







文章目录
前言
数据结构的常见线性表,分别是顺序表,链表,栈,队列
本篇给大家带来带头双向循环链表的实现和讲解
一、带头双向循环链表的结构
1.1、概念
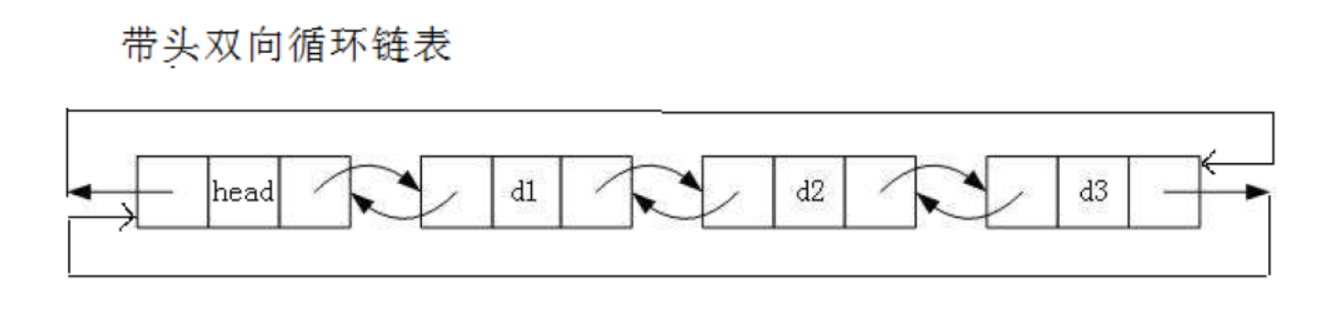
- 带头:不像单链表头节点就存放数据的,这里的作用主要作哨兵位,就不需要传
二级指针,因为对头部没有修改。 - 双向:有两个指针,分别是prev和next,分别存放
前一个节点和后一个节点`的地址 - 循环:头节点的prev尾,尾的next是头节点,意思是头节点前一个是尾,尾下一个是头节点
综上所述,这就是链表的最完美的结构,主要用来存储数据,但是单链表的存在并非没有意义,单链表主要做复杂数据结构的子结构和OJ,无论是尾插,头插等等,都是非常方便,而且实现也比较简单
二、带头双向链表的实现
2.1、结构定义
单个结点包含三个部分:前指针(prev)、数据(data)、后指针(next)

// 链表的结构
typedef int ListDataType;
// 链表的结构
typedef struct ListNode
{
ListDataType data; // 数据域
struct ListNode* prev; // 前一个结点
struct ListNode* next; // 后一个结点
}ListNode;
2.2、初始化
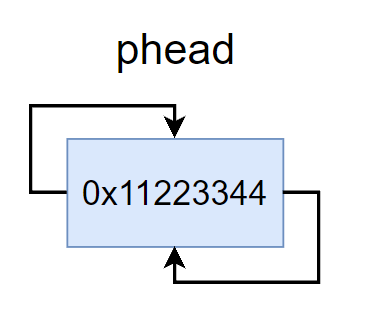
注意初始化是这里返回类型,我们是通过函数来完成初始化的,说明我们调用函数把头节点给修改,但是并没有用二级指针,这里我用的另外一个方法是函数的返回
该链表的结构十分的巧妙,只有一个节点的时候,就是哨兵位节点,不存储有效数据,而是做一个标志(哨兵)方便对第一个数据修改,而已他的next和prev都是指向自己,这是由于循环的特性,在删除和插入的是方便统一操作。
// 初始化
ListNode* ListInit()
{
// 申请一块空间
ListNode* phead = (ListNode*)malloc(sizeof(struct ListNode));
assert(phead); // 防止误操作
phead->next = phead;
phead->prev = phead;
