









端侧AI推理主要使用NPU完成,为了在性能,功耗和面积和通用性之间取得平衡,主流NPU采用了加速器架构,将算子固化在硬件中,并辅以可编程单元执行一些自定义算子/长尾算子兼顾灵活性。在计算方面,为了提高存储使用效率和加速计算,在满足计算精度的前提下,NPU普遍采用定点计算单元实现核心算子,以较低的带宽需求和较快的计算速度达到推理精度的要求,这样就需要在数据的预处理阶段和后处理阶段分别对数据做量化和反量化操作,以满足NPU计算单元对定点数据计算的需要,NPU的工作模型如下图所示,模型逐层运行,每一层执行一个或者几个kernel完成当前层的计算:

而GPU则不同,GPU的计算单元天然支持浮点计算,不需要执行量化和反量化的操作,模型推理更直接,以我的显卡为例,从下图可以看出,它的浮点算力远远高于定点算力:

正因为如此,使用GPU对模型推理,不需要量化和反量化操作:
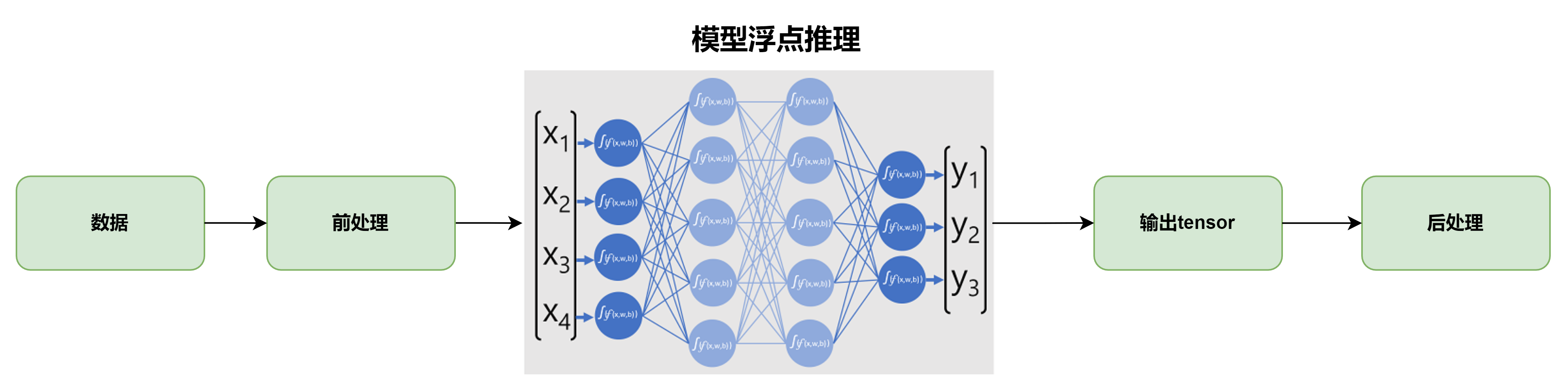
推理过程对量化的不同要求,可能会产生一个有意思的现象,就是两类设备推理的模型精度表现可能会出现抖动,这里所说的精度表现不是指浮点推理的精度一般要高于定点推理(量化和反量化会造成精度损失), 而是说,对于同一笔数据,在binary identical的情况下喂给GPU和NPU,NPU的推理结果表现出来的一致性要好于GPU。具体表现是,NPU对同样的输入会得到完全一样输出tensor,而同样一笔输入不同时刻在GPU上推理,每次的推理结果可能会有微小的差异。这个现象和几个因素有关,分析如下:
1.浮点数参与计算本身存在精度丢失的问题,比如下面的程序:
#include<stdlib.h>
#include<stdio.h>
int main(void)
{
int i = 0;
float j = 1.0;
float sum =0;
for(i = 0 ; i < 20000000 ; i ++)
sum += j;
printf("%f\n",sum);
return 0;
}预期结果为20000000.0,实际结果却是另外一个数:

