







Ⅰ:位、整数
信息的位表示
- 计算机存储、处理的信息:二值信号
- “位” 或 “比特”(bit):最底层的二进制数字(数码)称为位(bit,比特),值为0或1
- 位组合:把位组合到一起,采用某种规则进行解读;每个位组合都有含义
- 字节:8-bit 块
二进制数
位权为2^i
MSB:最高有效位(Most Significant Bit)
LSB:最低有效位(Least Significant Bit)

十六进制数
位权为16^i
0, 1,2,3,4,5,6,7,8,9,A,B,C,D,E,F
进制转换(自己试一试)
- 十进制整数转换为k(2、8或16)进制数
- 整数转换:用除法—除基取余法(从下到上)
十进制数整数部分不断除以基数k(2、8或16) ,并记下余数,直到商为0为止。
由最后一个余数起,逆向取各个余数,则为转换成的二进制和十六进制数
126=01111110B 二进制数用后缀字母B
126=7EH 十六进制数用后缀字母H - 小数转换:用乘法—乘基取整法(从上到下)
乘以基数k,记录整数部分,直到小数部分为0为止
0.8125=0.1101B
0.8125=0.DH
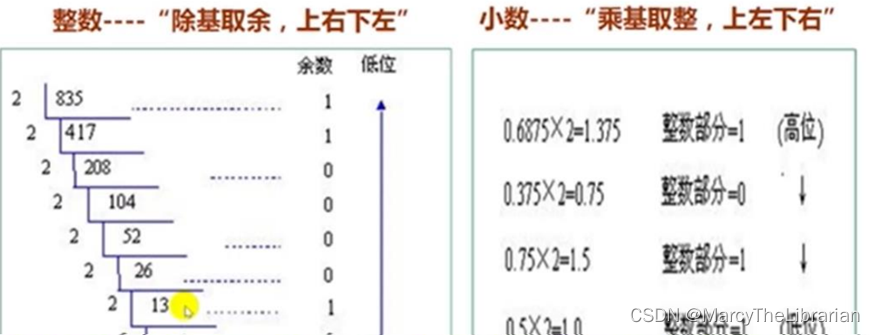
- 整数转换:用除法—除基取余法(从下到上)
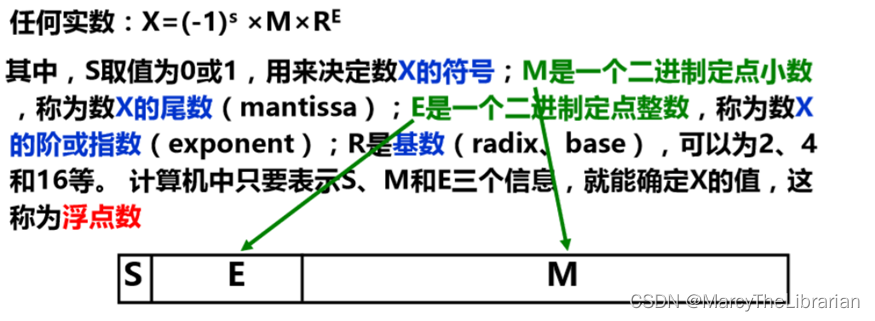
定点数与浮点数
- 定点数:小数点约定在固定位置的数
