







4.1 函数调用
函数是Go语言中的一等公民(First-class citizen,即函数可以像其他基础数据类型一样,可以赋值、传递、作为返回值返回、存储),理解和掌握函数的调用过程是我们深入学习Go无法跳过的,本节将从函数的调用惯例和参数的传递方法两个方面分别介绍函数的执行过程。
4.1.1 调用惯例
无论是系统级编程语言C和Go,还是脚本语言Ruby和Python,这些编程语言在调用函数时往往都使用相同的语法:
somefunction(arg0, arg1)
虽然它们调用函数的语法很相似,但是它们的调用惯例却可能大不相同。调用惯例是调用方和被调用方对于参数和返回值传递的约定,我们将在这里为各位读者分别介绍C和Go语言的调用惯例。
C语言
我们先来研究C语言的调用惯例,使用GCC和Clang编译器将C语言编译成汇编代码是分析它调用惯例的最好方法,从汇编语言中可以一窥函数调用的具体过程。
GCC和Clang编译相同C语言代码可能会生成不同的汇编指令,不过生成的代码在结构上不会有太大的区别,所以对只想理解调用惯例的人来说没有太多影响。作者在本节中选择使用GCC编译器来编译C语言:
假设我们有以下的C代码,代码中只包含两个函数,其中一个是主函数main,另一个是我们定义的函数my_function:
// ch04/my_function.c
int my_function(int arg1, int arg2) {
return arg1 + arg2;
}
int main() {
int i = my_function(1, 2)
}
我们可以使用cc -S my_function.c(cc通常是gcc或其他编译器的符号链接,-S选项告诉编译器只进行到汇编这一步,不会继续生成目标代码或可执行文件)命令将上述文件编译成如下所示的汇编代码:
main:
// 将当前的基址指针(base pointer)压栈,以保存函数调用前的栈帧基址
pushq %rbp
// 将当前的栈指针的值覆盖掉基址指针,设置了要调用函数(即main)的栈帧基址
// 使后续操作可用%rbp访问局部变量
movq %rsp, %rbp
// 将栈指针向下移动16字节,保证栈对齐,同时对齐的空间可作为main函数的本地变量分配的空间
// 通常在调用函数前需要保持栈对齐,以提高性能
subq $16, %rsp
// movl表示move long,作用是移动一个32位值,将常数2加载到寄存器%esi中
movl $2, %esi // 设置第二个参数
// 将常数1加载到寄存器%edi中
movl $1, %edi // 设置第一个参数
// 调用my_function,call将当前指令压栈,然后跳转到my_function函数的地址执行
call my_function
// 将my_function的返回值(存储在寄存器%eax中)加载到栈上以%rbp为基址,以-4为偏移的位置
movl %eax, -4(%rbp)
my_function:
// 同main函数的开头,保存函数调用前的栈帧基址
pushq %rbp
// 同main函数的开头,设置栈帧基址
movq %rsp, %rbp
// 从寄存器中取出两个参数
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
// 将两个参数加载到另外两个寄存器中
movl -8(%rbp), %eax // eax = edi = 2
movl -4(%rbp), %edx // edx = esi = 1
// 将寄存器%edx和%eax中的值相加
addl %edx, %eax // eax = eax + edx = 2 + 1 = 3
// 从栈顶弹出保存的基址指针,恢复调用前的栈帧基址
popq %rbp
我们按照my_function函数调用前、调用时以及调用后三个部分分析上述调用过程:
1.在my_function调用之前,调用方main函数将my_function的两个参数分别存到edi和esi寄存器中;
2.在my_function执行时,它会将寄存器edi和esi中的数据存储到eax和edx两个寄存器中,随后通过汇编指令addl计算两个入参之和;
3.在my_function调用之后,使用寄存器eax传递返回值,main函数将my_function的返回值存储到栈上的i变量中;
当my_function函数的入参增加至八个,这时重新编译当前程序会得到不同的汇编代码:
main:
// 将当前的基址指针入栈
pushq %rbp
// 将当前的栈指针的值复制到基址指针,设置当前调用函数(main函数)的基址指针
movq %rsp, %rbp
// 将栈指针向下移动16字节,给栈上分配空间
subq $16, %rsp // 为参数传递申请16字节的栈空间
// 将常数8放到以栈指针为基准,偏移量为8的位置,这是第8个参数
movl $8, 8(%rsp) // 传递第8个参数
// 将常数7放到以栈指针为基准,偏移量为0的位置,这是第7个参数
movl $7, (%rsp) // 传递第7个参数
// 依次将前6个参数加载到寄存器
movl $6, %r9d
movl $5, %r8d
movl $4, %ecx
movl $3, %edx
movl $2, %esi
movl $1, %edi
// 调用my_function,将当前的指令地址压栈,然后跳转到my_function的地址执行
call my_function
main函数调用my_function时,前六个参数是使用edi、esi、edx、ecx、r8d、r9d六个寄存器传递的。寄存器的使用顺序也是调用惯例的一部分,函数的第一个参数一定会使用edi寄存器,第二个参数使用esi寄存器,以此类推。
最后两个参数与前面的完全不同,调用方main函数通过栈传递这两个参数,图4-1展示了main函数在调用my_function前的栈信息:
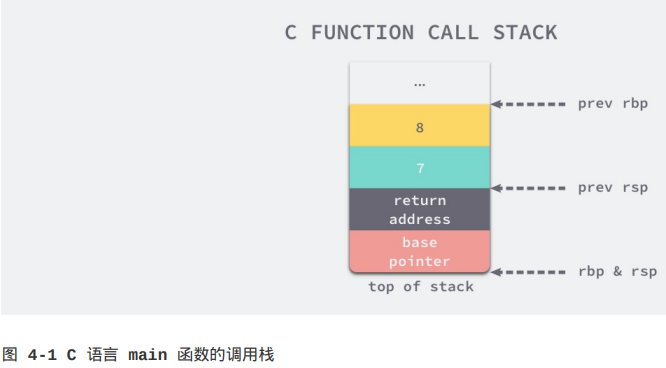
上图中rbp寄存器的作用是存储函数调用栈的基址指针,即属于main函数的栈空间的起始位置,而另一个寄存器rsp存储的是main函数调用栈结束的位置,这两个寄存器共同表示了一个函数的栈空间。
在调用my_function之前,main函数通过subq $16, %rsp指令分配了16个字节的栈地址,随后将第六个以上的参数按照从右到左的顺序存入栈中,即第八个和第七个,余下的六个参数会通过寄存器传递,接下来运行的call my_function指令会调用my_function函数:
my_function:
// 将基址指针入栈,保存调用者的基址指针
pushq %rbp
// 将栈指针的值复制到基址指针,设置当前my_function函数的基址指针
movq %rsp, %rbp
// 将寄存器%edi的值复制到以基址指针%rbp为基准,偏移量为-4处,这是第一个参数
movl %edi, -4(%rbp) // rbp-4 = edi = 1
// 将寄存器%esi的值复制到以基址指针%rbp为基准,偏移量为-8处,这是第二个参数
movl %esi, -8(%rbp) // rbp-8 = esi = 2
// ...
// 将第二个参数的值复制到寄存器%eax
movl -8(%rbp), %eax // eax = 2
// 将第一个参数的值复制到寄存器%edx
movl -4(%rbp), %edx // edx = 1
// 将第一个和第二个参数的值相加,结果存入寄存器%edx
addl %eax, %edx // edx = eax + edx = 3
// ...
