







关于KV存储
什么是NOSQL
NoSQL,指的是非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
Key_value数据库的物理组成
存储系统主要由索引文件(.idx)和存储文件(.mmap)组成,索引文件主要存储的是具体数据的索引元信息,帮助快速定位数据在mmap存储文件中的位置。
数据块的划分
数据文件和索引文件都以文件映射的方式映射到内存中。文件被划分为几个大块,每个大块的长度都是Integer.maxValue,每个大块又被多个block组成。
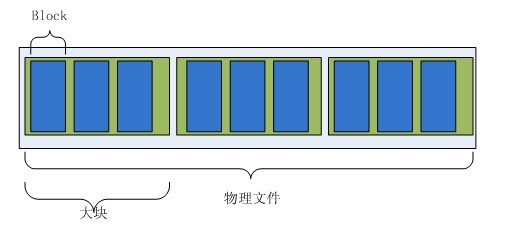
这样划分数据块的好处很明显,要在物理文件中定位数据很容易,只要知道block的index,则可以很快的利用除数找到数据所在的大块,然后用余数找到数据在大块中的偏移位置。
索引文件的存储
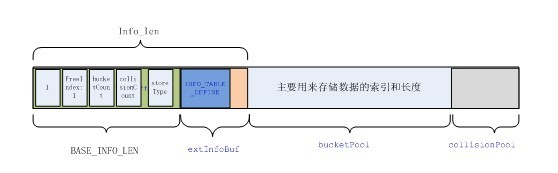
其中,base_info中主要存储的是以下数据:
isInit:是否已经初始化
bucketCount:桶的数量
collisionCount:备用的索引块的数量
freeBlockIdx:空间块索引
recordCount:记录的数量
storeType:存储类型
minCellSize:最小单元格尺寸
其中extinfo主要存储表的定义信息
collisionPool是当bucketpool不够用的时候做备用
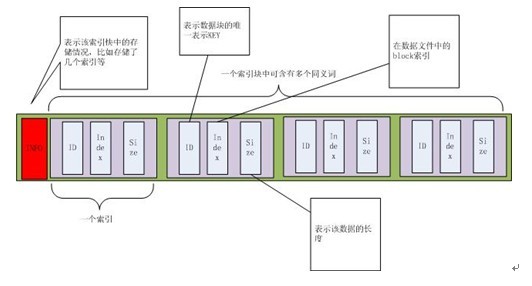
数据文件的格式如下
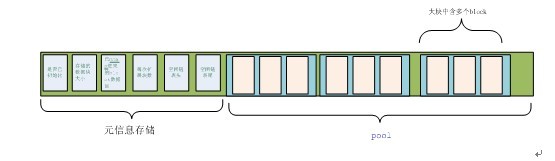
每个物理存储单元都存在一个指针,指向下一个单元,可养可以避免分配空间的时候必须分配成块的空间,也在空间回收的时候,避免了内存碎片无法使用的情况,其中元信息中含有空间的数据block空间的头和尾,用于在存储数据的时候,按照数据的size分派空间,并将此空间从队列出去除。
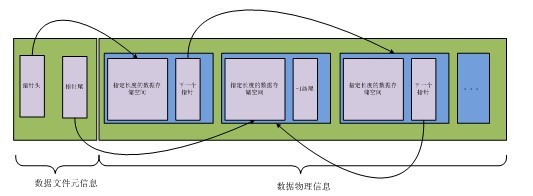
下面以数据的增删改查作为场景,分析一下:
l 新增数据:
1) 查找索引
this.index.get(hashCode);
根据Key的hashcode对bucketCount取余,然后定位到大块,然后对大块的buckCount取模,得到索引Block在大块中的偏移量。
2)判断索引块的几个同义词(hashCode%buckCount相等)是否存在该key的位置。
3)存储数据。
3.1)新增数据,从空闲链表空间中分配空间。
从空闲空间block的头开始遍历,知道找到能够容纳的他的空间。用block链表的形式返回,并且更新余下的空闲的block指针。
3.3)修改数据,数据长度变短。
如果数据长度简短,则覆盖数据后,必须将剩下多出来的block重新添加到空闲block队列后,改变指针即可做到。
3.3)修改数据,数据长度变长。
计算需要增加的block空间,从空闲block队列的得到,并且append在已有数据的block队列中即可。
4)更新索引
将索引的ID,数据block的头指针,数据的block个数等写入索引文件中相应的位置,并且更新索引快的Info标志。















 4701
4701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









