







本章谈的分布式系统是指运行在公司防火墙以内的信息基础设施(infrastructure),用于对外(客户)提供联机信息服务,不是针对公司员工的办公自动化系统。服务器的硬件平台是多核Intel x86-64处理器、几十GB内存、千兆网互联、常规存储、运行Linux操作系统。系统的规模大约在几十台到几百台,可以位于一个机房,也可以位于全球的多个数据中心。只有两台机器的双机容错(热备)系统不是本章的讨论范围。服务程序是普通的Linux用户进程,进程之间通过TCP/IP通信。特别是,本章不考虑分布式存储系统,只考虑分布式即时计算。
本章不谈“企业级开发”,也就是以商用数据库为存储,使用商用消息中间件(MQ,Message Queue,一些知名的商用消息中间件包括RabbitMQ(一个开源的消息代理软件,实现了高级消息队列协议(AMQP,Advanced Message Queuing Protocol),RabbitMQ在分布式系统、微服务架构和异步通信等场景中被广泛应用,提供了可靠、灵活的消息传递机制,帮助开发者构建可扩展和松耦合的系统)、Apache Kafka(一个分布式流处理平台,用于构建实时数据流应用程序和数据管道)、IBM MQ(WebSphere MQ,它是IBM公司提供的一种消息中间件(MQ)产品,最初被称为WebSphere MQ,它提供了可靠的消息传递、事务性消息、消息排队等功能)、ActiveMQ(一个开源的消息中间件(Message Broker),实现了Java Message Service(JMS)规范,它由Apache软件基金会管理,提供了可靠的消息传递服务,支持点对点和发布/订阅模型,以及许多高级功能,如事务性消息、消息持久性、消息过滤、集群支持等)等)或交易中间件(Tuxedo,TransaXiom Unified System for Operations,是一种事务处理中间件,允许开发者构建具有高度可靠性和一致性的分布式事务应用,由Oracle公司开发和维护),故障转移切换(failover)用VCS(Veritas Cluster Server,由Veritas公司开发,是一种常见的集群管理软件,旨在提供在系统或应用程序级别发生故障时实现快速故障切换和持续服务的能力)等商业解决方案。也不谈“高性能计算(HPC)”,这是一个相对成熟的领域,通常以MPI(Message Passing Interface,它是一种广泛采用的并行编程模型和通信库,MPI允许程序员将问题分解为多个任务,这些任务可以并行执行,并通过消息传递进行通信)为编程平台。并行算法对延迟有苛刻要求,通常采用InfiniBand(IB,是一种用于数据中心和高性能计算(HPC)领域的高速网络技术,提供了低延迟、高带宽和高度可扩展的网络连接,用于连接计算节点、存储系统和其他网络设备,InfiniBand最初设计用于替代传统的PCI(Peripheral Component Interconnect,一种计算机总线标准,用于连接计算机的内部组件,如插卡设备、扩展卡、图形卡、网卡等)总线,但后来广泛应用于构建高性能和超级计算机集群)为通信方式,不是常规的基于以太网的TCP/IP互联。
先谈钱
每台机器的购买成本是几万元人民币,每年的使用成本以一万元计(电费、机位、空调、网管,不含对外带宽)。换言之,本章讨论的是运行在几十台或几百台PC服务器(每台价值几万元)上的分布式系统,不是运行在几台高端服务器(每台价值几十万乃至上百万元)上的系统。换言之,是Google、Facebook、Amazon那种风格的分布式系统,不是IBM、Oracle、HP的scale up系统(指通过增加单个计算资源的能力(例如,添加更多的处理器、内存或存储)来提高系统性能和处理能力的方式,而不是通过连接多个独立的系统来实现)。
在这种commodity(指通用的,标准化的硬件设备,通常是相对较低成本的商业硬件,不是定制化或专门设计用于特定应用的,而是符合通用规范,能够被广泛应用于各种场景)硬件(服务器和网络)搭建的分布式系统中,扩容方式主要通过增加机器(scale out)进行。理想情况下,系统架构应该具备线性的伸缩性,系统实现应该让“伸缩”具有较小的比例系数。不妨假定同一批购买的相同用途的机器具有相同的配置,每次采购总是购买性价比最高的机型。服务器的服役期一般不超过5年,因为一台5年前购买的旧机器在消耗相同的电能的情况下,提供的处理能力只有新机器的一半甚至更少,不如淘汰它再买新机器更划算。
网络方面,可以认为同一数据中心的任何两台机器之间有千兆带宽,常用的做法是采用Clos/Fat-tree网络拓扑(一种经典的网络拓扑结构,主要用于构建大规模数据中心网络,它具有高度的可扩展性、低延迟、高冗余和高带宽聚合的特点,已经成为了目前数据中心网络的主流拓扑结构之一)(http://dl.acm.org/citation.cfm?id=1402967)。TCP/IP协议原本是为广域网设计的,但数据中心里的网络特性与传统广域网不同,会出现TCP Incast症状(一种网络拥塞现象,常见于数据中心网络中,它在高并发情况下出现,当多个客户端同时向服务器发送大量数据请求时,服务器将会面临处理大量请求的压力,导致网络拥塞和性能下降)。
也就是说,本章讨论在均质(homogeneous)的硬件和网络情况下来设计系统。
具体考虑以下有代表性的两种情况(这是非常业余的估算,只考虑了机器本身,没有考虑网络设备、制冷等方面,进一步的内容可以参考Google工程师写的《The Datacenter as a Computer》[DCC](方括号中的内容是书的缩写或简称)),假设每台机器每年的固定支出是1万元,再加上购买成本:
1.一台低端的价值2万元的服务器,使用寿命4年,平均每年支出1.5万元。
2.一台中端的价值5万元的服务器,预期服役3年,平均每年支出2.7万元。
为了便于计算,假定一台服务器一年的使用成本为3万元,来做一个非常粗略的估算:
1.一个普通程序员,公司每月支出2万元(注意这不是员工的税前工资,它包括了公司的其他用人成本,如场地租金、办公设施、五险一金等),一年24万,相当于8台服务器。
2.一个高级程序员,公司每月支出3万元,一年36万,相当于12台服务器。
一个高级程序员花3个月时间,把系统性能提高了20%,公司的成本是9万元,大约相当于3台中端服务器一年的使用费。如果原来有5台服务器,性能提高20%就意味着能节约1台服务器,这不见得划算。如果有50台服务器,解决了10台,有可能划得来。如果有500台服务器,节约了100台,肯定划得来。可见在需要提高系统处理能力的时候,优化代码不见得是首要的,有时候买新机器更划算。
硬件与操作系统
这种几万元级别的x86服务器的一般配置是:
1.双路多核CPU,一共8~16核(不含超线程)。
2.几十GB ECC内存(Error Correcting Code,错误修正码内存在传输和存储数据时,通过使用额外的校验位(parity bit)来检测和纠正内存中的错误)。
3.几块硬盘(本书不涉及存储,也就不仔细区分SSD、SAS、SATA的不同),容量几百GB至几TB。
4.冗余电源。
5.千兆网卡(GbE,Gigabit Ethernet,千兆以太网)或万兆网卡(10GbE)。
这种级别的硬件的可靠性见9.2,但是可以想见,不能指望单机具有坚不可摧的可靠性。分布式系统的可靠性不能依赖“硬件不会停机”这一假设。
这种服务器运行的通常是免费的Linux发行版。为什么不用Windows或其他商业系统?假设有200万元服务器硬件投资,可以买100台2万元的服务器。如果用Windows Server标准版,每台机器增加3000元成本(零售价是5000元,这里是作者估计的批发价),只能买87台服务器。Linux方案的硬件raw处理能力比其高15%。现在我们面临的不是Windows与Linux谁快的问题,而是Windows能否比Linux快15%(3000/20000=15%)以上,让投资回报合理。
在价值几万元这个级别的服务器上,作者认为Windows比Linux快是不成立的。本书讨论的分布式系统对操作系统的功能需求是:
1.管理十几个核上的任务调度。
2.管理几十GB物理内存的分配释放。
3.驱动一两个千兆或万兆网卡。
4.驱动十来块普通服务器级的硬盘。
Linux内核可以很好地完成以上这些任务,作者不认为其他操作系统能把这几样普通硬件管得更好。或许在高端128核1TB内存的安腾服务器(由英特尔公司推出的服务器产品系列)上Windows表现更佳,但这就不是本书讨论的范围了。既然操作系统选定为Linux,那自然不必考虑跨平台的问题,程序开发工作因此也简化了许多。
做分布式系统一个有意思的现象:公司越大,技术能力越强,用的机器越便宜。一般的公司会购买品牌服务器,配备冗余的电源和网卡,硬盘通常是配置为RAID 5/6/10等阵列,商用SAN存储也不少见。技术领先的互联网公司为了压缩成本,往往采用单电源、单网卡,存储也用一两块普通SATA硬盘(并且不用RAID),但无论如何,使用的还是服务器级的多路CPU和ECC内存(http://www.datacenterknowledge.com/archives/2012/06/27/video-facebook-compute-unit)。有的公司甚至用Intel Atom(英特尔公司推出的一系列低功耗处理器,专门设计用于移动设备、嵌入式系统和轻量级应用场景)或ARM(ARM架构是一种高效能、低功耗的处理器架构,广泛应用于移动设备、嵌入式系统和物联网设备等领域)来替换Xeon服务器(英特尔推出的一系列高性能服务器处理器,它们专门设计用于数据中心、云计算和企业级应用场景),以进一步降低能耗,但是由于可靠性较低(内存无校验),这些低端“服务器”通常用于静态cache之类的场合。
9.1 我们在技术浪潮中的位置
单机服务端编程问题已经基本解决
编写高吞吐、高并发、高性能的服务端程序的技术已经成熟。无论是程序设计还是性能调优,都有成熟的办法。在分布式系统中,单机表现出来就是一个网口(9.7.3),能收发消息,至于它内部用什么语言什么编程模型都是次要的。在满足性能要求的前提下,应该用尽量简单直接的编程方式。单机的技术热点不在于提高性能,而在于解放程序员的生产力,例如牺牲少许性能,用更易于开发的语言。
在编程模型方面,分布式对象已被淘汰
准确地说是远程对象(包括CORBA(Common Object Request Broker Architecture,通用对象请求代理体系结构,它允许不同的应用程序通过网络进行通信,共享和调用彼此的服务和对象)、DCON(Distributed Component Object Model,分布式组件对象模型,它是微软提供的一种分布式计算技术,用于实现不同机器上的对象之间的通信和协作)、RMI(Remote Method Invocation,远程方法调用,它是Java平台提供的一种分布式计算技术,用于实现在不同Java虚拟机之间的对象通信和方法调用,RMI允许开发者在网络上调用远程对象的方法,就像调用本地对象的方法一样简单)、EJB(Enterprise JavaBeans,企业级JavaBean,它提供了一种标准化的方法来开发可重用、可扩展和可事务化的分布式业务组件)、.NET Remoting(微软的一项技术,用于在.NET平台上实现分布式应用程序的通信和远程对象调用)等等),对象位于另一个进程(可能运行在另一台机器上),程序就像操作本地对象一样通过成员函数调用来使用远程服务。这种模型的本质难点在于容错语义。假设对象所在的机器坏了怎么办?已经发起但尚未返回的调用到底有没有成功?调用远程对象的method应该是阻塞还是抛异常呢(作者可能是要说,如果调用时间过长,应该是选择继续阻塞还是抛出异常,毕竟我们不知道是请求所需时间本就很长还是出现了异常)?假设持有对象引用的机器崩溃怎么办?对象有机会被回收吗?你理解并信得过它内置的容错与对象迁移机制(指在分布式系统中将对象从一个节点(可能是一台机器或进程)迁移到另一个节点的过程,应用程序可以在需要时动态地迁移对象以优化性能、负载均衡或故障恢复)吗?
20世纪80年代提出这种编程模型的前提是服务器的可靠性极高,有相当强的容错能力,几乎不存在失效的可能。这一前提在目前的分布式系统开发中是不成立的,这种技术适合所谓的企业级开发,不适合面向业务的分布式系统。这里推荐一篇Google的好文《Introduction to Distributed System Design》。其中的点睛之笔是:分布式系统设计,是design for failure。设计分布式系统不能基于错误的假设(《Fallacies of Distributed Computing Explained》)。
大规模分布式系统处于技术浪潮的前期
大家都在摸索中前进,尚未形成一套完整的方法论。某些领域相对成熟一些(分布式非结构化存储(一种存储系统,其特点是数据的组织方式不需要遵循严格的结构化模式,与传统的关系型数据库中的表格、行和列的结构不同,在非结构化存储系统中,数据通常以键值对、文档、图形或其他灵活的形式进行存储,而不需要固定的模式或预定义的数据模型)、离线数据处理(与实时数据处理相对应,在离线数据处理中,数据是按照批处理的方式进行处理,而不是实时或流式处理,这意味着数据被收集、存储,然后通过定期或按需的批次进行分析和处理)等),有一些开源的组件。但更多更本质的问题(正确性、可靠性、可用性、容错性、一致性)尚没有一套行之有效的方法论来指导实践,有的只是一些相对零散的经验(别人分享的经验也不一定完全可信,因为他可能分享的是一个阶段性成果,他告诉了你故事的开头,不一定也告诉你故事的结局,参见Amacon的Dynamo存储架构和采用这一思想的Cassandra项目的兴衰)。有人开玩笑说:“我不知道哪种方法一定能行,但是知道哪些方法是行不通的。”这或许正是我们这一阶段的真实写照,分布式系统开发还处于“摸着石头过河”阶段。
市面上分布式系统方面的书籍,大多谈的是高性能科学计算、并行算法,或者某些分布式算法的学术问题(分布式锁、选举等,见http://en.wikipedia.org/wiki/Distributed_algorithm),这些书对面向业务的分布式系统的指导意义有限。从另一个方面讲,面试一个“分布式系统的职位”都没有公认的好面试题(如果要考察C++程序员,虚析构是必问的;如果要考察C#程序员,value type与reference type是必问的;如果要考察多线程程序员,死锁和race condition是必问的。考察分布式程序员呢?),往往只能从项目经历来考察应聘者的水平。
我们怎么办?勿在浮沙筑高台,只用成熟的基础设施。目前看来,Linux、多线程编程、TCP/IP网络编程(而且只使用最基本的read/write数据流,不使用out-of-band,也不使用SCTP等不同寻常的协议)是成熟的,作者认为没有哪个“C++分布式中间件”是成熟的(对任何宣称“像开发单机程序一样写分布式应用”的广告语保持警惕,分布式系统有其本质困难)。2000年,Linux和多线程编程都不成熟;2004年Linux 2.6内核支持epoll和NTPL,Linux服务端多线程编程基本成熟。1990年,TCP/IP网络编程不成熟;W.Richard Stevens的传世经典《TCP/IP详解》和《UNIX网络编程(第2版)》分别在1993和1998年出版,网络编程基本成熟。现在,如果要学习Linux性能调优、多线程编程、网络编程、TCP/IP协议等等知识,都能找到非常好的书籍和网上资源,“能够靠读书、看文章、读代码、做练习学会的东西没什么门槛”(孟岩的《技术路线的选择重要但不具有决定性》,http://blog.csdn.net/myan/article/details/3247071)。
这也是本书主讲Linux多线程TCP网络编程的重要原因。但是这距离设计分布式系统还有巨大的鸿沟,本章的一些个人经验或许能让读者稍微少走一些弯路。
9.1.1 分布式系统的本质困难
Jim Waldo等人写的《A Note on Distributed Computing》(这篇文章同时指出延迟和内存访问也是重要区别)一针见血地指出分布式系统的本质困难在于partial failure。
拿我们熟悉的单机和分布式做个对比,初看起来,分布式系统很像是放大了的单机。一台机器通过总线把CPU、内存、扩展卡(网卡和磁盘控制器)连到一起(现在的CPU往往内置了内存控制器,不通过总线直接访问内存,但不影响此处的讨论),一个分布式系统通过网络把服务进程连到一起,网络就是总线。这种看法对吗?单机和分布式的区别究竟在哪里?能不能按照编写单机程序的思路来设计分布式系统?