// 将第七个参数的值复制到寄存器%eax
movl 16(%rbp), %eax // eax = 7
// 加上第七个参数的值,结果存入寄存器%edx
addl %eax, %edx // edx = eax + edx = 28
// 将第八个参数的值复制到寄存器%eax
movl 24(%rbp), %eax // eax = 8
// 加上第八个参数的值,结果存入寄存器%eax
addl %edx, %eax // edx = eax + edx = 36
popq %rbp
my_function会先将寄存器中的全部数据转移到栈上,然后利用eax寄存器计算所有入参的和并返回结果。
我们可以将本节的发现和分析简单总结成——当我们在x86_64的机器上使用C语言中的函数调用时,参数都是通过寄存器和栈传递的,其中:
1.六个以及六个以下的参数会按照顺序分别使用edi、esi、edx、ecx、r8d、r9d六个寄存器传递;
2.六个以上的参数会使用栈传递,函数的参数会以从右到左的顺序依次存入栈中;
而函数的返回值是通过eax寄存器进行传递的,由于只使用一个寄存器存储返回值,所以C语言的函数不能同时返回多个值。
Go语言
分析了C语言函数的调用惯例之后,我们再来剖析一下Go语言中函数的调用惯例。我们以下面这个非常简单的代码片段为例简要分析一下:
package main
func myFunction(a, b int) (int, int) {
return a + b, a - b
}
func main() {
myFunction(66, 77)
}
上述的myFunction函数接受两个整数并返回两个整数,main函数在调用myFunction时将66和77两个参数传递到当前函数中,使用go tool compile -S -N -l main.go命令(-S选项输出汇编代码,-N选项禁用优化,-l禁用函数内联)编译上述代码可以得到如下所示的汇编指令:
注:如果编译时不使用-N -l参数,编译器会对汇编代码进行优化,编译结果会有较大差别。
// ""表示包名,空串表示匿名包,即main包
// main表示函数名
// STEXT表示符号是一个文本段中的函数
// size=68表示函数大小为68字节
// args=0x0表示此函数没有参数
// locals=0x28表示本地变量占用0x28(40)字节
"".main STEXT size=68 args=0x0 locals=0x28
// 将线程局部存储(TLS)中的值移动到寄存器CX中
0x0000 00000 (main.go:7) MOVQ (TLS), CX
// 比较栈指针SP和CX寄存器偏移16字节处的值,这是在进行栈检查,确保栈空间足够
0x0009 00009 (main.go:7) CMPQ SP, 16(CX)
// 如果SP的值小于等于16(CX),则跳转到地址61
0x000d 00013 (main.go:7) JLS 61
// 栈指针向下移动40字节,为main函数分配栈空间
0x000f 00015 (main.go:7) SUBQ $40, SP // 分配40字节栈空间
// 将当前基址指针的值(main函数的基址指针)复制到栈上偏移量为32字节的位置
0x0013 00019 (main.go:7) MOVQ BP, 32(SP) // 将基址指针存储到栈上
// 将SP的值加32加载到BP中,这设置了新的栈帧基址
0x0018 00024 (main.go:7) LEAQ 32(SP), BP
// 将常数66存储到栈顶(SP)位置
0x001d 00029 (main.go:8) MOVQ $66, (SP) // 第一个参数
// 将常数77存储到栈顶偏移8字节的位置
0x0025 00037 (main.go:8) MOVQ $77, 8(SP) // 第二个参数
// 调用函数,SB是静态基址寄存器,指向全局符号表
0x002e 00046 (main.go:8) CALL "".myFunction(SB)
// 从栈顶偏移32字节的位置恢复先前保存的基址指针BP
0x0033 00051 (main.go:9) MOVQ 32(SP), BP
// 释放先前分配的栈空间
0x0038 00056 (main.go:9) ADDQ $40, SP
0x003c 00060 (main.go:9) RET
根据main函数生成的汇编指令,我们可以分析出main函数调用myFunction之前的栈情况:
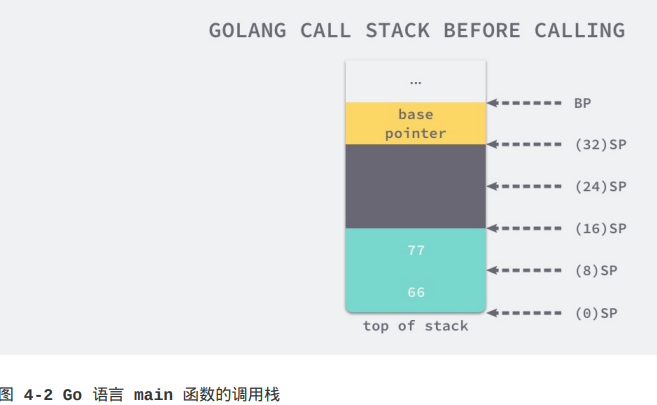
main函数通过SUBQ $40, SP指令一共在栈上分配了40字节的内存空间:

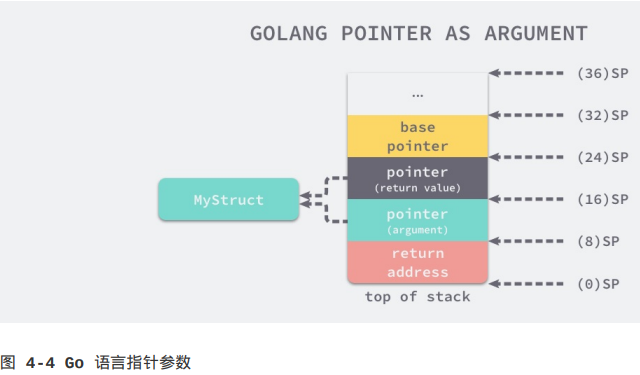
myFunction入参的压栈顺序和C语言一样,都是从右往左,即第一个参数66在栈顶的SP~SP+8,第二个参数存储在SP+8~SP+16的空间中(即先压栈第二个参数,再压栈第一个参数)。
当我们准备好函数的入参后,会调用汇编指令CALL "".myFunction(SB),这个指令首先会将main的返回地址存入栈中,然后改变当前的栈指针SP并开始执行myFunction的汇编指令:
"".myFunction STEXT nosplit size=49 args=0x20 locals=0x0
// 将常数0移动到以栈指针为基准,偏移量为24的位置,这个位置是返回值r2,相当于初始化返回值r2为0
0x0000 00000 (main.go:3) MOVQ $0, "".-r2+24(SP) // 初始化第一个返回值
// 将常数0移动到以栈指针为基准,偏移量为32的位置,这个位置是返回值r3,相当于初始化返回值r3为0
0x0009 00009 (main.go:3) MOVQ $0, "".-r3+32(SP) // 初始化第二个返回值
// 将参数a的值从栈指针偏移8的位置移动到寄存器AX
0x0012 00018 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
// 将参数b的值(栈指针偏移为16的位置)与寄存器AX的值相加
0x0017 00023 (main.go:4) ADDQ "".b+16(SP), AX // AX = AX + 77 = 143
// 将寄存器AX的值移动到栈指针偏移为24的位置,即将AX的值作为第一个返回值
0x001c 00028 (main.go:4) MOVQ AX, "".-r2+24(SP) // (24)SP = AX = 143
// 将参数a的值从栈指针偏移8的位置移动到寄存器AX
0x0021 00033 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
// 将寄存器AX的值减去参数b的值(栈指针偏移为16的位置),结果存在寄存器AX中
0x0026 00038 (main.go:4) SUBQ "".b+16(SP), AX // AX = AX - 77 = -11
// 将寄存器AX的值移动到栈指针偏移32的位置,存储第二个返回值
0x002b 00043 (main.go:4) MOVQ AX, "".-r3+32(SP) // (32)SP = AX = -11
0x0030 00048 (main.go:4) RET
从上述的汇编代码中我们可以看出,当前函数在执行时首先会将main函数中预留的两个返回值地址置成int类型的默认值0,然后根据栈的相对位置获取参数并进行加减操作并将值存回栈中,在myFunction函数返回之前,栈中的数据如图4-3所示:

在myFunction返回之后,main函数会通过以下的指令来恢复栈基址并销毁已经失去作用的40字节的栈空间:
// 恢复main函数的基址指针,调用myFunction前,我们将main的基址指针保存到了栈指针偏移32的位置,现恢复
0x0033 00051 (main.go:9) MOVQ 32(SP), BP
// 回收为myFunction函数分配的40字节栈帧
0x0038 00056 (main.go:9) ADDQ $40, SP
0x003c 00060 (main.go:9) RET
通过分析Go语言编译后的汇编指令,我们发现Go语言使用栈传递参数和接收返回值,所以它只需要在栈上多分配一些内存就可以返回多个值。
思考
C语言和Go语言在设计函数的调用惯例时选择了不同的实现。C语言同时使用寄存器和栈传递参数,使用eax寄存器传递返回值;而Go语言使用栈传递参数和返回值。我们可以对比一下这两种设计的优点和缺点:
1.C语言的方式能够极大地减少函数调用的额外开销,但是也增加了实现的复杂度;
(1)CPU访问栈的开销比访问寄存器高几十倍;
(2)需要单独处理函数参数过多的情况;
2.Go语言的方式能够降低实现的复杂度并支持多返回值,但是牺牲了函数调用的性能;
(1)不需要考虑超过寄存器数量的参数应该如何传递;
(2)不需要考虑不同架构上的寄存器差异;
(3)函数入参和出参的内存空间需要在栈上进行分配;
Go语言使用栈作为参数和返回值传递的方法是综合考虑后的设计,选择这种设计意味着编译器会更加简单、更容易维护。
4.1.2 参数传递
除了函数的调用惯例之外,Go语言在传递参数时是传值还是传引用也是一个有趣的问题,这个问题影响的是当我们在函数中对入参进行修改时会不会影响调用方看到的数据。我们先来介绍一下传值和传引用两者的区别:
1.传值:函数调用时会对参数进行拷贝,被调用方和调用方两者持有不相关的两份数据;
2.传引用:函数调用时会传递参数的指针,被调用方和调用方两者持有相同的数据,任意一方做出的修改都会影响另一方。
不同语言会选择不同的方式传递参数,Go语言选择了传值的方式,无论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝。本节剩下的内容将会验证这个结论的正确性。
整型和数组
我们先来分析Go语言是如何传递基本类型和数组的。如下所示的函数myFunction接收了两个参数,整型变量i和数组arr,这个函数会将传入的两个参数的地址打印出来,在最外层的主函数也会在myFunction函数调用前后分别打印两个参数的地址:
func myFunction(i int, arr [2]int) {
fmt.Printf("in my_function - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
func main() {
i := 30
arr := [2]int{66, 77}
fmt.Printf("before calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
myFunction(i, arr)
fmt.Printf("after calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
运行它:

通过运行这段代码我们会发现,main函数和被调用者myFunction中参数的地址是完全不同的。
不过从main函数的角度来看,在调用myFunction前后,整数i和数组arr两个参数的地址都没有变化。那么如果我们在myFunction函数内部对参数进行修改是否会影响main函数中的变量呢?我们更新myFunction函数并重新执行这段代码:
func myFunction(i int, arr [2]int) {
i = 29
arr[1] = 88
fmt.Printf("in my_function - i=(%d, %p) arr=(%v %p)\n", i, &i, arr, &arr)
}
运行它:

可以看到在myFunction中对参数的修改也仅仅影响了当前函数,并没有影响调用方main函数,所以我们能给出如下结论——Go语言中对于整型和数组类型的参数都是值传递的,也就是在调用函数时会对内容进行拷贝,需要注意的是如果当前数组的大小非常大,这种传值方式就会对性能造成比较大的影响。
结构体和指针
接下来我们继续分析Go语言另外两种常见类型——结构体和指针。在这段代码中定义一个只包含一个成员变量的简单结构体MyStruct以及接受两个参数的myFunction方法:
type MyStruct struct {
i int
}
func myFunction(a MyStruct, b *MyStruct) {
a.i = 31
b.i = 41
fmt.Printf("in my_function - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
func main() {
a := MyStruct{i: 30}
