







sparkR
在工作目录下创建behavior.R文件
#加载包
library(SparkR)
library(magrittr)
library(plyr)
######## debugs spark 1.6 #####################################
##加载环境
sc <- sparkR.init(appName="Behavior")
sqlContext <- sparkRSQL.init(sc)
hiveContext <- sparkRHive.init(sc)
######## import data #####################################
#日期
stat_date <- xxxx
#sql语句,两表合并
sqlpart1 <- "select a.deviceid,a.tid,a.vid,a.sort_st,a.sort_en, b.home1,b.home2,b.company1,b.company2"
data_name1 <- paste0("ubi_dw_cluster_point_",stat_date)
data_name2 <- paste0("ubi_dm_address_recognition_",stat_date)
sqlpart2 <- paste("from", data_name1, "as a inner join" ,data_name2 ,"as b",sep = " ")
sqlpart3 <- "on a.deviceid = b.deviceid"
trip<-sql(hiveContext,paste(sqlpart1,sqlpart2,sqlpart3,"limit 10000",sep = " "))
#加载包
SparkR:::includePackage(sqlContext, 'plyr')
#添加列
trip = trip %>% withColumn("behavior", lit("0")) %>% withColumn("trip1", lit("0")) %>% withColumn("trip2", lit("0")) %>%
withColumn("trip3", lit("0")) %>% withColumn("trip4", lit("0")) %>% withColumn("trip5", lit("0")) %>%
withColumn("trip6", lit("0")) %>% withColumn("trip7", lit("0")) %>% withColumn("trip8", lit("0"))
#转存为RDD
trip_rdd<-SparkR:::toRDD(trip)
######## zip&groupBy with keys #####################################
#划分分区
list_rd<-SparkR:::map(trip_rdd, function(x) {
user<-matrix(unlist(x),floor(length(unlist(x))/18),ncol=18,byrow=T)
user<-user[1,1]
})
#分区子集
stat_rdd<-SparkR:::map(trip_rdd, function(x) {
stat_trip<-matrix(unlist(x),floor(length(unlist(x))/18),ncol=18,byrow=T)
stat_trip
})
#通过分区对数据进行操作
rdd<-SparkR:::zipRDD(list_rd,stat_rdd)
parts <- SparkR:::groupByKey(rdd,240L)
SparkR:::cache(parts)
#对分区内数据操作,里面和R程序一样
user_behavior<-SparkR:::mapValues(parts, function(x) {
library("plyr")
user_trip<-matrix(unlist(x),floor(length(unlist(x))/18),ncol=18,byrow=T)
user_trip <- data.frame(user_trip,stringsAsFactors = F)
names(user_trip) <- c("imei","tid","vid","sort_st","sort_en","home1","home2","company1","company2","behavior",
"trip1","trip2","trip3","trip4","trip5","trip6","trip7","trip8")
user_trip$imei <- gsub(" ","",user_trip$imei)
user_trip$tid <- as.numeric(user_trip$tid)
user_trip$vid <- as.numeric(user_trip$vid)
user_trip$sort_st <- as.numeric(user_trip$sort_st)
user_trip$sort_en <- as.numeric(user_trip$sort_en)
user_trip$home1 <- as.numeric(user_trip$home1)
user_trip$home2 <- as.numeric(user_trip$home2)
user_trip$company1 <- as.numeric(user_trip$company1)
user_trip$company2 <- as.numeric(user_trip$company2)
homecompany <- unique(user_trip[,c(1:3,6:9,11:18)])
homecompany$trip1 <-base::paste(homecompany$home1,"_",homecompany$company1,sep = "")