分布式系统不是放大了的单机系统,根本原因在于单机没有部分故障(partial failure)一说。对于单机,我们能轻易判断某个进程、某个硬件是否还在正常工作。而在分布式系统中,这是无解的,我们无法及时得知另外一台机器的死活,也无法把机器崩溃与网络故障区分开来(《A Note on Distributed Computing》中写道:“[T]here is no common agent that is able to determine what component had failed and inform the other components of that failure, no global state that can be examined that allows determination of exactly what error has occurred. In a distributed system, the failure of a network link is indistinguishable from the failure of a processor on the other side of that link.”,这句话中,第一个字母T用中括号括起来了,这是因为在原文中,这句话不是句子的开头,t是小写的,而此处位于句子的开头,为了体现因语法导致的大小写转换,就把修改后的部分用中括号括起来)。这正是分布式系统与单机的最大区别。
例如一次RPC调用超时,调用方无法区分:
1.是网络故障还是对方机器崩溃?
2.软件还是硬件错误?
3.是去的路上出错还是回来的路上出错?
4.对方有没有收到请求,能不能重试?
在本机调用成员函数根本不会出现这种情况(Ken Arnold说道:“Now this is not a question you ask in local programming. You invoke a method and an object. You don’t ask,"Did it get there?"The question doesn’t make any sense. But it is the question of distributed computing.”,http://www.artima.com/intv/distrib.html)。这不是RPC的过错,而是分布式系统固有的特点,此处把RPC换成网络消息的请求响应也是一样的。简单地说,单机的编程经验不能直接套用在分布式系统上,分布式系统需要用单独的理论来分析(类似电路理论里的集总参数电路(一种电路模型,将电路中的元件和连线简化为一个等效的电路模型)和分布参数电路(主要用于描述高频电路的行为和特性,在分布参数电路中,电路中的元件(如电阻、电感、电容等)和传输线都被认为是有无限细小的分布参数),前者适用基尔霍夫定律,后者适用传输线理论(一种基于麦克斯韦方程组和电路理论,采用分布参数电路模型,将传输线看作是一个连续的电网络))。
单机(集中式)与分布式的根本区别在于进程的地址空间(address space)是一个还是多个,对于分布式系统来说,如果把进程比喻成“人”(第三章),那么这些“人”不是在一个屋子里交谈,而是通过电话会议交谈。或者类比成一群盲人在屋子里交谈。重要的区别在于,通过电话会议交谈的时候只能听到别人的发言,如果有人离场,其他人不会立刻得知,通常只能通过“一段时间没有发言”或者“叫他的名字没有回答”来间接判断某人已经离场。但是一个人被其他事情吸引(短暂过载)或开小差(网络暂时故障)也会表现为“一段时间没有发言”或者“叫他的名字没有回答”,其他人无法区分这两种情况。换言之,进程间通过收发消息来交换信息,一个进程看不到别的进程的数据,也不能立刻判断别的进程的死活(《Introduction to Distributed System Design》中讲:“We are fored to deal with uncertainty. A process knows its own state, and it knows what state othre processes were in recently. But the processes heve no way of knowing each other’s current state. They lack the equivalent of shared memory. They also lack accurate ways to detact failure, or to distinguish a local software/hardware failure from a communication failure.”)。当然,这个比喻本身也有问题,它假设了同时性和事件顺序的确定性。一个人说的话会立刻被其他人听到,甲乙两个人先后说话,那么其他人听到的顺序都是先甲后乙。这在分布式系统中是不成立的,见9.1.2中的例子。
分布式系统设计以进程为基本单位,先确定有哪些功能,需要做几个程序,每个程序的职责和它掌握的数据。然后安排这些程序在多台机器上的分布,规划每个程序起几个进程。进程之间的传输协议很容易确定,使用TCP长连接即可(第三章)。比较费脑筋的是进程之间的通信协议,即发送哪些消息,每条消息包含哪些内容。随着系统的演化,消息的内容也会变化,因为要提前做好准备(9.6)。
9.1.2 分布式系统是个险恶的问题
险恶的问题(wicked problem,《代码大全(第2版)》[CC2e]第5.1节:只有通过解决或部分解决才能被明确定义的问题。前面的CC2e是这本书的缩写)的意思是:你必须首先把这个问题“解决”一遍,以便能够明确地定义它,然后再解决一遍。在实现一个系统之前,很可能无法预料哪个技术方案行得通。这里举两个虚构的例子说明其险恶。
假设有一个缩略图(Thumbnailer)服务,它的功能是将用户提供的数码照片按比例缩小为固定尺寸,这是一个典型的无状态服务。它的实现很简单,不过是给ImageMagick(一个用于创建、编辑和合成图像的开源软件套件)的convert(1)命令提供一层网络封装。计算缩略图是一项相当耗时的任务(这是一个重采样(resampling,一种对数据进行重新采样的过程,通常用于调整数据的采样率、时钟频率或时间分辨率,以适应特定的需求或系统要求,这通常涉及到插值和抽取两个步骤,插值是通过使用已有的采样点来估计中间的采样点的值,抽取是通过删除或保留已有的采样点来调整采样率)过程,为了保证质量,用的是双三次(bicubic)插值算法(用于在重采样过程中估计中间采样点的值,它的主要优点是可以提供较高质量的插值结果)),平均每张图片用时0.5s,一台8核服务器每秒只能处理16张图片。相比之下,一台8核Web服务器可支撑每秒8000次HTTP请求响应,平均每个HTTP请求只占用1ms CPU时间。为了避免压缩照片影响Web服务器的性能,我们把生成缩略图功能移到单独的服务器中。系统中有多台Web服务器,连接到多台Thumbnailer服务器。现在的问题是,我们该如何做负载均衡?
第一个想法是每台Web服务器只和一台Thumbnailer打交道,通过Web本身的负载均衡来让图片压缩请求均匀地分散到多个Thumbnailer上。如图9-1所示的两种做法。

这种做法足够简单,但是Web负载从短期来看是非均匀的,具有突发性(burst)。假如某个用户通过某一个Web服务器上传了一堆照片,那么在现在这个设计中,会有一个Thumbnailer满负荷,而其他Thumbnailer都闲着,这不利于快速响应。
自然地,我们让每个Web服务器都可以和每个Thumbnailer服务器打交道,以期充分均匀地分散某一Web服务器的突发负载,形成了如图9-2所示的连接关系。那么负载均衡又该怎么做呢?
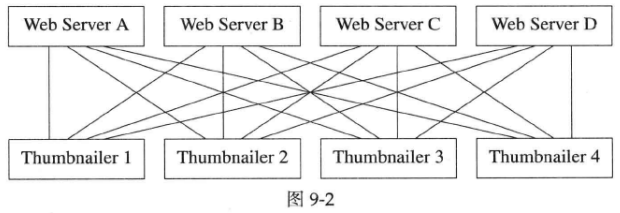
有几个实践证明不靠谱的做法:
1.每个Web服务器轮流向Thumbnailer[1,2,3,…,N]发送请求,结果发现Thumbnailer的负载像走马灯一样移动,因为Web服务器先集中火力攻击第1台Thumbnailer,然后再集中攻击第2台Thumbnailer,如此等等。
2.既然轮流发送请求不合适,就采用随机的方式选择Thumbnailer,随机数的种子用时间初始化。但是Web服务器几乎同时启动,他们用于初始化的种子相同,产生的伪随机序列也相同,造成与第1种做法相同的“潮涌”现象。
前面这两条都是开环控制,下面考虑闭环控制,让Web服务器知道Thumbnailer的实际负载,并从中选出负载最轻的来发送请求。
3.让Thumbnailer向Web服务器定期汇报当前负载情况,这种做法的缺点是消息数目与服务器数目呈平方关系,有M台Web服务器,N台Thumbnailer服务器,每个周期要发送M×N条消息,伸缩性不佳。而且“负载”强弱本身也不易定义。
4.通过某个集中的负载均衡器(load balancer)来收集并分发负载情况,好处是把消息数目将为M+N,但是造成了单点故障(Single Point of Failure,SPoF)。
这几个想法初看上去都挺合理,但是仔细一分析却有各自的问题。这里提出一种完全基于客户端视角的负载均衡策略。
第3和第4两种方案是基于Thumbnailer服务的当前负载的反馈控制,每次新请求都发向当前负载最轻的服务端。那么我们遇到的一个更本质问题是,如何定义服务端的负载?或者说Thumbnailer如何算出自己当前负载的单值(单独的数值或指标),以供客户端排序?其当前负载值与本机CPU使用率、内存占用率、硬盘剩余空间比例、网络带宽使用率是什么关系?各部分权重大小如何分配?有没有考虑同时运行在同一台机器上的其他服务进程也会消耗资源?
