cnt_loop ;
END
;;
DELIMITER ;
--创建生成订单数据的存储过程:pro_gen_order_datas
DROP PROCEDURE IF EXISTS `pro_gen_order_datas`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` PROCEDURE `pro_gen_order_datas`()
BEGIN
#状态取余
DECLARE new_order_settlement_status INTEGER;
#计算用户ID
DECLARE new_user_id INTEGER ;
#短UUID
DECLARE new_uuid BIGINT ;
#循环次数
DECLARE v_cnt DECIMAL (10) DEFAULT 0;
cnt_loop:LOOP
SET new_uuid = UUID_SHORT();
SET new_order_settlement_status = new_uuid % 4;
SET new_user_id = new_uuid % 100000;
INSERT INTO tb_order(order_no,user_id,create_date,order_settlement_status) VALUES ( new_uuid,new_user_id , NOW(),new_order_settlement_status);
COMMIT;
SET v_cnt = v_cnt+1;
IF v_cnt = 10000000 THEN
LEAVE cnt_loop;
END IF;
END LOOP cnt_loop ;
END
;;
DELIMITER ;
-- 创建随机生成姓名的方法:fun_gen_name
DROP FUNCTION IF EXISTS `fun_gen_name`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` FUNCTION `fun_gen_name`() RETURNS varchar(50) CHARSET utf8
BEGIN
DECLARE xing VARCHAR(2056) ;
DECLARE ming VARCHAR(2056) ;
# 这里的长度不是字符串的字数,而是此字符串的占的容量大小,一个汉字占3个字节
DECLARE l_xing INTEGER;
DECLARE l_ming INTEGER;
DECLARE return_str VARCHAR(255) DEFAULT '';
SET xing = '赵钱孙李周郑王冯陈楮卫蒋沈韩杨朱秦尤许何吕施张孔曹严华金魏陶姜戚谢喻柏水窦章云苏潘葛奚范彭郎鲁韦昌马苗凤花方俞任袁柳酆鲍史唐费廉岑薛雷贺倪汤滕殷罗毕郝邬安常乐于时傅皮齐康伍余元卜顾孟平黄和穆萧尹姚邵湛汪祁毛禹狄米贝明臧计伏成戴谈宋茅庞熊纪舒屈项祝董梁杜阮蓝闽席季麻强贾路娄危江童颜郭梅盛林刁锺徐丘骆高夏蔡田樊胡凌霍虞万支柯昝管卢莫经裘缪干解应宗丁宣贲邓郁单杭洪包诸左石崔吉钮龚程嵇邢滑裴陆荣翁';
SET ming = '嘉懿煜城懿轩烨伟苑博伟泽熠彤鸿煊博涛烨霖烨华煜祺智宸正豪昊然明杰诚立轩立辉峻熙弘文熠彤鸿煊烨霖哲瀚鑫鹏致远俊驰雨泽烨磊晟睿天佑文昊修洁黎昕远航旭尧鸿涛伟祺轩越泽浩宇瑾瑜皓轩擎苍擎宇志泽睿渊楷瑞轩弘文哲瀚雨泽鑫磊梦琪忆之桃慕青问兰尔岚元香初夏沛菡傲珊曼文乐菱痴珊恨玉惜文香寒新柔语蓉海安夜蓉涵柏水桃醉蓝春儿语琴从彤傲晴语兰又菱碧彤元霜怜梦紫寒妙彤曼易南莲紫翠雨寒易烟如萱若南寻真晓亦向珊慕灵以蕊寻雁映易雪柳孤岚笑霜海云凝天沛珊寒云冰旋宛儿绿真盼儿晓霜碧凡夏菡曼香若烟半梦雅绿冰蓝灵槐平安书翠翠风香巧代云梦曼幼翠友巧听寒梦柏醉易访旋亦玉凌萱访卉怀亦笑蓝春翠靖柏夜蕾冰夏梦松书雪乐枫念薇靖雁寻春恨山从寒忆香觅波静曼凡旋以亦念露芷蕾千兰新波代真新蕾雁玉冷卉紫山千琴恨天傲芙盼山怀蝶冰兰山柏翠萱乐丹翠柔谷山之瑶冰露尔珍谷雪乐萱涵菡海莲傲蕾青槐冬儿易梦惜雪宛海之柔夏青亦瑶妙菡春竹修杰伟诚建辉晋鹏天磊绍辉泽洋明轩健柏煊昊强伟宸博超君浩子骞明辉鹏涛炎彬鹤轩越彬风华靖琪明诚高格光华国源宇晗昱涵润翰飞翰海昊乾浩博和安弘博鸿朗华奥华灿嘉慕坚秉建明金鑫锦程瑾瑜鹏经赋景同靖琪君昊俊明季同开济凯安康成乐语力勤良哲理群茂彦敏博明达朋义彭泽鹏举濮存溥心璞瑜浦泽奇邃祥荣轩';
SET l_xing = LENGTH(xing) / 3;
SET l_ming = LENGTH(ming) / 3;
# 先选出姓
SET return_str = CONCAT(return_str, SUBSTRING(xing, FLOOR(1 + RAND() * l_xing), 1));
#再选出名
SET return_str = CONCAT(return_str, SUBSTRING(ming, FLOOR(1 + RAND() * l_ming), 1));
IF RAND()>0.400 THEN
#再选出名
SET return_str = CONCAT(return_str, SUBSTRING(ming, FLOOR(1 + RAND() * l_ming), 1));
END IF;
IF RAND()>0.9800 THEN
#再选出名
SET return_str = CONCAT(return_str, SUBSTRING(ming, FLOOR(1 + RAND() * l_ming), 1));
END IF;
RETURN return_str;
END
;;
DELIMITER ;
- 索引创建和删除的SQL语句