b := &MyStruct{i: 40}
fmt.Printf("before calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
myFunction(a, b)
fmt.Printf("after calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
运行它:
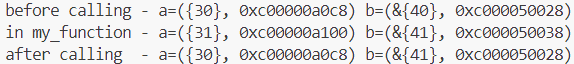
从运行的结果我们可以得出如下结论:
1.传递结构体时:会对结构体中的全部内容进行拷贝;
2.传递结构体指针时,会对结构体指针进行拷贝;
对结构体指针的修改是改变了指针指向的结构体,b.i可以被理解成(*b).i,也就是我们先获取指针b指向的结构体,再修改结构体的成员变量。我们简单修改上述代码,分析一下Go语言结构体在内存中的布局:
type MyStruct struct {
i int
j int
}
func myFunction(ms *MyStruct) {
ptr := unsafe.Pointer(ms)
for i := 0; i < 2; i++ {
c := (*int)(unsafe.Pointer((uintptr(ptr) + uintptr(8*i))))
*c += i + 1
fmt.Printf("[%p] %d\n", c, *c)
}
}
func main() {
a := &MyStruct{i: 40, j: 50}
myFunction(a)
fmt.Printf("[%p] %v\n", a, a)
}
运行它:
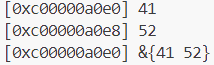
在这段代码中,我们通过指针的方式修改结构体中的成员变量,结构体在内存中是一片连续的空间,指向结构体的指针也是指向这个结构体的首地址。将MyStruct指针修改成int类型的,那么访问新指针就会返回整型变量i,将指针移动8个字节后就能获取下一个成员变量j。
如果我们将上述代码简化成如下所示的代码片段并使用go tool compile进行编译会得到如下的结果:
type MyStruct struct {
i int
j int
}
func myFunction(ms *MyStruct) *MyStruct {
return ms
}
得到如下编译结果:
$ go tool compile -S -N -l main.go
// STEXT表示这个符号是文本段中的一个函数
// nosplit表示不会触发栈分裂,即不会进行栈检查和栈扩展
"".myFunction STEXT nosplit size=20 args=0x10 locals=0x0
// 将常数0移动到栈指针偏移16字节的位置,这是返回值r1的位置,相当于初始化返回值
0x0000 00000 (main.go:8) MOVQ $0, "".-r1+16(SP) // 初始化返回值
// 将参数ms(位于栈指针偏移8字节的位置)移动到寄存器AX
0x0009 00009 (main.go:9) MOVQ "".ms+8(SP), AX // 复制引用
// 将寄存器AX中的值移动到返回值r1的位置
0x000e 00014 (main.go:9) MOVQ AX, "".-r1+16(SP) // 返回引用
0x0013 00019 (main.go:9) RET
在这段汇编语言中我们发现当参数是指针时,也会使用MOVQ "".ms+8(SP), AX指令对引用进行复制,然后将复制后的指针作为返回值传递回调用方。
所以将指针作为参数传入某一函数时,在函数内部会对指针进行复制,也就是会同时出现两个指针指向原有的内存空间,所以Go语言中“传指针”也是传值。
传值
当我们对Go语言中大多数常见的数据结构进行验证之后,其实就能够推测出Go语言在传递参数时其实使用的就是传值的方式,接收方收到参数时会对这些参数进行复制;了解到这一点之后,在传递数组或者内存占用非常大的结构体时,我们在一些函数中应该尽量使用指针作为参数类型来避免发生大量数据的拷贝而影响性能。
4.1.3 小结
这一节我们详细分析了Go语言的调用惯例,包括传递参数和返回值的过程和原理。Go通过栈传递函数的参数和返回值,在调用函数之前会在栈上为返回值分配合适的内存空间,随后将入参从右到左顺序压栈并拷贝参数,返回值会被存储到调用方预留好的栈空间上,我们可以简单总结出以下几条规则:
1.通过堆栈传递参数,入栈的顺序是从右到左;
2.函数返回值通过堆栈传递并由调用者预先分配内存空间;
3.调用函数时都是传值,接收方会对入参进行复制再计算;
4.2 接口
Go语言中的接口就是一组方法的签名,它是Go语言的重要组成部分。使用接口能够让我们更好地组织并写出易于测试的代码,然而很多工程师对Go的接口了解都非常有限,也不清楚其底层的实现原理,这成为了开发高性能服务的最大阻碍。
本节会介绍使用接口时遇到的一些常见问题以及它的设计与实现,包括接口的类型转换、类型断言以及动态派发机制,帮助各位读者更好地理解接口类型。
4.2.1 概述
在计算机科学中,接口是计算机系统中多个组件共享的边界,不同的组件能够在边界上交换信息。如图4-5,接口的本质就是引入一个新的中间层,调用方可以通过接口与具体实现分离,解除上下游的耦合,上层的模块不再需要依赖下层的具体模块,只需要依赖一个约定好的接口。
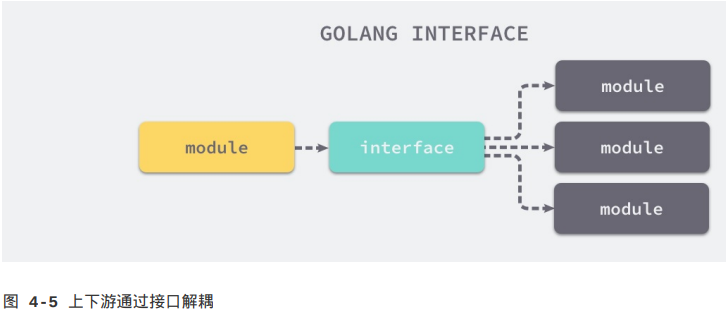
这种面向接口的编程方式有着非常强大的生命力,无论是在框架还是操作系统中我们都能够找到接口的身影。可移植操作系统接口(Portable Operating System Interface,POSIX)就是一个典型的例子,它定义了应用程序接口和命令行等标准,为计算机软件带来了可移植性——只要操作系统实现了POSIX,计算机软件就可以直接在不同操作系统上运行。
除了解耦有依赖关系的上下游,接口还能够帮助我们隐藏底层实现,减少关注点。《计算机程序的构造和解释》中有这么一句话:
代码必须能够被人阅读,只是机器恰好可以执行。
人能够同时处理的信息非常有限,定义良好的接口能够隔离底层的实现,让我们将重点放在当前的代码片段中。SQL就是接口的一个例子,当我们使用SQL语句查询数据时,其实不需要关心底层数据库的具体实现,我们只在乎SQL返回的结果是否符合预期。
计算机科学中的接口是一个比较抽象的概念,但是编程语言中接口的概念就更加具体。Go语言中的接口是一种内置的类型,它定义了一组方法的签名,这一小节会先介绍Go语言接口的几个基本概念以及常见问题,为之后介绍实现原理做一些铺垫。
隐式接口
很多面向对象语言都有接口这一概念,例如Java和C#。Java的接口不仅可以定义方法签名,还可以定义变量,这些定义的变量可以直接在实现接口的类中使用:
public interface MyInterface {
public String hello = "Hello";
public void sayHello();
}
上述代码定义了一个必须实现的方法sayHello和一个会注入到实现类的变量hello。在下面的代码中,MyInterfaceImpl就实现了MyInterface接口:
public class MyInterfaceImpl implements MyInterface {
public void sayHello() {
System.out.println(MyInterface.hello)
}
}
Java中的类必须通过上述方式(即使用implements)显式地声明实现的接口,但是在Go语言中实现接口就不需要使用类似的方式。首先,我们简单了解一下在Go语言中如何定义接口。定义接口需要使用interface关键字,在接口中我们只能定义方法签名,不能包含成员变量,一个常见的Go语言接口是这样的:
type error interface {
Error() string
}
如果一个类型需要实现error接口,那么它只需要实现Error() string方法,下面的RPCError结构体就是error接口的一个实现:
type RPCError struct {
Code int64
Message string
}
func (e *RPCError) Error() string {
return fmt.Sprintf("%s, code=%d", e.Message, e.Code)
}
细心的读者可能会发现上述代码根本就没有error接口的影子,这是为什么呢?Go语言中接口的实现都是隐式的,我们只需要实现Error() string方法就实现了error接口。Go语言实现接口的方式与Java完全不同:
1.在Java中:实现接口需要显式地声明接口并实现所有方法;
2.在Go中:实现接口的所有方法就隐式地实现了接口;
我们使用上述RPCError结构体时并不关心它实现了哪些接口,Go语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查,这里举几个例子来演示发生接口类型检查的时机:
func main() {
// 此处不知道为什么要进行类型检查,NewRPCError函数返回类型为error,rpcErr变量的类型也是error
// 并且NewRPCError函数中,在返回值时已经进行了类型检查
var rpcErr error = NewRPCError(400, "unknown err") // typecheck1
err := AsErr(rpcErr) // typecheck2
println(err)
}
func NewRPCError(code int64, msg string) error {
return &RPCError { // typecheck3
Code: code,
Message: msg,
}
}
func AsErr(err error) error {
return err
}
Go语言会编译期间对代码进行类型检查,上述代码总共触发了三次类型检查:
1.将*RPCError类型的变量赋值给error类型的变量rpcErr;
2.将*RPCError类型的变量rpcErr传递给签名中参数为error的AsErr函数;
3.将*RPCError类型的变量从函数返回值类型为error的NewRPCError的函数中返回;
从类型检查的过程来看,编译器仅在需要时才对类型进行检查,类型实现接口时只需要实现接口中的全部方法,不需要像Java等编程语言中一样显式声明。
类型
接口也是Go语言中的一种类型,它能够出现在变量的定义、函数的入参和返回值中,并对它们进行约束,不过Go语言中有两种略微不同的接口,一种是带有一组方法的接口,另一种是不带任何方法的interface{}:
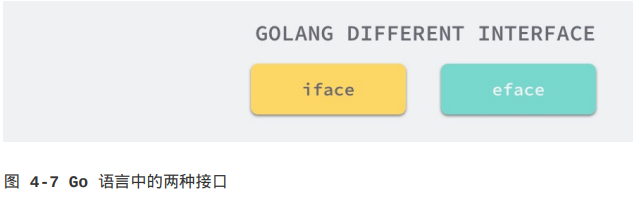
Go语言使用iface结构体表示第一种接口,使用eface结构体表示第二种空接口,两种接口虽然都使用interface声明,但是由于后者在Go语言中非常常见,所以在实现时使用了特殊的类型。
需要注意的是,与C语言中的void不同,interface{}类型不是任意类型,如果我们将类型转换成了interface{}类型,变量在运行期间的类型也发生了变化,获取变量类型时就会得到interface{}。
package main
func main() {
type Test struct{}
v := Test{}
Print(v)
}
func Print(v interface{}) {
println(v)
}
上述函数Print不接受任意类型的参数,只接受interface{}类型的值,在调用Print函数时会对参数v进行类型转换,将原来的Test类型转换成interface{}类型,我们会在本节后面介绍类型转换的过程和原理。
指针和接口
在Go语言中同时使用指针和接口时会发生一些让人困惑的问题,接口在定义一组方法时没有对实现的接收者做限制,所以我们会看到“一个类型”实现接口的两种方式:


这是因为结构体类型和指针类型是完全不同的,就像我们不能向一个接受指针的函数传递结构体,在实现接口时这两种类型也不能划等号。但是上图中的两种实现不可以同时存在,Go语言的编译器会在结构体类型和指针类型都实现一个方法时报错——method redeclared。
对Cat结构体来说,它在实现接口时可以选择接受者的类型,即结构体或结构体指针,在初始化时也可以初始化成结构体或者指针。下面的代码总结了如何使用结构体、结构体指针实现接口,以及如何使用结构体、结构体指针初始化变量。
type Cat struct {}
type Duck interface { /* ... */ }
// 这两行代码在做什么?