我们注意到,响应客户端(这里是Web服务器)请求的快慢直接反应了服务端(Thumbnailer)的负载。客户端根本无须关心服务端负载的具体情况(CPU负载、网络带宽负载、内存使用率等),只需要看它响应自己请求的速度就可以判断应该把下一个请求发给哪个服务端。具体地说是选择活动请求(已经发出请求而尚未收到响应)数目最少的那个服务端。这样一来客户端无须定期查询各个服务端的负载,只要根据自己以往的调用情况就能做出判断。这个做法大大简化了系统的设计。
客户端把服务端看成一个循环队列,在选择服务端时,从上次调用的服务端的下一个位置开始遍历,找出负载最轻的服务端。每次遍历的起点选在上次遍历终点的下一位置,这是为了在服务端负载相等的情况下轮流使用各个服务端,使各服务端负载大致相当。算法如下,其中last表示上次选取的服务端编号。
int selectLeastLoad(const vector<Endpoint> &endpoints, int *last)
{
int N = endpoints.size();
int start = (*last + 1) % N; // 每次从前次调用的下一位置找起
int min_load_idx = start; // 从start开始找负载最轻的服务端
int min_load = endpoints[start].active_reqs(); // 活动请求数目
for (int i = 0; i < N; ++i)
{
int idx = (start + i) % N;
int load = endpoints[idx].active_reqs(); // 负载即活动请求数目
if (load < min_load) // 找到更小的负载
{
min_load = load;
min_load_idx = idx;
if (min_load == 0) // 已经找到最小负载,无须再找
{
break;
}
}
}
*last = min_load_idx;
return min_load_idx;
}
举例来说,有4台Thumbnailer服务器。在某一时刻,客户端Web Server A向这4台服务器已发起而尚未结束的请求(即前述“活动请求”)的数目分别为3、2、3、4,Thumbnailer 2负载最轻,那么这时新的图片压缩任务将发给Thumbnailer 2。在下一次请求到来时,活动请求数目分别为3、3、3、3,客户端从Thumbnailer 2的下一位置(即Thumbnailer 3)开始查找可用的服务端,没有哪个服务端的负载比Thumbnailer 3更轻,因此新的图片压缩任务将发给Thumbnailer 3。
在最初的两种反馈控制设计中(3和4),是站在服务器的角度评估服务器的当前负载。某个服务程序的“当前负载”是一个全局数据,由服务端产生,每个客户端都希望这个全局数据随时保持更新。而在新的设计中,客户端根本不用关心这个全局数据,只要从自己的角度看,哪个服务器负载轻、等待响应的活动请求少,就把下一个请求发给哪个服务器。各个客户端看到的服务器负载情况可能不尽相同,不过从统计上看,负载仍然是均匀分配的,实验结果很好地支持了这一点。新的设计规避了分布式系统中保持全局数据一致性这个老大难问题。
在多个客户端(Web Server)的情况下,为了避免潮涌,每个Web Server用于初始化last值的随机数种子应该有足够的随机性,例如可以包括IP地址、MAC地址、当前地址、PID号等等。
这个简单的负载均衡策略在实际应用中获得了良好的效果。
第二个例子,分布式系统的险恶之处还在于时间与事件顺序违反直觉(就像具有狭义相对论效应,每个本地观察者有自己的时钟和事件顺序,http://research.microsoft.com/en-us/um/people/lamport/pubs/time-clocks.pdf,http://www.stanford.edu/class/ee380/Abstracts/091111-RethinkingTime.pdf),因为消息传递的延时是不固定的。
比方说,顾客向商店订购了一件商品(0:order),商店先是确认订单已收到(a:ack),再通知仓库发货(b:ship),随后立刻通知客户货物已发出(c:confirm),最后客户收到货物(d:deliver)。消息流程如图9-3所示。

按照常规的想法,a、c、d这3条消息发送的顺序是明确的,那么Customer收到消息的顺序也应该是a、c、d。但是在分布式系统中,a、c、d这3条消息到达Customer的顺序有6种可能。即便Shop与Customer采用一个TCP连接通信,保证a先于c到达,那么Customer收到这3条消息仍然有3种可能的顺序:
1.a,c,d。
2.a,d,c。
3.d,a,c。
由于a、c与d由两个不同的TCP连接发送,它们之间没有确定的先后关系。
同样的道理,如果客户端往Master发出一个请求,Master指定某个Worker来完成任务,Worker把计算结果发给客户端,消息流程如图9-4所示。
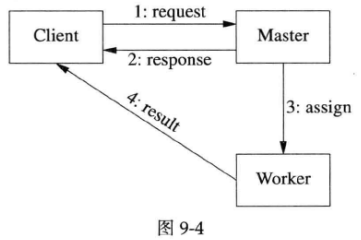
那么“4:result”完全有可能先于“2:response”到达客户端,因为TCP重传的首次间隔是200ms,如果发送“2:response”的时候发生了重传,那么它会比没有重传“4:result”更晚到达客户端。网络上消息传递的延迟没有上界,完全有可能出现后发先至的情况。客户端程序必须预见到并能正确应对这种乱序的情况。
另外,Client也没有办法判断“4:result”和“2:response”的发送哪个在前、哪个在后,即便Master和Worker都在消息中加上发送时间戳(timestamp)。这是因为分布式系统中每台机器有自己的本地时钟,Master和Worker的时钟之间肯定是有误差的,而Client并不知道它们的时间差多少。
在局域网内,消息的传输延迟不能通过发送方和接收方时间戳的差值算出来。因为在局域网中,虽然NTP对时的精度可以达到1毫秒之内,但消息的延迟本身也在1毫秒以内。测量值和未知系统误差(http://en.wikipedia.org/wiki/Systematic_error)在同一量级,测量结果是无意义的。必要的时候我们可以先测量两台机器之间的时间差,用来修正延迟测量的结果(7.9)。
9.2 分布式系统的可靠性浅说
本节谈谈作者对分布式系统可靠性的理解。要谈可靠性,必须要谈基本指标t
M
T
B
F
_{MTBF}
MTBF(平均无故障运行时间(http://en.wikipedia.org/wiki/Reliability_engineering,http://en.wikipedia.org/wiki/Mean_time_between_failures),单位通常是小时)。t
M
T
B
F
_{MTBF}
MTBF与可靠性的关系如下,其中t是系统运行时间。
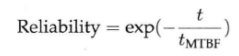
按照上式,当t=t
M
T
B
F
_{MTBF}
MTBF时,系统的可靠度为36.8%。也就是说当系统连续运转t
M
T
B
F
_{MTBF}
MTBF这么长时间后,发生故障的概率为63.2%。见图9-5中的指数曲线。

图9-5的横坐标为t
M
T
B
F
_{MTBF}
MTBF的倍数,纵坐标为可靠度。在粗略估算的时候,可以用直线代替曲线,达到t
M
T
B
F
_{MTBF}
MTBF时系统发生故障的概率为50%(图9-5中的实线)或100%(图9-5中的虚线)。如果要粗略估算短期可靠性,应该用图9-5中的虚线,它是指数曲线在t=0附近的一阶近似(斜率相等,为-1)。在估算可靠性的时候,一两倍的差距无伤大雅,因为t
M
T
B
F
_{MTBF}
MTBF本身只是平均数,而设备损坏时非均匀的(t
M
T
B
F
_{MTBF}
MTBF是用来估算机房需要准备多少块备用硬盘的,而不是预测下一次出现硬盘损坏是在什么时候)。
t
M
T
B
F
_{MTBF}
MTBF与使用寿命无关。硬盘的寿命通常是3~5年,但其标称t
M
T
B
F
_{MTBF}
MTBF是100万小时,即114年。这两个数字并不矛盾,t
M
T
B
F
_{MTBF}
MTBF为100万小时,意味着如果有1万块硬盘同时运行,那么平均每200小时会坏掉一块(也可以保守地估算为平均每100小时会坏掉一块)。如果按t
M
T
B
F
_{MTBF}
MTBF为100万小时计算,硬盘每年故障率不到1%,但是硬盘实际的年故障率在3%~8%,因此不能一味相信厂家给出的数据(《Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you?》,http://www.cs.cmu.edu/~bianca/fast07.pdf,http://storagemojo.com/2007/02/20/everything-you-know-about-disks-is-wrong)(《Failure Trends in a Large Disk Drive Population》,http://research.google.com/archive/disk_failures.pdf,http://storagemojo.com/2007/02/19/googles-disk-failure-experience)(《Empirical Measurements of Disk Failure Rates and Error Rates》)。
一个系统由多个部件组成,系统的整体可靠性取决于部件之间是“并联”还是“串联”。所谓两个部件“并联”,指的是两个部件同时坏掉会导致系统失灵,比方说冗余电源就是“并联”的。所谓两个部件“串联”,指的是只要有一个部件坏掉,系统就失灵了;一般的入门级服务器上,主板、CPU、内存都是“串联”的。
“并联”可以极大地提高可靠性。例如一台服务器有两个电源,同时工作,而且可以热插拔。如果单个电源的t M T B F _{MTBF} MTBF是10万小时,更换坏电源需要24小时。假设有100台单电源的机器,平均每42天会有一台机器出现电源故障(因为24×100×42=108000小时。这里也可以估算为83天,无妨)。如果改用双电源,在出现坏掉一个电源的情况后,在24小时内更换它,可确保不停机。那么这台机器的另一个电源在这24小时内坏掉的可能性是1-exp(-24/100000)=0.024%,因此双电源的可靠性是99.976%。
再来计算硬盘存储数据的可靠性(注意这里仅仅考虑了硬盘本身故障的因素,目的是举例说明t M T B F _{MTBF} MTBF的意义,不是严肃的可靠性估计)。为了便于计算,假设硬盘的年故障率是3.65%,更换坏硬盘并重建数据需要24小时。一块硬盘在24小时内坏掉的可能性约是0.01%(即10 − 4 ^{-4} −4)。如果我们按GFS(Google File System,谷歌公司开发的分布式文件系统,旨在为大规模数据存储和处理提供高性能、可靠性和可扩展性)的思路把数据存3份,在一块硬盘坏掉之后,立刻用另外两份拷贝开始在空余的硬盘上重建数据。那么在接下来的24小时里,另外两份拷贝同时坏掉的可能性是10 − 8 ^{-8} −8。在一年之内,某一块数据丢失的可能性是3.65×10 − 10 ^{-10} −10(有一块硬盘在一年内坏掉,同时另外两份拷贝也在24小时内都坏掉)。换言之,数据的可靠性(durability)是9个9。要想进一步提高可靠性,可行的方法有两个:一是提高冗余,比如每块数据存6份;二是降低重建数据的时间,比如把更换并重建硬盘的时间降为12小时(通过千兆网全速复制一个2TB的SATA硬盘的全部数据约需6小时)。
前面考虑的是从客户的角度看某一块指定的数据不丢失的概率,如果从存储服务端的角度考虑系统全部数据都不丢失的概率,情况就大不一样了。假设一个硬盘每天坏掉的概率为p,一共有n块硬盘,一天之内恰好坏掉k块硬盘的概率满足二项分布:
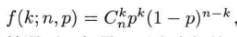
其中:
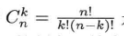
上式是二项式系数。在3份数据冗余的情况下,如果一天之内坏掉3块以上的硬盘,就有可能丢数据。因为如果有某块数据的3份冗余正好位于这3块坏掉的硬盘,那么这块数据就丢失了。因此不出现数据丢失的概率是(此处有误,不出现数据丢失的概率不等于坏掉的硬盘数小于3的概率和,当坏掉的硬盘数量大于等于3时,也有可能不丢失数据,此处的概率是数据一定不会丢失数据的概率,实际不出现数据丢失的概率,即可靠性,更高):
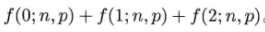
把p=10
−
4
^{-4}
−4,n=100,1000,10000分别带入公式,可知当n=100时,数据的可靠性接近100%;当n=1000时,数据可靠性为99.985%;而当n=10000时,数据的可靠性降为91.971%,即每天有8.029%的概率出现3块以上硬盘同时损坏的情况。如果某个有10000个硬盘的存储系统连续运行一个月,那么几乎肯定会遇到某天坏掉3块硬盘的情况出现,连续运行一年,几乎肯定会遇到数据丢失的情况出现。如果磁盘总数n继续增大,数据的总可靠性迅速降低。在无法改变磁盘故障率p的情况下,如果基于GFS思路不变,那么增加数据的冗余份数和降低重建数据的时间是提高可靠性的两个可行办法。
这看似矛盾的结果其实也很容易理解:一个人买一张彩票中头奖的概率是几百万分之一,一期彩票有几百万人购买,那么几乎每期都能开出头奖来。
可靠性与可用性(availability)(《Why Do Computers Stop and What Can Be Done About it?》http://www.hpl.hp.com/techreports/tandem/TR-85.7.pdf)是两码事,可靠性指的是数据不丢失的概率,可用性指的是数据或服务能被随时访问到的概率。可用性=t M T B F _{MTBF} MTBF/(t M T B F _{MTBF} MTBF+t M T T R _{MTTR} MTTR),其中t M T T R _{MTTR} MTTR是平均修复时间。因此为了提高可用性,提高t M T B F _{MTBF} MTBF和降低t M T T R _{MTTR} MTTR都是可行的。例如假设某服务的t M T B F _{MTBF} MTBF短到只有24小时,但t M T T R _{MTTR} MTTR做到10秒,可用性还是高达99.988%。
值得一提的是,前面只考虑了硬盘整体故障,没有考虑数据读写错误(《Understanding latent scetor errors and how to protect against them》,http://storagemojo.com/2010/03/05/storagemojos-best-paper-of-fast-10)。普通SATA硬盘的误码率(bit error rate)约是10 − 14 ^{-14} −14,也就是说大约每读12TB的数据就会遇到有数据读不出来(这大大影响了RAID5的可用性,http://www.zdnet.com/blog/storage/why-raid-5-stops-working-in-2009/162)。磁盘带宽按100MB/s算,那么持续全速读33小时就会出现这种错误。而ECC内存的可靠度远高于硬盘,大约每年有1.3%的机器会遇到不可恢复的内存故障(《DRAM errors in the wild: A Large-Scale Field Study》)。因此在没有使用RAID的廉价服务器上,应该关闭swap分区,避免因磁盘读写错误而损害非存储业务的可靠性。
单机易坏的部件通常都有廉价的冗余方案(双电源、热插拔硬盘、双口网卡),但是其余的核心部件(主板(某款Intel服务器主板的t M T B F _{MTBF} MTBF在10万至20万小时之间,与环境温度相关)、CPU、内存(每条ECC内存条每年出现不可恢复的错误的概率是0.22%。ECC内存能纠正单bit错误,检测双bit错误,即SECDED(Single Error Correction, Double Error Detection)。如果出现多bit同时翻转,ECC无能为力))没有廉价的热插拔方案,出现故障必须停机修复。如此看来,分布式系统中服务器硬件的可靠性并不如想象中高(有报告称某x86服务器的t M T B F _{MTBF} MTBF是5万小时)(高端IBM System z的t M T B F _{MTBF} MTBF是35万小时(http://en.wikipedia.org/wiki/IBM_System_z),普通PC台式机的t M T B F _{MTBF} MTBF是3万小时,那么PC服务器的t M T B F _{MTBF} MTBF按5~10万小时估算似乎是合理的),如果服务器的t M T B F _{MTBF} MTBF是10万小时,在100台服务器组成的分布式系统中,每个月出现一次服务器硬件故障的可能性略大于50%。
这还没有考虑需要停机维护的其他原因,包括机器搬动、空调故障、供电故障、网络交换机或路由器故障、机房进水或漏雨、操作系统或其他系统软件(固件)的安全补丁等等。因此,在设计分布式系统的时候,要把这些硬件和环境的不可靠因素考虑进去,避免制定出不切实际的单机软件可靠性指标(7×24是overkill,即过高的)。考虑了硬件不可靠的因素,实际上能降低软件的编码难度。
硬件故障固然不可避免,不过软件故障和人为故障往往更容易制造麻烦。软件故障的很大一部分是资源不足,例如内存耗尽、硬盘写满、网络带宽占满,以及文件描述符或i-node用完等。应对这种故障的办法是持续监控并报警,必要时自动或人工干预。有了这样的监控系统,也能减轻应用程序开发的负担,比如日志库就不必在意磁盘是否写满,因为机器上肯定有监测磁盘剩余空间的程序。
9.2.1 分布式系统的软件不要求7×24可靠
运行在一台机器(设备)上的软件的可靠性受限于硬件,如果硬件本身的可靠性不高,那么软件做得再可靠也没有意义。自己开发的软件的可靠性只需要略高于硬件及操作系统即可,即“不当木桶的短板”。学软件(计算机科学系)出身的人往往认为硬件不会坏,而学硬件(电子信息系)出身的人一般都认为硬件不会坏才怪。半导体器件是非常娇弱的,宇宙射线的中子和集成电路封装材料中的同位素衰变产生的α-粒子在击中硅片时会释放能量,有可能影响储能器件的“状态”,造成bit翻转(http://en.wikipedia.org/wiki/Soft_error,http://people.rit.edu/lffeee/lec_reli.pdf第23页)。
前面分析过,如果一台服务器的t M T B F _{MTBF} MTBF是10万小时,连续运行一年出现故障的概率是8.4%;如果一台网络交换机的t M T B F _{MTBF} MTBF是20万小时,它连续运行一年出现故障的概率是4.3%。在编写单机服务软件或网络交换机固件的时候,程序应该尽量可靠(7×24),要能连续稳定运行一年才不会影响系统的可靠性。
但是,在一个100台服务器规模的分布式系统中,每个月出现一次硬件故障的概率是51.3%;在一个1000台服务器规模的分布式系统中,每周出现硬件故障的概率是81.4%。在开发运行于这些硬件上的分布式服务软件时,要求单个程序“连续稳定运行一年”是做无用功。如果一年之内因为硬件或操作失误造成10次停机,软件故障造成两次停机,消除这两次软件故障并不能有效地提高系统的可靠性。
要求分布式中的单个服务“7×24不停机”通常是错误地理解了需求与约束。高可用的关键不在于做到不停机;恰恰相反,要做到能随时重启任何一个进程或服务。通过容错策略让系统保持整体可用,关键是要设计合理的协议来避免对单机过高的可靠性要求。只要重启或故障转移(failover)的时间足够短(秒级),则可用性仍然相当高。要设法从架构上搬掉这块“绊脚石”,通过多机协作达到可用性指标。在不可靠的硬件上,只有通过软件手段来提高系统的整体可用度。比方说9.1.2举的Thumbnailer就不必做到7×24,通过合理的设计协议,任何一个Thumbnailer都可以随时重启。
如果真要7×24连续运行,应该有明确的t M T B F _{MTBF} MTBF指标。另外,6.9×24行不行?7×23.9行不行(据作者所知,在金融领域,证券行业的服务程序必要的话可以每天重启,因为收市之后无交易;外汇交易的服务器可以每周重启,因为周末无交易)?对于非性命攸关的系统,在星期天凌晨3点短暂不可用会有多大的实际影响呢?