-- 查看指定数据表的索引。
show index from tb_order;
-- 创建普通索引:
create index idx_user_id on tb_order(user_id);
-- 修改表结构的方式添加索引,这种方式可以不指定索引名称,不指定系统会自动默认一个索引名称。
alter table tb_order add index idx_user_id(user_id);
-- 删除指定的索引。
drop index idx_user_id on tb_order;
-- 修改表结构的方式删除索引。
alter table tb_order drop index idx_user_id;
-- 创建唯一索引,指定创建唯一索引的列的值必须是唯一的,不能重复,但是可以为null。
create unique index idx_order_no on tb_order(order_no);
-- 修改表结构的方式添加唯一索引。
alter table tb_order add unique index idx_order_no(order_no);
-- 创建复合索引:
create index idx_order_no_2_3 on tb_order(order_no,order_no2,order_no3);
-- 修改表结构的方式添加索引,这种方式可以不指定索引名称,不指定系统会自动默认一个索引名称。
alter table tb_order add index idx_order_no_2_3 (order_no,order_no2,order_no3);
-- 添加全文索引,只能在MyISAM引擎上才能使用
alter table tb_order add fulltext index_name(order_no);
B+Tree实战分析我们在什么情况下能够用到我们的索引
- 全值匹配
## 查询优化器会分析这些查询条件并且按照可以使用的索引中列的顺序来决定先使用哪个查询条件。 从下面的结果中我们可以看到使用到了索引:idx_order_no_2_3
EXPLAIN SELECT user_id,order_no FROM tb_order WHERE order_no = '26479553664778247' AND order_no2 = '966' AND order_no3 = '37986' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: ref
possible_keys: idx_order_no_2_3
key: idx_order_no_2_3
key_len: 1359
ref: const,const,const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
- 匹配左边的列
## 使用到了索引
mysql> EXPLAIN SELECT user_id,order_no FROM tb_order WHERE order_no = '26479553664778247' AND order_no2 = '966' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: ref
possible_keys: idx_order_no_2_3
key: idx_order_no_2_3
key_len: 756
ref: const,const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
##直接用order_no2进行查询,可以看到是没有使用到索引的,因为B+树先是按照order_no列的值排序的,在order_no列的值相同的情况下才使用order_no2列进行排序,也就是说order_no列的值不同的记录中order_no2的值可能是无序的。而现在你跳过order_no列直接根据order_no2的值去查找,这是做不到的。
mysql> EXPLAIN SELECT user_id,order_no FROM tb_order WHERE order_no2 = '966' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9959026
filtered: 10.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
- 匹配列的前缀
## 这种是用不到索引的,因为字符串中间有'966'的字符串并没有排好序,所以只能全表扫描了
mysql> EXPLAIN SELECT user_id,order_no FROM tb_order WHERE order_no like '%966%' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9959026
filtered: 11.11
Extra: Using where
1 row in set, 1 warning (0.00 sec)
## 这种是可以用到索引的,因为字符串对开头有966'的字符串进行了排序,所以可以利用索引进行查询
mysql> EXPLAIN SELECT user_id,order_no FROM tb_order WHERE order_no like '966%' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: range
possible_keys: idx_order_no_2_3
