







1 设定评估指标
1.1 单一指标(Single Number Evaluation Metric)
下表给出了两个模型,Precision和Recall的意思如下:模型A有95% Precision,表明如果模型A判断类别为猫,实际有95%的概率真正是猫;模型A有90% Recall,表明有90%的猫被正确识别。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
可以看出,如果用Precision作指标,模型B优于A;如果用Recall作指标,模型A优于B。两个指标就很难区分模型A和B的优劣。因此,在机器学习中,通常将Precision和Recall结合起来,采用F1 Score作为指标来挑选模型。
F1=11Precision+1Recall(1)
采用单一指标,就很容易选取最好的模型。
1.2 满足指标和优化指标(Satisficing and Optimizing Metric)
假如想同时采用准确率和运行时间来判断模型的优劣,例如下表:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
则可以如下设置:
maximize{accuracy},subjecttorunningtime≤100ms(2)
这表明,应当在运行时间100 ms以内,对准确率进行优化,运行时间就是满足指标(Satisficing Metric),准确率就是优化指标(Optimizing Metric)。
1.3 开发集/测试集(Dev/Test Set)
在确定开发集/测试集数据时,将所有数据重新排序,随机分类为开发集和测试集,这样,可以确保开发集和测试集来自于相同分布。同时,应当确保开发集和测试集能够反应未来实际使用场景的数据。
测试集大小的确定:足够大,能够比较可信地反映出系统的整体性能。
2 与人类性能(Human-level Performance)对比
2.1 为什么与人类性能对比?
机器学习的性能通常与人类性能作比较。通常,机器学习的性能会不断提升,但是受到Bayers最优误差的限制,不会达到100%的准确率。
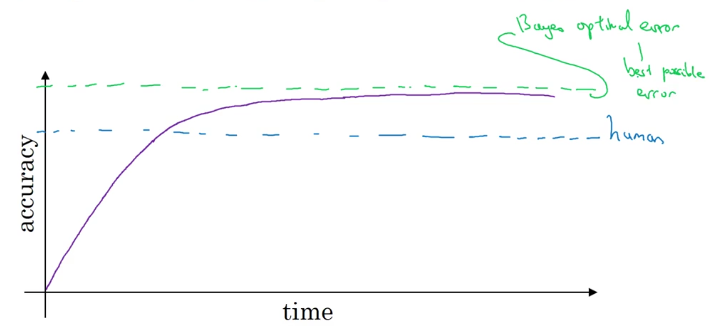
如果机器学习的性能比人类差,可以尝试:
(1) 得到人类标注的数据;
(2) 人工进行误差分析:为什么人类识别正确;
(3) 对偏差/方差详细分析。
2.2 可避免偏差(Avoidable Bias)
对于下表,人类误差仅有1%,而训练集误差为8%,此时应当将注意力放在训练集上,以降低偏差bias。
|
|
|
|---|---|
|
|
|
|
|
|
对于下表,人类误差有7.5%,训练集误差为8%,接近人类误差,此时应当将注意力放在开发集上,以降低方差variance。
|
|
|
|---|---|
|
|
|
|
|
|
可以采用人类误差作为估计的Bayers最优误差,来确定训练集误差的下限。训练集误差和Bayers最优误差可能存在一定差别,称作可避免偏差(Avoidable Bias)。
假设对于医疗图像,有如下误差:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
那么Bayers最优误差小于0.5%,因此可以采用0.5%作为估计的人类误差。
2.3 超越人类性能
当机器学习达到人类学习误差后,仍然有机会超越人类性能。实际上,机器学习在很多方面已经超越了人类性能,例如在线广告、预测线路等等,这些都是与人类感知无关的问题。而在计算机视觉、语音识别等与人类感知相关的问题上,机器学习仍然有待进步。
3 误差分析(Error Analysis)
3.1 误差分析的流程
在分析猫咪分类器识别误差时,发现一些错误识别的图像是狗的图片,是否应当改善模型使其对狗有更好的识别?