既然预料到硬件会出现故障,就能避免不切实际的软件可靠性指标。对于分布式系统中的进程来说,考虑到平均一两个月就会有程序版本更新,那么进程能连续运行数星期就可算达标了,软件升级的时候反正还是要重启进程的(在运行期热替换DLL(Dynamic Link Library,动态链接库,是一种Windows操作系统中常用的文件类型,DLL是包含已编译的代码和数据的文件,它可被多个程序同时使用,并提供了一种灵活和可重用的方式来共享代码和资源)通常是走火入魔的标志;真的需要在运行时替换程序逻辑的话,可以用嵌入脚本语言,把代码转换为数据。例如9.7介绍的用Groovy编写测试逻辑)。
以上理由不是给写出低质量代码找开脱的借口,而是说在编程的时候,不必纠结于想尽一些办法防止程序崩溃。这样可以简化错误处理,用最自然的方式编写C++代码,该new的就new,该用STL就用,不要视动态分配内存为“洪水猛兽”。不要把时间浪费在解决错误的问题(西谚有云:“Wait until you have a problem before you look for a solution.”),应集中精力应付更本质的业务问题。
比方说,对于某些资源耗尽的错误可以简化处理,在编写64-bit程序时也可以不必在意内存碎片(理由见A.1.8)。遇到某些发生概率很小的严重错误事件时,可以直接退出进程,举例来说:
1.如果初始化mutex失败,直接退出进程好了,反正程序也无法正确执行下去。
2.一般的程序(指非内存数据库、memcached之类的以内存为主要资源的程序)不必在意内存分配失败,遇到这种情况直接退出即可。一方面是在程序分配内存失败之前,资源监控系统应该已经报警(对于32-bit程序,在进程内存使用超过2GB时;对于64-bit程序,当空闲物理内存少于20%时),实施负载迁移;另一方面,如果真遇到std::bad_alloc异常,也没有特别有效的办法来应对(C++ new_handler(用于处理内存分配失败的情况,当使用new操作符分配内存时,如果内存不足或分配失败,C++会调用new_handler来尝试处理这种情况)在多线程中的作用非常有限,因为在多线程中,多个线程可以同时访问和修改堆上的内存,如果多个线程同时使用new_handler分配内存,可能会导致内存分配的竞争条件)。
3.程序也不必考虑磁盘写满(仅考虑写诊断日志这一种用途。分布式存储系统自然要设法应对磁盘写满的这一情况),因为在磁盘写满之前,监控系统已经报警(在磁盘空间使用量达到80%、90%、95%、99%时以不同级别报警)。如果是关键业务,必然已经有人采取必要的措施来腾出磁盘空间。
9.2.2 “能随时重启进程”作为程序设计目标
既然硬件和软件条件都不需要(不允许)程序长期运行,那么程序在设计的时候必须想清楚重启进程的方式与代价。进程重启大致可分为软硬件故障导致的意外重启与软硬件升级引起的有计划主动重启。无论是哪种重启,都最好让最终用户感觉不到程序在重启。重启耗时应尽量短,中断服务的时间也尽量短,或者最好能做到根本不中断服务。重启进程之后,应该能自动恢复服务,最好避免需要手动恢复。
《Google File System》论文(http://research.google.com/archive/gfs-sosp2003.pdf)第5.1.1节“Fast Recovery”提到:“Both the master and the chunkserver are designed to restore their state and start in seconds no matter how they terminated. In fact, we do not distinguish between normal and abnormal termination; servers are routinely shut down just by killing the process.”
以上说明,由于不必区分进程的正常退出与异常终止,程序也就不必做到能安全退出,只要能安全被杀即可。这大大简化了多线程服务端编程,我们只需关心正常的业务逻辑,不必为安全退出进程费心。
无论是程序主动调用exit(3)或是被管理员kill(1),进程都能立即重启。这就要求程序只使用操作系统能自动回收的IPC,不使用生命期大于进程的IPC,也不使用无法重建的IPC。具体说,只用TCP为进程间通信的唯一手段,进程一退出,连接与端口自动关闭。而且无论连接的哪一方断联,都可以重建TCP连接,恢复通信。
不要使用跨进程的mutex或semaphore,也不要使用共享内存,因为进程意外终止的话,无法清理资源,特别是无法解锁。另外也不要使用父子进程共享文件描述符的方式来通信(pipe(2)),父进程死了,子进程怎么办?pipe是无法重建的。
意外重启的常见情况及其原因是:
1.服务进程本机重启:程序bug或内存耗尽。
2.机器重启:kernel bug,偶然硬件错误。
3.服务进程移机重启:硬件/网络故障。
协议设计时应该要求客户端在TCP连接断开后能自动重连,muduo的TcpClient自带此功能。但在某些故障中客户端不能立刻收TCP断开的消息,因此也要求客户端检测服务端心跳,并能自动failover到备用地址(9.3)。但是换机器的话,如何通知客户端(9.8.4)?
如何优雅地重启?对于计划中的重启,一般可以采取以下步骤:
1.先主动停止一个服务进程心跳:
(1)对于短连接,关闭listen port,不会有新请求到达。
(2)对于长连接,客户会主动failover到备用地址或其他活着的服务端。
2.等一段时间,直到该服务进程没有活动的请求。
3.kill并重启进程(通常是新版本)。
4.检查新进程的服务正常与否。
5.依次重启服务端剩余进程,可避免中断服务。
除了要求客户端能正确处理心跳和TCP重连,还要求客户端能同时兼容旧版本的服务端协议(9.6)。
升级9.1.2提到的Thumbnailer服务就可以采取这个办法,完全可以做到不中断服务,因为每步只杀掉一个Thumbnailer进程,缩略图服务始终是可用的。如果要升级Web服务器,可以考虑Joshua Zhu介绍的Nginx热升级办法。
另外一种升级软件的做法是“迁移”。先启动一个新版本的服务进程,然后让旧版本的服务进程停止接受新请求,把所有新请求都导向新进程。这样一段时间之后,旧版本的服务进程上已经没有活动请求,可以直接kill进程,完成迁移和升级。在此升级过程中服务不中断,每个用户不必在意自己是连接到新版本还是旧版本的服务。一些看似不能中断的服务可以采用这种方式升级,因为单个请求的时长总是有限的。
扯远一句,火星探路者(pathfinder)也经历过真正的远程重启(http://www.drdobbs.com/a-conversation-with-glenn-reeves/184411097),发生在距离地球几亿千米的火星上。
9.3 分布式系统中心跳协议的设计
前面提到使用TCP连接作为分布式系统中进程间通信的唯一方式,其好处之一是任何一方进程意外退出的时候对方能及时得到连接断开的通知,因为操作系统会关闭进程中的TCP socket,会往对方发送FIN分节(TCP segment)。尽管如此,应用层的心跳还是必不可少的。原因有:
1.如果操作系统崩溃导致机器重启,没有机会发送FIN分节。
2.服务器硬件故障导致机器重启,也没有机会发送FIN分节。
3.并发连接数很高时,操作系统或进程如果重启,可能没有机会断开全部连接。换句话说,FIN分节可能出现丢包,但这时没有机会重试。
4.网络故障,连接双方得知这一情况的唯一方案是检测心跳超时。
为什么TCP keepalive不能替代应用层心跳?心跳除了说明应用程序还活着(进程还在,网络通畅),更重要的是表明应用程序还能正常工作。而TCP keepalive由操作系统负责探查,即使进程死锁或阻塞,操作系统也会如常收发TCP keepalive消息。对方无法得知这一异常。
心跳协议的基本形式是:如果进程C依赖S,那么S应该按固定周期向C发送心跳(心跳就像看门狗(watch dog)电路,只有不断的逗狗才能防止电路复位(reset),看门狗电路通常是一个计时器,定期接收来自系统的“喂狗”信号,如果系统正常运行,就会定期发送这个信号,以表明系统仍在工作,如果由于某种原因系统出现故障、死锁或停滞,就无法发送“喂狗”信号,看门狗电路会认为系统处于异常状态,并采取相应的措施),而C按固定的周期检查心跳。换言之,通常是服务端向客户端发送心跳,例如9.1.2提到的Thumbnailer服务应该向Web Server定期发送心跳,如图9-6所示。
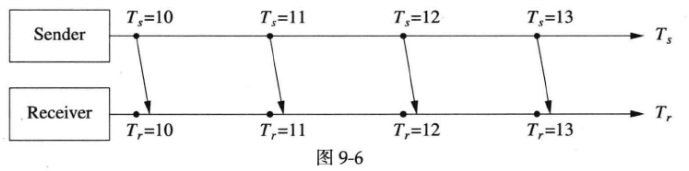
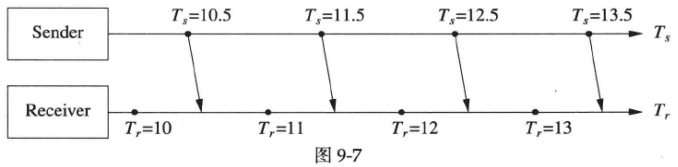
图9-6中Sender以1秒为周期向Receiver发送心跳消息,而Receiver以1秒为周期检查心跳消息。注意到Sender和Receiver的计时器是独立的,因此可能会出现图9-7所示的“发送和检查时机不对齐”情况,这是完全正常的。
心跳的检查也很简单,如果Receiver最后一次收到心跳消息的时间与当前时间之差超过某个timeout值,那么就判断对方心跳失效。例如Sender所在的机器在T
s
_{s}
s=11.5时刻崩溃,Receiver在T
r
_{r}
r=12时刻检查心跳是正常的,在T
r
_{r}
r=13时刻发现过去timeout秒之内没有收到心跳消息,于是判断心跳失效(图9-8)。注意到这距离实际发生崩溃的时刻已过去了1.5秒,这是不可避免的延迟。分布式系统没有全局瞬时状态,不存在立刻判断对方故障的方法,这是分布式系统的本质困难(9.1.1)。
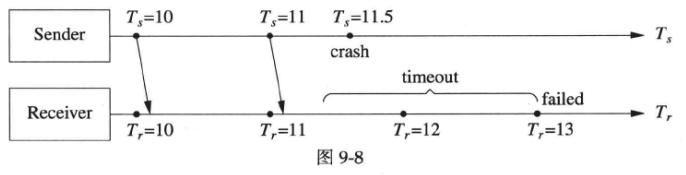
如果要保守一些,可以在连续两次检查都失效的情况下认定Sender已无法提供服务,但这种方法发现故障的延迟比前一种方法要多一个检查周期。这反映了心跳协议的内在矛盾:高置信度与低反应时间不可兼得。
现在的问题是如何确定发送周期、检查周期、timeout这三个值。通常Sender的发送周期和Receiver的检查周期相同,均为T
c
_{c}
c;而timeout>T
c
_{c}
c,timeout的选择要能容忍网络消息延时波动和定时器的波动。图9-9中T
s
_{s}
s=12.1发出的消息由于网络延迟波动,错过了检查点,如果timeout过小,会造成误报。
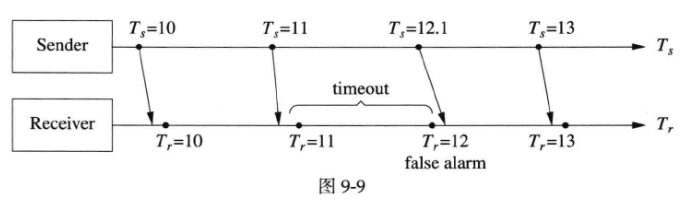
尽管发送周期和检查周期均为T
c
_{c}
c,但无法保证每个检查周期内恰好收到一条心跳,有可能一条也没有收到。因此为了避免误报(false alarm),通常可取timeout=2T
c
_{c}
c。
T c _{c} c的选择要平衡两方面因素:T c _{c} c越小,Sender和Receiver单位时间内处理的心跳消息越多,开销越大;T c _{c} c越大,Receiver检测到故障的延迟也就越大。在故障延迟敏感的场合,可取T c _{c} c=1s,否则可取T c _{c} c=10s。总结一下心跳的判断规则:如果最近的心跳消息的接收时间早于now-2T c _{c} c,可判断心跳失效。
