







9.8.1 境界1:全手工操作
这个大概是高校实验室的水平,分布式系统的规模不大,可能十来台机器上下。分布式系统的实现者为在校学生。
系统完全是手工搭起来的,host的IP地址采用静态配置。
部署
编译之后手工把可执行文件拷贝到各台机器上,或者放到公用的NFS目录下。配置文件也手工修改并拷贝到各台机器上(或者放到每个Sudoku Solver自己单独的NFS目录下)。
管理
手工启动进程,手工在命令行指定配置文件的路径。重启进程的时候需要登录到host上并kill进程。
升级
如果需要升级Sudoku Solver,则需要手工登录多台hosts,可以拷贝新的可执行文件覆盖原来的,并重启。
配置
Web Server的配置文件里写上Sudoku Solver的ip:port。如果部署了新的Sudoku Solver,多半要重启Web Server才能发挥作用。
监控
无。系统不是真实的商业应用,仅仅用作学习研究,发现哪儿不对劲了就登录到那台host上去看看,手工解决问题。
这个级别可算是“过家家”,系统时灵时不灵,可以跑跑测试,发发paper。
9.8.2 境界2:使用零散的自动化脚本和第三方组件
这大概是刚起步的公司的水平,系统已经投入商业应用。公司的开发重心放在实现核心业务、添加新功能方面,暂时还顾不上高效地运维,或许系统的运维任务由开发人员或网管人员兼任。公司已经有了基本的开发流程,代码采用中心化的版本管理工具(比如SVN),有比较正式的QA sign-off(指QA团队确认软件是否可以交付给最终用户这一决定)流程。
公司内网有DNS,可以把hostname解析为IP地址,host的IP地址由DHCP配置。公司内部的host的软硬件配置比较统一,比如硬件都是x86-64平台,操作系统统一使用Ubuntu 10.04 LTS(Long Term Support,即长期支持),每天机器上安装的package和第三方library也是完全一样的(版本号也相同),这样任何一个程序在任何一台host上都能启动,不需要单独的配置。
假设各台host已经配置好了SSH authentication key或者GSSAPI(Generic Security Services Application Program Interface,一种标准的安全服务应用程序接口,它提供了一种通用的方式,使应用程序能够与各种安全机制进行交互,而无需了解底层的安全细节),不需要手工输入密码。如果要在host1、host2、host3、host4上运行md5sum命令,看一下各台机器上的Sudoku Solver可执行文件的内容是否相同,可以在本机执行:
for h in host1 host2 host3 host4;
do ssh $h md5sum /path/to/SudokuSolver/version/bin/sudoku-solver;
done
公司的技术人员有能力配置使用cron、at(在指定的时间运行一次性任务)、logrotate(用于管理系统日志文件)、rrdtool(Round Robin Database Tool,一个用于存储时间序列数据并生成图表的开源工具)等标准的Linux工具来将部分运维任务自动化。
部署
可执行文件必须经过QA签署放行才能部署到生产环境(如有必要,QA要签署可执行文件的md5)。为了可靠性,可能不会把可执行文件放到NFS上(如果NFS发生故障,整个系统就瘫痪了)。有可能采用rsync(Remote Sync,一个用于文件和目录之间的数据同步工具,它可以在本地主机和远程主机之间进行同步操作,或者在本地文件系统中进行同步操作)把可执行文件拷贝到本机目录(考虑到可执行文件比较大,估计不适合直接放到版本管理库里),并且用md5sum检查拷贝之后的文件是否与源文件相同。部署可执行文件这一步骤应该可以用脚本自动执行(比方说ssh $host rsync /path/to/source/on/nfs /path/to/local/copy/)。为了让C++可执行文件拷贝到host上就能用,通常采用静态链接,以避免.so版本不同造成故障。
Sudoku Solver的配置文件会放到版本管理工具里,每个Solver instance可能有自己的branch,每次修改都必须入库。程序启动的时候用的配置文件必须从SVN里check-out,不能手工修改(减少人为错误)。
管理