精度损失的例子,以十进制浮点数8.1为例,转换成二进制数字为:
0.1*2=0.2,整数位为0
0.2*2=0.4,整数位为0
0.4*2=0.8,整数位为0
0.8*2=1.6,整数位为1,去掉整数位得0.6
0.6*2=1.2,整数位为1,去掉整数位得0.2
0.2*2=0.4.整数位为0.
................................
得到结果:
1000.00011001100110011.....
小数部分是以0011为循环节的无限循环数字,在有限的计算机位宽下无法存储,所以必然会发生精度损失。(从这个例子中也可以看出,十进制能够表示的小数,不一定能够通过有限的二进制数表示,这表示在一种数制下能够通过有限位表示的数字,在另一种数制下可能需要循环的无穷多位,这无穷多位一定要是循环的构成有理域,无理数在任何数制下都是无限不循环的 )。
这个道理很容易想通,举个例子就明白了,任何一个无限循环小数都可以转化成一个分数,假如是N/M,则如果数制选择为M,那么这个无限循环小数就可以表示为0.N. 用有限来表示。
2.大数吃小数的问题
本质上这个问题和问题1相同,都是由于浮点数的表示方式导致的计算精度问题,下面是个例子:
#include<stdlib.h>
#include<stdio.h>
int main(void)
{
float j = 1.0;
float i = 20000000.0;
float k = 20000000.0;
float m = i + j;
float s = k + i;
printf("%f, %f\n", m, s);
return 0;
}
大数吃掉了小数,但却吃不掉大数

3.和GPU的计算体系结构相关,GPU是多warp(线程束)竞争调度的,每次运行推理,同一kernel的调度执行顺序是不同的,这样会造成浮点计算顺序的差别。
对于GPU推理同一数据集每次运行结果的不一致问题,如果说前面两条因素是问题发生的客观条件的话,那么问题3就是发生问题的充分条件和直接原因了,由于GPU是由成千上万的小CPU并发执行完成某次计算的,调度顺序的微小差异会导致浮点计算顺序的差异,叠加上大数吃小数和精度损失的综合作用,从而使不同次的运行推理,产生了不一样的精度结果。
4.NPU为何在多次推理的实验中能保持一致?大概也和前面提到的几点因素有关,第一,NPU不同的网络层之间的运算完全由于硬件完成,数据,权重在不同层的调度分配完全是确定的,没有随机性,这样,导致问题的充分条件就被破坏掉了,同时权重数据经过量化后都是定点数据,NPU执行定点运算,执行顺序不同不会造成不同的结果,自然不会产生多次运行结果不一致的问题。
说到底,还是计算架构的不同以及计算数据的不同类型综合作用决定的,仅仅计算随机性不足以产生不一致的结果,因为随机性并不影响定点运算的执行结果,同样的,仅仅因为浮点运算而不考虑随机性,也不会造成每次结果的不一致。所以这种现象的产生,计算架构的随机性和浮点数据参与计算两个是充分和必要条件,缺一不可。

以一个典型的例子作为总结,例子中的问题为:一个大数连续累计加一个小数多次得到的结果,是否和这个小数先累加同样的次数,再和大数相加得到的结果一致?程序如下:
#include<stdlib.h>
#include<stdio.h>
int main(void)
{
int count;
float j = 1.0;
float i = 20000000.0;
float k = 20000000.0;
float m = i + j;
float s = k + i;
printf("%f, %f\n", m, s);
for(count = 0; count < 100; count ++) {
k += 0.1;
printf("%s line %d, k = %f.\n", __func__, __LINE__, k);
}
i = 0.0;
for(count = 0; count < 100; count ++) {
i += 0.1;
printf("%s line %d, i = %f.\n", __func__, __LINE__, i);
}
k += i;
printf("%s line %d, k = %f.\n", __func__, __LINE__, k);
return 0;
}结果是,由于大数吃小数的现象,第一次的结果和第二次的结果不同,对于小数来说,适合先猥琐发育,先将周围的小数团结起来吃掉,再和大数硬碰硬,否则直接和大数硬刚,结果就是落地成盒,灰飞烟灭。