心跳消息应该包含发送方的标识符,可按9.4的方式确定分布式系统中每个进程的唯一标识符。建议也包含当前负载,便于客户端做负载均衡。由于每个程序对“负载”的定义不同,因此心跳消息的格式也就各不相同。作者认为可以在某些公共字段的基础上增加应用程序的特定字段,而不要强行规定全部程序都用相同的心跳消息格式。
以上是Sender和Receiver直接通过TCP连接发送心跳的做法,如果Sender和Receiver之间有其他消息中转进程,那么还应该在心跳消息中加上Sender的发送时间,防止消息在传输过程中堆积而导致假心跳(见图9-10)。相应的判断规则改为:如果最近的心跳消息的发送时间早于now-2T
c
_{c}
c,心跳失效。使用这种方式时,两台机器的时间应该都通过NTP协议与时间服务器同步,否则几秒的时钟差可能造成误判心跳失效,因为Receiver始终收到的是“过去”发送的消息(作者曾经见过x86服务器上的集成显卡的驱动有bug,偶到导致机器的时间发生跳变(这跟当时Linux内核的时钟管理机制有关),造成某台机器的时间大大超前于其他机器(几秒),这台机器上的进程会认为它收到的心跳都是失效的。这时可以用ntpdate(1)命令强制同步时间,即可立刻修复故障)。

考虑到闰秒的影响,T
c
_{c}
c小于1秒是无意义的,因为闰秒会让两台机器的相对时差发生跳变,可能造成误报警,如图9-11所示(Sender不会发生闰秒跳变的情况):
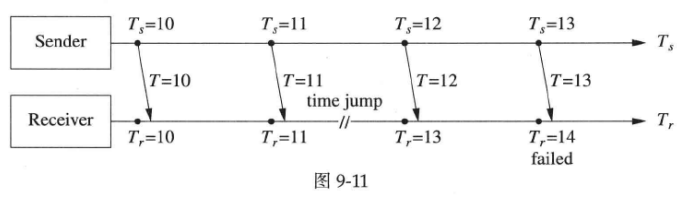
计算机的计时是UTC时间,UTC时间会受闰秒的影响,它不是完全均匀流逝的。目前闰秒的插入点是在每年的固定日期(12月31日或6月30日),不考虑星期几。这会对日常生活(特别是电子化交易)造成影响。作者认为应该修改规则,在年末或年中的某个星期日凌晨(GMT时区,格林威治标准时间 )插入闰秒,避免在交易时段出现时间跳变。NTP协议对闰秒的处理也比较僵硬,基本采取暂停时钟的办法来插入闰秒,这会造成分布式系统中两台机器在发生闰秒时出现时间差,即便它们的时钟都是和NTP服务器对准的。在分布式系统中,有时我们需要特别处理这一问题,尤其在设计容错协议的时候,见Google的一篇blog(http://googleblog.blogspot.hk/2011/09/time-technology-and-leaping-seconds.html)。
心跳协议还有两个实现上的关键点:
1.要在工作线程发送,不要单独起一个“心跳线程”。
2.与业务消息用同一个连接,不要单独用“心跳连接”。
这么做的原因是为了防止伪心跳。
对于第1点,这是防止工作线程死锁或阻塞时还在继续发心跳。对于采用第六章方案5的单线程服务程序,应该用EventLoop::runEvery()注册周期性定时器回调,在回调函数中发送心跳消息。对于采用方案8的多线程服务器,应该用EventLoop::runEvery()注册周期性定时器回调,在回调函数中往线程池post一个任务,该任务会发送心跳消息。这样就能有效地检测工作线程死锁或阻塞的情况。对于方案9和方案11也可以采取类似的办法,对多个EventLoop轮流调用runInLoop(),以防止某个业务线程(即业务所属的IO线程)死锁还继续发送心跳。
对于第2点,心跳消息的作用之一是验证网络畅通,如果它验证的不是收发业务数据的TCP连接畅通,那其意义就大为缩水了。特别要避免用TCP做业务连接,用UDP发送心跳消息,防止一旦TCP业务连接上出现消息堆积而影响正常业务处理时,程序还一如既往地发送UDP心跳,造成客户端误认为服务可用。《Release It》一书第4.1节“The 5 a.m. Problem”讲了一个生动的例子,用于描述心跳也是合适的。这个例子说的是Sender和Receiver位于两个数据中心,之间有网络防火墙。网络防火墙的一个特点是会自动检测TCP死连接,即长期没有消息往来的TCP连接,并清除内存中的连通规则(即认为这个连接不再联通,不会再为此连接转发包)。原来的程序通过单独的TCP连接发送心跳,与业务数据不在同一TCP连接。由于心跳始终在周期性地发送,因此,防火墙认为这个TCP连接是活动的。但是业务连接在每天晚上有很长一段时间没有数据交互,防火墙就判断其为死连接,并且不再转发此连接的IP packet。尽管Sender和Receiver还认为这个TCP业务连接活着,但防火墙实际上已经让连接断开了。当每天早上5点钟第一笔订单进来的时候,始终会出现超时错误,因为业务连接的TCP segment无法到达对方。TCP协议要经过很长一段时间才能真正判断连接断开(相当于中途断网,TCP会重试很多次),这时只有重启一方的进程才能快速修复错误。当把心跳消息放到业务连接上之后,问题就迎刃而解了。
9.4 分布式系统中的进程标识
本节假定一台机器(host)只有一个IP,不考虑multihome的情况(如果要考虑multihome,把文中的IP换为hostname即可,结论一样成立)。同时假定分布式系统中的每一台机器都正确运行了NTP,各台机器的时间大体同步。
“进程(process)”是操作系统的两大基本概念之一,指的是在内存中运行的程序。在日常交流中,“进程”这个词通常不止这一个意思。有时候我们会说“httpd进程”或者“mysqld进程”,指的其实是program,而不一定是特指某一个“进程”——某一次fork()系统调用的产物。一个“httpd进程”重启了,它还是“一个httpd进程”。本文讨论的是,如何为一个程序每次运行的进程取一个唯一标识符。也就是说,httpd程序第一次运行,进程是httpd_1,它原地重启了,进程是httpd_2。
本节所指的“进程标识符”是用来唯一标识一个程序的“一次运行”的。每次启动一个进程,这个进程应该被赋予一个唯一的标识符,与当前正在运行的所有进程都不同;不仅如此,它应该与历史上曾经运行过,目前已消亡的进程也都不同(这两条的直接推论是,与将来可能运行的进程也都不同)。“为每个进程命名”在分布式系统中有相当大的实际意义,特别是在考虑failover的时候。因为一个程序重启之后的新进程和它的“前世进程”的状态通常不一样,凡是与它打交道的其他进程最好能通过它的进程标识符变更来很容易地判断该程序已经重启,而采取必要的救灾措施,防止搭错话。
本节先假定每个服务端程序的端口是静态分配的,在公司内部有一个公用wiki来记录端口和程序的对应关系(然后通过NIS(Network Information Service,一种网络信息服务,是UNIX和类UNIX系统中用于管理用户账户、密码、组信息等的分布式数据库系统,它允许多台计算机共享这些信息,使得用户可以在任意一台主机上进行认证和访问)或DNS发布)。比如端口11211始终对应memcached,其他程序不会使用11211端口;3306始终留给mysqld;3690始终留给svnserve。在分布式系统的初级阶段,这是通常的做法;到了高级阶段,多半会用动态分配端口号(9.8),因为端口号只有6万多个,是稀缺资源,在公司内部也有分配完的一天。
我们假定在一台机器上,一个listening port同时只能由一个进程使用,不考虑古老的listen()+fork()模型(多个进程可以accept同一个端口上进来的连接)。关于这点作者已经写了很多,见第3章。本书只考虑TCP协议,不考虑UDP协议,“端口”指的都是TCP端口。
9.4.1 错误做法
在分布式系统中,如何指涉(refer to)某一个进程呢,或者说一个进程如何取得自己的全局标识符(以下简称gpid)?容易想到的有两种做法:
1.ip:port(port是这个进程对外提供网络服务的端口号,一般就是它的listening port)。
2.host:pid。
而这两种做法都有问题。为什么?
如果进程本身是无状态的,或者重启了也没有关系,那么用ip:port来标识一个“服务”是没问题的,比如常见的httpd和memcached都可以用它们的惯用port(80和11211)来标识。我们可以在其他程序里安全地引用(refer to)“运行在10.0.0.5:80的那个HTTP服务器”,或者“10.0.0.6:11211的memcached”,就算这两个service重启了,也不会有太恶劣的后果,大不了客户端重试一下,或者自动切换到备用地址。
如果服务是有状态的,那么ip:port这种标识方法就有大问题,因为客户端无法区分从头到尾和自己打交道的是一个进程还是先后多个进程。如果客户端和服务端直接通过TCP相连,那么可以获知进程退出引发的连接断开事件。但是如果客户端与服务端之间用某种消息中间件来回转发消息,那么客户端必须通过进程标识才能识别服务端。在开发服务端程序的时候,为了能快速重启,我们一般都会设置SO_REUSEADDR,这样的结果是前一秒站在10.0.0.7:8888后面的进程和后一秒占据10.0.0.7:8888的进程可能不相同——服务端程序快速重启了。
比方说,考虑一个类似GFS的分布式文件系统的master,如果它仅以ip:port来标识自己,然后它向shadows(不是chunk server,shadows是与主节点master相连的备用节点或镜像节点,这些影子节点的目的是在主节点失效或不可用时提供冗余和容错能力,而chunk server是存储实际文件数据的节点)下达同步指令(即将文件系统的数据变更传播给备用节点,以确保数据的可靠性和一致性),那么shadows如何得知master是不是已经重启呢?发指令的事master的“前世”还是“今生”?是不是应该拒绝“前世”的遗命?
考虑如果改成host:pid这种标识方式会不会好一点?作者认为换汤不换药,因为pid的状态空间很小,重复的概率比较大。比如Linux的pid的最大值默认(/proc/sys/kernel/pid_max)是32768,一个程序重启之后,获得与“前世”相同pid的概率是1/32768。或许有读者不相信重启之后pid会重复,理由是因为pid是递增的,遇到上限再回到目前空闲的最小pid。考虑一个服务端程序A,它的pid是1234,它已经稳定运行了好几天,这期间,pid已经增长了几个轮回(因为这台机器时常会启动一些后台脚本执行一些辅助工作)。在A崩溃的前一刻,最近被使用的pid已经回到了1232,当A崩溃之后,某个守护进程启动一个脚本(pid=1233)来清理A的log,然后再重启A程序;这样一来,重启之后的A程序的pid碰巧和它的前世相同,都是1234。也就是说,用host:pid不能唯一标识进程。
那么合在一起,用ip:port:pid呢?也不能做到唯一。它和host:pid面临的问题是一样的,因为ip:port这部分在重启之后不会变,pid可能轮回。
作者猜这时有人会想,建一个中心服务器,专门分配系统的gpid好了,每个进程启动的时候向它询问自己的gpid。这错得更远:这个全局pid分配器的gpid由谁来定?如何保证它分配的gpid不重复(考虑这个程序也可能意外重启)?它是不是成为系统的single point of failure?如果要对该gpid分配器做容错,是不是面临分布式系统的基本问题:状态迁移(即一个节点出现故障或者需要进行容错处理时,需要将这个节点的状态迁移到其他节点上,以保证整个系统的正常运行)?