第一次启动进程的时候,会从SVN check-out配置文件;以后重启进程的时候可以从本地working copy读取配置文件(避免SVN服务器故障对系统造成影响),只在改过配置文件之后才要求svn update。服务进程使用daemon方式管理(/sbin/init(Linux系统中的初始化进程,它是操作系统启动时第一个被启动的进程,它的主要职责是初始化系统并启动其他系统进程)或upright工具(一个由Advanced Micro Devices(AMD)开发的用于系统和硬件监控的命令行工具)),crash之后会立刻自动重启(利用respawn功能,该功能在一个进程崩溃或停止运行后,系统会自动重新启动该进程,以保持系统的稳定性和连续性)。服务进程一般会随host启动而启动(放到/etc/init.d(Linux系统中用于存放系统启动脚本的目录,在Linux系统启动过程中,init进程会读取/etc/init.d目录下的启动脚本,并按照一定顺序执行这些脚本)里),如果要重启hostA上的服务进程,可以通过SSH远程操作(比如在本机运行ssh hostA /etc/init.d/sudoku-solver restart)。进程管理是分散的,每台host运行哪些service完全由本机的/etc/init.d目录决定。把一个service从一台host迁移到另一台host,需要登录到这两台host上去做一些手工配置。
升级
可执行文件也有一套版本管理(不一定通过SVN),发布新版本的时候严禁覆盖已有的可执行文件。比方说,现在运行的是/path/to/SudokuSolver/1.0.0/bin/sudoku-solver,那么新版本的Sudoku Solver会发布到/path/to/SudokuSolver/1.1.0/bin/sudoku-solver。
这么做的原因是,对于C++服务程序,如果在程序运行的时候覆盖了原有的可执行文件,那么可能会在一段时间之后出现bus error,程序因SIGBUS而crash。另外,如果程序发生core dump,那么验尸(post mortem)的时候必须用“产生core dump的可执行文件”配合core文件。如果覆盖了原来的可执行文件,post mortem将无法进行。
配置
Web Server的配置文件里写上Sudoku Solver的host:port(比境界1有所提高,境界1使用ip,这里使用host,依赖DNS,通常DNS有一主一备,可靠性足够高)。不过Web Server的配置文件和Sudoku Solver的配置文件是独立的,如果新增了Sudoku Solver或者迁移了host,除了修改Sudoku Solver的配置文件外,还要修改所有用到它的Web Server的配置文件。这在系统规模比较小的时候尚且可行,系统规模一大,这种服务之间的依赖关系会变得隐晦。如果关闭了某个服务程序,就可能一不小心造成其他组的某个服务失灵。如孟岩在《通过一个真实故事理解SOA监管》(http://blog.csdn.net/myan/archive/2007/08/09/1734343.aspx)举得那个例子一样。
监控
公司会使用一些开源的监控工具(以下以Monit(一个用于监控Unix系统上进程、文件系统、文件、网络连接等资源的工具,它旨在帮助系统管理员确保系统的稳定性,自动进行故障检测和恢复)为例)来监控每台host的资源使用情况(内存、CPU、磁盘空间、网络带宽等等)。必要的话可以写一些插件,使之能监控我们自己写的服务程序(Sudoku Solver)。但是这些监控工具通常只是观察者,它们与进程管理工具是独立的,只能看,不能动。这些监控工具有自己的配置文件,这些配置需要与Sudoku Solver的配置同步修改。Monit可以管理进程,但是它判断服务进程是否能正常工作是通过定时轮询进行的,不一定能立刻(几秒之内)发现问题。
在这个境界,分布式系统已经基本可用了,但也有一些隐患。
配置零散
每个服务程序有自己独立的配置,但是整个系统没有全局的部署配置文件(比方说哪个服务程序应该运行在哪些host上)。
服务程序的配置文件和用到此服务的客户端程序的配置是独立的,如果把Sudoku Solver迁移到另一台host,那么不仅要修改Sudoku Solver的配置,还要修改用到Sudoku Solver的Web Server的配置,以及监控Sudoku Solver的Monit的配置。如果忘记修改其中的一处,就会造成系统故障。
分布式系统中服务程序的依赖关系是个令人头疼的问题,“依赖”还好办(程序的作者知道自己这个服务程序会依赖哪些其他服务),“被依赖”则比较棘手(如何才能知道停掉自己这个程序会不会让公司其他系统崩溃?)。这也从一个侧面证明使用TCP协议作为唯一的IPC手段的必要性。如果采用TCP通信,为了查出有哪些程序用到了我的Sudoku Solver(假设listening port是9981),那么我只要运行netstat -tpn | grep 9981就能找到现在的客户;或者让Suduko Solver自己打印accept(2) log,连续检查一周或者一个月就能知道有哪些程序用到了Sudoku Solver。
进程管理分散
如果hostA发生硬件故障,如何能快速地用一台备用服务器硬件顶替它?能否先把它上面原来运行的Sudoku Solver迁移到空闲的hostB上,然后通知Web Server用hostB上的Sudoku Solver?“通知Web Server”这一步要不要重启Web Server?
