







顺序表和链表的优缺点
一、顺序表
1.1、优点
- 支持随机访问(用下标访问),
时间复杂度为O(1)
顺序表在物理上是连续,如一些排序,二分查找等都是类似为与顺序表的结构 - CPU高速缓存命中率
高
1.2、缺点
- 头部中部的插入删除效率低,
时间复杂度为O(N)
顺序表是从开始的位置连续存储数据,对头部和中间的数据进行操作,就需要挪动数据,效率很低 - 空间不够需要扩容
顺序表的扩容其实是很不高效的,扩容分两种,1. 原地扩容 2.异地扩容
- 原地扩容:当前扩容的地方,还剩多的空间够你扩容
- 异地扩容:当前扩容的地方,没有多的空间够你扩容,系统就自动的帮你到内存堆上找一个足够大(比扩容后的空间大)的空间,再把之前空间的数据可以拷贝过来,在销毁以前的空间,这样的效率非常低
- 扩容空间浪费
为了避免频繁扩容,一般都是扩2倍,可能会导致一定的空间浪费,如:原来的空间有100个,满了,扩容到200个,我们就在想插入5个,就会有95个空间浪费,而且你删除的数据多了,更加空间浪费,他并不会释放空间。
二、链表
2.1、优点
- 任意位置插入删除效率高,
时间复杂度为O(1) - 按需申请释放空间
2.2、缺点
- 不支持随机访问(下标访问)
由于链表在物理上是不连续的 - 链表每一个节点都需要申请,在存储上面有一定的消耗
