







字典
字典有一些形如
字典类
字典的节点
// 链表节点定义
template <typename K, typename E>
struct pairNode
{
pair<const K, E> element;
pairNode<K, E>* next;
pairNode() {}
pairNode(const pair<const K, E>& element) : element(element)
{
}
pairNode(const pair<const K, E>& element, pairNode<K, E>* next)
: element(element)
{
this->next = next;
}
};字典类
这里主要实现上述的操作
template <typename K, typename E>
class sortedChain
{
public:
sortedChain();
~sortedChain();
bool emtpy() const
{
return dSize == 0;
}
int size() const
{
return dSize;
}
pair<const K, E>* find(const K&) const; // 查找操作, 如果找到返回指针,否则返回NULL
void erase(const K&);
void insert(const pair<const K, E>&);
void output(ostream& out) const;
private:
pairNode<K, E>* firstNode;
int dSize;
};字典类的实现
find()
只需要一次遍历,判断currentNode->element.first 和 theKey 是否相等
insert()
插入的时候首先通过查找操作来确定字典中是否存在相同关键字的数对,如果有,则更新(因为是一对一的字典)
template <typename K, typename E>
void sortedChain<K, E>::insert(const pair<const K, E>& thePair)
{
pairNode<K, E>* p = firstNode, *tmp = NULL;
// 遍历链表
while(p != NULL && p->element.first < thePair.first)
{
tmp = p;
p = p->next;
}
// 如果存在相同的key值,更新
if(p != NULL && p->element.first == thePair.first)
{
p->element.second = thePair.second;
return;
}
// 插入
pairNode<K, E>* newNode = new pairNode<K,E>(thePair, p);
if(tmp == NULL)
firstNode = newNode;
else
tmp->next = newNode;
dSize++;
}erase()
template <typename K, typename E>
void sortedChain<K, E>::erase(const K& theKey)
{
pairNode<K, E>* p = firstNode, *tmp = NULL;
while(p != NULL && p->element.first < theKey)
{
tmp = p;
p = p->next;
}
if(p != NULL && p->element.first == theKey)
{
if(tmp == NULL) // 这种情况的出现是因为while循环没有执行,之所以不执行是因为, 要没删除的theKey是第一个
firstNode = p->next;
else
tmp->next = p->next;
// 删除p(thekey所在位置)
delete p;
--dSize;
}
}跳表
构建思路
当我们在进行链表查找,删除,添加的时候,要进行n次的比较,如果链表的中间有一个指针,那么我们的这些操作次数可以减少一半。
定义
增加额外的向前指针的链表叫做跳表,因此它会比普通的链表复杂一点。跳表结构的头结点需要足够的指针域,以满足最大链表级数的构建需要,而尾节点不需要指针域。
如下图的结构我们叫做跳表,在该结构中有一组等级链表,0级链表包括所有数对,1级链表每2个节点取一个,2级链表每4个取一个,当然隔几个取一个指针不是固定的。
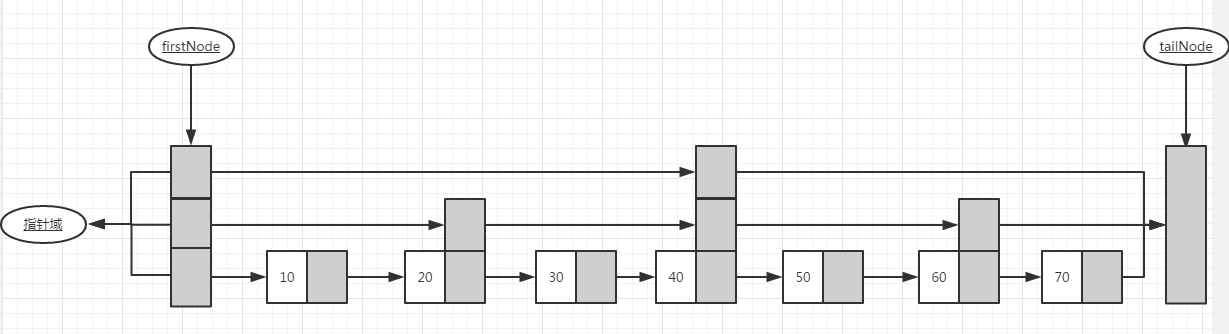
跳表类
节点
与字典节点结构有点不同,next指针变为指针数组,即指针域
template <typename K, typename E>
struct skipNode
{
typedef pair<const K, E> pairType;
pairType element;
skipNode<K, E>** next; // 指针数组
skipNode(const pairType& thePair, int size) : element(thePair)
{
next = new skipNode<K, E>*[size];
}
};跳表类
template <typename K, typename E>
class SkipList
{
public:
SkipList(K largeKey, int maxPairs, float prob);
~SkipList();
// find, 如果找到返回指针,没有返回NULL
pair<const K, E>* find(const K& theKey) const;
