







什么是逻辑回归
之前我们讲过线性回归的原理以及推导过程。今天,我们回家另外一个算法,叫逻辑回归。简单归类一下,这个算法不是归类预测算法,大家千万不要被名字不会了。它其实属于分类算法。说到分类算法,大家有没有联想到?没错,逻辑回归属于监督学习。所以它需要带标签的数据。
这里简单的列举一下逻辑回归的使用场景:
- 垃圾邮件分类
- 网络诈骗分类
- 恶行肿瘤鉴定
逻辑回归模型推导
为何不能用线性模型
下面以恶行肿瘤来举例子。假如我们有个数据集,他们他描述的是肿瘤大小,以及是否为和兴肿瘤。大致如下:
| 肿瘤大小 | 是否恶性 |
|---|---|
| 1 | 否 |
| 5 | 否 |
| 10 | 是 |
| 10.5 | 否 |
| 15 | 是 |
假设x是肿瘤的大小,y代表否恶性。最终我们可以得到下图左边的8个红色交叉点。假如我们线性回归预测这8个点时,我们可以得到蓝色的一条线。若我们假设蓝色线上面的是恶行肿瘤,下面的是良性肿瘤。这里看上去预测的结果好像还可以。
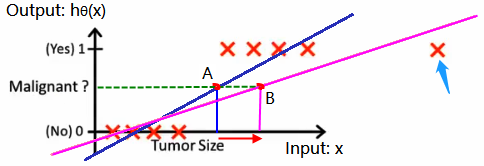
但假如这时候出现一个右边蓝色肩头上点,我们重新用线性模型预测出回归线,然后得到粉色的线。这时候问题就出现了,新增的点的x其实非常的大,但是却被模型判定成良性肿瘤。这样是不是就不对了。所以,我们需要修改我们的模型。我们要把我们的线性模型改成二分类模型。在逻辑回归的思想下,我们需要引入Sigmoid函数。
线性模型转二分类模型(Sigmoid)
突然冒出一个莫名其妙的Sigmoid的词汇是不是很”方“。其实Sigmoid的引入,就是逻辑回归的魅力所在。只要我们在模型中引入它,我们就可以把一条直线“掰”成一条曲线最终变成二分类模型。事不宜迟,马上介绍Sigmoid。
经过上一步的推导,我们可以得到一条线性回归线,这里把它写成:
f
(
x
)
=
ω
T
x
+
b
(
式
1
)
f(x) = \omega^Tx + b (式1)
f(x)=ωTx+b(式1)
在逻辑回归中,所谓的Sigmoid函数其实就是,同时可以得到下图:
g
(
x
)
=
1
1
+
e
−
x
(
式
2
)
g(x) = \frac{1}{1+e^{-x}} (式2)
g(x)=1+e−x1(式2)
我们把式1和式2做结合,就可以得到:
g
(
x
)
=
1
1
+
e
f
(
x
)
(
式
3
)
g(x) = \frac{1}{1+e^{f(x)}} (式3)
g(x)=1+ef(x)1(式3)
g
(
x
)
=
1
1
+
e
ω
T
x
+
b
(
式
4
)
g(x) = \frac{1}{1+e^{\omega^Tx + b}} (式4)
g(x)=1+eωTx+b1(式4)
经过这么一段推导,我们就能得到逻辑回归模型的核心公式g(x)。当g(x)>0.5时,我们就认为结果为1;对应g(x)<0.5时,我们认为结果为0。说白了就是把f(x)转化成接近0/1的g(x)。这就是逻辑回归中的Sigmoid函数。对应的Python实现是:
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))
代价函数
上面讲了逻辑回归的基本推导,下面进阶的来了啊。那就是代价函数。至于代价函数是什么,大家另行查阅资料。下面到了求最优解的问题了。
使用最小二乘法估计
所谓的最小二乘法,其实就是求f(x)与实际y的欧氏距离。从上面结合,我们得知
f
(
x
)
=
ω
T
x
+
b
f(x) = \omega^Tx + b
f(x)=ωTx+b
通过求f(x)和y的欧氏距离,我们可以得到
J
(
θ
)
=
1
m
∑
i
=
1
m
(
f
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J(\theta) = \frac{1}{m}\sum^m_{i=1}(f_{\theta}(x^{(i)}) - y^{(i)})^2
J(θ)=m1i=1∑m(fθ(x(i))−y(i))2
显然,我们现有的代价函数只适合凸函数的场景下。假如函数是一个非凸的函数,最小二乘法求代价函数显然是不可取的。就如下图一样