homecompany$trip2 <-base::paste(homecompany$home1,"_",homecompany$company2,sep = "")
homecompany$trip3 <-base::paste(homecompany$home2,"_",homecompany$company1,sep = "")
homecompany$trip4 <-base::paste(homecompany$home2,"_",homecompany$company2,sep = "")
homecompany$trip5 <-base::paste(homecompany$company1,"_",homecompany$home1,sep = "")
homecompany$trip6 <-base::paste(homecompany$company1,"_",homecompany$home2,sep = "")
homecompany$trip7 <-base::paste(homecompany$company2,"_",homecompany$home1,sep = "")
homecompany$trip8 <-base::paste(homecompany$company2,"_",homecompany$home2,sep = "")
exchange_id <- as.numeric(user_trip$sort_st) < as.numeric(user_trip$sort_en)
user_trip$behavior[which(exchange_id)] <- base::paste(user_trip$sort_st,"_",user_trip$sort_en,sep = "")[which(exchange_id)]
user_trip$behavior[which(!exchange_id)] <- base::paste(user_trip$sort_en,"_",user_trip$sort_st,sep = "")[which(!exchange_id)]
user_main <- ddply(user_trip,c("imei","tid","vid","behavior"),each(nrow))
user_main <- ddply(user_main,c("imei","tid","vid"),summarise,behavior = behavior[which.max(nrow)])
user<-merge(user_main,homecompany,by=c("imei","tid","vid"))
homecompany_id <- user$behavior == user$trip1 |user$behavior == user$trip2|
user$behavior == user$trip3|user$behavior == user$trip4|user$behavior == user$trip5|
user$behavior == user$trip6|user$behavior == user$trip7|user$behavior == user$trip8
user_main$car_behavior <- user_main$behavior
user_main$car_behavior[homecompany_id] <- 2
user_main$car_behavior[!homecompany_id] <- 1
user_main$car_behavior <- as.integer(user_main$car_behavior)
user_main$dim_month <- as.character(stat_date)
user <- subset(user_main,select = c("imei","tid","vid","dim_month","car_behavior"))
user})
#提取结果
user_behavior_rdd<-SparkR:::values(user_behavior)
######## register dynamic.partitions table #####################################
#转存为DF
user_behavior_df<-SparkR:::toDF(user_behavior_rdd,list("imei",'tid','vid',"dim_month",'car_behavior'))
#写到表中
registerTempTable(user_behavior_df,"behavior")
#写外部表,将运行结果写到表中和HDFS上
sql(hiveContext,"drop table ubi_dw_user_behavior_xxxx")
sql(hiveContext,"CREATE external TABLE ubi_dw_user_behavior_xxxxx (
imei string,
tid int,
vid int,
dim_month string,
car_behavior int
) ROW FORMAT delimited FIELDS TERMINATED BY '#' location 'hdfs:.../ubi_dw_user_behavior/stat_date=xxxx'")
sql(hiveContext,paste("insert overwrite table",paste0("ubi_dw_user_behavior_",stat_date,"01"),"select imei,tid,vid,dim_month,car_behavior from behavior7",sep = " "))
sparkR.stop()运行代码
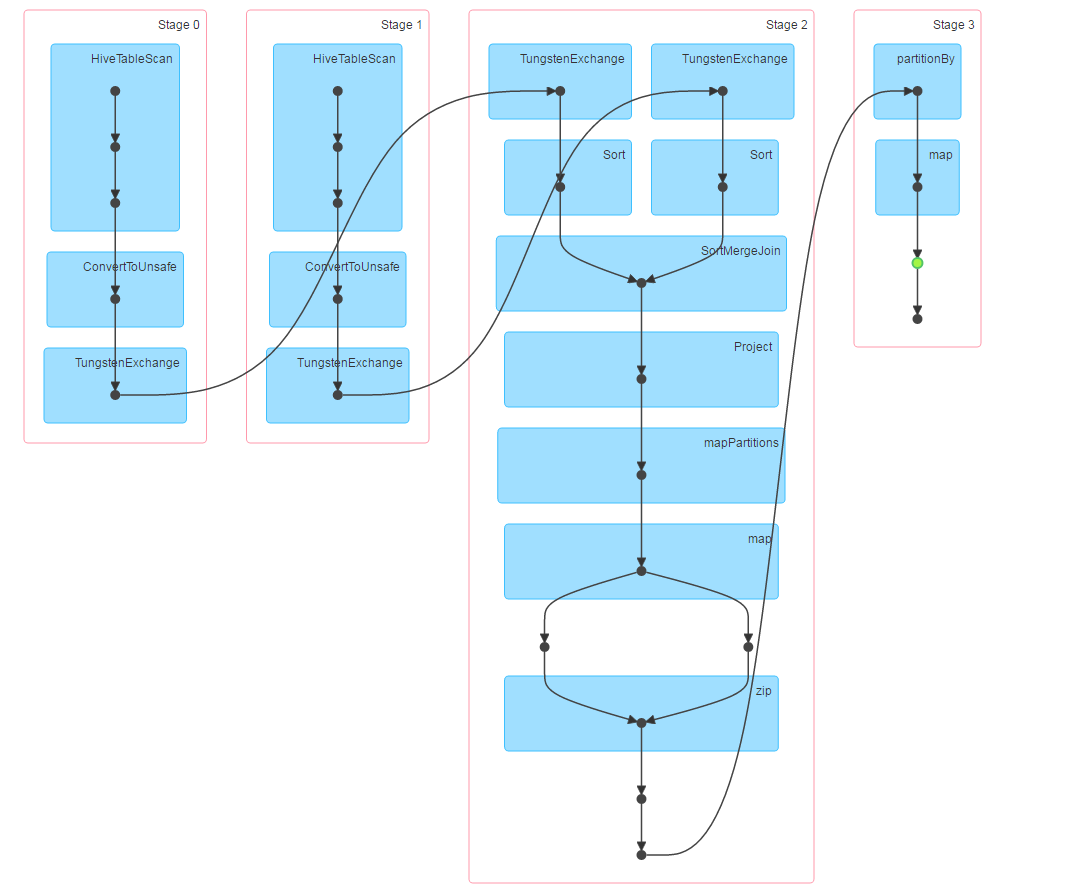
./sparkR /…/r/behavior.R
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