- 浮点数:小数点约定为可浮动的数
- 定点小数用来表示浮点数的尾数部分
- 定点整数用来表示整数,分带符号整数和无符号整数
X = ( − 1 ) s ∗ M ∗ R E X=(-1)^s\ast M\ast R^E X=(−1)s∗M∗RE
S决定符号;M是定点小数,是尾数;E是二进制定点整数,称为阶或指数
位级运算
布尔代数(Boolean Algebra)
&:相与,|:相或,~:取反,^:异或


C语言中的移位运算
- 左移: x << y
将位向量x向左移动y位
逻辑左移和算术左移都是补0 - 右移: x >> y
将位向量x向右移动y位
逻辑右移:在左边补0
算术右移:复制左边的最高位(y次)
整型数
表示:无符号数和有符号数
无符号数:
B
2
U
(
X
)
=
∑
i
=
0
w
−
1
x
i
⋅
2
i
B2U(X)=\sum_{i=0}^{w-1}x_i·2i
B2U(X)=∑i=0w−1xi⋅2i
有符号数——补码:
B
2
T
(
X
)
=
−
x
w
−
1
⋅
2
w
−
1
+
i
=
0
w
−
2
x
i
⋅
2
i
B2T(X)=-x_{w-1}·2w-1+i=0w-2xi·2i
B2T(X)=−xw−1⋅2w−1+i=0w−2xi⋅2i
无符号数值:
U
M
i
n
=
0
UMin=0
UMin=0
U
M
a
x
=
2
w
−
1
UMax=2^{w-1}
UMax=2w−1
补码数值:
T
M
i
n
=
−
2
w
−
1
TMin=-2^{w-1}