// level,级的分配
int level() const;
// search,搜索
skipNode<K,E>* search(const K& theKey) const;
// insert, 插入操作
void insert(const pair<const K, E>& thePair);
// erase,删除操作
void erase(const K& theKey);
private:
float cutOff; // 用来确定层数
int levels; // 当前最大的非空链对
int dSize; // 字典的数对个数
int maxLevel; // 允许的最大链表层数
K tailKey; // 最大关键字
skipNode<K, E>* headerNode; // 头结点指针
skipNode<K, E>* tailNode; // 尾节点指针
skipNode<K, E>** last; // last[i] 表示i层的最后节点
};删除
在删除节点后需要重新更新级数
查找
例如,如果我们要查找关键字为30的节点,find从最高级链表开始查找,知道0级链表。在每一级链表中采用逼近的方法,直到0级链表,图解如下:
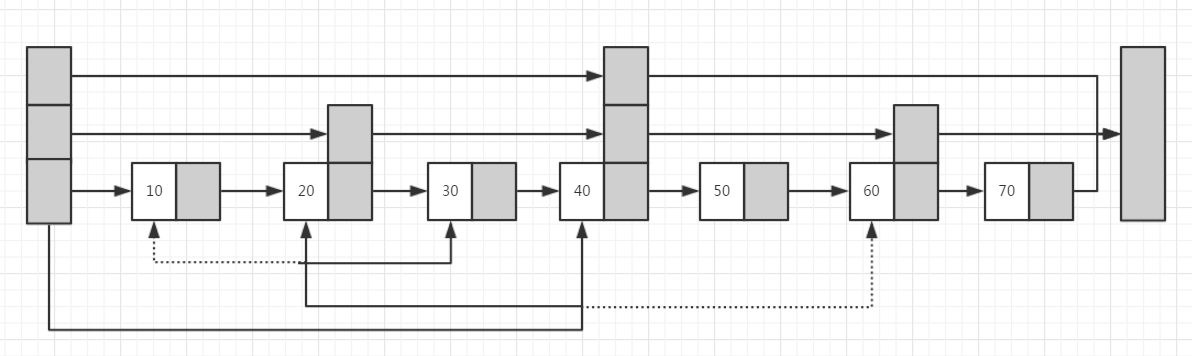
部分代码
template <typename K, typename E>
pair<const K, E>* SkipList<K,E>::find(const K& theKey) const
{
// 返回匹配的数对的指针
// 如果关键字大于最大关键字,返回NULL
if(theKey >= tailKey)
return NULL;
// 位置beforeNode是关键字为theKey的节点之最右边的位置
skipNode<K,E>* beforeNode = headerNode;
for(int i = levels; i >= 0; i--)
while(beforeNode->next[i]->element.first < theKey)
beforeNode = beforeNode->next[i];
if(beforeNode->next[0]->element.first == theKey)
return &beforeNode->next[0]->element;
return NULL;
}完整代码
/* 跳表实现 */
#ifndef _SKIPLIST_H_
#define _SKIPLIST_H_
#include <iostream>
#include <cstdlib> // RAND_MAX
#include <cmath> // ceil()
#include <new>
using namespace std;
template <typename K, typename E>
struct skipNode
{
typedef pair<const K, E> pairType;
pairType element;
skipNode<K, E>** next;
skipNode() {}
skipNode(const pairType& thePair, int size) : element(thePair)
{
next = new skipNode<K, E>* [size];
}
};
template <typename K, typename E>
class SkipList
{
public:
SkipList() {}
SkipList(K largeKey, int maxPairs, float prob);
~SkipList();
// find, 如果找到返回指针,没有返回NULL
pair<const K, E>* find(const K& theKey) const;
// level,级的分配
int level() const;
// search,搜索
skipNode<K,E>* search(const K& theKey) const;
// insert, 插入操作
void insert(const pair<const K, E>& thePair);
// erase,删除操作
void erase(const K& theKey);
private:
float cutOff; // 用来确定层数
int levels; // 当前最大的非空链对
int dSize; // 字典的数对个数
int maxLevel; // 允许的最大链表层数
K tailKey; // 最大关键字
skipNode<K, E>* headerNode; // 头结点指针
skipNode<K, E>* tailNode; // 尾节点指针
skipNode<K, E>** last; // last[i] 表示i层的最后节点
};
template <typename K, typename E>
SkipList<K, E>::SkipList(K largeKey, int maxPairs, float prob)
{
// 构造函数,关键字小于largeKey且数对个数size最多为maxPairs, 0 < prob < 1;
cutOff = prob * RAND_MAX;
maxLevel = (int)ceil(logf((float)maxPairs) / logf(1 / prob)) - 1; // 向上取整
levels = 0;
dSize = 0;
tailKey = largeKey;
// 生产头结点,尾节点和数组last
pair<K,E> tailPair;
tailPair.first = tailKey;