误差分析的流程如下:
(1) 从开发集中找出100张错误识别的图片,计算狗图片的比例;
(2) 如果仅有5%的狗图片,即使改善模型使其对狗有更好的识别,错误率可能仅仅从10%降低到9.5%,就没有必要花时间去改善模型;
(3) 如果有50%的狗图片,那么改善模型,错误率可能从10%降低到5%,因此有必要花时间去改善模型。
通常,会有多个可以选择的方向,例如:
(1) 改善将狗图片识别为猫咪图片的问题;
(2) 改善将狮子图片识别为猫咪图片的问题;
(3) 提升模糊图片的识别率。
在分析时,可以将这些问题写入如下表格:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2 开发集/测试集标注错误
开发集/测试集中可能存在标注错误的图片,可以在误差分析时加一行列:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果开发集误差为10%,错误标注误差为6%,那么纠正错误标注的图片仅能够使开发集误差降低到9.4%,就不是优先需要处理的问题;如果错误标注的误差较高,那么应当花时间去纠正错误标注的图片。
在纠正错误标注数据时,应当确保对开发集和测试集有相同的操作,确保开发集和测试集来自相同的分布。此时,可以允许训练集和开发集的分布略有不同,训练算法对此具有不错的鲁棒性。
3.3 快速构建系统
(1) 设置开发集/测试集,构建评价指标;
(2) 快速构建初始系统;
(3) 采用偏差/方差分析和误差分析去优化。
4 训练集和开发集/测试集的不匹配(Mismatch)
4.1 不同分布下的训练和测试
假如有200000张图片来自网页,10000张图片来自用户上传,目标是对用户图片进行识别,可以将训练集设置为200000张网页图片 + 5000张用户上传图片,开发集和测试集分别为2500张用户上传图片。
4.2 不同分布下的偏差/方差分析
假设人类误差约为0%,训练集误差1%,开发集误差10%。如果训练集和开发集来自于相同分布,那么训练存在方差大过拟合的问题;如果训练集和开发集来自于不同分布,还有可能开发集比训练集的识别难度更大,例如开发集数据更模糊等,这样就很难判断9%的差距是来自于算法还是来自于数据不匹配。
解决方法是,设置训练 – 开发集,与训练集来自于相同分布,但是不用于训练。这样,如果训练 – 开发集的误差为9%,那么就是算法过拟合;如果训练 – 开发集误差为1.5%,那么方差较小,这就是数据不匹配导致的问题。
实际分析可以列出下表,分析可避免偏差(Avoidable Bias)、方差(Variance)和数据不匹配(Data Mismatch)。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.3 数据不匹配(Data Mismatch)
对训练集和开发集/测试集之间的区别进行误差分析。
使训练集数据尽可能与开发集/测试集更相似,可以采用人工数据合成(Artificial Data Synthesis)。例如,如果开发集/测试集的背景噪声较多,可以在训练集上人工加入噪声生成新的训练集。
5 迁移学习(Transfer Learning)/多任务学习(Multi-task Learning)
5.1 迁移学习(Transfer Learning)
将针对猫咪图片的训练,转移到针对X光片图片的训练,就称作迁移学习(Transfer Learning)。
如下图,将最后一层删除,并加入新的层,设置新的参数W[L]和b[L]。然后将所有数据替换为新的数据,如果数据较少,可以只针对最后一层或者最后两层进行训练,而不用修改前面各层的参数。如果数据较多,可以重新训练整个网络,并将之前的训练当作预训练(Pre-training)。
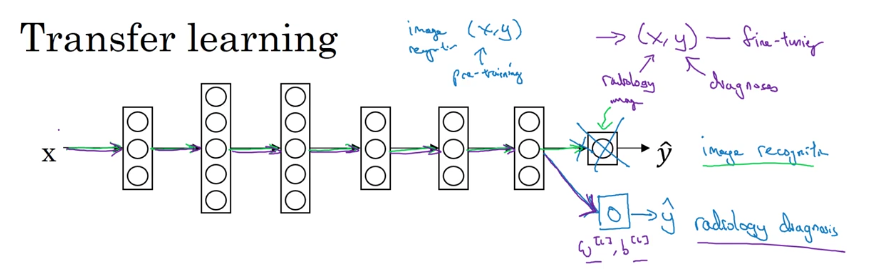
当已知问题的训练数据较多,而新问题的训练数据较少时,迁移学习会有帮助。
5.2 多任务学习(Multi-task Learning)
神经网络同时训练完成多个目标,就称作多任务学习(Multi-task Learning)。
例如下图,输出层有4个单元,与Softmax分类不同,每个数据可以有多个标注。此时,代价函数可以写成:
J=1m∑i=1m∑j=14L(y^(i)j,y(i)j)(3)
与之前的神经网络不同的是,代价函数对输出层的4个单元进行了求和。
当各个目标之间的相似程度较高,而且每个目标的数据量比较接近时,多任务学习会有帮助。
6 端对端深度学习(End-to-end Deep Learning)
以语音识别为例。对于以往的深度学习,对于音频x和翻译y,先要对音频x进行特征提取(如MFCC),然后采用机器学习算法得到音素(Phoneme),由音素得到单词,进而得到翻译y。
audiox→feature→Phoneme→words→transcripty(4)
而在端对端深度学习中,采用单个深度学习网络,直接由音频x得到翻译y。
audiox→transcripty(5)
通常,两步策略可能会工作得更好。例如,对于人脸识别,第一步先识别到人脸并放大,第二部再识别人脸信息得到人的身份信息。
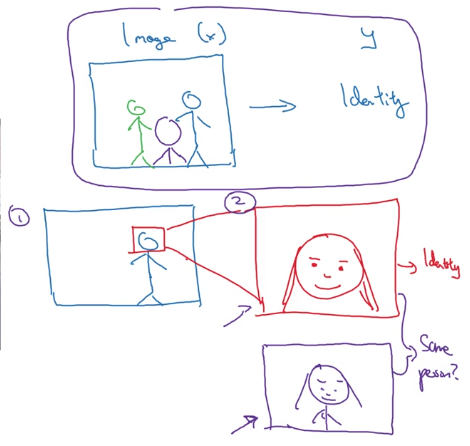
端对端学习的优点:让数据说话,简化网络结构,更少的人工标注。
端对端学习的缺点:可能需要大量数据,排除了可能有用的人工标注。
是否使用端对端学习,关键在于:是否有足够多的数据,来学习输入端到输出端映射的复杂函数。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