TMin=−2w−1
T
M
a
x
=
2
w
−
1
−
1
TMax=2^{w-1}-1
TMax=2w−1−1
位数 W = 16 时的数值
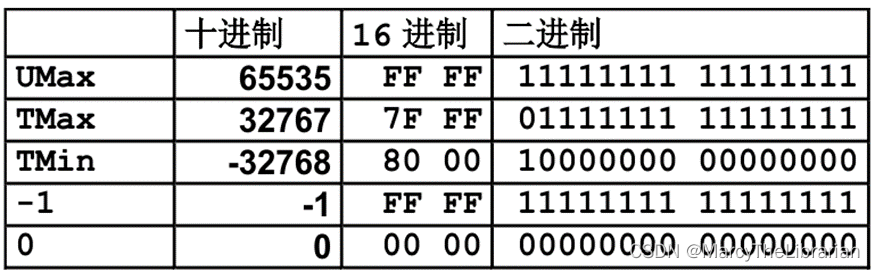
不同字长的数值

机器数
机器数:最高位0表示非负数,1表示负数。
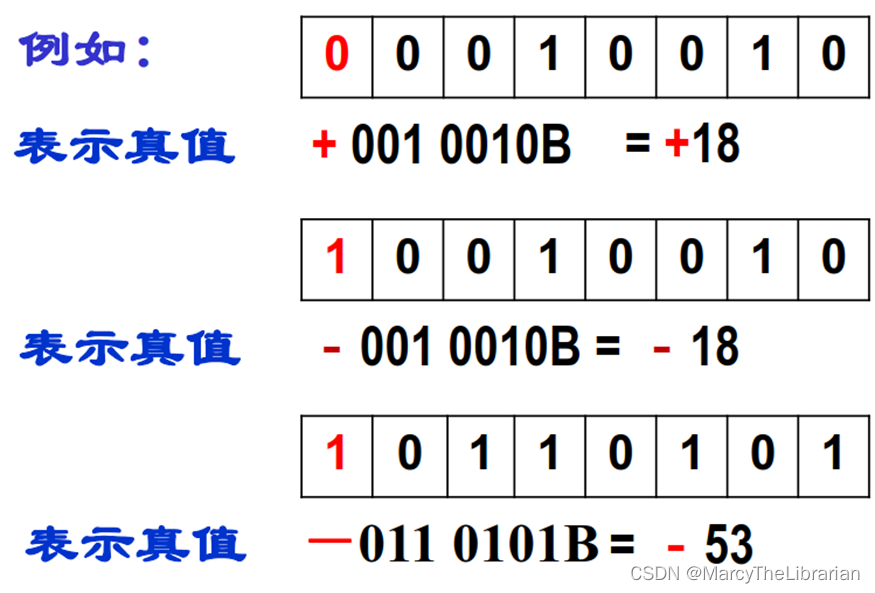
原码、反码、补码
原码:符号位 绝对值
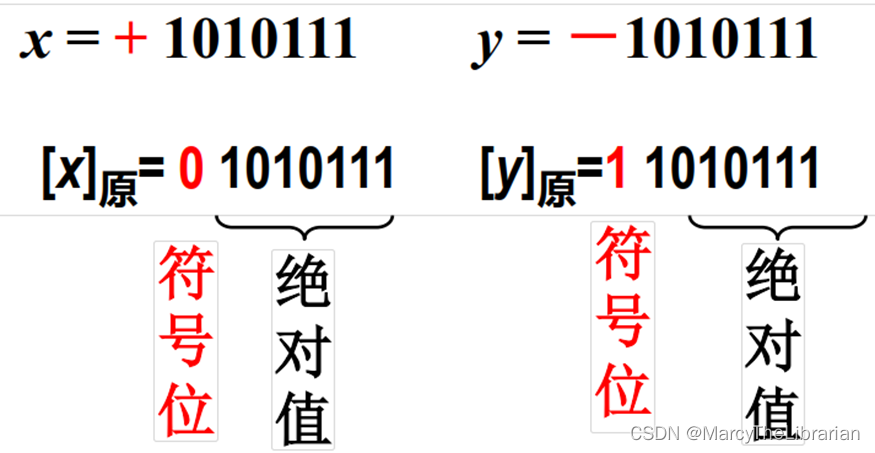
反码:
正数的反码:与其原码相同。
负数的反码为:其原码中符号位不变,其余各位取反。
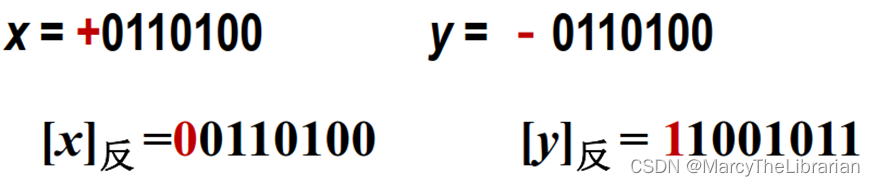
补码
正数的补码与其原码相同。(正数的原码、反码、补码均相同)
负数的补码为:其反码的最低位加1。
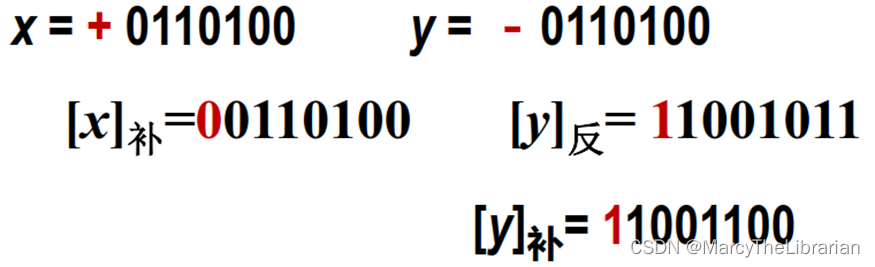
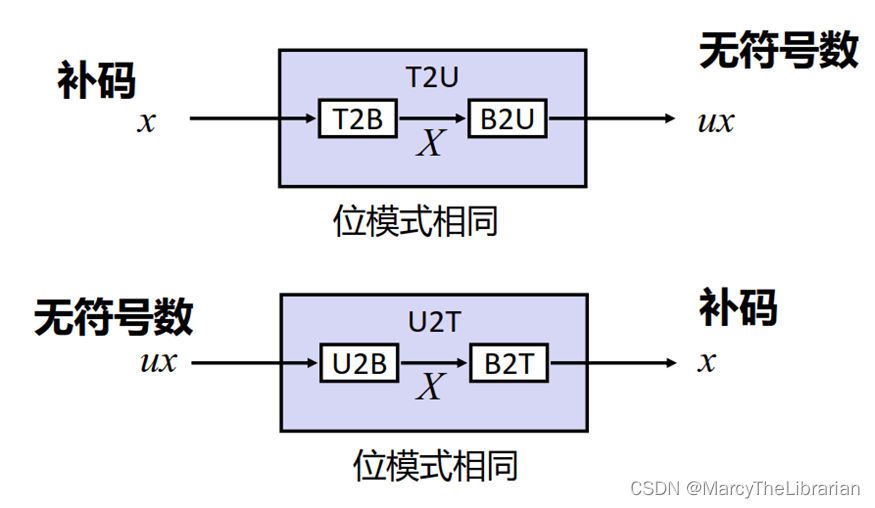
无符号数和有符号数的转换
规则:位模式不变、数值可能改变**(按不同编码规则重新解读)**
- C语言中的有符号数和无符号数
常量:数字默认是有符号数、无符号数用后缀“U”:0U, 4294967259U
类型转换:
-
显示的强制类型转换
int tx, ty;
unsigned ux, uy;
tx = (int) ux;
uy = (unsigned) ty; -