key: idx_order_no_2_3
key_len: 153
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
- 精确匹配某一列并范围匹配另外一列
## 这样也可以用到索引
mysql> EXPLAIN SELECT user_id,order_no FROM tb_order WHERE order_no = '26479553664778247' AND order_no3 > '37986%' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: ref
possible_keys: idx_order_no_2_3
key: idx_order_no_2_3
key_len: 153
ref: const
rows: 1
filtered: 33.33
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
- 排序
## 这种情况下是可以使用到索引的
mysql> EXPLAIN SELECT order_no,order_no2,order_no3 FROM tb_order order by order_no\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: index
possible_keys: NULL
key: idx_order_no_2_3
key_len: 1359
ref: NULL
rows: 9959026
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
## 这个查询的结果集需要先按照b值排序,如果记录的order_no值相同,则需要按照order_no2来排序,如果order_no2的值相同,则需要按照order_no3排序。因为这个B+树索引本身就是按照上述规则排好序的,所以直接从索引中提取数据,如果查询的列数据正好是复合索引的列,那么就不需要回表进行提取数据操作,如果不是的话,就需要进行回表操作取出该索引中不包含的列,但是不一定,MySQL引擎会根据表中的数据里量以及要查询的列,判断是否要用到索引,因为如果回表的时间远远大于索引所用的时间,还不如不使用索引,比如下面的查询
mysql> EXPLAIN SELECT * FROM tb_order order by order_no,order_no2,order_no3 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9959026
filtered: 100.00
Extra: Using filesort
1 row in set, 1 warning (0.00 sec)
- 分组
##这种情况也是可以用到索引的
mysql> EXPLAIN SELECT order_no,order_no2,order_no3 FROM tb_order group by order_no,order_no2,order_no3 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb_order
partitions: NULL
type: index
possible_keys: idx_order_no_2_3
key: idx_order_no_2_3
key_len: 1359
ref: NULL
rows: 9959026
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.92 sec)
这个查询语句相当于做了3次分组操作:
- 先把记录按照order_no值进行分组,所有order_no值相同的记录划分为一组。
- 将每个order_no值相同的分组里的记录再按照order_no2的值进行分组,将title值相同的记录放到一个分组里。
- 再将上一步中产生的分组按照d的值分成更小的分组。
如果没有索引的话,这个分组过程全部需要在内存里实现,而如果有索引的话,正好这个分组顺序又和B+树中
的索引列的顺序是一致的,所以可以直接使用B+树索引进行分组。
- 使用联合索引进行排序或分组的注意事项
对于联合索引有个问题需要注意,ORDER BY的子句后边的列的顺序也必须按照索引列的顺序给出,
如果给出order by order_no2,order_no3, order_no 的顺序,那也是用不了B+树索引的。
- 不可以使用索引进行排序或分组的几种情况
ASC和DESC混用,对于使用联合索引进行排序的场景,我们要求各个排序列的排序顺序是一致的,也就是要么各个列都是ASC规
则排序,要么都是DESC规则排序。
- 考虑索引的选择性
索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数的比值:
选择性 = 基数/ 记录数
选择性的取值范围为(0, 1],选择性越高的索引价值越大。如果选择性等于1,就代表这个列的不重复值和表记录
数是一样的,那么对这个列建立索引是非常合适的,如果选择性非常小,那么就代表这个列的重复值是很多的,
不适合建立索引。
- 总结
- 索引列的类型尽量小
- 利用索引字符串值的前缀
- 主键自增
- 定位并删除表中的重复和冗余索引
- 尽量使用覆盖索引进行查询,避免回表带来的性能损耗。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