type (c Cat) Quack {} // 使用结构体实现接口
type (c *Cat) Quack {} // 使用结构体指针实现接口
// 作者应该想要演示如何实现接口,实现接口只需实现接口所需方法,因此这两行代码应该是这样的
func (c Cat) Quack() {} // 使用结构体实现接口
func (c *Cat) Quack() {} // 使用结构体指针实现接口
// 这两个func只能存在一个,两个同时存在时会报错method redeclared
var d Duck = Cat{} // 使用结构体初始化变量,Cat实现了接口Duck
var d Duck = &Cat{} // 使用结构体指针初始化变量,*Cat实现了接口Duck
实现接口的类型和初始化返回的类型两个维度组成了四种情况,这四种情况并不都能通过编译器的检查:

四种中只有“使用指针实现接口,使用结构体初始化变量”无法通过编译,其他三种情况都可以正常执行。当实现接口的类型和初始化变量时返回的类型相同时,代码通过编译是理所应当的:
1.方法接受者和初始化类型都是结构体;
2.方法接受者和初始化类型都是结构体指针;
而剩下的两种方式为什么一种能够通过编译,另一种无法通过编译呢?我们先来看一下能够通过编译的情况,也就是方法的接受者是结构体,而初始化的变量是结构体指针:
type Cat struct{}
func (c Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Duck = &Cat{}
c.Quack()
}
作为指针的&Cat{}变量能够隐式地获取到指向的结构体,所以能在结构体上调用Walk和Quack方法。我们可以将这里的调用理解成C语言中的d->Walk()和d->Speak(),它们都会先获取指向的结构体再执行对应的方法。
但是如果我们将上述代码中方法的接受者和初始化的类型进行交换,代码就无法通过编译了:
type Duck interface {
Quack()
}
type Cat struct{}
func (c *Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Duck = Cat{}
c.Quack()
}
编译它:

编译器会提醒我们:Cat类型没有实现Duck接口,Quack方法的接受者是指针。这两个报错对于刚刚接触Go语言的开发者比较难以理解,如果我们想要搞清楚这个问题,首先要知道Go语言在传递参数时都是传值的。
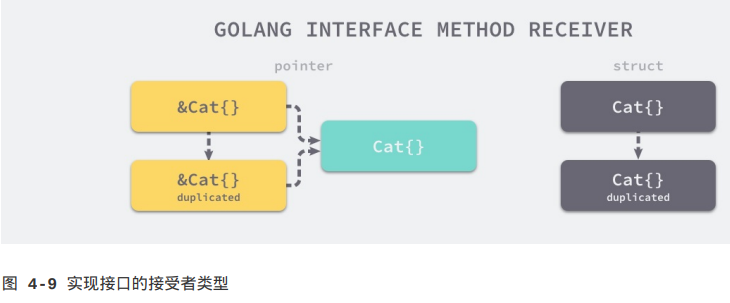
如上图所示,无论上述代码中初始化的变量c是Cat{}还是&Cat{},使用c.Quack()调用方法时都会发生值拷贝:
1.如图4-9左侧,对于&Cat{}来说,这意味着拷贝一个新的&Cat{}指针,这个指针与原来的指针指向一个相同且唯一的结构体,所以编译器可以隐式地对变量解引用(dereference)获取指针指向的结构体;
2.如图4-9右侧,对于Cat{}来说,这意味着Quack方法会接受一个全新的Cat{},因为方法的参数是*Cat,编译器不会无中生有创建一个新的指针;即使编译器可以创建指针,这个指针指向的也不是最初调用该方法的结构体;
上面的分析解释了指针类型的现象,当我们使用指针实现接口时,只有指针类型的变量才会实现该接口;当我们使用结构体实现接口时,指针类型和结构体类型都会实现该接口。当然这并不意味着我们应该一律使用结构体实现接口,这个问题在实际工程中也没那么重要,在这里我们只想解释现象背后的原因。
nil和non-nil
我们可以通过一个例子理解“Go语言的接口类型不是任意类型”这一句话,下面的代码在main函数中初始化了一个*TestStruct结构体指针,由于指针的零值是nil,所以变量s在初始化之后也是nil:
package main
type TestStruct struct{}
func NilOrNot(v interface{}) bool {
return v == nil
}
func main() {
var s *TestStruct
fmt.Println(s == nil) // #=> true
fmt.Println(NilOrNot(s)) // #=> false
}
我们简单总结一下上述代码执行的结果:
1.将上述变量与nil比较会返回true;
2.将上述变量传入NilOrNot方法并与nil比较会返回false;
出现上述现象的原因是——调用NilOrNot函数时发生了隐式的类型转换,除了向方法传入参数之外,变量的赋值也会触发隐式类型转换。在类型转换时,TestStruct类型会转换成interface{}类型,转换后的变量不仅包含转换前的变量,还包含变量的类型信息TestStruct,所以转换后的变量与nil不相等。
4.2.2 数据结构
相信各位读者已经对Go语言的接口有了一些的了解,接下来我们从源代码和汇编指令层面介绍接口的底层数据结构。
Go语言根据接口类型“是否包含一组方法”对类型做了不同的处理,我们使用iface结构体表示包含方法的接口;使用eface结构体表示不包含任何方法的interface{}类型,eface结构体在Go语言的定义是这样的:
type eface struct { // 16 bytes
_type *_type
data unsafe.Pointer
}
由于interface{}类型不包含任何方法,所以它的结构也相对来说比较简单,只包含指向底层数据和类型的两个指针。从上述结构我们也能推断出——Go语言中的任意类型都可以转换成interface{}类型。
另一个用于表示接口的结构体是iface,这个结构体中有指向原始数据的指针data,不过更重要的是itab类型的tab字段。
type iface struct { // 16 bytes
tab *itab
data unsafe.Pointer
}
接下来我们将详细分析Go语言接口中的这两个类型,即_type和itab。
类型结构体
_type是Go语言类型的运行时表示。下面是运行时包中的结构体,结构体包含了很多元信息,例如:类型的大小、哈希、对齐以及种类等。
type _type struct {
size uintptr
ptrdata uintptr
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte
str nameOff
ptrToThis typeOff
}
1.size字段存储了类型占用的内存空间,为内存空间的分配提供信息;
2.hash字段能够帮助我们快速确定类型是否相等;
3.equal字段用于判断当前类型的多个对象是否相等,该字段是为了减少Go语言二进制包大小而从typeAlg结构体中迁移过来的;
我们只需要对_type结构体中的字段有一个大体的概念,不需要详细理解所有字段的作用和意义。
itab结构体
itab结构体是接口类型的核心组成部分,每一个itab都占32字节的空间,我们可以将其看成接口类型和具体类型的组合,它们分别用inter和_type两个字段表示:
type itab struct { // 32 bytes
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}
除了inter和_type两个用于表示类型的字段之外,上述结构体中的另外两个字段也有自己的作用:
1.hash是对_type.hash的拷贝,当我们想将interface类型转换成具体类型时,可以使用该字段快速判断目标类型和具体类型_type是否一致;
2.fun是一个动态大小的数组,它是一个用于动态派发的虚函数表,存储了一组函数指针。虽然该变量被声明成大小固定的数组,但是在使用时会通过原始指针获取其中的数据,所以fun数组中保存的元素数量是不确定的;
我们会在类型断言中介绍hash字段的使用,在动态派发一节中介绍fun数组中存储的函数指针是如何被使用的。
4.2.3 类型转换
既然我们已经了解了接口在运行时的数据结构,接下来会通过几个例子来深入理解接口类型是如何初始化和传递的,这里会介绍在实现接口时使用指针类型和结构体类型的区别。这两种不同的接口实现方式会导致Go语言编译器生成不同的汇编代码,带来执行过程上的一些差异。
指针类型
首先我们回到这一节开头提到的Duck接口的例子,我们使用//go:noinline指令禁止Quack方法的内联编译:
package main
type Duck interface {
Quack()
}
type Cat struct {
Name string
}
//go:noinline
func (c *Cat) Quack() {
println(c.Name + " meow")
}
func main() {
var c Duck = &Cat{Name: "grooming"}
c.Quack()
}
我们使用编译器将上述代码编译成汇编语言,删掉其中一些对理解接口原理无用的指令并保留与赋值语句var c Duck = &Cat{Name: "grooming"}相关的代码,我们将生成的汇编指令拆分成三部分分析:
1.结构体Cat的初始化;
2.赋值触发的类型转换过程;
3.调用接口的方法Quack();
我们先来分析结构体Cat的初始化过程:
// LEAQ(Load Effective Address)指令将type."".Cat的地址加载到寄存器AX中
// type."".Cat是结构体的类型描述符的地址,SB是一个静态基址寄存器,表示全局符号的基地址
// 因此type."".Cat(SB)的含义为,以SB为基准,偏移为type."".Cat的位置
LEAQ type."".Cat(SB), AX ;; AX = &type."".Cat
// 将寄存器AX中存储的Cat类型的地址移动到栈指针指向的位置(栈顶)
MOVQ AX, (SP) ;; SP = &type."".Cat
// 调用runtime.newobject函数分配一个新对象,参数是Cat类型的地址
// 新分配的对象的地址保存在栈指针偏移8字节的位置
CALL runtime.newobject(SB) ;; SP + 8 = &Cat{}
// 将新分配的对象的地址加载到DI寄存器
MOVQ 8(SP), DI ;; DI = &Cat{}
// 将立即数8复制到以DI寄存器保存的地址为基准,偏移量为8的位置,即Cat结构体的Name字段的长度Len的位置
MOVQ $8, 8(DI) ;; StringHeader(DI.Name).Len = 8
// 将grooming串的地址(以静态基址寄存器中的值为基准,偏移为go.string."grooming")加载到AX