隐式的类型转换(赋值、函数调用等情况下发生)
tx = ux;
uy = ty;
- 表达式计算
- 表达式中有符号和无符号数混用时:有符号数隐式转换为无符号数
- 包括比较运算符<, >, ==, <=, >=
- 注意下面的第3、5、7、9行
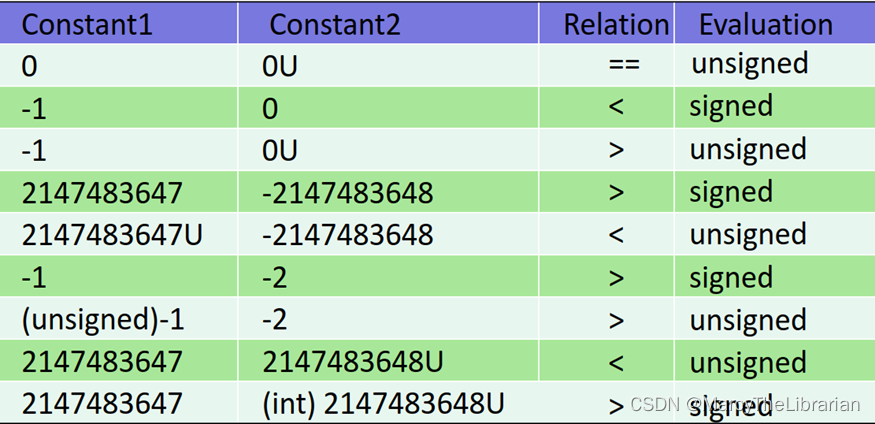
- C语言中的整数(注意带星的)
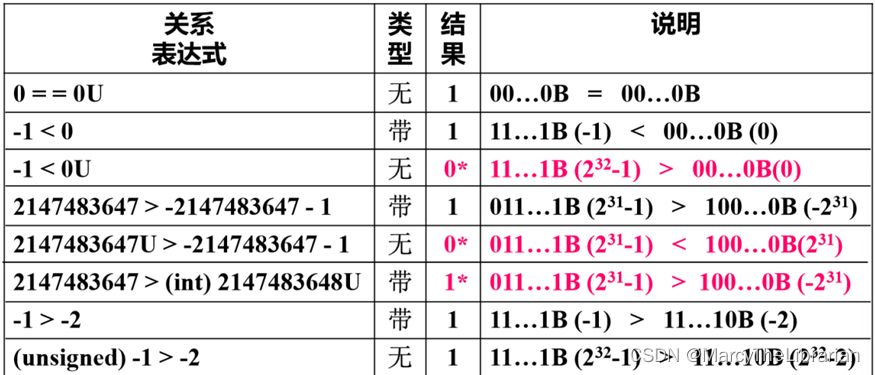
- 有符号数和无符号数转换的基本原则
位模式不变
重新解读(按目标编码类型的规则解读)
会有意外副作用: 数值被 + 或 − 2 w -2^w −2w
扩展、截断
-
符号扩展
给定w位的有符号整型数x,将其转换为w+k位的相同数值的整型数
规则:
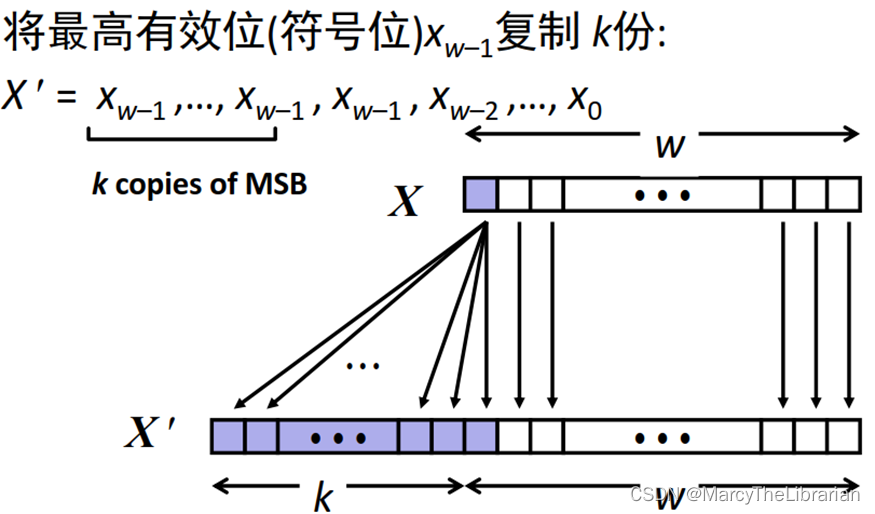
符号扩展示例

-
总结:扩展、截断的基本规则
| 扩展 | 截断 |
|---|---|
| 从short int 到int的转换 | 从unsigned 到unsigned short的转换 |
| 无符号数: 填充0 有符号数:符号扩展 结果都是明确的预期值 | 无论有/无符号数: 多出的位均被截断 结果重新解读 无符号数: 相当于求模运算 有符号数: 与求模运算相似 对于小整数,结果是明确的预期值 |
整数运算:加、非、乘、移位
-
无符号数加法
标准加法:忽略进位输出
模数加法:相当于增加一个模运算
