







 本文详细介绍了深度学习中的优化算法,包括小批量梯度下降、动量梯度下降、RMS Prop、Adam算法和学习因子衰减。通过代码实现和实验对比,展示了不同算法在模型训练中的表现,特别是Adam算法在收敛速度和准确率上的优势。
本文详细介绍了深度学习中的优化算法,包括小批量梯度下降、动量梯度下降、RMS Prop、Adam算法和学习因子衰减。通过代码实现和实验对比,展示了不同算法在模型训练中的表现,特别是Adam算法在收敛速度和准确率上的优势。
1. 优化算法
1.1 小批量梯度下降(Mini-batch Gradient Descent)
对于很大的训练集m,可以将训练集划分为T个mini-batch,分批量来学习,这样将第t个mini-batch的参数定义为X{
t}、Y{
t}。训练流程如下:
fort=1,…,TforwardpropagationonX{
t},computecostJ{
t},backwardpropagationtocomputedW[l],db[l],gradientdescentW[l]=W[l]−αdW[l],b[l]=b[l]−αdb[l](1)
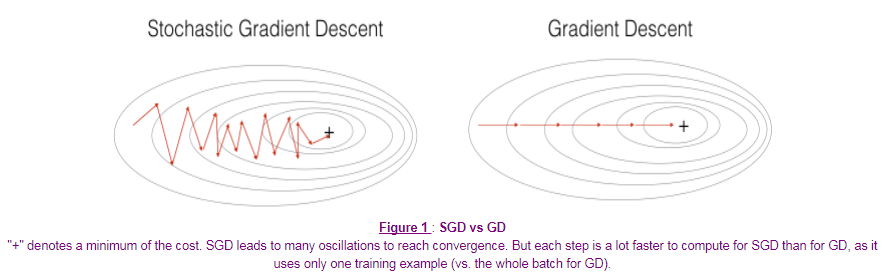
如果mini-batch的大小为m,也就是批量梯度下降(Gradient Descent),参数会沿着梯度最大的方向迭代,代价函数不断下降,但是每次迭代花费的时间较长。
如果mini-batch的大小为1,也就是随机梯度下降(Stochastic Gradient Descent),其中的噪声较多,代价函数会呈波动下降的趋势,不过失去了向量化所带来的计算优势。
选取合适的mini-batch大小,能够减少迭代花费的时间,同时将向量化计算的优势也发挥出来。并不能保证每次都能得到代价函数的最小值,但是比随机梯度下降的噪声更小。
Mini-batch大小的选取:如果训练集较小(m < 2000),就使用批量梯度下降法;否则,可以将mini-batch的大小设置为64、128、256、512等。

1.2 动量梯度下降(Gradient Descent with Momentum)
在梯度下降时,波动可能较小,而动量梯度下降的思想是,采用指数加权平均,使得每次梯度下降更加平滑,具体如下:
VdW=β1VdW+(1−β1)dWVdb=β1Vdb+(1−β1)dbW=W−αVdW,b=b−αVdb(2)
上式中,初始化VdW = 0,Vdb = 0。如果β1 = 0,就等效于梯度下降。实践中,β1 = 0.9是比较稳健的数值,也可以选择其他数值。
1.3 均方根传递(RMS Prop, Root Mean Square Prop)
在梯度下降时,例如dW较小、db较大的情况,希望减慢b方向的学习,同时加快或者不减慢W方向的学习,可以采用均方根传递如下:
SdW=β2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









