







一.下载
地址:https://lucene.apache.org/solr/downloads.html
下载binary releases,我这里下载了比较新的solr-8.11.0。
二.使用默认容器jetty安装
(1)进入solr-8.11.0/bin,修改solr.in.sh,SOLR_ULIMIT_CHECKS=false
(2)./solr start -p 8983 -force
(3)登录http://192.168.124.128:8983/solr
三.创建core
在网页左下角点击Core Admin-Add Core(如name设置成my_core)-add Core:
此时会弹出在my_core目录下缺少solrconfig.xml,将含有此配置文件的文件夹(solr8是solr-8.11.0/server/solr/configsets/_default的conf文件夹)放入该目录下即可。若创建成功,可以看到solr-8.11.0/server/solr生成了目录my_core。
四.配置分词器
(1)下载中文分词器ik-analyzer(gitee/github,注意版本)https://gitee.com/xuquanch_9895/ik-analyzer-solr?_from=gitee_search,查看使用说明,上面有jar包下载和单机版solr的使用说明
(2)jar包放入/server/solr-webapp/webapp/WEB-INF/lib
(3)在server/solr/my_core/conf的managed-schema中添加如下代码
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
(4)重启./solr restart -p 8983 -force
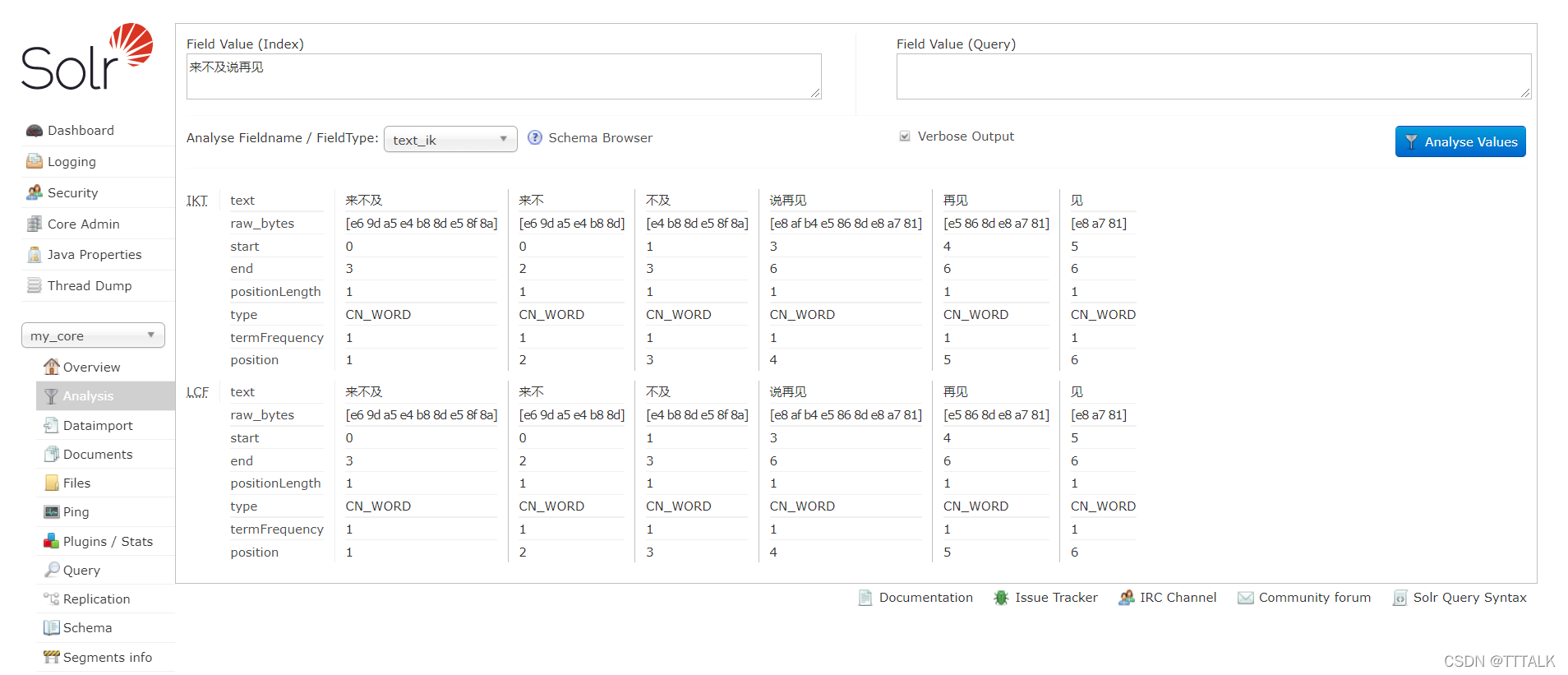
(5)再次登录,左下角的Core Selector选择my_core -> Analysis -> Field Value (Index)输入 “来不及说再见”;选择分词器Fieldname / FieldType: text_ik
