






01
The Illustrated 系列
如果你关注大模型技术动态,你可能知道这两个名字:Jay & Maarten,如果你不知道,那你大概率知道这篇文章——“The Illustrated Transformer”,或是读过以各种形式翻译过的这篇文章。我们说这篇文章是“爆款”“在圈内疯传”,一点儿也不夸张。
今年春节,在 DeepSeek-R1 最火的时候,解读底层原理的“The Illustrated DeepSeek-R1” 又刷屏了我们的朋友圈。
以上两篇文章的作者都是 Jay(Jay Alammar);而 Maarten(Grootendorst),大家看他的文章也不少,只是他对热点的追踪没那么快,但跟 Jay 相比,Maarten 的表达功力有过之而无不及。看看下面的图解系列的文章,总有一款你熟悉(都出自两位):
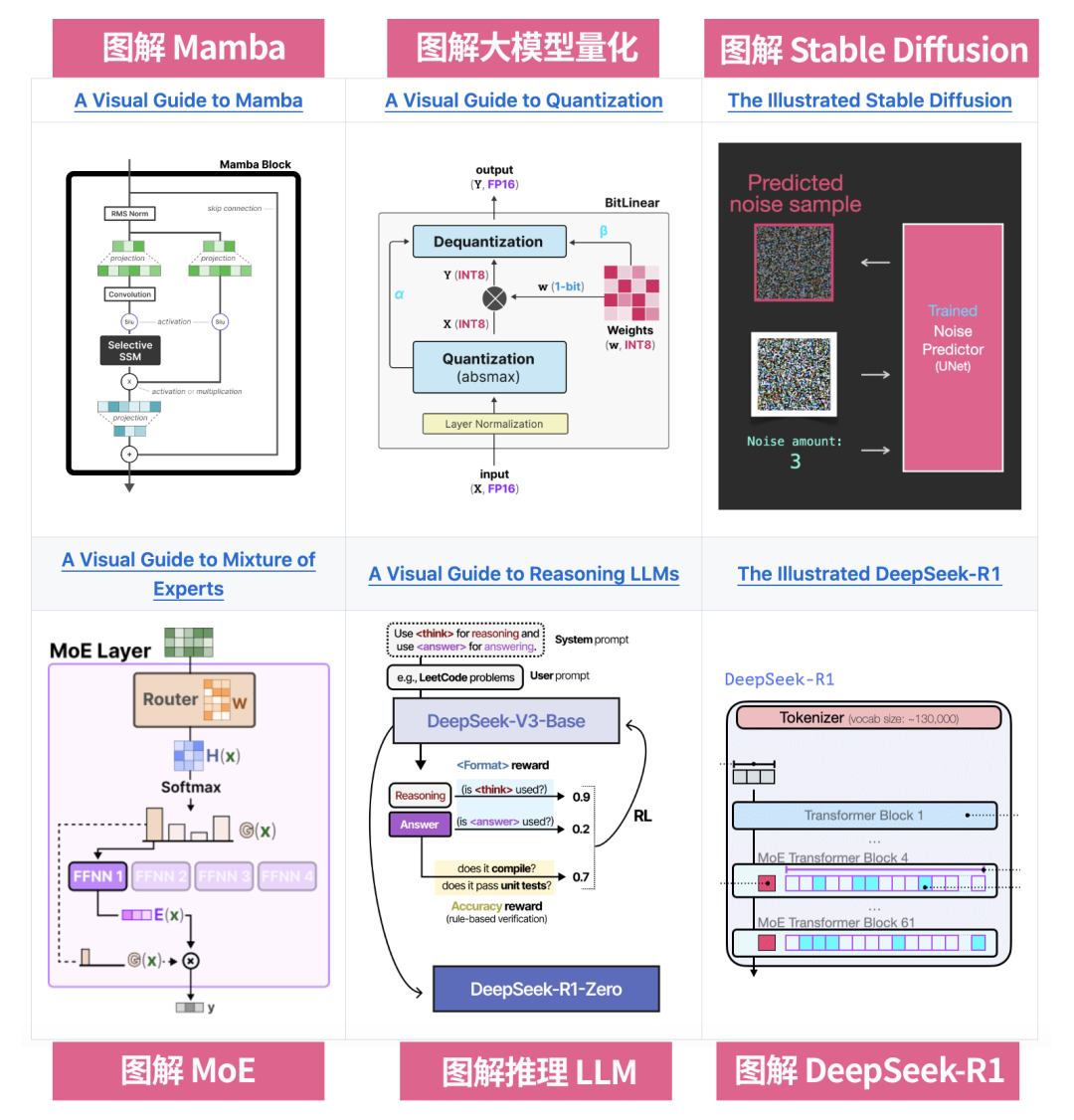
The Illustrated 系列已经成为大模型技术圈的王牌解读博客文章,每次出现新技术,读者翘首以盼。
02
《图解大模型》
而今天介绍的这本书:
正是两位业内资深专家专门为初中级读者创作的大模型学习指南,原始资料就是百万读者亲自验证过的一些热门博客文章,看到封面上的袋鼠部分朋友已经很熟悉了,原书非常有名:Hands-On Large Language Models: Language Understanding and Generation。
中文书名为《图解大模型》,即以“图解”为核心理念,通过高质量插图(超过 300 幅哦!),彻底颠覆你对技术书“晦涩难懂”的刻板印象。从底层原理到应用开发,再到模型训练与微调,让大家不仅能“读懂”,还能“看懂”,更要“用起来”。
很多读者说,这书的中文书名并没有照搬英文书名,必须承认,原书名将“动手做”列为第一特征,中文书名将“图解”作为首要特色,“实战”作为第二特色,这确实是我们反复思考之后,觉得最能体现图书特色的书名了——左手代码,右手图,边看边操作,学得肯定快!