LEAQ go.string."grooming"(SB), AX ;; AX = &"grooming"
// 将寄存器AX中保存的grooming串的地址移动到Cat结构体的Name字段的数据Data的位置
MOVQ AX, (DI) ;; StringHeader(DI.Name).Data = &"grooming"
1.获取Cat结构体类型指针并将其作为参数放到栈上;
2.通过CALL指定调用runtime.newobject函数,这个函数会以Cat结构体类型指针作为入参,分配一片新的内存空间并将指向这片内存空间的指针返回到SP+8上;
3.SP+8现在存储了一个指向Cat结构体的指针,我们将栈上的指针拷贝到寄存器DI上方便操作;
4.由于Cat中只包含一个字符串类型的Name变量,所以在这里会分别将字符串地址&"grooming"和字符串长度8设置到结构体上,最后三行汇编指令等价于cat.Name = "grooming";
字符串在运行时的表示其实就是指针加上字符串长度,在前面的章节字符串已经介绍过它的底层表示和实现原理,但是我们这里要看一下初始化之后的Cat结构体在内存中的表示是什么样的:
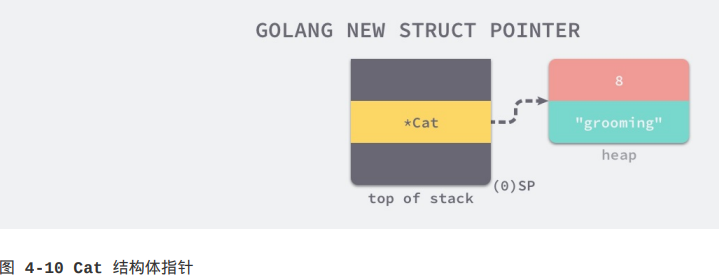
因为Cat结构体的定义中只包含一个字符串,而字符串在Go语言中总共占16字节,所以每一个Cat结构体的大小都是16字节。初始化Cat结构体之后就进入了将*Cat转换成Duck类型的过程了:
// 将符号go.itab.*"".Cat,"".Duck(SB)的地址加载到寄存器AX
// go.itab.*"".Cat,"".Duck表示Cat类型实现Duck接口的itab结构的地址
LEAQ go.itab.*"".Cat,"".Duck(SB), AX ;; AX = *itab(go.itab.*"".Cat,"".Duck
// 将寄存器DI中存放的Cat对象的地址移动到栈指针处
// 下面的注释应该是有误的,应该是;; SP = DI
MOVQ DI, (SP) ;; SP = AX
类型转换的过程比较简单,Duck作为一个包含方法的接口,它在底层使用iface结构体表示。iface结构体包含两个字段,其中一个是指向数据的指针,另一个是表示接口和结构体关系的tab字段,我们已经通过上一段代码SP+8初始化了Cat结构体指针,这段代码只是将编译期间生成的itab结构体指针复制到SP上:
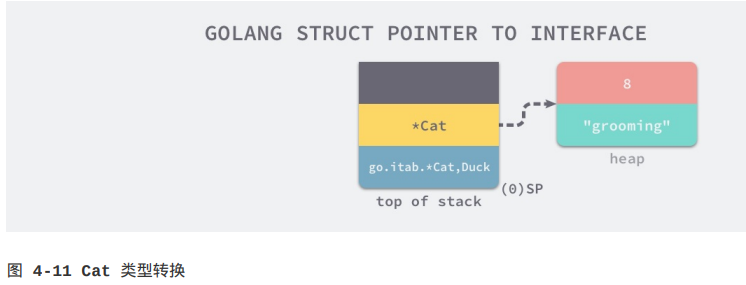
到这里,我们会发现SP~SP+16共同组成了iface结构体,而栈上的这个iface结构体也是Quack方法的第一个入参。
CALL "".(*Cat).Quack(SB) ;; SP.Quack()
上述代码会直接通过CALL指令完成方法的调用,细心的读者可能会发现一个问题——为什么在代码中我们调用的是Duck.Quack但生成的汇编是*Cat.Quack呢?Go语言的编译器会在编译期间将一些需要动态派发的方法调用改写成对目标方法的直接调用,以减少性能的额外开销。如果在这里禁用编译器优化,就会看到动态派发的过程,我们会在后面分析接口的动态派发以及性能上额外开销。
结构体类型
在这里,我们继续修改上一节中的代码,使用结构体类型实现Duck接口并初始化结构体类型的变量:
package main
type Duck interface {
Quack()
}
type Cat struct {
Name string
}
//go:noinline
func (c Cat) Quack() {
println(c.Name + " meow")
}
func main() {
var c Duck = Cat{Name: "grooming"}
c.Quack()
}
如果我们在初始化变量时使用指针类型&Cat{Name: "grooming"}也能够通过编译,不过生成的汇编代码和上一节中的几乎完全相同,所以这里也就不分析这个情况了。
编译上述的代码会得到如下所示的汇编指令,需要注意的是为了代码更容易理解和分析,这里的汇编指令依然经过了删减,不过不会影响具体的执行过程。与上一节一样,我们将汇编代码的执行过程分成以下几个部分:
1.初始化Cat结构体;
2.完成从Cat到Duck接口的类型转换;
3.调用接口的Quack方法;
我们先来看一下上述汇编代码中用于初始化Cat结构体的部分:
// 对寄存器X0自身进行异或操作,即清0
XORPS X0, X0 ;; X0 = 0
// 将寄存器X0中的全0值移动到以栈指针为基准,偏移量为32的位置
// ""..autotmp_1+32指的是偏移量为32,""..autotmp_1是编译器生成的临时变量
MOVUPS X0, ""..autotmp_1+32(SP) ;; StringHeader(SP+32).Data = 0
// 将grooming的地址存放到寄存器AX中
LEAQ go.string."grooming"(SB), AX ;; AX = &"grooming"
// 将grooming串的地址移动到以栈指针为基准,偏移量为32的位置,即string的Data字段
MOVQ AX, ""..autotmp_1+32(SP) ;; StringHeader(SP+32).Data = AX
// 将立即数8移动到以栈指针为基准,偏移量为40的位置,即string的Len字段
MOVQ $8, ""..autotmp_1+40(SP) ;; StringHeader(SP+32).Len = 8
这段汇编指令会在栈上初始化Cat结构体,而上一节的代码在堆上申请了16字节的内存空间,栈上只有一个指向Cat的指针。
初始化结构体后就进入类型转换的阶段,编译器会将go.itab."".Cat,""Duck的地址和指向Cat结构体的指针作为参数一并传入runtime.convT2I函数:
// 将go.itab."".Cat,"".Duck的地址加载到寄存器AX中
LEAQ go.itab."".Cat,"".Duck(SB), AX ;; AX = &(go.itab."".Cat,"".Duck)
// 将寄存器AX中存放的itab结构地址移动到栈指针处
MOVQ AX, (SP) ;; SP = AX
// 将""..autotmp_1+32(SP)位置存放的Cat结构体的地址加载到寄存器AX中
LEAQ ""..autotmp_1+32(SP), AX ;; AX = &(SP+32) = &Cat{Name: "grooming"}
// 将寄存器AX中存放的Cat结构体指针移动到栈指针偏移8字节处
MOVQ AX, 8(SP) ;; SP + 8 = AX
// 调用runtime.convT2I,将Cat类型转换为接口类型
// 看上去这句汇编只将SB参数传入函数,但实际上按照调用惯例,会从SB开始位置找到所需的两个参数
CALL runtime.convT2I(SB) ;; runtime.convT2I(SP, SP+8)
convT2I函数会获取itab中存储的类型,根据类型的大小申请一片内存空间并将elem指针中的内容拷贝到目标的内存空间中:
// 将具体类型转换为接口类型
func convT2I(tab *itab, elem unsafe.Pointer) (i iface) {
// 获取itab中存储的类型信息
t := tab._type
// 分配内存,大小为t.size,类型为t,且需要置0(true)
x := mallocgc(t.size, t, true)
// 将elem移动到新分配的内存x中,t是类型信息,用于正确处理类型安全的内存拷贝
typedmemmove(t, x, elem)
// 设置iface字段
i.tab = tab
i.data = x
return
}
runtime.convT2I会返回一个iface结构体,其中包含itab指针和Cat变量。当前函数返回之后,main函数的栈上会包含以下数据:
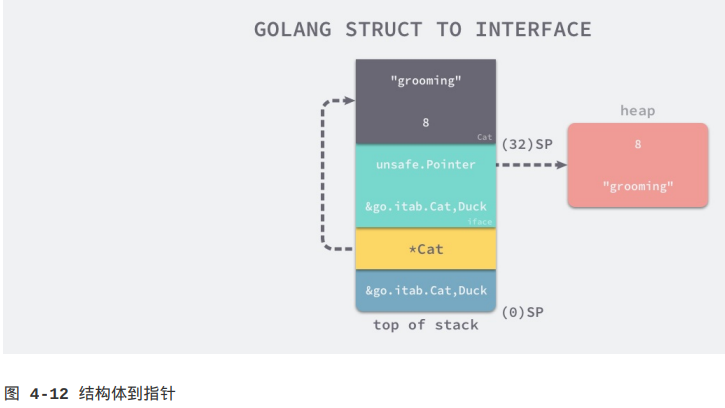
SP和SP+8中存储的itab和Cat指针就是runtime.convT2I参数的入参,这个函数的返回值位于SP+16,是一个占16字节内存空间iface结构体,SP+32存储的就是在栈上的Cat结构体,它会在runtime.convT2I执行的过程中拷贝到堆上。
在最后,我们会通过以下的指令调用Cat实现的接口方法Quack():
// 将栈指针16字节偏移处的地址(itab的地址)移动到寄存器AX中
MOVQ 16(SP), AX ;; AX = &(go.itab."".Cat,"".Duck)
// 将栈指针24字节偏移处的地址(Cat对象的地址)移动到寄存器CX中
MOVQ 24(SP), CX ;; CX = &Cat{Name: "grooming"}
// 将寄存器AX 24字节偏移处的值(fun数组的地址)移动到寄存器AX
MOVQ 24(AX), AX ;; AX = AX.fun[0] = Cat.Quack
// 将寄存器CX中的地址(Cat对象的地址)存放到栈顶,这一步是准备函数调用的接收者
MOVQ CX, (SP) ;; SP = CX
// 调用寄存器AX中存放的Quack函数,其接收者是上一步中的栈顶实例
CALL AX ;; CX.Quack()
这几个汇编指令还是非常好理解的,MOVQ 24(AX), AX是最关键的指令,它从itab结构体中取出Cat.Quack方法指针作为CALL指令调用时的参数。接口变量的第24字节是itab.fun数组开始的位置,由于Duck接口只包含一个方法,所以itab.fun[0]中存储的就是指向Quack方法的指针了。
4.2.4 类型断言
上一节介绍是如何把具体类型转换成接口类型,而这一节介绍的是如何将一个接口类型转换成具体类型。本节会根据接口中是否存在方法分两种情况介绍类型断言的执行过程。
非空接口
首先分析接口中包含方法的情况,Duck接口是一个非空的接口,我们来分析从Duck转换回Cat结构体的过程:
func main() {
var c Duck = &Cat{Name: "grooming"}
switch c.(type) {
case *Cat:
cat := c.(*Cat)
cat.Quack()
}
}
我们将编译得到的汇编指令分成两部分分析,第一部分是变量的初始化,第二部分是类型转换,第一部分的代码如下:
// TEXT是一个伪指令,用于声明一个代码段
// "".main说明是main函数的标签,SB表示静态基址段
// ABIInternal表明使用内部调用约定
// $32-0表示该函数在栈上预留了32字节的空间
00000 TEXT "".main(SB), ABIInternal, $32-0
....
