







故事背景
两台ES集群,xx客户+xx项目经理竟然允许ES装在磁盘空间只有20G的服务器上。
由于磁盘紧张,脚本删除数据,但由于数据还有价值只能考虑挂载。在挂载的时候有一台es被无情删除,那酸爽,嘿嘿。我顶你个肺,顶到底。
现象
- 一台ES分片删除后,不要问我分片是什么,就是你打开ES页面,本来绿色带有一个个数字的都没有了。
- 数据丢失一半,查询的时候只有正常的那一台的数据存在。
- 数据还能正常存储,还特么只能存储一般,另一半你就是查不到
恢复
单个分片恢复
1、登陆服务器,切换到你安装ES的用户
2、输入命令curl -XGET http://localhost:9209/_cat/shards 查看所有分片状态;
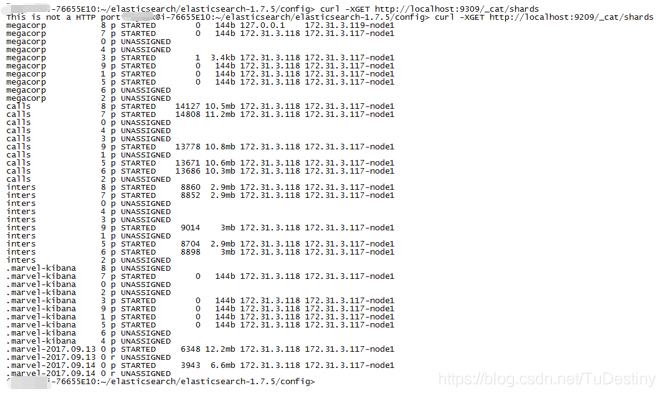
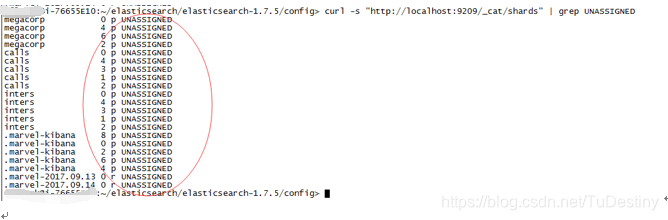
3、输入命令curl -s "http://localhost:9209/_cat/shards" | grep UNASSIGNED,找出UNASSIGNED分片
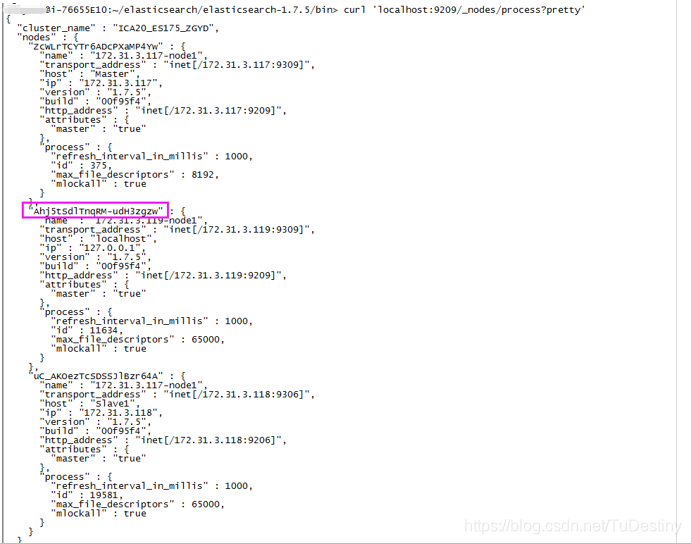
4、输入命令curl 'localhost:9209/_nodes/process?pretty'查询得到需要重建的es(即另外一个es集群)节点node1的唯一标识:
5、执行reroute(分多次,变更index、shard和node值, index是第3步查出来的异常分片区域,变更shard的值为UNASSIGNED查询结果中编号, 上一步查询结果是0、1、2、3、4、6和8,node为第4步查出的node1的唯一标识),以index=megacorp,分片为0举例子,输入命令:
curl -XPOST 'localhost:9209/_cluster/reroute' -d '{
"commands" : [ {
"allocate" : {
"index" : "megacorp",
"shard" : 0,
"node" : "il1jzOPUS8uQ_apmQQ9vcQ",
"allow_primary" : true
}
}
]
}'
出现如下日志,表示执行完成:

6、重启需要重建的es服务,注意重启后,节点的唯一标识node值会有变化;
7、登录es平台http://xxxxx:9209/_plugin/head/,查看es集群是否正常了
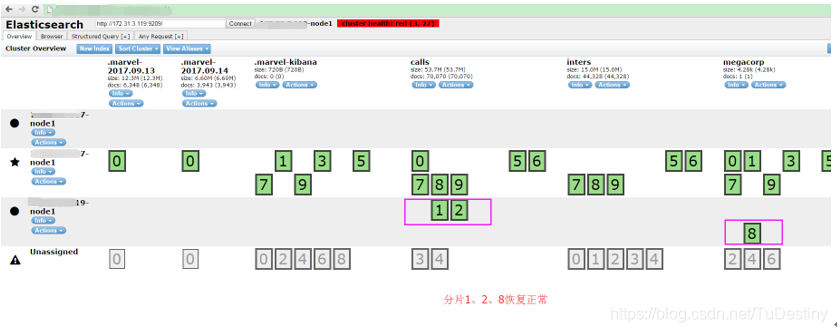
多个分片异常恢复步骤:
1、如果分片异常很多,使用shell脚本批量修复:
vim RecoverUNASSIGNED.sh
#!/bin/bash
for index in $(curl -s 'http://localhost:9209/_cat/shards' | grep UNASSIGNED | awk '{print $1}' | sort | uniq); do
for shard in $(curl -s 'http://localhost:9209/_cat/shards' | grep UNASSIGNED | grep $index | awk '{print $2}' | sort | uniq); do
echo $index $shard
echo '-------------------------------------'
curl -XPOST 'localhost:9209/_cluster/reroute' -d '{
"commands" : [ {
"allocate" : {
"index" : "'"$index"'",
"shard" : "'$shard'",
"node" : "8T_T8RyZRt64PgEbVfWraw",
"allow_primary" : true
}
}
]
}'
sleep 5
done
Done
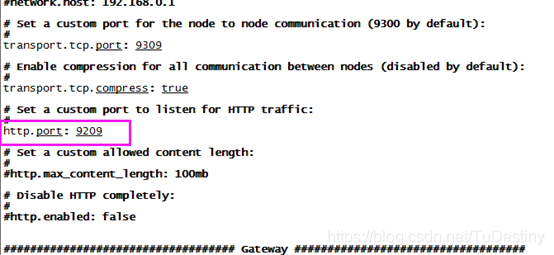
注意:9209即elasticsearch.yml 配置文件中http.port: 9209配置项,node需要替换成实际的node

注意:9209即elasticsearch.yml 配置文件中http.port: 9209配置项,node需要替换成实际的node
2、脚本执行完成后,重启分片异常的es服务;
执行完,问题也就解决了,可以安心睡觉了。














 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