我们展示几页内文,请大家体会一下——将抽象概念转换为形象图形的巧思:
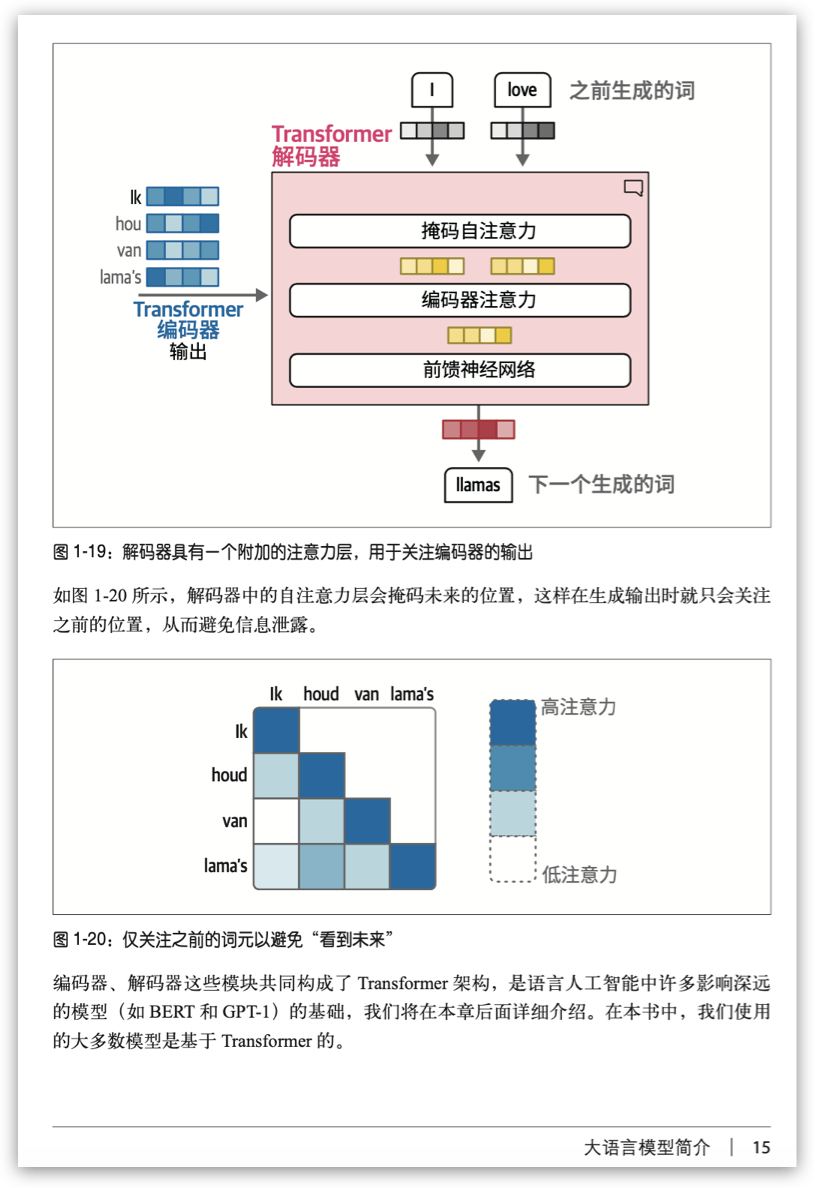
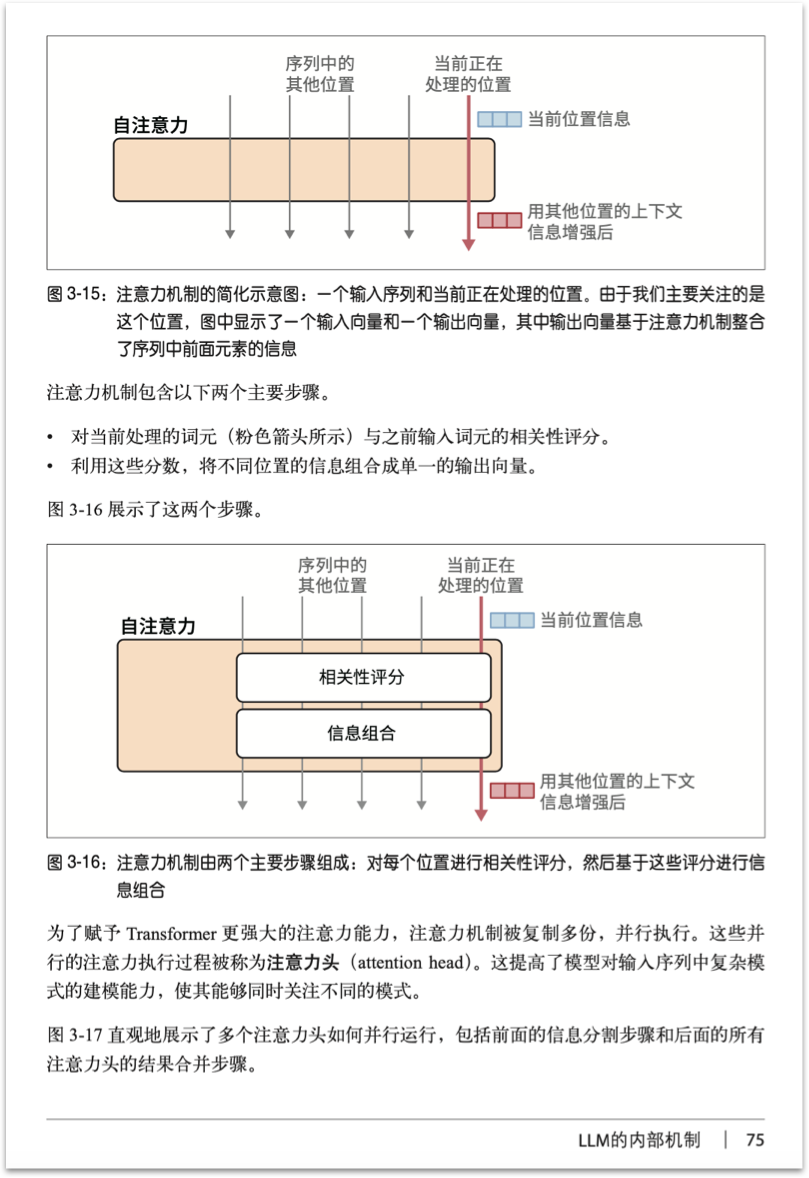
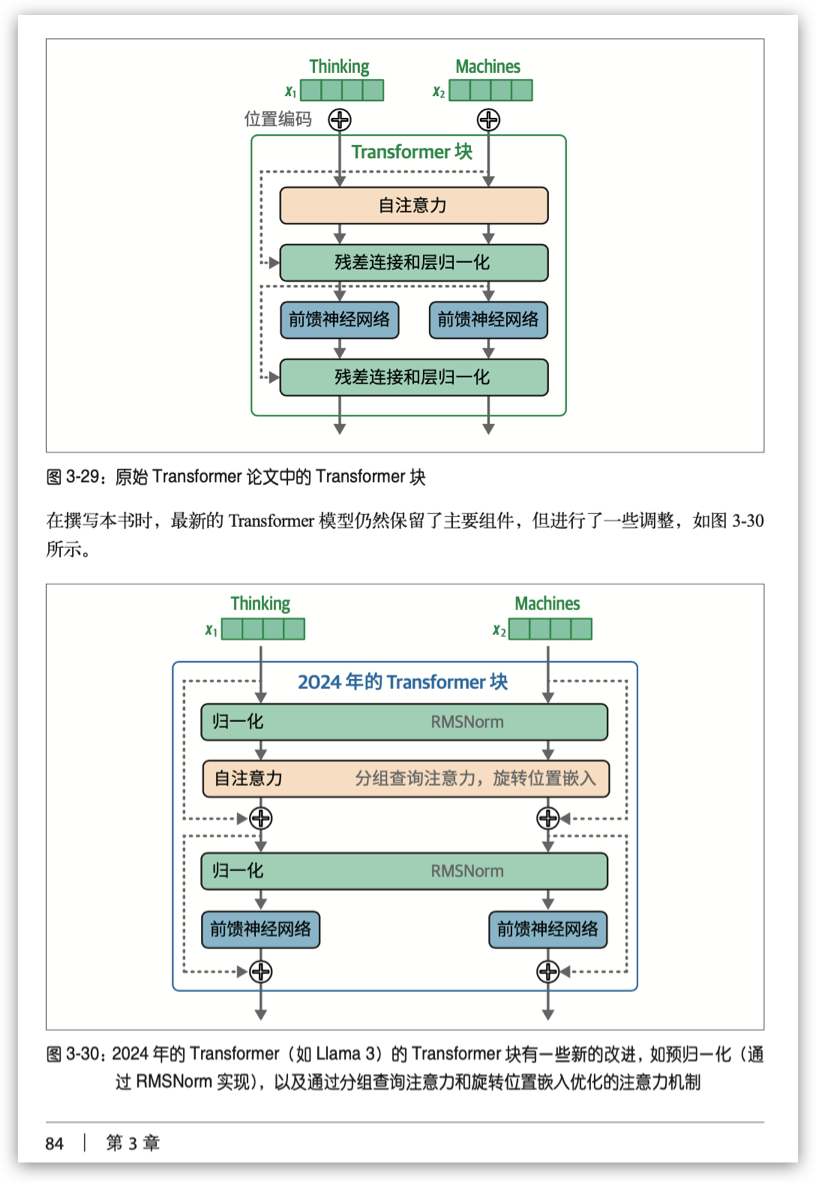
03
Jay & Maarten × 李博杰
两位作者背景相当硬核:

刚提到了两位作者,也要隆重地介绍一下我们的译者李博杰老师,同时也是业内 AI 创业者:

博杰老师不仅在原作上下了功夫,还结合自己在创业过程中面试候选人的经历,以及本书及其关联资料,针对大模型领域系统梳理出 200 道高质量面试题,附赠读者,旨在帮助大家更深刻地理解相关知识点。
附赠的内容以免费电子资料的形式开放(大家可前往图灵社区下载阅读)。
回到图书本身的内容,我们来看看这本书具体是怎么组织的,看一张目录导图吧!
04
这本书讲什么

结合这个目录,我们来看看本书的主要内容:
第一部分:理解语言模型
探索大、小语言模型的内部运作机制。首先概述该领域和常用技术(见第 1 章),然后讨论这些模型的两个核心组件(见第 2 章):词元(token)和嵌入 (embedding)。本部分最后是对 Jay 的大名鼎鼎的文章“The Illustrated Transformer”的更新和扩展,深入探讨了这些模型的架构(见第 3 章)。本部分还将介绍许多贯穿全书的术语及其定义。