还有一种办法,用一个足够强的随机数做gpid,这样一来确实不会重复,但是这个gpid本身也没有多大额外的意义,不便于管理和维护,比方说根据gpid找到是哪个机器上运行的哪个进程。
9.4.2 正确做法
正确做法:以四元组ip:port:start_time:pid作为分布式系统中进程的gpid,其中start_time是64-bit整数,表示进程的启动时刻(UTC时区,从Unix Epoch到现在的微秒数,muduo::Timestamp)。理由如下:
1.容易保证唯一性。如果程序短时间重启,那么两个进程的pid必定不重复(还没有走完一个轮回:就算每秒创建1000个进程,也要30多秒才会轮回,而以这么高的速度创建进程的话,服务器已基本瘫痪了);如果程序运行了相当长一段时间再重启,那么两次启动的start_time必定不重复。
2.产生这种gpid的成本很低(几次低成本系统调用),没有用到全局服务器,不存在single point of failure。
3.gpid本身有意义,根据gpid立刻就能知道是什么进程(port),运行在哪台机器(IP),是什么时间启动的,在/proc目录中的位置(/proc/pid)等,进程的资源使用情况也可以通过运行在那台机器上的监控程序报告出来。
4.gpid具有历史意义,便于将来追溯。比方说进程crash,那么我知道它的gpid,就可以去历史记录中查询它crash之前的CPU和内存负载有多大。
如果仅以ip:port:start_time作为gpid,则不能保证唯一性,如果程序短时间重启(间隔一秒或几秒),start_time可能会往回跳变(NTP在调时间)或暂停(正好处于闰秒期间)。
没有port怎么办?一般来说,一个网络服务程序会侦听某个端口来提供服务,如果它是个纯粹的客户端,只主动发起连接,没有主动侦听端口,gpid该如何分配呢?根据9.5的观点,分布式系统中的每个长期运行的、会与其他机器打交道的进程都应该提供一个管理接口,对外提供一个维修探查通道,可以查看进程的全部状态。这个管理接口就是一个TCP server,它会侦听某个port。
使用这样的维修通道的一个额外好处是,可以自动防止重复启动程序。因为如果重复启动,bind到那个运维port的时候会出错(端口已被占用),程序会立刻退出。更妙的是,不用担心进程crash没来得及清理锁(如果用跨进程的mutex就有这个风险),进程关闭的时候操作系统会自动把它打开的port都关上,下一个进程可以顺利启动。
进一步,还可以把程序的名称和版本号作为gpid的一部分,这起到锦上添花的作用。
有了唯一的gpid,那么生成全局唯一的消息id字符串也十分简单,只要在进程内使用一个原子计数器,用计数器递增的值和gpid即可组成每个消息的全局唯一id。这个消息id本身包含了发送者的gpid,便于追溯。当消息被传递到多个程序中,也可以根据gpid追溯其来源。
9.4.3 TCP协议的启示
本节讲的这个gpid其实是由TCP协议启发而来的。TCP用ip:port来表示endpoint,两个endpoint构成一个socket。这似乎符合一开始提到的以ip:port来标识进程的做法。其实不然。在发起TCP连接的时候,为了防止前一次同样地址的连接(相同的local_ip:local_port:remote_ip:remore_port)的干扰(称为wandering duplicate,即流浪的packets),TCP协议使用seq号码(这种在SYN packet里第一次发送的seq号码称为initial sequence number,ISN)来区分本次连接和以往的连接。TCP的这种思路与我们防止进程的“前世”干扰“今生”很相像。内核每次新建TCP连接的时候会设法递增ISN以确保与上次连接最后使用的seq号码不同。相当于说把start_time加到了endpoint之中,这就很接近我们后面提到的“正确的gpid”做法了(当然,原始BSD 4.4的ISN生成算法有安全漏洞,会导致TCP sequence prediction attack,Linux内核已经采用更安全的办法来生成ISN)。
9.5 构建易于维护的分布式程序
本节标题中的“易于维护”指的是supportability,不是maintainability。前者是从运维人员的角度说,程序管理起来很方便,日常的劳动负担小;后者是从开发人员的角度说,代码好读好改。
在《分布式系统的工程化开发方法》(http://blog.csdn.net/solstice/article/details/5950190)演讲中作者提到了一个观点:分布式系统中的每个长期运行的、会与其他机器打交道的进程都应该提供一个管理接口,对外提供一个维修探查通道,可以查看进程的全部状态。一种具体的做法是在程序里内置HTTP服务器,能查看基本的进程健康状态与当前负载,包括活动连接及其用途,能从root set(可能指的是系统中的一组核心对象或节点,这些对象或节点是整个系统状态的起点)开始查到每一个业务对象的状态。这种做法类似Java的JMX(Java Management Extensions,是一种为Java应用程序添加管理和监控功能的标准API),又类似memcached的stats命令(可以获取有关memcached服务器当前状态和性能的详细信息)。
这里展开谈一谈这么做的必要性。分成两个方面来说:一、在服务程序内置监控接口的必要性;二、HTTP协议的便利性。
必要性
在程序中内置监控接口可以说是受了Linux procfs(/proc文件系统,是 Linux 操作系统中的一种虚拟文件系统,它提供了一种访问内核信息和进程信息的机制)的启发。在Linux下,查看内核的状态不需要任何特殊的工具,只要用ls和cat在/proc目录下查看文件就行了。要知道当前系统中运行了哪些进程、每个进程都打开了哪些文件、进程的内存和CPU使用情况如何、每个进程启动了几个线程、当前有哪些TCP连接、每个网卡收发的字节数等等,都可以在/proc中找到答案。Linux Kernel通过procfs这么一个探查接口把状态充分暴露出来,让监控操作系统的运行变得容易。
但是procfs也有两点明显的不足:
1.它只能暴露system-wide的数据,不能查看每个进程内部的数据。
2.它是本地文件系统,必须登录到这台机器上才能查看,如果要管理很多台机器,势必增加工作量。
对于第一点,举例来说,我想知道某个我们自己编写的服务进程的运行情况:
1.到目前为止累计接受了多少个TCP连接。
2.当前有多少活动连接(这个可以通过procfs查看)。
3.每个活动连接的用途是什么。
4.一共响应了多少次请求。
5.每次请求的平均输入输出数据长度是多少字节。
6.每次请求的平均响应时间是多少毫秒。
7.进程平均有多少个活动请求(并发请求)。
8.并发请求数的峰值是多少,出现在什么时候。
9.某个连接上平均有多少个活动请求(指在一段时间窗口内,平均有多少个活动请求)。
10.进程中XXXRequest对象有多少份实体。
11.进程中打开了多少个数据库连接,每个连接的存活时间是多少。
12.程序中有一个hashmap,保存了当前的活动请求,我想把它打印出来。
13.某个请求似乎卡在某个步骤了,我想打印进程中该请求的状态。
这些正当需求只有通过程序主动暴露状态才能满足;否则,就算ssh登录到这台机器上,也看不到这些有用的进程内部信息(总不能gdb attach吧?那就让服务进程暂停响应了。且不说gdb打印一个hashmap有多麻烦)。
便利性
如果程序要主动暴露内部状态,那么以哪种方式最为便利呢?当然是HTTP。HTTP的好处如下:
1.它是TCP server,可以远程访问,不必登录到这台机器上。
2.TCP server的另一个好处是能安全方便地防止程序重复启动,这一点在9.4已有论述。
3.最基本的HTTP协议实现起来很简单,不会给服务端程序带来多大负担,见muduo::net::HttpServer的例子。
4.不必使用特定的客户端程序,用普通Web浏览器就能访问。
5.可以比较容易地用脚本语言实现客户端,便于自动化的状态收集与分析。
6.HTTP是文本协议,紧急情况下在命令行用curl/wget甚至telnet也能访问(比方说你在家通过ssh连到公司服务器解决某个线上问题,这时候没有Web浏览器可用)。
7.借助URL路径区分,很容易实现有选择地查看一些信息,而不是把晋城的全部状态一股脑儿全dump出来,见muduo::net::Inspector的例子,如http://host:port/request/xxx表示ID为xxx的请求的状态。
8.HTTP天生支持聚合(指将多个资源合并为一个),一个浏览器页面可以内置多个iframe(每个iframe可以独立加载网页内容,即独立加载不同的资源、页面或应用),一眼就能看清多个进程的状态。
9.除了GET method,如果有必要,还可以实现PUT/POST/DELETE,通过HTTP协议来控制并修改进程的状态,让程序“能观能控”(“能观性(Observability)”和“能控性(Controllability)”是自动控制领域的术语,此处“能观性”是指能获知进程的一切状态,“能控性”是指能让进程达到我们想要的任何状态)。
10.最好能在运行时修改程序用到的后台服务的host:port(原本写在配置文件中),这样可以随时主动切换后台服务(平滑升级或故障预防),而无须重启本进程。
11.必要的时候还可以用REST(Representational State Transfer)的方式实现高级的聚合,见作者在演讲中的“一种REST风格的监控”:

另外,我们讨论分布式系统是运行在企业防火墙之内的基础设施,HTTP的安全性应该由防火墙保证。就好比你的Hadoop master和memcached不会暴露给外网一样,在公司内部使用HTTP,只要没有人故意搞破坏就没事。
实例
演讲中作者举了Google的例子(见Jeff Dean演讲中的“Add Sufficient Monitoring/Status/Debugging Hooks”一节,http://www.cs.cornell.edu/projects/ladis2009/talks/dean-keynote-ladis2009.pdf),Google的每个服务进程(无论C++或Java)都会:
1.提供HTML的状态页面,以便快速诊断问题;
2.通过某种标准接口暴露出一组key-value pairs;
3.监控程序定期从全部服务进程收集性能数据;
4.TCP子系统对全部请求采样:错误的,耗时>0.05s,>0.1s,>0.5s,>1.0s……
当然,我们看不到Google内部的服务器的状态页面究竟是什么样子,不过可以看看别的例子,比如Hadoop。Hadoop有四种主要services:NameNode、DataNode、JobTracker、TaskTracker。每种service都内置了HTTP状态页面,其默认HTTP端口分别是:
1.NameNode——50070
2.DataNode——50075
3.JobTracker——50030
4.TaskTracker——50060
如果某台机器运行了DataNode和TaskTracker,那么我们可以通过访问http://hostname:50075和http://hostname:50060来方便地查询其运行状态。
例外
如果不方便内置HTTP服务,那么内置一个简单的telnet服务也不难,就像memcached的stats命令那样。
如果服务程序本身以RPC方式提供服务,那么可以不必内置HTTP服务,而是增加一个RPC调用实现相同的功能。这个RPC可以命名为inspect(),输入的内容类似URL,返回的是该URL对应的页面内容,可以是文本格式,也可以是RPC原生的打包格式。
如果是Java程序,可以直接使用JMX,也可以继续使用本节提到的HTTP方法,这样管理和监控的一致性较好,至少不需要为Java服务进程准备特殊的客户端。
小结
在自己编写分布式程序的时候,提供一个维修通道是很有必要的,它能帮助日常运维,而且在出现故障的时候帮助排查。相反,如果不在程序开发的时候统一预留这些维修通道,那么运维起来就抓瞎了——每个进程都是黑盒子,出点什么情况都得拼命查log试图恢复(猜测)进程的状态,工作效率不高。
9.6 为系统演化做准备
一个分布式系统的生命期会长达数年,在首次上线运行之后,系统会经历多次升级和演化,因此在一开始设计的时候要适当为将来考虑。一个典型的考虑点是:通信的双方很有可能不会同时升级。通信双方可能由不同的开发团队开发,开发和发布周期不同步。有可能为了稳妥起见先升级其中一方,验证稳定性,然后再升级另一方。当然,升级之前一定要制定好rollback计划,留好退路。
具体来说,服务端新加功能,不一定所有的客户端都会马上升级并用上新功能,因此新的服务端上线之后要保证和现有的客户端的功能和协议的兼容性,这样才能平稳升级。系统中的不同组件可能用不同的编程语言来编写,有时候会把一个组件换一种语言重写,因此应该使用一种跨语言的可扩展消息格式。
9.6.1 可扩展的消息格式
考虑服务器升级的可能时,一种很容易想到的做法是在消息中放入版本号,服务端每次收到消息,先根据版本号做分发(dispatch)。实践证明这种做法是非常不靠谱的,很容易在服务端留下一堆垃圾代码,时间一长,谁也弄不清版本之间具体有哪些细微差别,也不敢轻易删掉处理旧版本消息的代码,历史包袱就一直背下去了。
因此,可扩展消息格式的第一条原则是避免协议的版本号,否则代码里会有一堆难以维护的switch-case,就像Google Protocol Buffers文档举的反面例子(http://developers.google.com/protocol-buffers/docs/overview)。

另一种常见的错误是通过TCP连接发送C struct或使用bit fields。这或许是因为在学习TCP/IP协议和网络编程的时候,书上一般会画出IP header和TCP header,其中就有big fields,这给人留下了一个错误印象,似乎网络协议应该这么设计。其实不是这样的,C struct和bit fields的缺点很多。其一是不易升级。如果在C struct里新加了一些元素,同样要求客户端和服务端一起升级,否则就语言不通了。其二是不跨语言(就算是C/C++也要考虑32-bit或64-bit平台,endian、编译器对齐(alignment)的影响等等)。如果客户端和服务端用不同的语言来编写,那么让非C/C++语言生成和解析这种消息格式是比较麻烦的。而且更重要的是需要时刻维护其他语言的打包、解包代码与C/C++头文件里struct定义的同步,稍不注意就会造成格式解析错乱。
解决办法是,采用某种中间语言来描述消息格式(schema),然后生成不同语言的解析与打包代码。如果用文本格式,可以考虑JSON和XML;如果用二进制格式,可以考虑Google Protobuf Buffers。使用文本格式的一个常见问题是处理转义字符(escape character),比如消息id字段如果出现’&',在XML中要写成&。如果公司名字是AT&T,在XML中要写成<company>AT&T</company>。
Google Protobuf是结构化的二进制消息格式(结构化的意思是说一个消息可以使用其他自定义消息类型为成员,也可以包含数组,数组的元素可以是其他自定义消息类型),兼顾性能(Protobuf二进制格式中的整数采用变长编码,可以节约带宽,降低延迟,https://developers.google.com/protocol-buffers/docs/encoding)与可扩展性。其文档中说(http://developers.google.com/protocol-buffers/docs/cpptutorial):Importantly, the protocol buffer format supports the idea of extending the format over time in such a way that the code can still read data encoded with the old format。
这种“中间语言”或者叫“数据描述语言”定义的消息格式可以有可选字段(optional fields),一举解决了服务端和客户端升级的难题。新版的服务端可以定义一些optional fields,根据请求中这些字段的存在与否来实施不同的行为,即可同时兼容旧版和新版的客户端。给每个field赋终生不变的id是保证兼容性的绝招,Google Protobuf的文档强调在升级proto文件时要注意(http://developers.google.com/protocol-buffers/docs/proto#updating):
1.you must not change the tag numbers of any existing fields.
2.you must not add or delete any required fields.