// 将寄存器X0异或清零
00029 XORPS X0, X0
// MOVUPS指令用于移动单精度浮点数
// 将寄存器X0中的0移动到栈指针偏移量为8字节的位置,该位置是一个临时变量
00032 MOVUPS X0, ""..autotmp_4+8(SP)
// 将grooming串在静态基址段(SB)中的地址加载到寄存器AX
00037 LEAQ go.string."grooming"(SB), AX
// 将寄存器AX中存放的串地址移动到栈指针偏移量为8的位置,该位置是一个临时变量
00044 MOVQ AX, ""..autotmp_4+8(SP)
// 将立即数8移动到栈指针偏移量为16的位置,该位置是一个临时变量
00049 MOVQ $8, ""..autotmp_4+16(SP)
0037~0049三个指令初始化了Duck变量,Cat结构体初始化在SP+8~SP+24上。因为Go语言的编译器做了一些优化,所以代码中没有iface的构建过程,不过对于这一节要介绍的类型断言和转换没有太多的影响。下面进入类型转换的部分:
// CMPL命令比较两个整数,这里比较的是itab的hash字段和目标类型的hash
00058 CMPL go.itab.*"".Cat,"".Duck+16(SB), $593696792
// 如果两者相等,则跳转到80处执行
00068 JEQ 80 ;; if (c.tab.hash != 593696792) {
// MOVQ指令用于移动64位数据,将栈偏移24字节的值移动到BP,这是在恢复调用者的基址指针,准备退出函数
00070 MOVQ 24(SP), BP ;; BP = SP+24
// 将立即数32与栈指针相加,释放为当前函数分配的空间
00075 ADDQ $32, SP ;; SP += 32
00079 RET ;; return
;; } else {
// 将栈指针偏移8字节处的地址(临时变量autotmp_4,即Cat实例的地址)加载到寄存器AX
00080 LEAQ ""..autotmp_4+8(SP), AX ;; AX = &Cat{Name: "grooming"}
// 将寄存器AX中存放的Cat实例的地址移动到栈指针处
00085 MOVQ AX, (SP) ;; SP = AX
// 调用Quack函数,接收者是Cat实例
00089 CALL "".(*Cat).Quack(SB) ;; SP.Quack()
// 跳转到70处,用于函数正常退出
00094 JMP 70 ;; ...
;; BP = SP+24
;; sp += 32
;; return
;; }
switch语句生成的汇编指令会将目标类型的hash与接口变量中的itab.hash进行比较:
1.如果两者相等意味着变量的具体类型是Cat,我们会跳转到0080所在的分支完成类型转换。
(1)获取SP+8存储的Cat结构体指针;
(2)将结构体指针拷贝到栈顶;
(3)调用Quack方法;
(4)恢复函数的栈并返回;
2.如果接口中存在的具体类型不是Cat,就会直接恢复栈指针并返回到调用方;
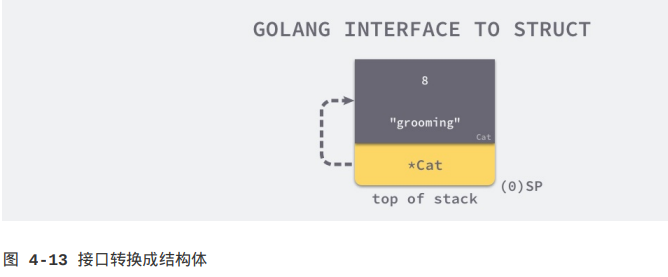
上图展示了调用Quack方法时的堆栈情况,其中Cat结构体存储在SP+8~SP+24上,Cat指针存储在栈顶并指向上述结构体。
空接口
当我们使用空接口类型interface{}进行类型断言时,如果不关闭Go语言编译器的优化选项,生成的汇编指令是差不多的。编译器会省略将Cat结构体转换成eface的过程:
func main() {
var c interface{} = &Cat{Name: "grooming"}
switch c.(type) {
case *Cat:
cat := c.(*Cat)
cat.Quack()
}
}
如果禁用编译器优化,上述代码会在类型断言时不会直接获取变量中具体类型的_type(应该指的是itab中的_type),而是从eface._type中获取,汇编指令仍然会使用目标类型的hash字段与变量的类型比较。
4.2.4 动态派发
动态派发(Dynamic dispatch)是在运行期间选择具体多态操作(方法或函数)执行的过程,它是一种在面向对象语言中常见的特性。Go语言虽然不是严格意义上的面向对象语言,但是接口的引入为它带来了动态派发这一特性,调用接口类型的方法时,如果编译期间不能确认接口的类型,Go语言会在运行期间决定具体调用该方法的哪个实现。
在如下代码中,main函数调用了两次Quack方法:
1.第一次以Duck接口类型的身份调用,调用时需要经过运行时的动态派发;
2.第二次以*Cat具体类型的身份调用,编译器就会确定调用的函数;
func main() {
var c Duck = &Cat{Name: "grooming"}
c.Quack()
c.(*Cat).Quack()
}
因为编译器优化影响了我们对原始汇编指令的理解,所以需要使用编译参数-N关闭编译器优化。如果不指定这个参数,编译器会对代码进行重写,与最初生成的执行过程有一些偏差,例如:
1.因为接口类型中的tab类型的参数itab并没有被使用,所以优化从Cat转换到Duck的过程;
2.因为变量的具体类型是确定的,所以删除从Duck接口类型转换到*Cat具体类型时可能会发生的panic分支;
在具体分析调用Quack方法的两种姿势之前,我们要先了解Cat结构体究竟是如何初始化的,以及初始化完成后的栈上有哪些数据:
// 将Cat的类型描述符的地址加载到寄存器AX中
LEAQ type."".Cat(SB), AX
// 将寄存器AX中存放的Cat类型描述符的地址移动到栈顶
MOVQ AX, (SP)
// 调用运行时函数runtime.newobject,创建新对象,期望的类型在调用前已经被放到栈顶
// 创建的新对象的地址会存放在栈顶偏移8字节的位置
CALL runtime.newobject(SB) ;; SP + 8 = new(Cat)
// 将栈顶偏移8字节处存放的新对象的地址移动到寄存器DI
MOVQ 8(SP), DI ;; DI = SP + 8
// 将寄存器DI中存放的新Cat对象的地址移动到栈顶偏移32字节的位置,该位置是一个临时变量
MOVQ DI, ""..autotmp_2+32(SP) ;; SP + 32 = DI
// 将立即数8移动到寄存器DI指向的地址上偏移8字节的位置,这是在设置字符串的长度
MOVQ $8, 8(DI) ;; StringHeader(cat).Len = 8
// 将grooming串的地址加载到寄存器AX中
LEAQ go.string."grooming"(SB), AX ;; AX = &"grooming"
// 将寄存器AX中存放的串地址移动到寄存器DI指向的地址上,这是在设置字符串的内容
MOVQ AX, (DI) ;; StringHeader(cat).Data = AX
// 将栈顶偏移32字节处存放的Cat实例的地址移动到寄存器AX中
MOVQ ""..autotmp_2+32(SP), AX ;; AX = &Cat{...}
// 将寄存器中存放的Cat实例的地址移动到栈顶偏移40字节的位置
MOVQ AX, ""..autotmp_1+40(SP) ;; SP + 40 = &Cat{...}
// 加载类型Cat到Duck的itab的地址到寄存器CX
LEAQ go.itab.*"".Cat,"".Duck(SB), CX ;; CX = &go.itab.*"".Cat,"".Duck
// 将寄存器CX中存放的itab地址移动到栈顶偏移48字节的位置,这是在设置iface结构的tab字段
MOVQ CX, "".c+48(SP) ;; iface(c).tab = SP + 48 = CX
// 将寄存器AX中存放的Cat实例的地址移动到栈顶偏移56字节的位置,这是在设置iface结构的data字段
MOVQ AX, "".c+56(SP) ;; iface(c).data = SP + 56 = AX
这段代码的初始化过程其实和上两节中的过程没有太多的差别,它先初始化了Cat结构体指针,再将Cat和tab打包成了一个iface类型的结构体,我们直接来看初始化结束后的栈情况:
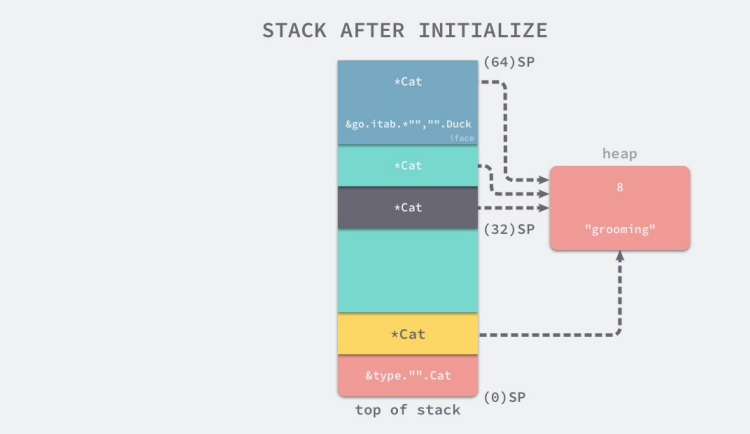

1.SP是Cat类型描述符的地址,它也是运行时runtime.newobject方法的参数;
2.SP+8是runtime.newobject方法的返回值,也就是指向堆上的Cat结构体的指针;
3.SP+32、SP+40是对SP+8的拷贝,这两个指针都会指向栈上的Cat结构体;
4.SP+48~SP+64是接口变量iface结构体,其中包含了tab结构体指针和*Cat指针;
初始化过程结束之后,我们进入到了动态派发的过程,c.Quack()语句展开的汇编指令会在运行时确定函数指针。
// 将栈顶偏移48字节处的值(此处是接口变量c中tab字段的地址)移动到寄存器AX
MOVQ "".c+48(SP), AX ;; AX = iface(c).tab
// 将寄存器AX指向的地址偏移24字节的值(即c.tab字段的fun数组地址)移动到寄存器AX
MOVQ 24(AX), AX ;; AX = iface(c).tab.fun[0] = Cat.Quack
// 将栈顶偏移56字节的值(c的data字段)移动到寄存器CX
MOVQ "".c+56(SP), CX ;; CX = iface(c).data
// 将寄存器CX中存放的接口data字段移动到栈顶,相当于传参,参数通过栈传递