return phead;
}
我就应该这样调用

初始化后的结点如图
2.2、创建一个节点
每次插入的时候,我们都需要写很多重复的代码,所以可以把创建节点写成一个函数,后面方便调用。
// 创建一个节点
ListNode* ListCreateNode(ListDataType x)
{
ListNode* newNode = (ListNode*)malloc(sizeof(ListNode));
assert(newNode);
newNode->data = x;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}
2.3、尾插

大家可以把代码代入图中(走读代码)就可以很清晰的明白这个过程
// 尾插
void ListPushBack(ListNode* phead, ListDataType x)
{
// 实参不能传NULL
assert(phead);
ListNode* newNode = ListCreateNode(x);
ListNode* tail = phead->prev;
// phead tail newNode
tail->next = newNode;
newNode->prev = tail;
newNode->next = phead;
phead->prev = newNode;
}
2.4、头插
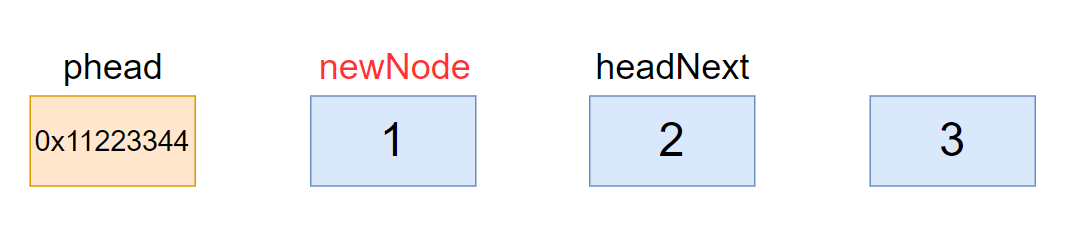
// 头插
void ListPushFront(ListNode* phead, ListDataType x)
{
// 实参不能传NULL
assert(phead);
ListNode* newNode = ListCreateNode(x);
ListNode* headNext = phead->next;
// phead newNode headNext
newNode->next = headNext;
headNext->prev = newNode;
phead->next = newNode;
newNode->prev = phead;
}
2.5、尾删
要注意只有哨兵位不能删除,我这里加的assert(断言),为假就报错,所以