,点击Analyse Values,分词后显示如下。
五.连接数据库
这里我用的是mysql,mysql的安装可参考:https://blog.csdn.net/tttalk/article/details/121929642
(1)建立数据库,创建表,建立索引。
CREATE TABLE celebrity (
id int(8) NOT NULL AUTO_INCREMENT,
name varchar(50) DEFAULT NULL COMMENT ‘姓名’,
description varchar(500) DEFAULT NULL COMMENT ‘简介’,
PRIMARY KEY (id)
);
insert into celebrity(name,description) values(‘神九根’,‘国家一级书画家’);
insert into celebrity(name,description) values(‘翟全刚’,‘心无旁骛的创作者’);
insert into celebrity(name,description) values(‘潘昭亮’,‘雕刻名家’);
insert into celebrity(name,description) values(‘夏国祥’,’“盛世中国”书画界最’);
insert into celebrity(name,description) values(‘陈鸣楼’,’《南宋皇城图》创作说明’);
insert into celebrity(name,description) values(‘张祥伟’,‘玉雕艺术乃是毕生追求’);
(2)将solr-8.11.0\dist下的两个jar:solr-dataimporthandler-8.2.0.jar 和 solr-dataimporthandler-extras-8.2.0.jar和数据库驱动包放入server/solr-webapp/webapp/WEB-INF/lib。
mysql8驱动包(mysql-connector-java-8.0.15.jar)下载路径:①https://dev.mysql.com/downloads/file/?id=484819,下载完记得解压,
②参考上面那个mysql安装的文章,成功连接后,使用maven中下载的jar包