s = U A d d w ( x , y ) = ( x + y ) m o d 2 w s = UAdd_w(x , y) = (x + y)\mod2^w s=UAddw(x,y)=(x+y)mod2w𝑈 𝐴 𝑑 𝑑 𝑤 ( x , y ) = { 𝑥 + 𝑦 , 𝑥 + 𝑦 < 2 𝑤 𝑥 + 𝑦 − 2 𝑤 , 𝑥 + 𝑦 ≥ 2 𝑤 𝑈𝐴𝑑𝑑_𝑤 (x, y) = \begin{cases} {𝑥 + 𝑦 ,𝑥 + 𝑦 < 2^𝑤}\\ {𝑥 + 𝑦 − 2^𝑤 ,𝑥 + 𝑦 ≥ 2^𝑤} \end{cases} UAddw(x,y)={x+y,x+y<2wx+y−2w,x+y≥2w
-
补码加法
T A d d ( x , y ) = { x + y − 2 w , T M a x w < x + y x + y , T M i n x ≤ x + y ≤ T M a x w x + y + 2 w , x + y < T M i n w TAdd(x,y)=\begin{cases} {x+y-2^w,TMax_w<x+y}\\ x+y,TMin_x \leq x+y \leq TMax_w\\ x+y+2^w,x+y<TMin_w \end{cases} TAdd(x,y)=⎩ ⎨ ⎧x+y−2w,TMaxw<x+yx+y,TMinx≤x+y≤TMaxwx+y+2w,x+y<TMinw -
乘法
乘积的精确结果可能超过w 位
-
无符号数乘法