5个节点,就需要5个结构体,每个结构体里面还需要存指针。 - CPU高速缓存命中率
低 - 缓存污染

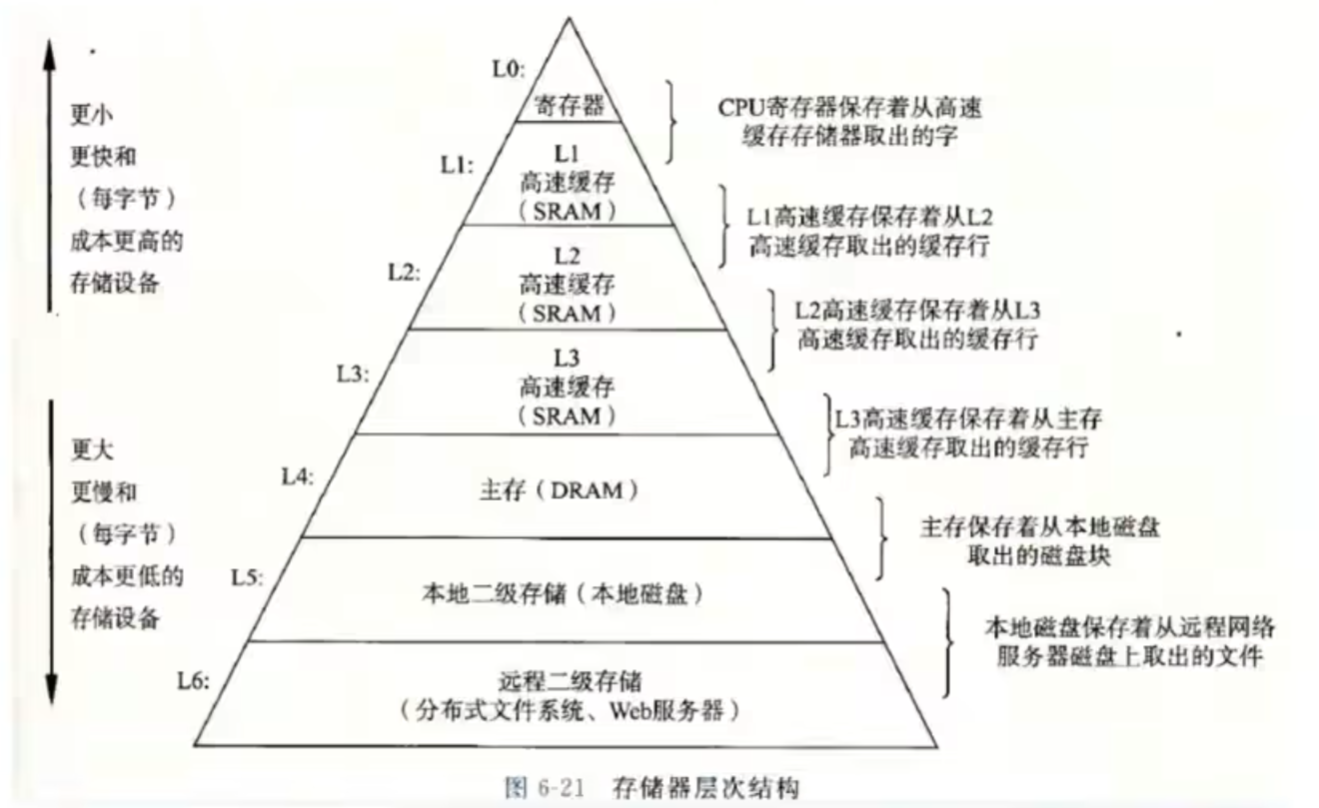
三、CPU高速缓存缓存命中率
计算机的存储分为内储存器和外存储器。
内储存器:寄存器,三级缓存(L1,L2,L3),主存(内存)
外存储器:硬盘
高速缓存的作用:解决CPU和内存速度不匹配

我们编写了一段代码(.c),需要进行 预编译,编译,汇编,链接,才能变成可执行文件(.exe)。
编译:高级语言(我们写的代码语句)变为汇编代码
在汇编的过程中汇编代码又变成机器码(机器语言),也就是我们说的指令
指令会将内存的数据传输到寄存器或缓存中,最后写入内存
寄存器:速度最快,存储小,一个寄存器一般能存4Byte或8Byte的数据
如:a+b
数据较小,指令就会将a和b放到寄存器里,在寄存器里进行运算,最后写入内存
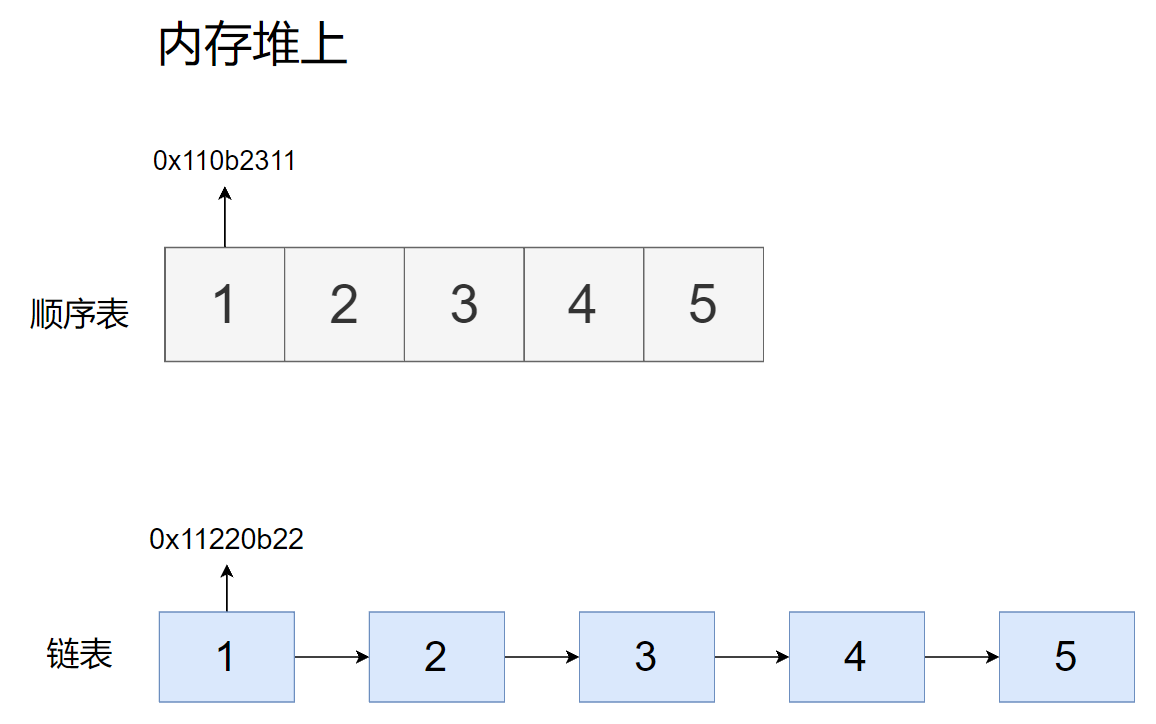
我们分别遍历一遍顺序表和链表
- 都存放5个数据
- 顺序表数据1地址是
0x110b2311 - 链表数据1地址是是
0x11220b22
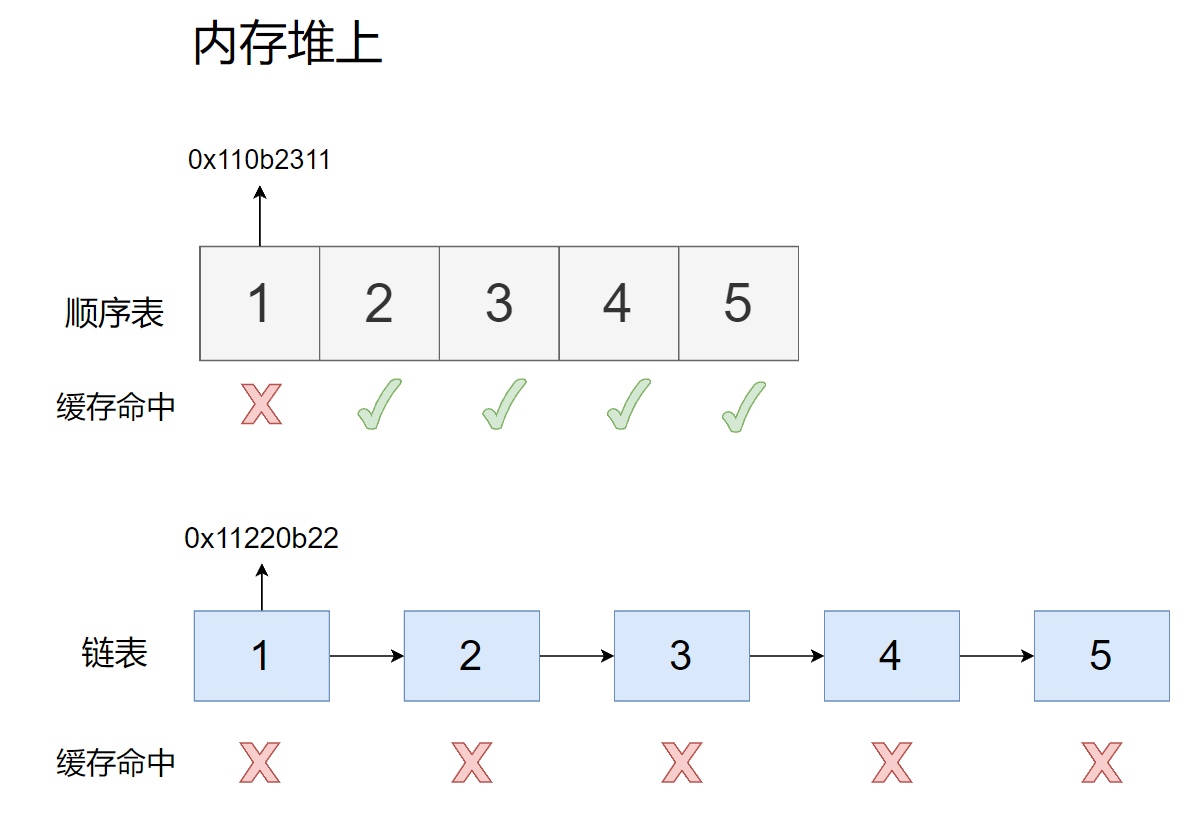
现在就体现出CPU高速缓存缓存命中率这个概念了
CPU会看这数据1的内存地址是否在缓存中
- 在:命中,直接访问数据
- 不在:未命中,把一块连续空间数据放入到缓存中(空间局部性),放入多少数据这要看内存的大小。
第一次都是未命中
第二次,由于空间局部性原理(下一次访问该地址的附近地址)
- 顺序表:命中,物理地址连续,第一次把后面的数据预加载到缓存
- 链表:未命中,物理地址是不连续。
所以结果是:顺序表除了第一次未命中,后面几次都命中。链表第一次未命中,其他几次几乎都不会命中
链表还会造成缓存污染。
四、缓存污染是什么?
缓存污染是指操作系统将不常用的数据从内存移到缓存,降低了缓存效率的现象。
就按我们刚才的例子,分别遍历顺序表和链表
顺序表只有1次未命中,链表几乎5次未命中
假设一次加载20Byte数据到缓存(具体多少取决于CPU)
我们遍历的数据就5个int整形,1个int整形占4Byte,一共20Byte。
顺序表在缓存里只用了20Byte,链表用了100Byte,所以链表浪费80Byte的缓存空间,然而缓存空间也是有限的,满了的话就需要把近期未访问的数据给移出去
五、总结
经过这么多对比,可以发现顺序表和链表就是互补的存在,两个都有存在的意义和自己擅长的领域。















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