phead->next != phead

// 尾删
void ListPopBack(ListNode* phead)
{
// 实参不能传NULL
assert(phead);
// 就哨兵位一个不能删除
assert(phead->next != phead);
ListNode* tail = phead->prev;
ListNode* tailPrev = tail->prev;
// phead tailPrev tail
tailPrev->next = phead;
phead->prev = tailPrev;
free(tail);
}
2.6、头删
要注意只有哨兵位不能删除,我这里加的assert(断言),为假就报错,所以
phead->next != phead
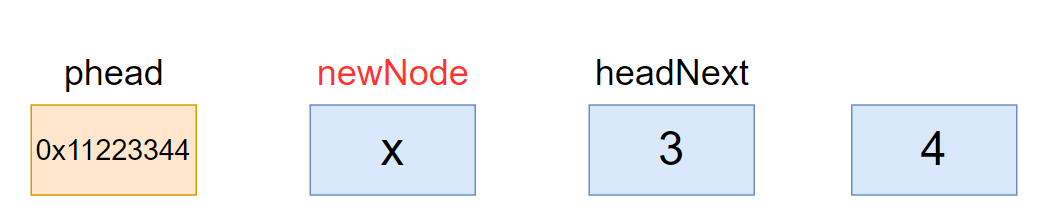
// 头删
void ListPopFront(ListNode* phead)
{
// 实参不能传NULL
assert(phead);
// 就哨兵位一个不能删除
assert(phead->next != phead);
ListNode* head = phead->next;
ListNode* headNext = head->next;
// phead head headNext
phead->next = headNext;
headNext->prev = phead;
free(head);
}
2.7、打印
由于循环的特性,所以没有NULL,所以我们打印的停止条件也要改变,从phead的下一个开始打印,因为phead不存有效数据,打印一圈回到phead即可。
// 打印
void ListPrint(ListNode* phead)
{
// 实参不能传NULL
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
同时我们在测试下刚才写的插入和删除
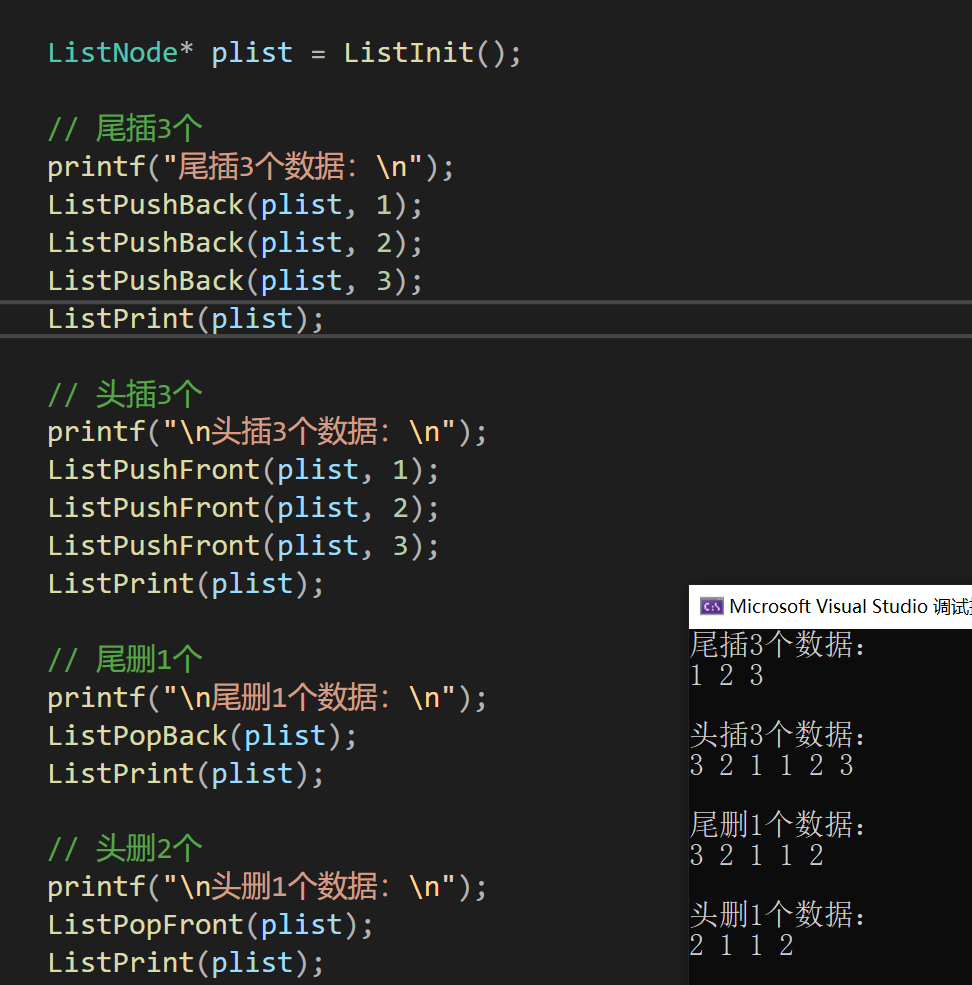
2.8、查找
找到还是返回节点,可以和pos配合或者直接修改那个节点的数据,找不到就返回NULL。
// 查找