U M u l t w ( x , y ) = x ⋅ y m o d 2 w UMult_w(x , y) = x ·y \mod 2^w UMultw(x,y)=x⋅ymod2w -
有符号数乘法
丢弃w 位: 保留低w 位 -
用移位实现“乘以2的幂”
无论有符号数还是无符号数:
u < < k 可得到 u ∗ 2 k u << k \space可得到\space u*2^k u<<k 可得到 u∗2k -
用移位实现无符号数“除以2的幂”(逻辑右移)
u > > k 得到 u / 2 k 的向下取整 u >> k\space得到\space u / 2^k \space的向下取整 u>>k 得到 u/2k 的向下取整
-
内存、指针、字符串表示
程序用地址来引用内存中的数据:
内存可看做巨大的“字节数组”、地址就像这个“字节数组”的索引
操作系统为每个进程提供私有的地址空间
每个进程可访问自己地址空间中的内存数据,彼此不干扰。
Ⅱ:浮点数
二进制小数
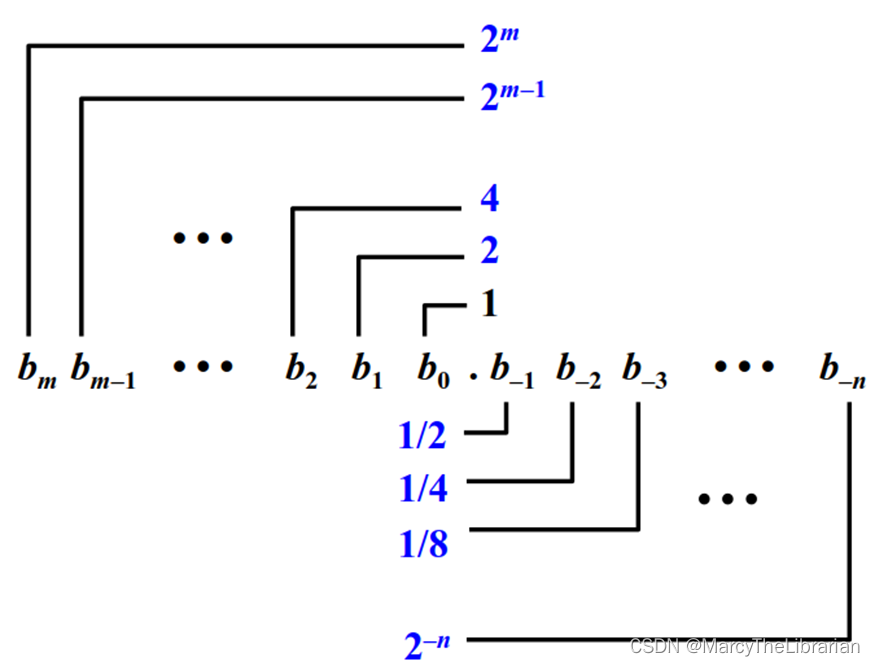
表示的有理数:
∑
i
=
−
n
𝑚
𝑏
𝑖
×
2
𝑖
\sum^𝑚_{i=-n} 𝑏_𝑖 × 2^𝑖
i=−n∑mbi×2i
只能精确表示形如 x/{2^k}的数值,其他有理数的二进制表示存在重复段
IEEE 浮点数标准: IEEE 754
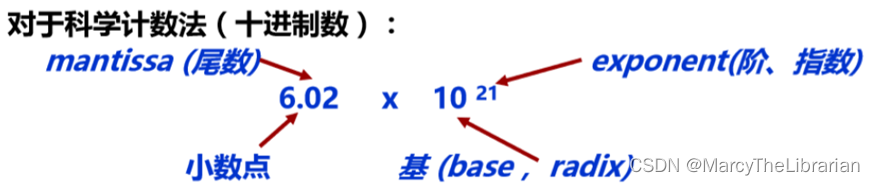

规格化数
规格化数的形式
+
/
−
1.