9.8.3 境界3:自制机群管理系统,集中化配置
这可能是比较成熟的大公司的水平。
境界2中的分散式进程管理已经不能满足业务灵活性方面的需求,公司开始整合现有的运维工具,开发一套自己的机群管理软件。作者还没有找到一个开源的符合作者的要求的机群管理软件,以下虚构一套名为Zurg(http://en.wikipedia.org/wiki/Google_platform#Software)(名字取自科幻电影《第五元素》,拼写稍有不同;Zurg也是《玩具总动员》中的一个角色)的分布式系统管理软件(Slave的实现代码见http://github.com/chenshuo/muduo-protorpc附带的例子)。
Zurg的架构很简单,典型的Master/Slave结构,见第三章“管理Linux服务器机群”的描述(见图9-19)。图9-19中矩形为服务器,圆角矩形为进程,实线箭头表示TCP连接,虚线表示进程的父子关系。
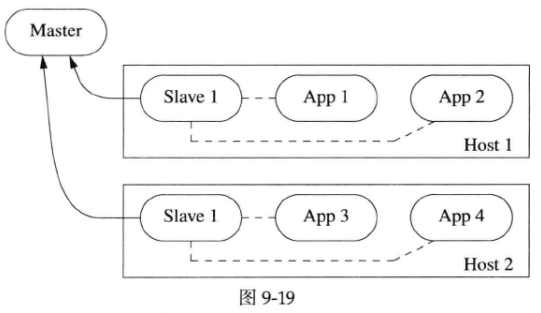
在《分布式系统的工程化开发方法》(http://blog.csdn.net/Solstice/article/details/5950190)中谈到了Zurg的功能需求:
1.典型的Master/Slave/Client结构。
2.一个Master进程,兼做name service。可用冷热备份(冷备份是指将Master进程暂停或者关闭,然后将其配置和状态保存到备份服务器中,热备份是指在主进程运行期间,实时将其数据和状态拷贝到备份服务器),或者用consensus多点状态同步(consensus是一种多点状态同步的机制,它确保多个节点之间的状态是一致的,有了consensus机制进行状态同步,就相当于冷备份或热备份Master进程了)。如果Master意外重启,全部Slave都会自动重连。
3.每个节点运行一个Slave进程。定期向Master汇报该节点的资源使用率,控制其他服务进程的启停,捕获SIGCHLD信号,及时知道服务进程(图9-19中的App)意外退出(如果Slave意外重启,如何避免重复启动服务?)。
4.到了这一境界,日常的管理运维工作已经不再需要反复执行ssh,常见任务都可通过Zurg来完成。
部署
只需要向Master发一条指令,Master会命令Slave从指定的地点rsync新的可执行文件到本地目录。
进程管理与监控
Zurg的主要功能就是进程管理和监控,比起一般的开源工具,Zurg更具备一些优势。由于Sudoku Solver是由Zurg Slave fork(2)而得的,那么当Sudoku Solver crash的时候,Zurg Slave会立刻收到SIGCHLD,从而能立刻向管理员报告状态并重启。这比Monit的轮询要迅速得多(还可以在fork()之前做一些手脚,让Zurg Slave能更方便地获得Sudoku Solver的存活状态。比方说,打开一对pipe,让子进程继承写端fd,在父进程中关注读端fd的readable事件。这样一旦子进程退出,父进程Zurg Slave立刻就能读到EOF,这比用SIGCHLD signal更可靠)。
为了安全起见,Zurg Slave在启动可执行文件的时候可以验证其md5,这样避免错误版本的服务程序运行在生产环境。
Zurg Master可以提供一个Web页面以供查看本机群内各个服务程序是否正常运行,并且提供一个接口(可以是HTTP)让我们能编写脚本来控制Zurg Master。
升级
如果要主动重启Sudoku Solver,可以向Zurg Master发出指令,不需要用ssh & kill。Zurg会保存每台host上服务进程的启动记录,以便事后分析。如果用境界2中的手动/etc/init.d管理方式,需要到每台机器上收集log才知道Sudoku Solver什么时候重启过。
另外也可以单独开发GUI程序,运行在运维人员桌面上,重启多台host上的Sudoku Solver只需要轻点几下鼠标。
配置
零散的配置文件被集中的Zurg配置文件取代。
Zurg配置文件会制定哪些service会在哪些host上运行,Zurg Master读取配置文件,然后命令各个Zurg Slave启动相应的服务程序。比方说配置文件指定Sudoku Solver运行在host1、host2、host3上,那么Zurg会通知在host1、host2、host3上的Zurg Slave启动Sudoku Solver(当然,每台host上的Zurg Slave需要由/etc/init.d启动,其他的服务程序都由它负责启动)。