headerNode = new skipNode<K, E> (tailPair, maxLevel + 1);
tailNode = new skipNode<K, E> (tailPair, 0);
last = new skipNode<K, E>*[maxLevel + 1];
for(int i = 0; i <= maxLevel; i++)
headerNode->next[i] = tailNode;
}
template <typename K, typename E>
SkipList<K,E>::~SkipList()
{
// Empty
}
template <typename K, typename E>
pair<const K, E>* SkipList<K,E>::find(const K& theKey) const
{
// 返回匹配的数对的指针
// 如果关键字大于最大关键字,返回NULL
if(theKey >= tailKey)
return NULL;
// 位置beforeNode是关键字为theKey的节点之最右边的位置
skipNode<K,E>* beforeNode = headerNode;
for(int i = levels; i >= 0; i--)
while(beforeNode->next[i]->element.first < theKey)
beforeNode = beforeNode->next[i];
if(beforeNode->next[0]->element.first == theKey)
return &beforeNode->next[0]->element;
return NULL;
}
template <typename K, typename E>
int SkipList<K,E>::level() const
{
// 返回一个表示链表级的随机数,这个数不大于maxLevel
int lev = 0;
while(rand() <= cutOff)
lev++;
return (lev <= maxLevel) ? lev : maxLevel;
}
template <typename K, typename E>
skipNode<K, E>* SkipList<K, E>::search(const K& theKey) const
{
// 返回beforeNode时关键字
skipNode<K, E>* beforeNode = headerNode;
for(int i = levels; i >= 0; i--)
{
while(beforeNode->next[i]->element.first < theKey)
beforeNode = beforeNode->next[i];
last[i] = beforeNode;
}
return beforeNode->next[0];
}
template <typename K, typename E>
void SkipList<K,E>::insert(const pair<const K, E>& thePair)
{
if(thePair.first >= tailKey)
{
cout << "Key = " << thePair.first << " must be < " << tailKey;
return;
}
// 查看关键字是否已经存在
skipNode<K, E>* theNode = search(thePair.first);
if(theNode->element.first == thePair.first)
{
theNode->element.second = thePair.second;
return;
}
// 若不存在, 确定所在链级数
int theLevel = level();
if(theLevel > levels)
{
theLevel = ++levels;
last[theLevel] = headerNode;
}
// 再借点theNode 之后插入新节点
skipNode<K, E>* newNode = new skipNode<K, E>(thePair, theLevel + 1);
for(int i = 0; i < theLevel; i++)
{
// 插入i级链表
newNode->next[i] = last[i]->next[i];
last[i]->next[i] = newNode;
}
dSize++;
return;
}
template <typename K, typename E>
void SkipList<K,E>::erase(const K& theKey)
{
if(theKey >= tailKey)
return;
//查看是否有匹配的数对
skipNode<K,E>* theNode = search(theKey);
if(theNode->element.first != theKey)
return;
for(int i = 0; i <= levels && last[i]->next[i] == theNode; i++)
last[i]->next[i] = theNode->next[i];
while(levels > 0 && headerNode->next[levels] == tailNode)
levels--;
delete theNode;
dSize--;
}
#endif // !_SKIPLIST_H_















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