第二部分:使用预训练语言模型
通过常见用例探索如何使用 LLM。我们将使用预训练模型并展示它们的功能,无须进行微调。
你将学习如何使用语言模型进行监督分类(见第 4 章)、文本聚类和主题建模(见第 5 章),利用嵌入模型进行文本生成(见第 6 章和第 7 章)、语义搜索(见第 8 章),以及将文本生成能力扩展到视觉领域(见第 9 章)。
学习这些独立的语言模型功能将使你具备用 LLM 解决问题的技能,并能够构建越来越高级的系统和流程。
第三部分:训练和微调语言模型
通过训练和微调各种语言模型来探索高级概念。我们将探讨如何构建和微调嵌入模型(见第 10 章),回顾如何针对分类任务微调 BERT(见第 11 章),并以几种生成模型的微调方法结束本书(见第 12 章)。
附录:图解 DeepSeek-R1
中文版专享福利,添加 Jay 大名鼎鼎的文章 “The Illustrated DeepSeek-R1”,通过 18 幅彩图解读 DeepSeek 底层原理,帮助读者真正认识推理大模型的本质。
05
适合谁阅读
本书适合对大模型感兴趣的开发者、研究人员和行业从业者。读者无须具备深度学习基础知识,只要会用 Python,就可以通过本书深入理解大模型的原理并上手大模型应用开发。书中示例还可以一键在线运行,让学习过程更轻松。