最大似然法
那么,为了满足我们的需求,我们就需要换一个思路。最后大佬们相处了最大似然估计这个方式。什么是最大似然估计请大家自行查阅资料。所谓的极大似然估计其实就是使模型正确率最高的意思。我们可以拟定
{
P
(
y
=
1
∣
x
,
θ
)
=
h
θ
(
x
)
P
(
y
=
0
∣
x
,
θ
)
=
1
−
h
θ
(
x
)
\begin{cases} P(y=1|x,\theta) =h_\theta(x)& \\ P(y=0|x,\theta) =1-h_\theta(x) \end{cases}
{P(y=1∣x,θ)=hθ(x)P(y=0∣x,θ)=1−hθ(x)
综合他们的总概率,我们可以得到
P
(
y
∣
x
,
θ
)
=
h
θ
(
x
)
y
(
1
−
h
θ
(
x
)
)
y
P(y|x,\theta) = h_\theta(x)^y(1-h_\theta(x))^y
P(y∣x,θ)=hθ(x)y(1−hθ(x))y
得到上述的公式,我们就可以求出最优解了。但P是乘法的,这样我们并不容易求出我们想要的结果。所以我们可以采用对数极值的方式来求。因为对数可以让乘法变成加法。也就是说:
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
{
−
l
o
g
(
h
θ
x
)
if y=1
−
l
o
g
(
1
−
h
θ
x
)
if y=0
Cost(h_{\theta}(x),y)=\begin{cases}-log(h_{\theta}x) &\text{if y=1}\\ -log(1-h_{\theta}x) &\text{if y=0} \end{cases}
Cost(hθ(x),y)={−log(hθx)−log(1−hθx)if y=1if y=0

这里可以看出,当y=1时,代价函数将越来越小。对应cost代码如下:
import numpy as np
def cost(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X* theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X* theta.T)))
return np.sum(first - second) / (len(X))
代码样例
讲了这么多,我们开始紧张刺激的环节吧。让我们来构建一个简单的逻辑回归模型。输入参数依然是癌症肿瘤,判断肿瘤是否恶性。(数据来源)然后包采用sklearn的类库。(官方文档)由于网上比较多的资料都是用这份数据的,所以代码可能差不多。
import pandas as pd
from sklearn.linear_model import LogisticRegression
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
from sklearn.linear_model import SGDClassifier
columns_names = ['Sample code number','Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape',
'Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli',
'Mitoses','Class']
data = pd.read_csv('breast-cancer-wisconsin.data',names=columns_names)
#把?的缺失值删除掉
data = data.replace(to_replace='?',value=np.nan)
data = data.dropna(how='any')
#分割数据成测试集和训练集(监督学习必备)
X_train,X_test,y_train,y_test = train_test_split(data[columns_names[1:10]],data[columns_names[10]],test_size=0.25,random_state=33)
#数据预处理
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.fit_transform(X_test)
#创建并训练模型
lr = LogisticRegression().fit(X_train,y_train)
#predict出测试集
lr_y_predict = lr.predict(X_test)
#调用SGDClassifier 中的fit函数进行训练
sgdc = SGDClassifier()
sgdc.fit(X_train,y_train)
sgdc_y_predict=sgdc.predict(X_test)
#打印结果
print('Accuracy of LR Classifier:',lr.score(X_test,y_test))
print(classification_report(y_test,lr_y_predict,target_names=['Benign','Malignant']))
总结
逻辑回归是一个监督学习中的分类算法。他的核心思想就是通过Sigmoid函数的引入,使一条线性回归的线变成一个二分类问题。所以对于Sigmoid函数的理解和整个推导式逻辑回归的核心。
但事实上,除了线性的逻辑回归以外,还有非线性的逻辑回归模型。关于这个我们后续有机会的话继续学习。
点我阅读更多算法分享















 6337
6337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