ListNode* ListFind(ListNode* phead, ListDataType x)
{
// 防止实参传NULL过来
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
}
2.9、pos位置(pos前)插入
这里就不需要传链表的头
- 带哨兵位的原因,不会修改头节点
- 由于双向的特性,可以直接找到前后节点,不需在遍历
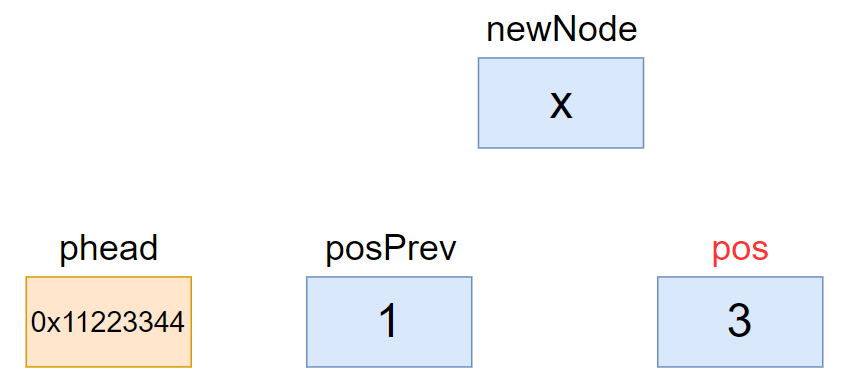
// pos处插入
void ListInsert(ListNode* pos, ListDataType x)
{
assert(pos);
ListNode* newNode = ListCreateNode(x);
ListNode* posPrev = pos->prev;
// prevPos newNode pos
posPrev->next = newNode;
newNode->prev = posPrev;
newNode->next = pos;
pos->prev = newNode;
}
2.10、pos位置删除
这里就不需要传链表的头
- 带哨兵位的原因,不会修改头节点
- 由于双向的特性,可以直接找到前后节点,不需在遍历

// pos处删除
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* posPrev = pos->prev;
ListNode* posNext = pos->next;
// posPrev pos posNext
posPrev->next = posNext;
posNext->prev = posNext;
free(pos);
}
测试下pos相关操作
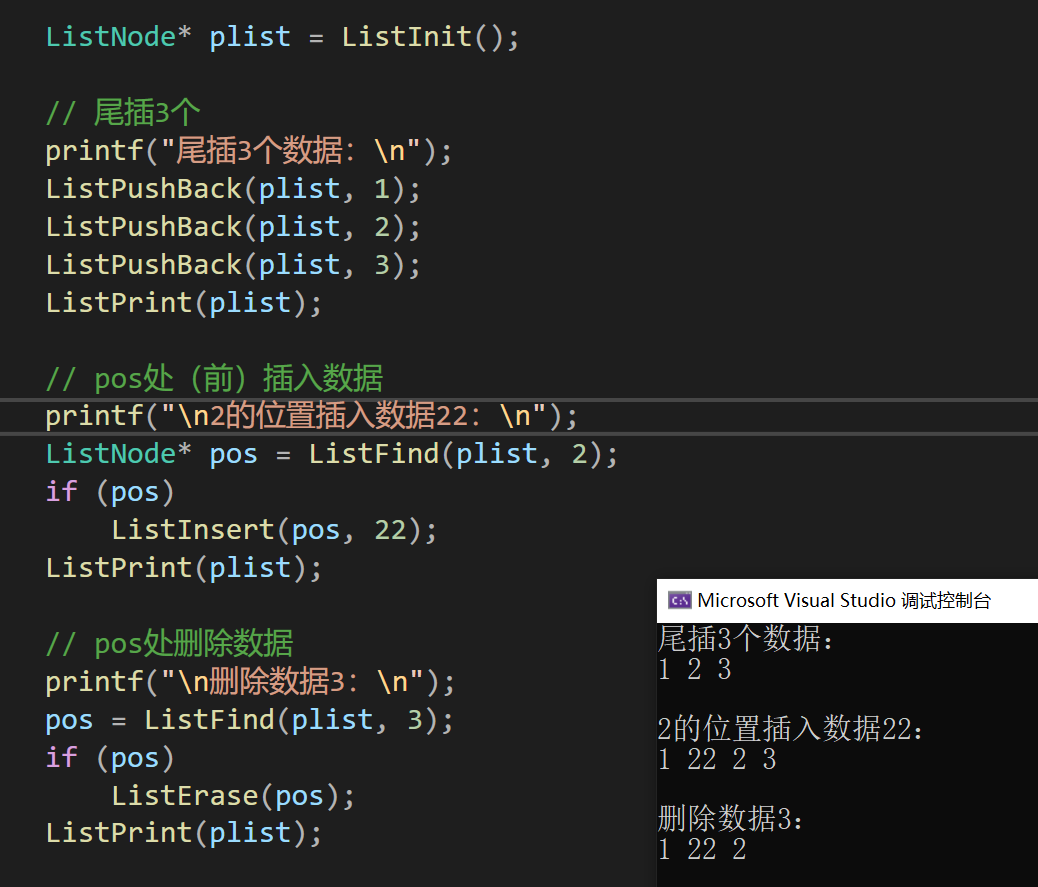
2.11、利用pos复用插入和删除
- 尾插:哨兵位前一个就是尾
// 尾插
void ListPushBack(ListNode* phead, ListDataType x)
{
// 哨兵位前一个就是尾
ListInsert(phead, x);
}
- 头插:哨兵位下一个就是头
// 头插