S
i
g
n
i
f
i
c
a
n
d
×
R
E
x
p
o
n
e
n
t
+/-1.Significand × R^{Exponent}
+/−1.Significand×RExponent
32-bit规格化数
| S(1 bit) | Exponent(? bit) | Significand(? bit) |
|---|---|---|
| 符号位 | 译码(增码、阶码) | 部分尾数 |
| 精度选项 | bits |
|---|---|
| 单精度 | 32 bits(1+8+23) |
| 双精度 | 64 bits(1+11+52) |
| 扩展精度 | 80 bits(1+15+63/64) |
阶码(Exp) 采用偏置值编码,阶码的值(阶):
E
=
E
x
p
–
B
i
a
s
E
x
p
:
E
x
p
o
n
e
n
t
字段的编码(无符号数)
B
i
a
s
:偏置
=
2
k
−
1
−
1
k
为阶码的位数
E = Exp – Bias\\ Exp: Exponent 字段的编码(无符号数)\\ Bias:偏置 = 2^{k-1} - 1\\ k 为阶码的位数
E=Exp–BiasExp:Exponent字段的编码(无符号数)Bias:偏置=2k−1−1k为阶码的位数
单精度 : 127 ( E x p : 1 … 254 , E : − 126 … 127 ) 双精度 : 1023 ( E x p : 1 … 2046 , E : − 1022 … 1023 ) 单精度: 127 (Exp: 1…254, E: -126…127)\\ 双精度: 1023 (Exp: 1…2046, E: -1022…1023) 单精度:127(Exp:1…254,E:−126…127)双精度:1023(Exp:1…2046,E:−1022…1023)
尾数(Significand) 编码隐含先导数值1:
M
=
1.
x
x
x
…
x
2
x
x
x
…
x
:
是
f
r
a
c
字段的数码
f
r
a
c
=
000
…
0
(
M
=
1.0
)
时,为最小值
f
r
a
c
=
111
…
1
(
M
=
2.0
–
ε
)
时,为最大值
额外增加了一位的精度(隐含值
1
)
M = 1.xxx…x_2\\ xxx…x: 是 frac字段的数码\\ frac=000…0 (M = 1.0)时,为最小值\\ frac=111…1 (M = 2.0 – ε)时,为最大值\\ 额外增加了一位的精度(隐含值1)
M=1.xxx…x2xxx…x:是frac字段的数码frac=000…0(M=1.0)时,为最小值frac=111…1(M=2.0–ε)时,为最大值额外增加了一位的精度(隐含值1)
规格化编码示例
1521
3
10
=
1.110110110110
1
2
∗
2
13
尾数
(
S
i
g
n
i
f
i
c
a
n
d
)
:
M
=
1.110110110110
1
2
f
r
a
c
=
1101101101101000000000
0
2
阶码
(
E
x
p
o
n
e
n
t
)
E
=
13
=
E
x
p
−
B
i
a
s
B
i
a
s
=
127
E
x
p
=
140
=
1000110
0
2
编码结果
:
0
10001100
11011011011010000000000
15213_{10} = 1.1101101101101_2 * 2^{13}\\ 尾数(Significand):\\ M = 1.1101101101101_2\\ frac = 11011011011010000000000_2\\ 阶码(Exponent)\\ E = 13 =Exp-Bias\\ Bias = 127\\ Exp = 140 = 10001100_2\\ 编码结果:\\ 0\space 10001100\space 11011011011010000000000
1521310=1.11011011011012∗213尾数(Significand):M=1.11011011011012frac=110110110110100000000002阶码(Exponent)E=13=Exp−BiasBias=127Exp=140=100011002编码结果:0 10001100 11011011011010000000000
试求:
1 0111101 110000000000000000 的十进制:0.4375
-12.75 的机器数: 1 10000010 100110000000000000000000
非规格化数