proto文件就像C/C++动态库的头文件,其中定义的消息就是库(分布式服务)的接口,一旦发布就不能做有损二进制兼容性的修改。因此11.2的知识可以套用过来,包括不能更改已有的enum类型的成员的值等。
PNG(Portable Network Graphics,是一种常见的图像文件格式)文件给我们很好的启示。PNG是一种精心设计的二进制文件格式,文件由一系列数据块(chunks)组成,每个数据块的前4个字节表示该数据块的长度,接下来的4个字节代表该数据块的类型。PNG的解译程序会忽略那些自己不认识的数据块,因此PNG文件没有版本之说,不存在前后版本不兼容的问题。
Google Protobuf是精心设计的协议格式,还体现在客户端可以先升级,发送服务端不认识的field,服务端可以安全地跳过这些字段。
TCP/IP在设计的时候也在固定长度的header之后预留了可选项,目前广泛使用的有window scale和timestamp等。
9.6.2 反面教材:ICE的消息打包格式
ICE(http://www.zeroc.com)是一个对象中间件,它实现类似CORBA(Common Object Request Broker Architecture,公共对象请求代理体系结构,是一种面向对象的分布式计算平台,旨在解决分布式系统中对象之间的通信和交互问题)的跨语言、跨进程的函数调用。作者对ICE的设计及实现很不以为然。其中一个原因是它按struct field和函数参数的顺序来打包消息,难以无痛升级。一旦给struct新加一个成员或者给函数新加一个参数,客户端和服务端必须同时升级,否则就言语不通了。另外一个原因是它的远程函数调用居然能返回异常。也就是说,当服务端的RPC函数抛出异常时,RPC机制会捕捉这个异常,通过网络传送到客户端,在客户端重新抛出这个异常。作者实在不理解这种异常捕捉下来有何用处,客户端可能是Python,服务端是C++,Python代码拿到C++异常能干什么?还不如老老实实直接返回错误代码,处理起来更简单。
9.7 分布式程序的自动化回归测试
本节所谈的“测试”指的是“开发者测试(developer testing)”,由程序员自己来做,不是由QA团队进行的系统测试。这两种测试各有各的用途,不能相互替代。
11.1 “朴实的C++设计”中谈到:“为了确保正确性,我们另外用Java写了一个测试夹具(test harness)来测试我们这个C++程序。这个测试夹具模拟了所有与我们这个C++程序打交道的其他程序,能够测试各种正常或异常的情况。”
本节详细介绍一下这个test harness的做法。
自动化测试的必要性
自动化测试的必要性无须赘言,自动化测试是absolutely good stuff。
基本上,要是没有自动化的测试,作者是不敢改产品代码的(“改”包括添加新功能和重构)。自动化测试的作用是把程序已经实现的features以test case的形式固化下来,将来任何代码改动如果破坏了现有的功能需求就会触发测试failure。好比DNA双链的互补关系,这种互补关系对保持生物遗传的稳定有重要作用。类似地,自动化测试与被测程序的互补结构对保持系统的功能稳定有重要作用。
9.7.1 单元测试的能与不能
一提到自动化测试,作者猜很多人想到的是单元测试(unit testing)。单元测试确实有很大的用处,对于解决某一类型的问题很有帮助。粗略地说,单元测试主要用于测试一个函数、一个class或者相关的几个class。
最典型的是测试纯函数,比如计算个人所得税的函数,输入是“起征点、扣除五险一金之后的应纳税所得额、税率表”,输出是应该缴的个税。又比如,作者在《程序中的日期与时间》的第一章“日期计算”(http://blog.csdn.net/solstice/article/details/5814486)中用单元测试来验证Julian day number算法的正确性。再比如,作者在《“过家家”版的移动离线计费系统实现》(http://www.cnblogs.com/solstice/archive/1022/04/22/2024791.html)和《模拟银行窗口排队叫号系统的运作》(http://blog.csdn.net/solstice/article/details/6324749)中用单元测试来检查程序运行的结果是否符合预期(最后这个或许不是严格意义上的单元测试,更像是验收测试)。
为了能用单元测试,程序代码有时候需要做一些改动。这对Java通常不构成问题(反正都编译成jar文件,在运行的时候指定entry point)。对于C++,一个程序只能有一个main()入口点,要采用单元测试的话,需要把功能代码(被测对象)做成一个library,然后让单元测试代码(包含main()函数)link到这个library上;当然,为了正常启动程序(非单元测试的情况),我们还需要写一个普通的main(),并link到这个library上。
单元测试的缺点
根据作者的个人经验,发现单元测试有以下缺点。
阻碍大型重构
单元测试是白盒测试,测试代码直接调用被测代码,测试代码与被测代码紧耦合。从理论上说,“测试”应该只关心被测代码实现的功能,不用管它是如何实现的(包括它提供什么样的函数调用接口)。比方说,以前面的个税计算器函数为例,测试代码必须调用被测代码,那么测试代码必须要知道个税计算器的package、class、method name、parameter list、return type等等信息,还要知道如何构造这个class。以上任何一点改动都会造成测试失败(编译不通过)。
在添加新功能的时候,我们常会重构已有的代码,在保持原有功能的情况下让代码的“形状”更适合实现新的需求。一旦修改原有的代码,单元测试就可能编译不过:比如给成员函数或构造函数添加一个参数,或者把成员函数从一个class移到另一个class。对于Java,这个问题还比较好解决,因为IDE的重构功能很强,能自动找到reference,并修改之。
对于C++,这个问题更为严重,因为一改功能代码的接口,单元测试就编译不过了,而C++通常没有自动重构工具(语法太复杂,语意太微妙)可以帮我们,都得手动来。要么每改动一点功能代码就修复单元测试,让编译通过;要么留着单元测试编译不通过,先把功能代码改成我们想要的样子,再来统一修复单元测试。
这两种做法都有困难,前者,C++编译缓慢,如果每改动一点就修复单元测试,一天下来也前进不了几步,很多时间都浪费在了等待编译上;后者,问题更严重,单元测试与被测代码的互补性是保证程序功能稳定的关键,如果大幅修改功能代码的同时又大幅修改了单元测试,那么如何保证前后的单元测试的效果(测试点)不变?如果单元测试自身的代码发生了改动,如何保证它测试结果的有效性?会不会某个手误让功能代码和单元测试犯了相同的错误,负负得正,测试结果还是绿的,但是实际功能已经亮了红灯?难道我们要为单元测试编写单元测试吗?
有时候,我们需要重新设计并重写某个程序(有可能换用另一种语言)。这时候旧代码中的单元测试完全作废了(代码结构发生巨大改变,甚至连编程语言都换了),其中包含的宝贵的业务知识也付之东流,岂不可惜?
为了方便测试而施行依赖注入,破坏代码的整体性
为了让代码具有“可测试性”,我们常会使用依赖注入技术(一种设计模式,用于降低代码中各个组件之间的耦合度,在依赖注入中,一个类的依赖关系不是在类内部创建,而是由外部的调用者或容器注入),这么做的好处据说是“解耦”,坏处就是割裂了代码的逻辑:单看一块代码不知道它是干嘛的,它依赖的对象不知道是在哪创建的,如果一个interface有多个实现,不到运行的时候不知道用的是哪个实现(动态绑定的初衷就是如此,想来读过“以面向对象思想实现”的代码的人都明白作者在说什么)。
以第七章中“Boost.Asio的聊天服务器”中出现的聊天内容ChatServer为例,ChatServer直接使用了muduo::net::TcpServer和muduo::net::TcpConnection来处理网络连接并收发数据,这个设计简单直接。如果要为ChatServer写单元测试,那么首先它肯定不能在构造函数里初始化TcpServer了(而是由调用者,即单元测试代码来初始化)。
稍微复杂一点的测试要用mock object(模拟对象,是软件测试中的一种概念,用于模拟或替代真实对象,以便在测试过程中控制对象的行为)
ChatServer用TcpServer和TcpConnection来收发消息,为了能单元测试,我们要为TcpServer和TcpConnection提供mock实现(mock实现是用于测试的模拟实现,可以在测试中控制其行为以验证ChatServer的正确性),在这个过程中,原本一个具体类(Concrete Class,指的是一个具体、实际实现的类,而不是抽象类或接口)TcpServer变成了一个TcpServer interface,并分别实现了两个TcpServerImpl和TcpServerMock,同理TcpConnection也一化为三。ChatServer本身的代码也变得复杂,我们要设法把TcpServer和TcpConnection注入其中,ChatServer不能自己初始化TcpServer对象。
这恐怕是在C++中使用单元测试的主要困难之一。Java有动态代理(在动态代理中,代理对象的行为可以在运行时通过InvocationHandler进行定制),还可以用cglib(一个针对Java字节码的代码生成库,广泛用于实现动态代理和其他类似的代码生成任务,cglib的主要优势在于能够在运行时动态生成类的子类,而不需要源代码)来操作字节码以实现注入。而C++比较原始,只能自己手工实现interface和implementations。这样原本紧凑的以concrete class构成的代码结构因为单元测试的需要而变得松散(所谓“面向接口编程”嘛,即将具体的实现替换为接口),而这么做的目的仅仅是为了满足“源码级的可测试性”,是不是有一点因小失大呢(这里且暂时忽略虚函数和普通函数在性能上的些微差别)?对于不同的test case,可能还需要不同的mock对象,比如TcpServerMock和TcpServerFailureMock,这又增加了编码的工作量。
此外,如果程序中用到的涉及IO的第三方库没有以interface方式暴露接口,而是直接提供的concrete class(这是对的,因为C++中应该“避免使用虚函数作为库的接口”,见11.3),这也让编写单元变得困难,因为总不能自己挨个wrapper一遍吧?难道用link-time的注入技术(在链接时将代码或数据注入到可执行文件中的技术,无需修改源代码)?
某些failure场景难以测试
而考察这些场景对编写稳定的分布式系统有重要作用。比方说:网络连不上、数据库超时、系统资源不足。
对多线程程序无能为力
如果一个程序的功能涉及多个线程合作,那么就比较难用单元测试来验证其正确性。
如果程序涉及比较多的交互(指和其他程序交互,不是指图形用户界面),用单元测试来构造测试场景比较麻烦,每个场景要写一堆无趣的代码。而这正是分布式系统最需要测试的地方。
总的来说,单元测试是一个值得掌握的技术,用在适当的地方确实能提高生产力。同时,在分布式系统中,我们还需要其他的自动化测试手段。
9.7.2 分布式系统测试的要点
在分布式系统中,class与function级别的单元测试对整个系统的帮助不大。这种单元测试对单个程序的质量有帮助,但是,一堆砖头垒在一起是变不成大楼的。
分布式系统测试的要点是测试进程间的交互:一个进程收到客户请求,该如何处理,然后转发给其他进程;收到其他进程的响应之后,又修改(可能指的是修改进程的内部状态,或修改其他进程的响应)并应答客户。测试这些多进程写作的场景才算测到了点子上。
假设一个分布式系统由四五种进程组成,每个程序有各自的开发人员。对于整个系统,我们可以用脚本来模拟客户,自动化地测试系统的整体运作情况,这种测试通常由QA团队来执行,也可以作为系统的冒烟测试。
对于其中每个程序的开发人员,上述测试方法对日常的开发帮助不大。因为测试要能通过,必须整个系统都正常运转才行,在开发阶段,这一点不是时时刻刻都能满足的(有可能你用到的新功能对方还没有实现,这反过来影响了你的进度)。另一方面,如果出现测试失败,开发人员不能立刻知道这是自己的程序出错(也有可能是环境原因造成的错误),这通常要去读程序日志才能判定。还有,作为开发者测试,我们希望它无副作用,每天反复多次运行也不会增加整个环境的负担,以整个QA系统为测试平台不可避免地要留下一些垃圾数据,而清理这些数据又会花一些宝贵的工作时间(你得判断数据时自己的测试生成的还是别人的测试留下的,不能误删了别人的测试数据)。
作为开发人员,我们需要一种单独针对自己编写的那个程序的自动化测试方案,一方面提高日常开发的效率,另一方面作为自己那个程序的功能验证测试集,以及回归测试(regression tests)。
9.7.3 分布式系统的抽象观点
一台机器两根线
形象地来看(见图9-12),一个分布式系统就是一堆机器,每台机器的“屁股”上拖着两根线:电源线和网线(不考虑SAN等存储设备),电源线插到电源插座上,网线插到交换机上。
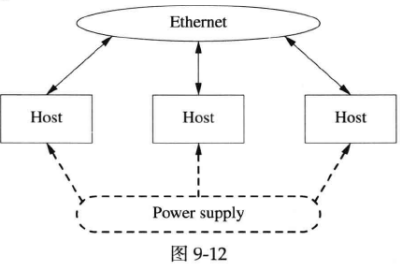
这个模型实际上说明,一台机器、一个程序表现出来的行为完全由它接出来的两根线展现,本书不谈电源线,只谈网线(“在乎服务器的功耗”在作者看来就是公司利润率很低的标志,要从电费上抠成本)。
如果网络是普通的千兆以太网,那么吞吐量不大于125MB/s。这个吞吐量比起现在的CPU运算速度和内存带宽简直小得可怜。这里作者想提的是,对于不特别在意latency的应用,只要能让千兆以太网的吞吐量饱和或接近饱和,用什么编程语言其实无所谓。Java做网络服务端开发也是很好的选择(不是指Web开发,而是做一些基础的分布式组件,例如ZooKeeper和Hadoop之类)。尽管可能C++只用了15%的CPU,而Java用了30%的CPU,Java还占用更多内存,但是千兆网卡带宽都已经跑满,那些省下的资源也只能浪费了;对于外界(从网线上看来)而言,两种语言的效果是一样的,而通常Java的开发效率更高。Java比C++慢一些,但是通过千兆网络不一定能看得出这个区别来。同样的道理,单机程序的某些“性能优化”不一定真能提高系统整体表现出来的、能被观察到的性能,这也是本书基本不谈微观性能优化的主要原因。在弄清楚系统瓶颈之前贸然投入优化往往是浪费时间和精力,还耽误了项目进度,颇为不值。
进程间通过TCP相互连接
作者在第三章中提倡仅使用TCP作为进程间通信的手段,此处这个观点将再次得到验证。
图9-13是Hadoop的分布式文件系统HDFS的架构简图。
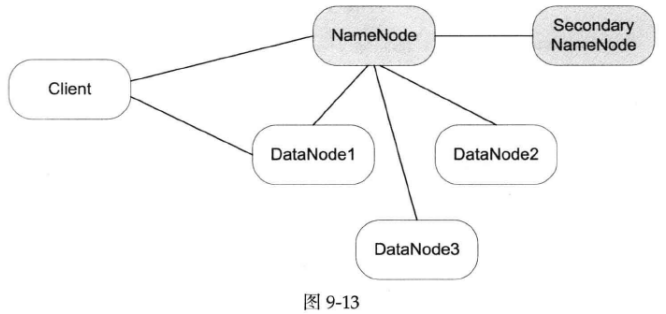
HDFS有四个角色参与其中,NameNode(保存元数据)、DataNode(存储节点,多个)、Secondary NameNode(定期写check point)、Client(客户,系统的使用者)。这些进程运行在多台机器上,之间通过TCP协议互联。程序的行为完全由它在TCP连接上的表现决定(TCP就好比前面提到的“网线”)。
在这个系统中,一个程序其实不知道与自己打交道的到底是什么。比如,对于DataNode,它其实不在乎自己连接的是真的NameNode还是某个调皮的小孩用Telnet模拟的NameNode,它只管接受命令并执行。对于NameNode,它其实也不知道DataNode是不是真的把用户数据存到磁盘上去了,它只需要根据DataNode的反馈更新自己的元数据就行。这已经为我们指明了方向。
9.7.4 一种自动化的回归测试方案
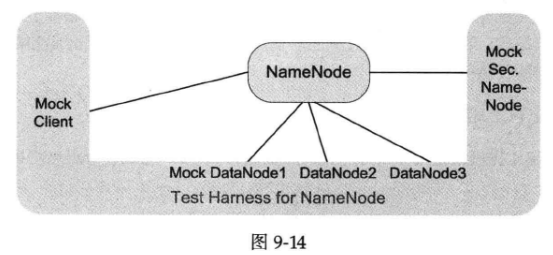
假如作者是NameNode的开发者,为了能自动化测试NameNode,可以为它写一个test harness(这是一个独立的进程),这个test harness仿冒(mock)了与被测进程打交道的全部程序。如图9-14所示,是不是有点像“缸中之脑”?