void ListPushFront(ListNode* phead, ListDataType x)
{
// 哨兵位下一个就是头
ListInsert(phead->next, x);
}
- 尾删:哨兵位前一个就是尾
// 尾删
void ListPopBack(ListNode* phead)
{
// 哨兵位前一个就是尾
ListErase(phead->prev);
}
- 头删:哨兵位下一个是头
// 头删
void ListPopFront(ListNode* phead)
{
// 哨兵位下一个是头
ListErase(phead->next);
}
测试结果,和我们之前写的测试结果一模一样,所以想要快速实现双向带头循环链表功能,可以直接写这两个函数即可。

2.12、销毁
由于函数接口的一致性,我们最好传一级指针,还是这有一个问题,就是phead会野指针,我们无法在函数内把phead置为NULL,所以就只能在主函数里置为NULL,在函数体内也是需要手动置空,所以不一定要在函数体内置NULL,可以在外面置空
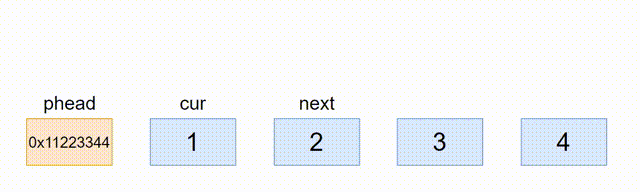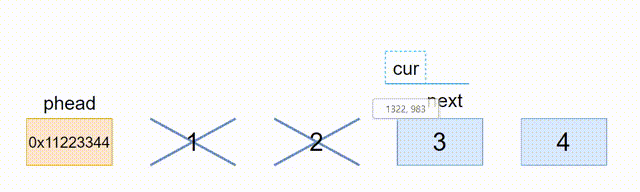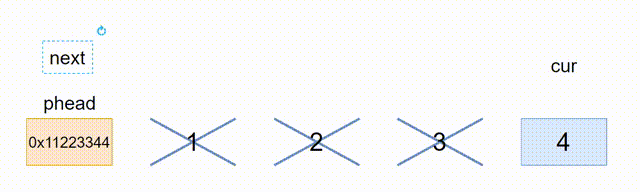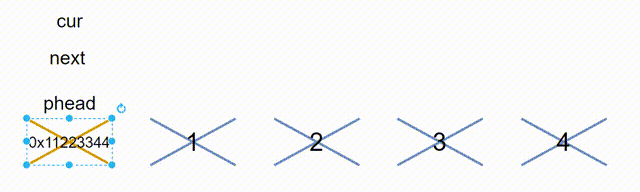
// 销毁
void ListDestroy(ListNode* phead)
{
ListNode* cur = (phead)->next;
while (cur != phead)
{
ListNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
}
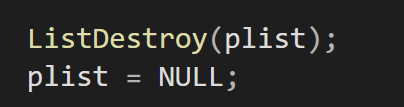
主函数调用销毁后,手动在置空
总结
带头双向循环链表,虽然结构复杂但是实现起来特别简单,如果想快速实现功能可以直接写两个函数,pos的插入和删除,带头双向循环链表主要还是主要存储数据。















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









