






利用http协议向服务器传参的途径
url的特定部分 get post 请求头数据
在服务器保存的叫session
如果浏览器禁用了cookie, session不能实现
在客户端保存的叫cookie,换浏览器失效;基于域名,换浏览器失效
浏览器中的cookie过期时间
1.具体某时间失效,如max_age=3600 3600秒后失效
2.浏览会话结束时,指的是浏览器关闭时!max_age=None
MTV模型

M: model 处理数据库
V:view 处理业务逻辑
T:template 页面模板html
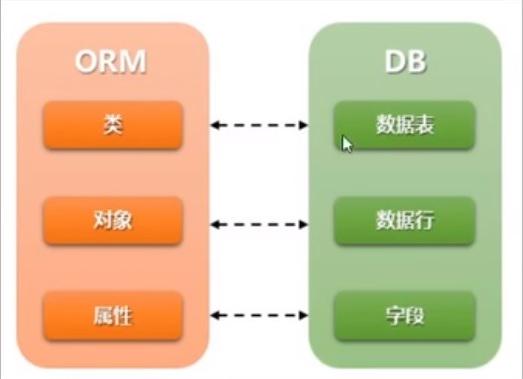
ORM框架
使同一套代码操作可以应用于不同的数据库
all() 返回所有数据,all()[0:2]返回前两个
filter() 返回满足条件的数据
exclude() 返回条件之外的数据
order_by() 对返回结果进行排序
两个属性的比较用F对象
BookInfo.objects.filter(A__gt=F(B)) # 属性A大于属性B
属性的与或非
BookInfo.objects.filter(Q(A__gt=1)&Q(B__gt=2)) #A大于1且B大于2 Q能与%或|非~
BookInfo.objects.filter(~Q(A__gt=1)) #A没大于1的 Q能与%或|非~
BookInfo.objects.filter(A__gt=2,B__gt=3) #A大于二里B大于3的
聚合函数
BookInfo.objects.aggregate(Sum('A')) #聚合函数 Sum,Avg,Max,Min,Count
排序
BookInfo.objects.all().order_by('A') #按A的升序排列
BookInfo.objects.all().order_by('-A') #按A的降序排列
关联查询
已知主表数据 关联查询从表数据
book=BookInfo.objects.get(id=1) #查找id为1的书籍,BookInfo是主表
book.peopleinfo_set.all()
#从表peopleinfo中建立了关于book的外键 在此获取peopleinfo中外键有book(id=1)的数据
girls = GirlsInfo.object.all() #不操作数据库
girls_list = [girl from girls]#操作数据库 操作结果存入缓存
girls_list = [girl from girls]#相同任务 不操作数据库 直接读取缓存
reverse函数
根据路由名称,返回具体的路径
项目名下的urls.py
urlpatterns=[url(r'^',include('book.urls',namespace='book'))]
某app名下的view.py
path=reverse('book:index')
用namespace避免不同应用间冲突
提取url的特定部分
app的urls.py
from django.urls import path,include,re_path
from girls import views
urlpatterns = [
path('girls_name', views.girls_name),
re_path('^(girls)_(height)$', views.girls_height), # 正则用re_path,这里有两个输入参数
re_path(r'^(\d+)/(\d+)$',views.girls_weight)# 获取路由url传入的参数
re_path(r'^(?P<p2>\d+)/(?P<p1>\d+)$',views.girls_weight)]
# p1 p2是views.girls_weight()里的关键字参数
app的views.py
def girls_height(request,p1,p2): #获取路由传入的两个参数
return HttpResponse('I am girls_height'+' '+str(p1)+' '+str(p2))
django中间件
请求前 执行顺序按照注册的顺序
请求后 执行顺序按照注册的逆序
mysql
打开操作日志
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
general_log_file = /var/log/mysql/mysql.log 设定log文件地址
general_log = 1
sudo tail -f /var/log/mysql/mysql.log
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新















 1885
1885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