本书 GitHub 附赠大量延伸资料,且代码可通过 Google Colab 一键运行。
GitHub:
https://github.com/HandsOnLLM/Hands-On-Large-Language-Models

06
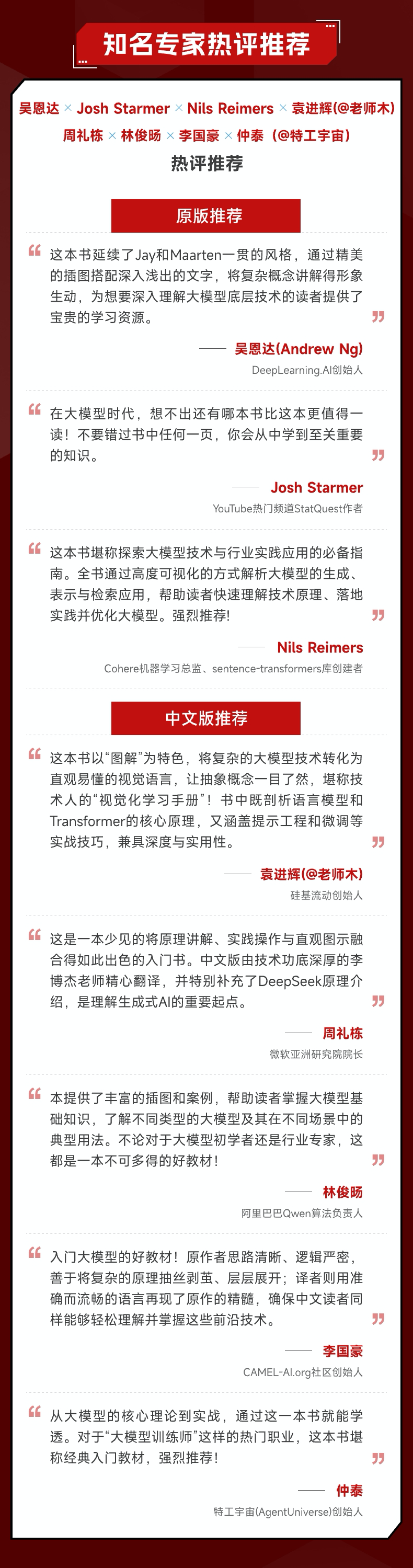
业内专家热评推荐
在国外,从 AI 教育专家,到 YouTube 大神,再到 Transformer 热门库创建者,都这本书赞誉有加。
在国内,大模型领域一线技术专家热评了本书在“图解”“可视化学习”与“工程落地”方面的特色。
以下为领域专家提前审阅本书给出的评价,供大家参考。
07
中文版附赠福利
大家知道,大模型技术迭代很快,在本书出版之后,DeepSeek-R1是大家当前集体关注的新技术突破,为了让这本经典之作同时能涵盖大家最关注的这部分内容,中文版附赠《DeepSeek底层原理解读》,请见本书最后的附录。
除了附赠DeepSeek底层原理解读,本书译者李博杰还为大家准备了一份相当特别的礼物——《大模型面试题200问》。博杰老师结合自己在创业过程中面试候选人的经历,以及本书及其关联资料,针对大模型领域系统梳理出 200 道高质量面试题,附赠读者,带着这些问题,你的学习将更有针对性。