(3)配置需要分词的查询方法,数据库连接等
①在solr\my_core\conf中新建文件data-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<!-- 数据库信息 -->
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.124.128:3306/mysql?characterEncoding=utf-8"
user="root" password="Ppp11111111!" encoding="UTF-8"/>
<document>
<entity name="celebrity" pk="id" query="select * from celebrity ">
<!-- 对应数据库表的字段 -->
<field column="id" name="id" />
<field column="name" name="name" />
<field column="description" name="description" />
</entity>
</document>
</dataConfig>
②将刚刚的配置data-config.xml配置到同目录的solrconfig.xml中,搜索Request Handlers,放在其下面
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
③配置managed-schema,其中type="text_ik"为第四步中测试过的分词器,找到
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
将下面两行放在该代码下,如果不配置这两行数据,则查询结果只会展示id和version。
<field name="name" type="text_ik" indexed="true" stored="true" multiValued="true" />
<field name="description" type="text_ik" indexed="true" stored="true" multiValued="true" />
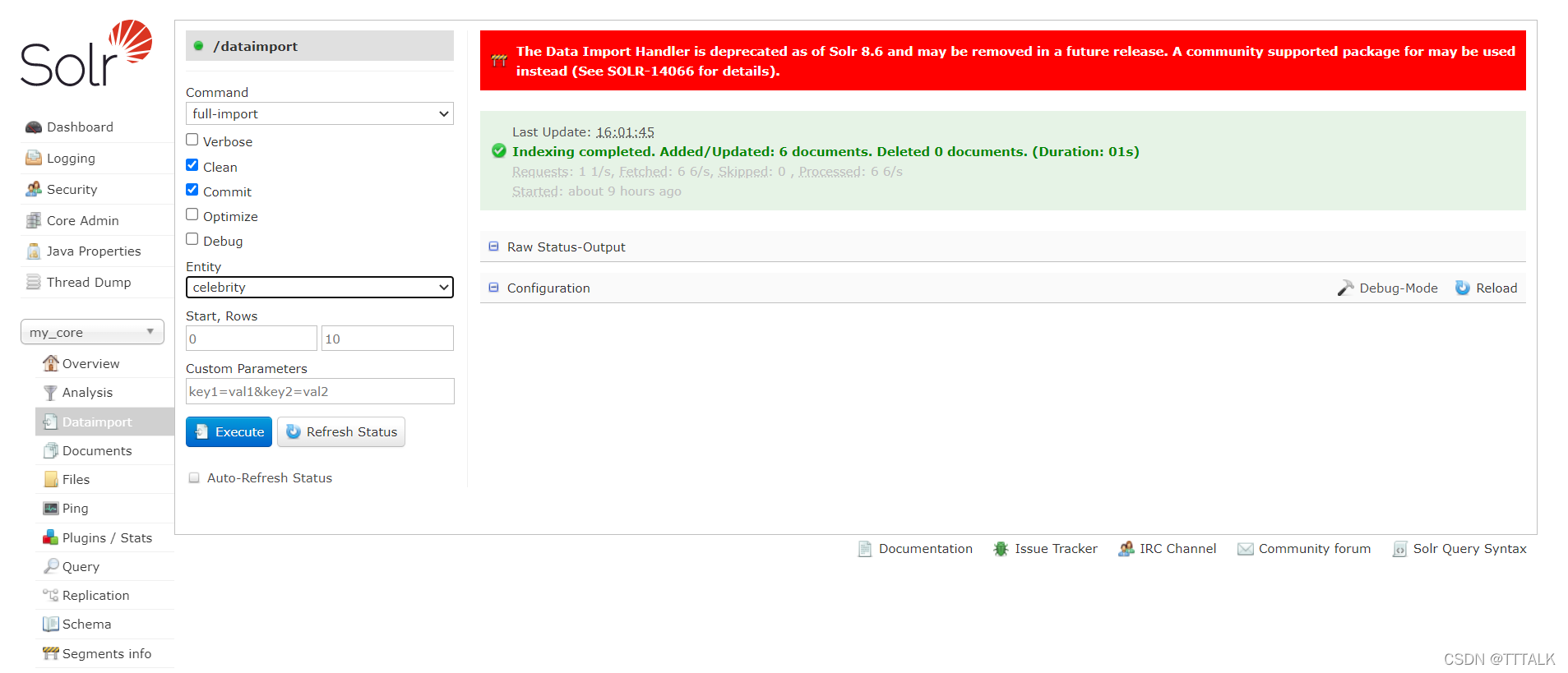
(4)重启后再次登录,左下角的Core Selector选择my_core-Dataimport-full import,勾选clean/commit,Entity选择celebrity,点击Execute以及Refresh Status,
可以看到Added/Updated: 6 documents. Deleted 0 documents.说明表中的6条数据都已经导进去了
然后选择Dataimport下面的query,点击Execute Query,能看到6条数据。
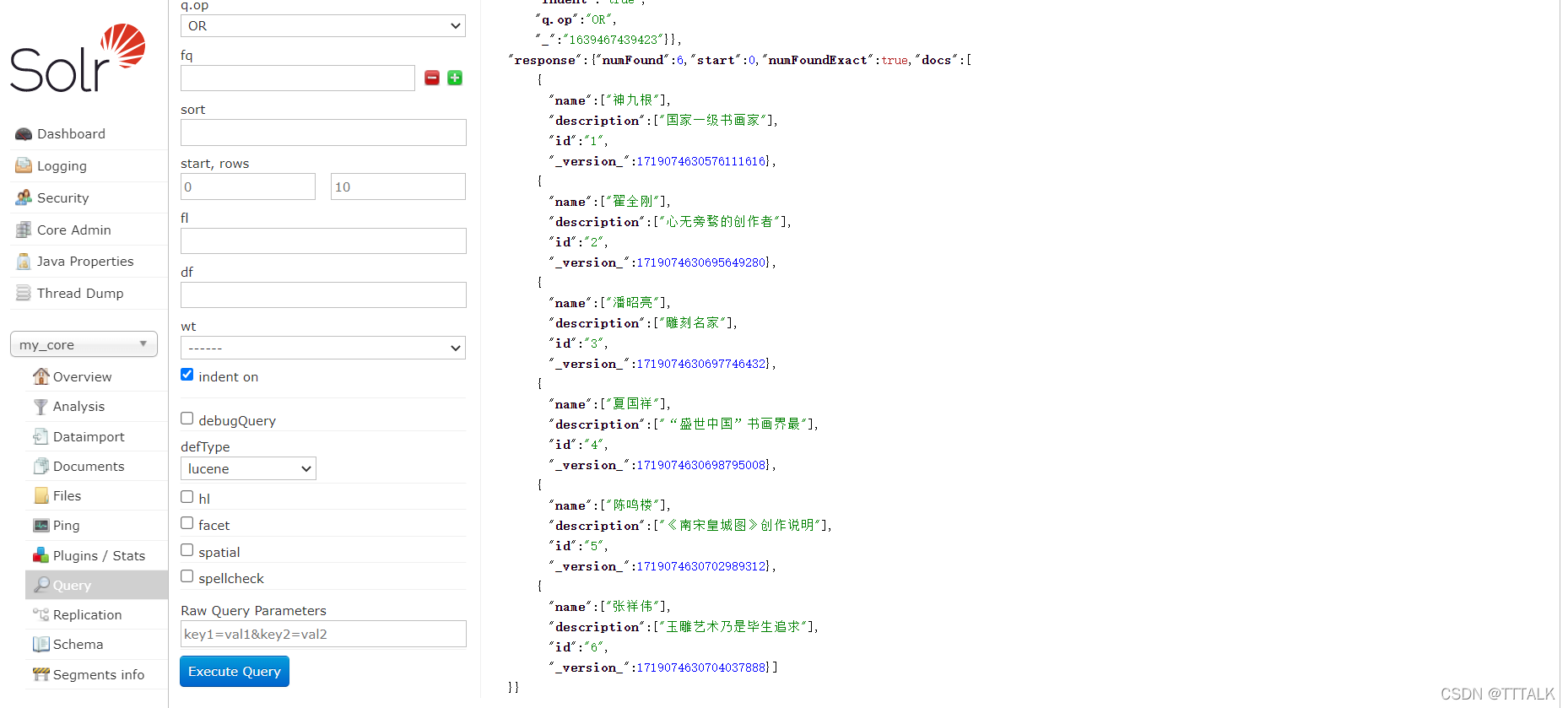
(5)query界面参数详细解释
qt :(query type)指定那个类型来处理查询请求,一般不用指定,默认是standard;
q : 查询的关键字,此参数最为重要,如输入 name:神九根 则会查询name='神九根’的数据;
fq :(filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的;
sort : 排序方式,例如id desc 表示按照 “id” 降序;
rows :指定返回结果最多有多少条记录,默认值为 10,配合start实现分页;
fl : 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,name,默认返回数据配置文件中file的字段;
df 默认的查询字段,一般默认指定。
wt:返回类型,有json、XML等;
hl:高亮显示;
facet:分组,其中facet.query表示所有的索引中含有该内容的数据有多少条,facet.field和facet.prefix需要结合,表示字段facet.field含有facet.prefix的内容共有多少条;
(6)如果报错,可以参考日志:solr-8.11.0/server/logs/solr.log














 1590
1590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