更重要的是,服务程序之间的依赖关系在Zurg配置文件里直接体现出来。比方说,在Zurg配置文件里指明Web Server依赖Sudoku Solver,Web Server的配置文件由Zurg Master生成(可能会用到模板引擎,读入一个Web Server的配置模板),其中出现的Sudoku Solver的host:port由Zurg Master自动填上,这样如果把Sudoku Solver从hostA迁移到hostB,只需要改一处地方(Zurg的配置),而Sudoku Solver和Web Solver的配置都由Zurg Master自动生成。这样大大降低了犯错误的机会。
到了这一境界,分布式系统的日常管理已经基本成熟,但在容错与负载均衡方面有较大的提升空间。
目前最大的障碍是DNS,它限制了快速failover。比方说,如果hostA发生硬件故障,Zurg Master固然可以在hostB上立刻启动Sudoku Solver,但是如何通知Web Server到hostB上享用服务呢?修改DNS entry的话(把hostA的域名解析到hostB的IP),可能要好几分钟才能完成更新,因为DNS没有推送机制。
如果思路受限制于host:port,那么会采取一些看似高级,实则笨拙的高可用(high availability)解决方案。比方说在内核里做做手脚,设法让两台机器共享同一个IP,然后通过专门的心跳连线来控制哪台host对外提供服务,哪台是备用机。如果那台“主机”发生故障,则可以快速(几秒)切换到备用机,因为hostname和IP地址是相同的,客户端不用重新配置或重启,只要重新连接TCP就能完成failover。如果在错误的道路上走得更远一点,可能还会设法把TCP连接一同迁移到备用机,这样客户端甚至不需要断开并重连。
Load balance也受限于DNS
如果发现现有的4个Sudoku Solver不堪重负,又部署了4台Sudoku Solver,如何通知各个Web Server把新的Sudoku Solver加到连接池里?
有一些ad hoc(含义是简单的、易于实现的)的手段,比方说每个Web Server有一个管理接口,可以通过这个接口向它动态地增减Sudoku Solver的地址。借助这个管理接口,我们也可以做一些计划中的联机迁移。比方说要主动把某个Sudoku Solver从hostA迁移到hostB,我们可以先在hostB上启动Sudoku Solver,然后通过Web Server的管理接口把hostB:9981添加到Web Server的连接池中,再把hostA:9981从连接池中删掉,最后停掉hostA上的Sudoku Solver。这对计划中的Sudoku Solver升级是可行的,能做到避免中断Web Server服务。对于failover,这种做法似乎稍显不够方便,因为要让Zurg Master理解Web Server的管理接口,会给系统带来循环依赖(正常情况下,Zurg Master不应该知道或访问它管理的服务程序的接口细节,这样Sudoku Solver升级的时候就不用升级Zurg Master,而上述方法中,为了完成Soduku Solver的迁移,Zurg Master需要理解并访问Web Server的管理接口)。
这种做法要求Web Server在开发的时候留下适当的维修探查通道,见9.5的推荐做法。
另外一种ad hoc的手段,每个Sudoku Solver在启动的时候自己主动往某个数据库表里insert或update本程序的host:port。Web Server的配置里写的不是host:port,而是一条SELECT语句,用于找出它依赖的Sudoku Solver的host:port。Web Server还可以通过数据库触发器来及时获知Sudoku Solver address list的变化。这样增加或减少Sudoku Server的话,Web Server几乎可以立刻应对,也不需要通过管理接口来手工增减Sudoku Solver地址。数据库在这里扮演了naming service的角色,它的可用性直接影响了整个系统的可用性。
境界3是黎明前的黑暗,只要统一引入naming service,抛开DNS,容错和负载均衡的问题便迎刃而解。
9.8.4 境界4:机群管理与naming service结合
这是业内领先的公司的水平。
前面分析到,使用Zurg机群管理软件能大大简化分布式系统的日常运维,但是它也有很大的缺陷——不能实现快速failover。如果系统规模大到一定程度,机器出故障的频率会显著增加,这时候自动化的快速failover是必备的,否则运维人员就会疲于奔命地“救火”。
实现简单而快速的failover不需要特殊的编程技巧,也不需要对kernel动手脚,只要抛弃传统的DNS观念,摆脱host:port的束缚,采用为分布式系统特制的naming service代替DNS即可。