MOVQ CX, (SP) ;; SP = CX = &Cat{...}
// 调用寄存器AX中存放的Quack方法,方法接收者是栈顶的Cat实例
CALL AX ;; SP.Quack()
这段代码的执行过程可以分成以下三个步骤:
1.从接口变量中获取了保存Cat.Quack方法指针的tab.func[0];
2.接口变量中的变量数据(即保存的实例的指针)会被拷贝到栈顶;
3.方法指针会被拷贝到寄存器中并通过汇编指令CALL触发;
另一个调用Quack方法的语句c.(*Cat).Quack()生成的汇编指令看起来会有一些复杂,但是代码前半部分都是在做类型转换,将接口类型转换成*Cat类型,只有最后两行代码才是函数调用相关的指令:
// 将栈顶偏移56字节位置的值(Cat实例的地址)移动到寄存器AX中
MOVQ "".c+56(SP), AX ;; AX = iface(c).data = &Cat{...}
// 将栈顶偏移48字节位置的值(itab的地址)移动到寄存器CX中
MOVQ "".c+48(SP), CX ;; CX = iface(c).tab
// 将Cat类型到Duck接口的转换表itab的地址的地址移动到寄存器DX中
LEAQ go.itab.*"".Cat,"".Duck(SB), DX ;; DX = &&go.itab.*"".Cat,"".Duck
// 比较类型转换的源和目标类型的两个itab是否相等
CMPQ CX, DX ;; CMP(CX, DX)
// 如果相等,跳转到163处
JEQ 163
// 如果不相等,跳转到201处,这是错误处理部分
JMP 201
// 将寄存器AX中存放的Cat实例的地址移动到栈顶偏移24字节的位置,该位置是一个临时变量autotmp_3
MOVQ AX, ""..autotmp_3+24(SP) ;; SP+24 = &Cat{...}
// 将寄存器AX中存放的Cat实例的地址移动到栈顶(SP指向的地址处),这是为了下一步函数调用准备参数
MOVQ AX, (SP) ;; SP = &Cat{...}
// 调用栈顶处Cat实例的Quack方法
CALL "".(*Cat).Quack(SB) ;; SP.Quack()
下面的几行代码只是将Cat指针拷贝到了栈顶并调用Quack方法。这一次调用的函数指针在编译期就已经确定了,所以运行时就不需要动态查找方法的实现:
// 将栈顶偏移48字节的地址(iface的tab字段)移动到寄存器AX中
MOVQ "".c+48(SP), AX ;; AX = iface(c).tab
// 将寄存器AX中存放的tab字段指针指向位置偏移24字节的地址移动到寄存器AX中
MOVQ 24(AX), AX ;; AX = iface(c).tab.fun[0] = Cat.Quack
// 将栈顶偏移56字节的地址(iface的data字段)移动到寄存器CX中
MOVQ "".c+56(SP), CX ;; CX = iface(c).data
两次方法调用对应的汇编指令差异就是动态派发带来的额外开销,这些额外开销在有低延时、高吞吐量需求的服务中是不能被忽视的,我们来详细分析一下产生的额外汇编指令对性能造成的影响。
基准测试
下面代码中的两个方法BenchmarkDirectCall和BenchmarkDynamicDispatch分别会调用结构体方法和接口方法,在接口上调用方法时会使用动态派发机制,我们以直接调用作为基准分析动态派发带来了多少额外开销:
func BenchmarkDirectCall(b *testing.B) {
c := &Cat{Name: "grooming"}
for n := 0; n < b.N; n++ {
// MOVQ AX, "".c+24(SP)
// MOVQ AX, (SP)
// CALL "".(*Cat).Quack(SB)
c.Quack()
}
}
func BenchmarkDynamicDispatch(b *testing.B) {
c := Duck(&Cat{Name: "grooming"})
for n := 0; n < b.N; n++ {
// MOVQ "".d+56(SP), AX
// MOVQ 24(AX), AX
// MOVQ "".d+64(SP), CX
// MOVQ CX, (SP)
// CALL AX
c.Quack()
}
}
我们直接运行下面的命令,使用1个CPU运行上述代码,每一个基准测试都会被执行3次:
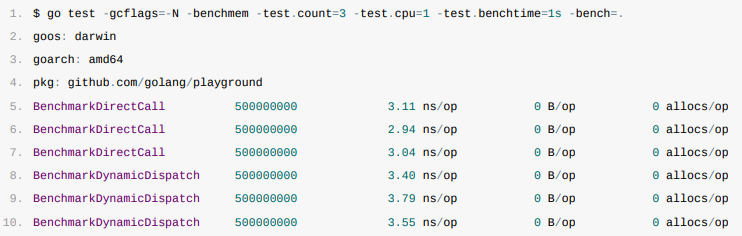
上图命令中,-gcflags=-N选项会传递给Go编译器,表示禁用编译器优化;-benchmem选项会启用后会报告内存分配的统计信息,包括内存分配次数和平均每次分配的大小;-test.count=3表示测试执行3次;-test.cpu=1表示仅在单核心上运行测试;-test.benchtime=1s表示每项测试最小执行1秒,更长的测试时间提供更稳定和准确的性能数据;-bench=.表示运行当前包中的所有基准测试。
1.调用结构体方法时,每一次调用需要~3.03ns;
2.使用动态派发时,每一次调用需要~3.58ns;
在关闭编译器优化的情况下,从上面的数据来看,动态派发生成的指令会带来~18%左右的额外性能开销。
这些性能开销在一个复杂的系统中不会带来太多的影响。一个项目不可能只使用动态派发,而且如果我们开启编译器优化后,动态派发的额外开销会降低至~5%,这对应用性能的整体影响就更小了,所以与使用接口带来的好处相比,动态派发的额外开销往往可以忽略。
上面的性能测试建立在实现和调用方法的都是结构体指针上,当我们将结构体指针换成结构体又会有比较大的差异:
func BenchmarkDirectCall(b *testing.B) {
c := Cat{Name: "grooming"}
for n := 0; n < b.N; n++ {
// MOVQ AX, (SP)
// MOVQ $8, 8(SP)
// CALL "".Cat.Quark(SB)
c.Quack()
}
}
func BenchmarkDynamicDispatch(b *testing.B) {
c := Duck(Cat{Name: "grooming"})
for n := 0; n < b.N; n++ {
// MOVQ 16(SP), AX
// MOVQ 24(SP), CX
// MOVQ AX, "".d+32(SP)
// MOVQ CX, "".d+40(SP)
// MOVQ "".d+32(SP), AX
// MOVQ 24(AX), AX
// MOVQ "".d+40(SP), CX
// MOVQ CX, (SP)
// CALL AX
c.Quack()
}
}
我们重新执行相同的基准测试时,会得到如下所示的结果:
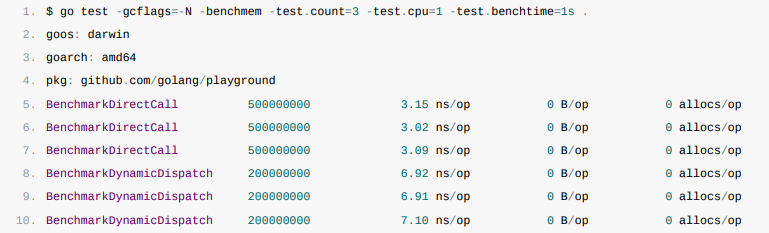
直接调用方法需要消耗时间的平均值和使用指针实现接口时差不多,约为~3.09ns,而使用动态派发调用方法却需要~6.98ns,相比直接调用额外消耗了~125%的时间,从生成的汇编指令我们也能看出后者的额外开销会高很多。

从上述表格我们可以看到使用结构体来实现接口带来的开销会大于使用指针实现,而动态派发在结构体上的表现非常差,这也提醒我们应当尽量避免使用结构体类型实现接口。
使用结构体带来的巨大性能差异不只是接口带来的问题,带来性能问题主要因为Go语言在函数调用时是传值的,动态派发的过程只是放大了参数拷贝带来的影响。
4.2.6 小结
重新回顾一下本节介绍的内容,我们在开头简单介绍了使用Go语言接口的常见问题,例如使用不同类型实现接口带来的差异、函数调用时发生的隐式类型转换;我们还分析了接口的类型转换、类型断言以及动态派发机制。
4.3 反射
反射是Go语言比较重要的特性。虽然在大多数的应用和服务中并不常见,但是很多框架都依赖Go语言的反射机制实现简化代码的逻辑。因为Go语言的语法元素很少、设计简单,所以它没有特别强的表达能力,但是Go语言的reflect包能够弥补它在语法上的一些劣势。
reflect实现了运行时的反射能力,能够让程序操作不同类型的对象。反射包中有两对非常重要的函数和类型,reflect.TypeOf能获取类型信息,reflect.ValueOf能获取数据的运行时表示,另外两个类型是Type和Value,它们与函数是一一对应的关系:

类型Type是反射包定义的一个接口,我们可以使用reflect.TypeOf函数获取任意变量的类型,Type接口中定义了一些有趣的方法,MethodByName可以获取当前类型对应方法的引用、Implements可以判断当前类型是否实现了某个接口:
type Type interface {
Align() int
FieldAlign() int
Method(int) Method
MethodByName(string) (Method, bool)
NumMethod() int
// ...
Implements(u Type) bool
// ...
}
反射包中Value的类型与Type不同,它被声明成了结构体。这个结构体没有对外暴露的字段,但是提供了获取或者写入数据的方法:
type Value struct {
// contains filtered or unexported fields
}
func (v Value) Addr() Value
func (v Value) Bool() bool
func (v Value) Bytes() []byte
// ...