v = ( – 1 ) s ∗ M ∗ 2 E 阶码 ( E x p ) 的值 : E = 1 – B i a s ( i n s t e a d o f E = 0 – B i a s ) 尾数 ( S i g n i f i c a n d ) 编码隐含先导数值 0 : M = 0. x x x … x 2 v = (–1)^s *M* 2^E\\ 阶码(Exp)的值: E = 1 – Bias (instead\space of\space E = 0 – Bias)\\ 尾数(Significand)编码隐含先导数值0: M = 0.xxx…x_2 v=(–1)s∗M∗2E阶码(Exp)的值:E=1–Bias(instead of E=0–Bias)尾数(Significand)编码隐含先导数值0:M=0.xxx…x2
特殊值
e x p = 111 … 1 , f r a c = 000 … 0 表示无穷 ( i n f i n i t y ) 、溢出的运算 正无穷 : 0 111111111 000 … 0 负无穷 : 1 111111111 000 … 0 exp= 111…1, frac= 000…0\\ 表示 无穷(infinity) 、溢出的运算\\ 正无穷:0\space 111111111\space 000…0\\ 负无穷:1\space 111111111\space 000…0\\ exp=111…1,frac=000…0表示无穷(infinity)、溢出的运算正无穷:0 111111111 000…0负无穷:1 111111111 000…0
e x p = 111 … 1 , f r a c ≠ 000 … 0 表示:不是一个数 N o t − a − N u m b e r ( N a N ) 表示没有数值结果,例如 : s q r t ( – 1 ) , ∞ − ∞ , ∞ ∗ 0 exp= 111…1, frac≠ 000…0\\ 表示:不是一个数Not-a-Number (NaN)\\ 表示没有数值结果,例如:sqrt(–1), \infty− \infty, \infty*0 exp=111…1,frac=000…0表示:不是一个数Not−a−Number(NaN)表示没有数值结果,例如:sqrt(–1),∞−∞,∞∗0
当输入数据是一个不可表示数时,机器将其转换位最邻近的可表示数。
舍入模式
向偶数舍入(默认的舍入模式)
其他方法都有统计偏差——对正整数集合求和时,和将始终被低估或高估(负偏差、正偏差)
当恰好在两个可能的数值正中间时(中间值时):舍入后,最低有效位的数码为偶数
其他时候:向最近的数值舍入,比中间值小向下舍入,比中间值大向上舍入
10进制数向最近的百分位舍入为例:
7.8949999 ==> 7.89 (比中间值小:向下舍入)
7.8950001 ==> 7.90 (比中间值大:向上舍入)
7.8950000 ==> 7.90 (中间值—向上舍入)
7.8850000 ==> 7.88 (中间值—向下舍入)
二进制数的舍入
偶数 : 最低有效位值为 0 中间值 : 舍入位置右侧的位都是 0 ,即形如 : x x x 100 … 2 偶数:最低有效位值为0\\ 中间值:舍入位置右侧的位都是0,即形如: xxx\space 100…_2 偶数:最低有效位值为0中间值:舍入位置右侧的位都是0,即形如:xxx 100…2
浮点数运算
基本思想
首先,计算精确结果;然后,变换到指定格式
阶码(Exp) 太大可能溢出,小数部分可能需要舍入
浮点乘法

浮点数加法

C语言的浮点数
从int转换为float,不会发生溢出,但有可能舍入
从int或float转换为double时,能保留精确值
从double转换为float和int时,可能发生溢出,也有可能舍入
从float或double转换为int时,因为int没有小数部分,所以数据可能会向0方向截断
i
n
t
x
=
…
;
f
l
o
a
t
f
=
…
;
d
o
u
b
l
e
d
=
…
;
int\space x = …;\\ float\space f = …;\\ double\space d = …;\\
int x=…;float f=…;double d=…;
| 表达式 | 判断Y/N |
|---|---|
| x == (int)(float) x | No: 24 位尾数 |
| x == (int)(double) x | Yes: 53位尾数 |
| f == (float)(double) f | Yes: 增加精度 |
| d == (float) d | No: 损失精度 |
| f == -(-f); | Yes: 仅仅改变符号位 |
| 2/3 == 2/3.0 | No: 2/3 == 0 |
| d < 0.0 => ((d*2) < 0.0) | Yes! 单调 |
| d > f => -f < -d | Yes 对称 |
| d *d >= 0.0 | Yes! |
| (d+f)-d == f | No: 不具备结合性 |















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