naming service是实现快速failover的必备条件。Host A上的服务S1崩溃了,failover到Host B上,如何把新的地址(或端口号)通知给S1的使用者?为什么DNS不适合?DNS设计上作为静态或缓慢变化的域名解析,DNS客户端与DNS服务器之间采用超时轮询而不是主动通知,不适合快速failover。DNS也不能解析端口号(除非使用不常用的SRV RR记录(DNS中的一种资源记录类型,用于指定提供特定服务的服务器的信息,包括服务的协议、服务名称、域名、优先级、权重和端口等信息),见RFC 2782)。解决办法是:实现自己的名字服务,并在程序的配置中使用service_name而不是host:port。例子:Chubby(Google公司开发的一个分布式锁服务,主要用于协调和管理分布式系统中的共享资源和元数据,它还提供了一个分层的文件系统和命名空间,允许应用程序组织和存储共享配置、元数据等信息,这使得Chubby不仅仅是一个锁服务,还是一个可用于存储和共享分布式系统配置的数据存储服务)、ZooKeeper、Eureka(Netflix开源的一款基于REST(Representational State Transfer,是一种面向资源的软件架构风格,通常用于构建分布式系统和基于网络的应用程序,它强调了系统的可伸缩性、性能和可移植性,RESTful架构是一种设计风格,强调简单、统一的接口,以及无状态的通信)的服务发现框架,用于构建和管理微服务架构中的服务注册和发现)(http://techblog.netflix.com/2012/09/eureka.html)。
naming service的功能是把一个service_name解析成list of ip:port。比方说,查询“sudoku_solver”,返回host1:9981、host2:9981、host3:9981。
naming service与DNS最大的不同在于它能把新的地址信息推送给客户端。比方说,Web Server订阅了“sudoku_solver”,每当sudoku_solver发生变化,Web Server就会立刻收到更新。Web Server不需要轮询,而是等候通知。
naming service谁负责更新
在境界2中,Sudoku Solver会自己主动去naming server注册。到了境界3,由于Sudoku Solver是由Zurg负责启动的,那么Zurg知道Sudoku Solver运行在哪些hosts上,它会主动更新naming service,不需要Sudoku Solver自己动手。
naming service的可用性(availability)和一致性如何保证
毫无疑问,一旦采用这种方案,naming service是系统正常运转的关键,它的可用性决定了系统的可用性。naming service绝对不能只run在一台服务器上,为了可靠性,应该用一组(通常是5台)服务器同时提供服务。当然,这需要解决一致性问题。目前实现高可用naming service的公认办法是Paxos算法,也有了一些开源的实现(ZooKeeper、KeySpace、Doozer)。
对程序设计的影响
如果公司的网络库在设计的时候就考虑了naming service,那么对程序设计来说是透明的。配置文件里写的不再是host:port,而是service_name,交给网络库去解析成ip:port地址列表。
为什么muduo网络库没有封装DNS解析
一方面因为gethostbyname()和getaddrinfo()解析DNS是阻塞的(除非用UDNS之类的异步DNS库);另一方面,因为在大规模分布式系统中DNS的作用不大,作者宁愿花时间实现一个naming service,并且为它编写name resolve library。
在境界3中,每个项目组有自己的hosts,只运行本项目中的服务程序,每个服务程序的TCP端口可以静态分配(比如Sudoku Solver固定使用9981端口),不担心端口冲突。如果公司规模继续扩大,迟早会把16-bit的port命名空间用完,这时候给新项目分配端口号将成为问题。
到了境界4,这一限制将被打破,服务程序可以run在公司内任何一台host上,也不用担心端口冲突,因为Zurg会选择当前host的空闲端口来启动Sudoku Solver,并且把选中的端口保存在naming service中。这样一来,TCP port也实现了动态配置,Web Server完全能自动适应run在不同port的Sudoku Solver。














 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