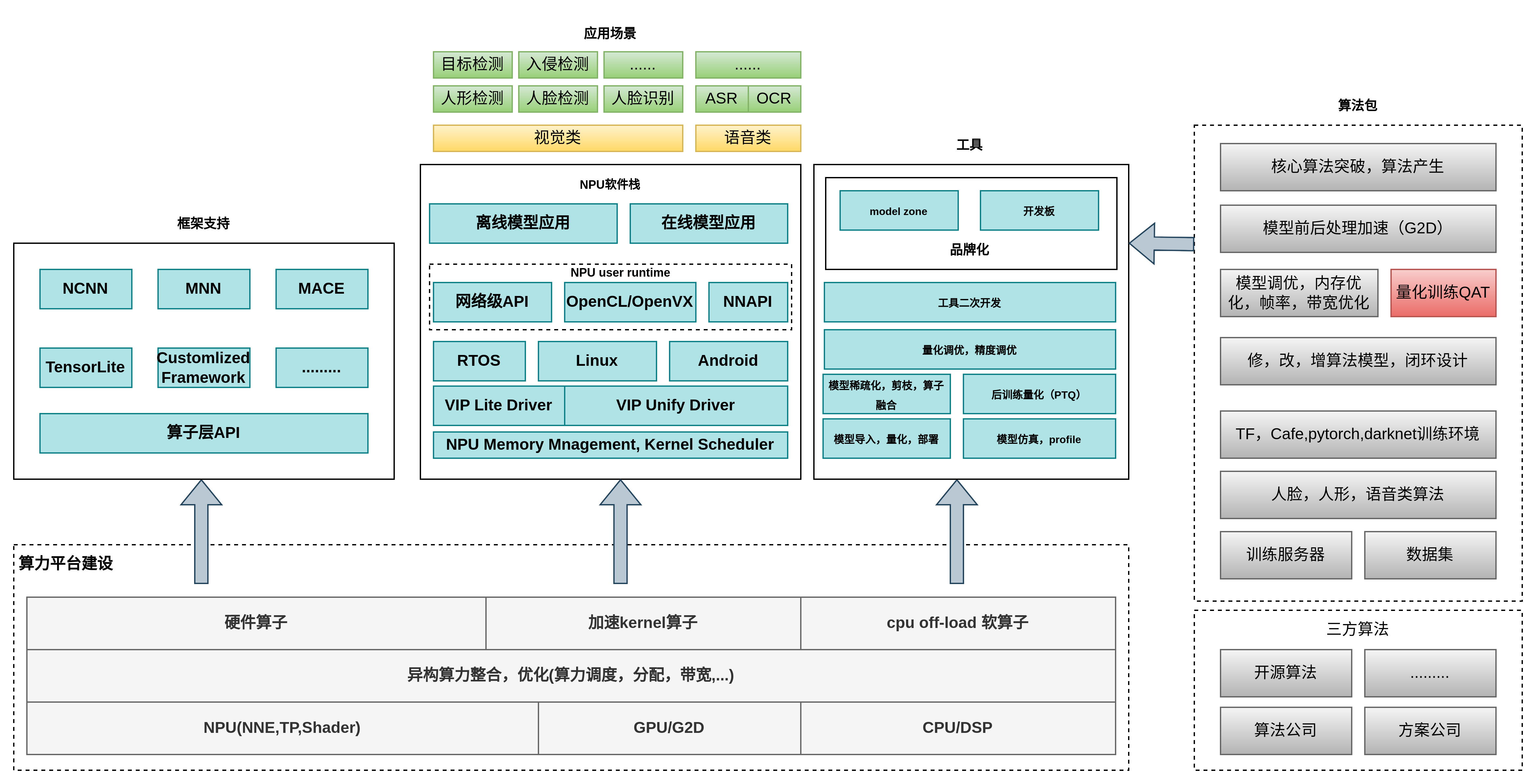
终端NPU应用架构:
参考文章
flaot 数据类型的一些坑(大数吃小数)_有态度的程序员的博客-CSDN博客




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