反射包中的所有方法基本都是围绕着Type和Value这两个类型设计的。我们通过reflect.TypeOf、reflect.ValueOf可以将一个普通的变量转换成“反射”包中提供的Type和Value,随后就可以使用反射包中的方法对它们进行复杂的操作。
4.3.1 三大法则
运行时反射是程序在运行期间检查其自身结构的一种方式。反射带来的灵活性是一把双刃剑,反射作为一种元编程方式可以减少重复代码,但是过量使用反射会使我们的程序逻辑变得难以理解并且运行缓慢。我们在这一节中会介绍Go语言反射的三大法则,其中包括:
1.从interface{}变量可以反射出反射对象;
2.从反射对象可以获取interface{}变量;
3.要修改反射对象,其值必须可设置;
第一法则
反射的第一法则是我们能将Go语言的interface{}变量转换成反射对象。很多读者可能会对这一法则产生困惑——为什么是从interface{}变量到反射对象?当我们执行reflect.ValueOf(1)时,虽然看起来是获取了基本类型int对应的反射类型,但是由于reflect.TypeOf、reflect.ValueOf两个方法的形参都是interface{}类型,所以在方法执行的过程中发生了类型转换。
在函数调用一节中曾经介绍过,Go语言的函数调用都是值传递的,变量会在函数调用时进行类型转换。基本类型int会转换成interface{}类型,这也就是为什么第一条法则是“从接口到反射对象”。
上面提到的reflect.TypeOf和reflect.ValueOf函数就能完成这里的转换,如果我们认为Go语言的类型和反射类型处于两个不同的“世界”,那么这两个函数就是连接这两个世界的桥梁。
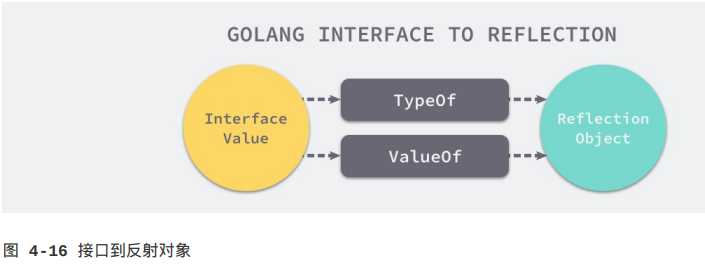
我们通过以下例子简单介绍这两个函数的作用,reflect.TypeOf获取了变量author的类型,reflect.ValueOf获取了变量的值draven。如果我们知道了一个变量的类型和值,那么就意味着知道了这个变量的全部信息。
package main
import (
"fmt"
"reflect"
)
func main() {
author := "draven"
fmt.Println("TypeOf author:", reflect.TypeOf(author))
fmt.Println("ValueOf author:", reflect.ValueOf(author))
}
运行它:

有了变量的类型之后,我们可以通过Method方法获得类型实现的方法,通过Field获取类型包含的全部字段。对于不同的类型,我们也可以调用不同的方法获取相关信息:
1.结构体:获取字段的数量并通过下标和字段名获取字段StructField;
2.哈希表:获取哈希表的Key类型;
3.函数或方法:获取入参和返回值的类型;
总而言之,使用reflect.TypeOf和reflect.ValueOf能够获取Go语言中的变量对应的反射对象。一旦获取了反射对象,我们就能得到跟当前类型相关的数据和操作,并可以使用这些运行时获取的结构执行方法。
第二法则
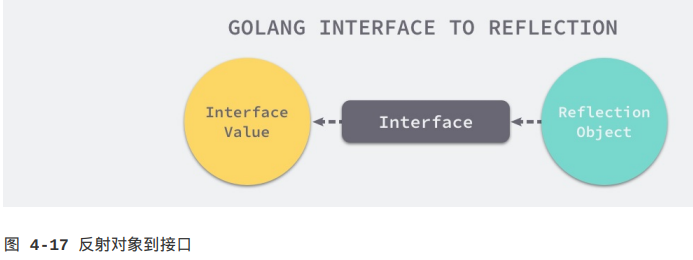
反射的第二法则是我们可以从反射对象获取interface{}变量。既然能够将接口类型的变量转换成反射对象,那么一定需要其他方法将反射对象还原成接口类型的变量,reflect中的reflect.Value.Interface方法就能完成这项工作:
不过调用reflect.Value.Interface方法只能获得interface{}类型的变量,如果想要将其还原成最原始的状态还需要经过如下所示的显示类型转换:
v := reflect.ValueOf(1)
// 类型断言,如果真的是int值,则返回该值,否则抛出运行时错误
// 如果用两个参数接收类型断言的返回值,第二个返回值会返回是否成功
// 这种情况下就不会抛运行时错误,因此此时可以安全地检查出类型断言错误
v.Interface().(int)
从反射对象到接口值的过程就是从接口值到反射对象的镜面过程,这两个过程都需要经历两次转换:
1.接口值到反射对象:
(1)从基本类型到接口类型的类型转换;
(2)从接口类型到反射对象的转换;
2.从反射对象到接口值:
(1)反射对象转换成接口类型;
(2)通过显式类型转换变成原始类型;
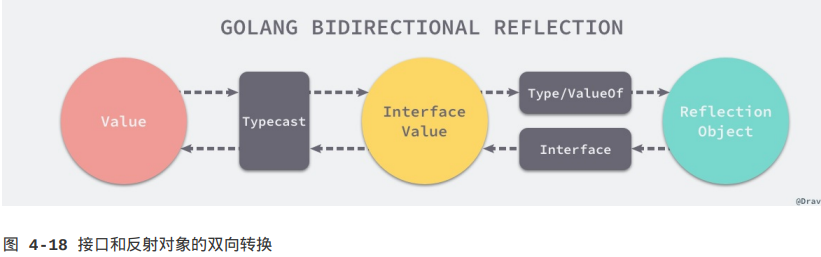
当然不是所有的变量都需要类型转换这一过程。如果变量本身就是interface{}类型,那么它不需要类型转换,因为类型转换这一过程一般是隐式的,所以我们不太需要关心它,只有在我们需要将反射对象转换回基本类型时才需要显式的转换操作。
第三法则
Go语言反射的最后一条法则是与值是否可以被更改有关,如果我们想要更新一个reflect.Value,那么它持有的值一定是可以被更新的,假设我们有以下代码:
func main() {
i := 1
v := reflect.ValueOf(i)
v.SetInt(10)
fmt.Println(i)
}
运行它:
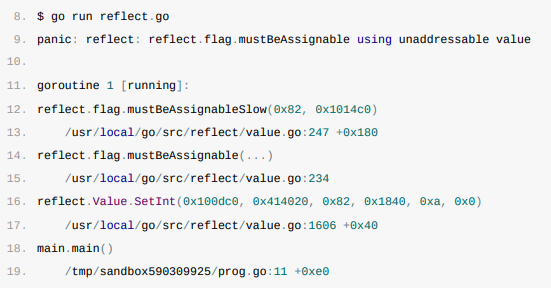
运行上述代码会导致程序崩溃并报出reflect: reflect.flag.mustBeAssignable using unaddressable value错误,仔细思考一下就能够发现出错的原因,Go语言的函数调用都是值传递的,所以我们得到的反射对象跟最开始的变量没有任何关系,所以直接对它修改会导致崩溃(简单来说,错误的原因在于试图直接修改一个非指针类型reflect.Value的值,v是由i的副本创建的,所以v不可寻址,也不能被修改)。
想要修改原有的变量只能通过如下的方法:
func main() {
i := 1
v := reflect.ValueOf(&i)
v.Elem().SetInt(10)
fmt.Println(i) // 会输出10
}
1.调用reflect.ValueOf函数获取变量指针;
2.调用reflect.Value.Elem方法获取指针指向的变量(此方法返回的变量类型还是reflect.Value);
3.调用reflect.Value.SetInt方法更新变量的值;
由于Go语言的函数调用都是值传递的,所以我们只能先获取指针对应的reflect.Value,再通过reflect.Value.Elem方法迂回地得到可以被设置的变量,我们通过如下所示的代码理解这个过程:
func main() {
i := 1
v := &i
*v = 10
}
如果不能直接操作i变量修改其持有的值,我们就只能获取i变量所在地址并使用*v修改所在地址中存储的整数。
4.3.2 类型和值
Go语言的interface{}类型在语言内部是通过emptyInterface这个结构体来表示的(跟上面的eface结构相同),其中的rtype字段用于表示变量的类型,另一个word字段指向内部封装的数据:
type emptyInterface struct {
typ *rtype
word unsafe.Pointer
}
用于获取变量类型的reflect.TypeOf函数将传入的变量隐式转换成emptyInterface类型并获取其中存储的类型信息rtype:
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
// rtype类型实现了Type接口,因此可以转换为Type接口类型
func toType(t *rtype) Type {
if t == nil {
return nil
}
return t
}
rtype就是一个实现了Type接口的结构体,我们能在reflect包中找到如下所示的reflect.rtype.String方法帮助我们获取当前类型的名称等信息:
func (t *rtype) String() string {
s := t.nameOff(t.str).name()
if t.tflag & tflagExtraStar != 0 {
return s[1:]
}
return s
}
reflect.TypeOf函数的实现原理其实并不复杂,它只是将一个interface{}变量转换成了内部的emptyInterface表示,然后从中获取相应的类型信息。
用于获取接口值Value的函数reflect.ValueOf实现也非常简单,在该函数中我们先调用了reflect.escapes函数保证当前值逃逸到堆上,然后通过reflect.unpackEface方法从接口中获取Value结构体:
func ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
escapes(i)
return unpackEface(i)
}
func unpackEface(i interface{}) Value {
e := (*emptyInterface)(unsafe.Pointer(&i))
t := e.typ
if t == nil {
return Value{}
}
f := flag(t.Kind())
// 如果需要设置指针标志
if ifaceIndir(t) {
f |= flagIndir
}
return Value{t, e.word, f}
}
reflect.unpackEface函数会将传入的接口转换成emptyInterface结构体,然后将具体类型和指针包装成Value结构体并返回。
reflect.TypeOf和reflect.ValueOf函数的实现都很简单,我们已经分析了这两个函数的实现,现在需要了解编译器在调用函数前做了哪些工作:
package main
import (
"reflect"
)
func main() {
i := 20
_ = reflect.TypeOf(i)
}
编译它(使用构建命令go build,-gcflags的内容会传递给go编译器,其中,-S让编译器输出汇编代码,-N禁用编译器优化):

从上面这段截取的汇编语言,我们发现在函数调用前已经发生了类型转换,上述指令将int类型的变量转换成了占用16字节的autotmp_19+280(SP) ~ autotmp_19+288(SP)接口,两个LEAQ指令分别获取了类型的指针type.int(SB)以及变量i所在的地址。
当我们想要将一个变量转换成反射对象时,Go语言会在编译期间完成类型转换工作,将变量的类型和值转换成了interface{}并等待运行期间使用reflect包获取接口中存储的信息。















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