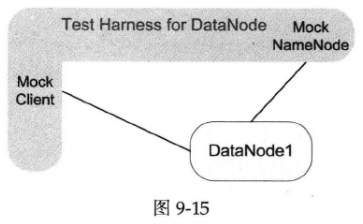
对于DataNode的开发者,他们也可以写一个专门的test harness,模拟Client和NameNode(见图9-15)。
test harness的优点
1.完全从外部观察被测程序,对被测程序没有侵入性,代码该怎么写就怎么写,不需要为测试留路。
2.能测试真实环境下的表现,程序不是单独为测试编译的版本,而是将来真实运行的版本。数据也是从网络上读取,发送到网络上。
3.允许被测程序做大的重构,以优化内部代码结构,只要其表现出来的行为不变,测试就不会失败(在重构期间不用修改test case)。
4.能比较方便地测试failure场景。比如,若要测试DataNode出错时NameNode的反应,只要让test harness模拟的那个mock DataNode返回我们想要的出错信息。要测试NameNode在某个DataNode失效之后的反应,只要让test harness断开对应的网络连接即可。要测量某请求超时的反应,只要让test harness不返回结果即可。这对构建可靠的分布式系统尤为重要。
5.帮助开发人员从使用者的角度理解程序,程序的哪些行为在外部是看得到的,哪些行为是看不到的。
6.有了一套比较完整的test harness之后,甚至可以换种语言重写被测程序(假设为了提高内存利用率,换用C++来重新实现NameNode),测试用例依旧可用。这时test harness起到知识传承作用。
7.发现bug之后,往test harness里添加能复现bug的test case,修复bug之后,test case继续留在harness中,防止出现回归(regression)。
实现要点
1.test harness的要点在于隔断被测程序与其他程序的联系,它冒充了全部其他程序。这样被测程序就像被放到测试台上观察一样,让我们只关注它一个。
2.test harness要能发起或接受多个TCP连接,可能需要某个现成的NIO(Non-blocking I/O)网络库,如果不想写成多线程程序的话。
3.test harness可以与被测程序运行在同一台机器,也可以运行在两台机器上。在运行被测程序的时候,可能要用一个特殊的启动脚本把它依赖的host:port指向test harness。
4.test harness只需要表现得跟它要mock的程序一样,不需要真的去实现复杂的逻辑。比如mock DataNode只需要对NameNode返回“Yes sir,数据已存好”,而不需要真的把数据存到硬盘上。若要mock比较复杂的逻辑,可以用“记录+回放”的方式,把预设的响应放到test case里回放(replay)给被测程序。
5.因为通信走TCP协议,test harness不一定要和被测程序用相同的语言,只要符合协议就行。试想如果用共享内存实现IPC,这是不可能的。本书7.6提到利用Protobuf的跨语言特性,我们可以采用Java为C++服务程序编写test harness。其他跨语言的协议格式也行,比如XML或JSON。
6.test harness运行起来之后,等待被测程序的连接,或者主动连接被测程序,或者兼而有之,取决于所用的通信方式。
7.一切就绪之后,test harness依次执行test cases。一个NameNode test case的典型过程是:test harness模仿client向被测NameNode发送一个请求(如创建文件),NameNode可能会联络mock DataNode,test harness模仿DataNode应有的响应,NameNode收到mock DataNode的反馈之后发送响应给client,这时test harness检查响应是否符合预期。
8.test harness中的test cases以配置文件(每个test case有一个或多个文本配置文件,每个test case占一个目录)方式指定。test harness和test cases连同程序代码一起用version control工具管理起来。这样能复现任何一个版本的应有行为。
9.对于比较复杂的test case,可以用嵌入式脚本语言来描述场景。如果test harness是用Java写的,那么可以嵌入Groovy(一种面向对象的编程语言,它兼容Java并且在Java平台上运行),就像笔者在《“过家家”版的移动离线计费系统实现》中用Groovy实现计费逻辑一样。Groovy调用test harness模拟多个程序分别发送多份数据并验证结果,Groovy本身就是程序代码,可以有逻辑判断甚至循环。这种动静结合的做法在不增加test harness复杂度的情况下提供了相当高的灵活性。
10.test harness可以有一个命令行界面,程序员输入“run 10”就选择执行第10号test case。
几个实例
test harness这种测试方法适合测试有状态的、与多个进程通信的分布式程序,除了Hadoop中的NameNode与DataNode,作者还能想到几个例子。
chat聊天服务器
聊天服务器会与多个客户端打交道,我们可以用test harness模拟5个客户端,模拟用户上下线、发送信息等情况,自动测试聊天服务器的功能。
连接服务器、登录服务器、逻辑服务器
这是云风在他的blog中提到的三种网游服务器(http://blog.codingnow.com/2007/02/user_authenticate.html,http://blog.codingnow.com/2006/04/iocp_kqueue_epoll.html,http://blog.codingnow.com/2010/11/go_prime.html),作者这里借用来举例子。
如果要为连接服务器写test harness,那么需要模拟客户(发起连接)、登录服务器(验证客户资料)、逻辑服务器(收发网游数据),有了这样的test harness,可以方便地测试连接服务器的正确性,也可以方便地模拟其他各个服务器断开连接的情况,看看连接服务器是否应对自如。
同样的思路,可以为登录服务器写test harness(作者估计不用为逻辑服务器再写了,因为肯定已经有自动测试了)。
见7.12的一个具体示例。
多master之间的二段提交(Two-Phase Commit,简称2PC,它用于确保分布式系统中的多个节点(或称为Masters)在进行事务性操作时能够保持一致性,流程为:事务协调者(Coordinator)向所有参与者(Participants)发送事务请求,并询问它们是否可以执行事务操作,参与者执行本地事务,并将执行结果的反馈(事务执行成功或失败)发送给事务协调者,如果协调者收到了所有参与者的执行结果,它将向所有参与者发出全局提交请求,参与者收到全局提交请求后,如果本地事务执行成功,就执行提交操作;如果本地事务执行失败,就执行回滚操作,参与者在执行完提交或回滚操作后,向协调者发送执行结果的消息,协调者等待收集所有参与者的执行结果,如果所有参与者都成功提交,协调者向所有参与者发送事务已经完成的消息,否则,它将发送事务已中止的消息)
这是分布式容错的一个经典做法。用test harness能把primary master和secondary master单独拎出来测试。在测试primary master的时候,test harness扮演name service和secondary master。在测试secondary master的时候,test harness扮演name service、primary master、其他secondary masters。可以比较容易地测试各种failure情况。如果不这么做,而直接部署多个master来测试,恐怕很难做到自动化测试。
Paxos的实现
Paxos协议(一种用于分布式系统中实现一致性的算法)的实现肯定离不了单元测试,因为涉及多个角色中比较复杂的状态变迁。同时,如果作者要写Paxos实现,那么test harness也是少不了的,它能自动测试Paxos节点再真实网络环境下的表现,并且轻松模拟各种failure场景。
局限性
如果被测程序有TCP之外的IO,或者其TCP协议不易模拟(比如通过TCP连接数据库),那么这种测试方案会受到干扰。
对于数据库,如果被测程序只是简单地从数据库SELECT一些配置信息,那么或许可以在test harness里内嵌一个in-memory H2 DB engine(H2数据库引擎是一种嵌入式、基于内存的关系型数据库引擎,它是用Java编写的,因此可以轻松地嵌入到Java应用程序中,H2数据库支持多种模式,包括内存模式、磁盘模式和混合模式,其中内存模式即为在内存中存储数据,是一种轻量级且快速的选择,H2的内存模式经常被用于快速原型开发、单元测试和临时数据存储),然后让被测程序从这里读取数据。当然,前提是被测程序的DB driver能连上H2(或许不是大问题,H2支持JDBC(Java Database Connectivity是Java平台提供的一种用于与数据库通信的API)和部分ODBC(Open Database Connectivity是一种用于在计算机系统之间进行数据库连接的开放标准)。如果被测程序有比较复杂的SQL代码,那么H2表现的行为不一定和生产环境的数据库一致,这时候恐怕还是要部署测试数据库(有可能为每个开发人员部署一个小的测试数据库,以免互相干扰)。
如果被测程序有其他IO(写log不算),比如DataNode会访问文件系统,那么test harness没有能把DataNode完整地包裹起来,有些failure case不是那么容易测试的。这时或许可以把DataNode指向tmpfs(一种在内存中创建临时文件系统的Linux文件系统类型,它允许将一部分计算机的内存用作文件系统,用于存储临时数据,这样可以在内存中快速读写,而不必将数据写入磁盘),这样能比较容易地测试磁盘满的情况。当然,这样也有局限性,因为tmpfs没有真实磁盘那么大,也不能模拟磁盘读写错误。作者不是分布式存储方面的专家,这些问题留给分布式文件系统的实现者去考虑吧)(测试Paxos节点似乎也可以用temfs来模拟persist storage,由test case填充所需的初始数据)。
9.7.5 其他用处
test harness除了实现features的回归测试外,还有别的用处。
加速开发,提高生产力
前面提到,如果有个新功能(增加一种新的request type)需要改动两个程序,有可能造成相互等待:客户程序A说要先等服务程序B实现对应的功能响应,这样A才能发送新的请求,不然每次请求就会被拒绝,无法测试;服务程序B说要先等A能够发送新的请求,这样自己才能开始编码与测试,不然都不知道请求长什么样子,也触发不了新写的代码(当然,这是作者虚构的例子)。
如果A和B都有各自的test harness,事情就好办了,双方大致商量一个协议格式,然后分头编码。程序A的作者在自己的harness里边添加一个test case,模拟他认为B应有的响应,这个响应可以hard code某种最常见的响应,不必真的实现所需的判断逻辑(毕竟这是程序B的作者该干的事情),然后程序A的作者就可以编码并测试自己的程序了。同理,程序B的作者也不用等A拿出一个半成品来发送新请求,他往自己的harness添加一个test case,模拟他认为A应该发送的请求,然后就可以编码并测试自己的新功能了。双方齐头并进,减少扯皮。等功能实现得差不多了,两个程序互相连一连,如果发现协议不一致,检查一下harness中的新test cases(这代表了A/B程序对对方的预期),看看哪边改动比较方便,很快就能解决问题。
压力测试
test harness稍加改进还可以变功能测试为压力测试,供程序员profiling(性能分析)用。比如反复不间断发送请求,向被测程序加压。不过,如果被测程序是用C++写的,而test harness是用Java写的,有可能出现test harness占100%CPU,而被测程序还跑得优哉游哉的情况。这时候可以单独用C++写一个负载生成器。
小结
以单独的进程作为test harness对于开发分布式程序相当有帮助,它能达到单元测试的自动化程度和细致程度,又避免了单元测试对功能代码结构的侵入与依赖。
9.8 分布式系统部署、监控与进程管理的几重境界
约定:本节只考虑Linux系统,文中涉及的“服务程序”是以C++或Java编写的,编译成二进制可执行文件(binary或jar),程序启动的时候一般会读取配置文件(或者以其他方式获得配置信息),同一个程序每个服务进程的配置文件可能略有不同。“服务器”这个词有多重含义,为避免混淆,本节以host指代服务器硬件,以“服务端程序/进程”指代服务器软件(或者具体说Web Server和Suduku Solver,这两个都是服务软件)。
在进入正题之前,先看一个虚构但典型的例子:Sudoku Solver(Sudoku Solver是个均质的(“均质的” 可能表示这个服务的实例之间在状态或性质上没有显著的差异,它们具有相同的特征和行为)无状态服务,分布式系统中进程的状态转移不是本节的主题)。
假设你们公司的分布式系统中有一个专门求解数独(Sudoku)的服务程序,这个程序是你们团队开发并维护的。通常Web Server会使用这个Sudoku Solver提供的服务,用户通过Web页面提交一个Sudoku谜题,Web Server转而向Sudoku Solver寻求答案。每个Web Server会同时跟多个Sudoku Solver联系,以实现负载均衡。系统的消息收发关系大致如图9-16所示,每个矩形是一个进程,运行在各自的host上。
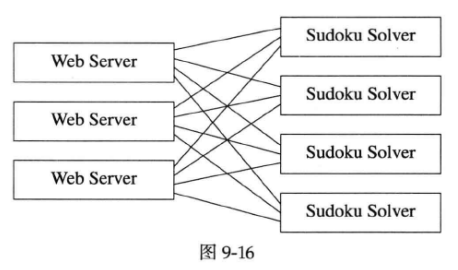
图9-16中的Web Server请不要简单理解为httpd+cgi(Common Gateway Interface,是一种用于在Web服务器上执行外部程序的标准),它其实泛指一切客户端,其本身(指上图的Web Server)可能是个stateful的服务程序。
当然,系统不是一开始就是这样的,它经历了多步演化。
1.最开始的时候,Sudoku求解直接在Web Server内完成。后来为了提高负载能力,把Sudoku单独做成服务。一开始系统规模很小,只有一个Sudoku Solver,也只有一台Web Server,是个简单的一对一(1:1)的使用关系,如图9-17所示。

2.随后,随着业务量增加,一台host不堪重负,于是又部署了几台Sudoku Solver,变成了一对多(1:N)的使用关系,如图9-18所示。

3.再后来,一台Web Server撑不住了,于是部署了几台Web Server,形成了我们一开始看到的图9-16中的多对多(M:N)的使用关系。
在分布式系统中部署并运行Sudoku Solver,需要考虑以下几个问题:
1.Sudoku Solver如何部署到多台host上运行?是把可执行文件拷贝过去吗?程序用到的库怎么办?配置文件怎么办?
2.如何启动服务程序Sudoku Solver?如果每个Solver的配置文件稍有不同(比如每个Solver有自己的service name),那么配置文件是自动生成吗?
3.Sudoku Solver的listening port如何配置?如何保证它不与其他服务程序重复?
4.如果程序crash,谁来重启?能否自动重启?开发/运维人员能否及时收到alert?
5.如果想主动重启Sudoku Solver,要不要登录到那台host上去kill?还是能够远程控制?
6.如果要升级Sudoku程序,如何重新部署?如何(尽量)做到不中断服务?
7.Web Server如何知道那些Sudoku Solver的地址?是不是静态写到Web Server的配置文件里?
8.如果Sudoku Solver所在的host发生硬件故障,管理人员是否能立刻得知这一状况?Web Server能否自动failover到其他alive的Solver上?
9.部署新的Sudoku Solver之后,Web Server能否自动开始使用新的Solver而无须重启(重启Web Server似乎不是大问题,这里我们进一步考虑client是个有状态的服务,应该尽量避免无谓的重启)?
10.程序可否安全地退役?比方说公司不再做求解Sudoku的业务,那么关闭全部Sudoku Solver会不会对其他业务造成影响?
这些问题可以大致归结为几个方面:部署(含升级)可执行文件与配置文件、监控进程状态、管理服务进程、故障响应,这些合起来可称为运维(operation)。
根据公司的规模和技术水平不同,分布式系统的运维分为几重境界,以下是作者对各重境界的简要描述。














 3019
3019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