附赠的内容以免费电子资料的形式开放给大家(大家可前往图灵社区下载阅读:https://www.ituring.com.cn/book/3285)。最后,让我们再来看看这本书的特色,这样的宝藏好书,谁能不心动呢?
【直观】300幅全彩插图,极致视觉化呈现
【全面】涵盖大模型原理、应用开发、优化
【实操】真实数据集,实用项目,典型场景
【热点】18 幅图深度解读 DeepSeek 底层原理
【附赠】一键运行代码 + 大模型面试题 200 问
【附赠】大量延伸阅读资料 + 两位作者的公开视频课
08
购买链接
相信有了这么强大的自学指南,再加上独一无二的配套资料和延伸阅读资料、公开课视频,不论是你是零基础的读者,还是初中级读者,学透大模型理论,真正把大模型用起来都不在话下!
300 幅图,全彩印刷,可一键运行的代码,还有面试题检验你的学习效果:
并不便宜,但物超所值!大家一起学起来~

最后啰嗦一句!要是觉得独自摸索大模型太费劲,想找搭子一起交流,扫码进群就对啦!群里能畅聊图书内容、技术难题,还能抢先读新书,紧跟领域新进展,更有专属福利。别等了,快进群,咱们抱团学习,一起进步!



















 16
16

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









