







写在前面:本文是当初老师画完重点后从零看书自学的笔记,语言基本是自己的理解,可能不够严谨,建议配合原书看,佛系党用来渡劫问题不大。
关于考试:都是主观题,一题15分好像,老师原话是没有标准答案,只要理解到位就行。所以使劲写想到啥写啥就给分,我当初考完觉得挺差劲的,最后考了97分,也有同学平时听课考前背了很久觉得写的很好然后成绩不高。
PS:去年我们考试最后一题老师划重点没有划到,所以你们信不信重点,看你们咯
第一章 计算机系统漫游
基本概念
-
字:一串数码作为一个整体来处理或运算的,称为一个计算机字,简称字。(课本没找到定义,老师说就是一个word,16位)
-
字长:指的是CPU一次能并行处理的二进制位数,字长总是8的整数倍(wordsize,32位、64位操作系统指的就这个)
-
POSIX:可移植操作系统接口(英语:Portable Operating System Interface,缩写为POSIX)是IEEE为要在各种UNIX操作系统上运行软件,而定义API的一系列互相关联的标准的总称
课本上:IEEE为了标准化Unix的开发,建立了一系列标准,称为POSIX标准
-
并发:一个同时具有多个活动的系统(?)
-
并行:用并发来使一个系统运行的更快(?和os讲的不一样)
-
SMT:超线程,也叫同时多线程,是一项允许一个CPU控制多个控制流的技术
-
SIMD:允许一条指令产生多个可以并行执行的操作,这种方式成为单指令、多数据,即SIMD并行
1.2 编译系统
hello.c 文本文件,以字节序列方式储存,每个字节对应一个ASCII编码
hello.i 经预处理器的预处理阶段,将.c文件开头的#include。。弄进来,新的C程序
hello.s 编译器——编译阶段 文本文件,包含汇编语言程序,该程序包含main的汇编定义
hello.o 汇编器——汇编阶段 机器语言(二进制代码)指令,指令打包在可重定位目标程序,保存在可重定位目标文件
链接阶段 .o文件合并——>可执行目标文件
1.4.2 运行hello程序
想课本图
- 从键盘读取hello命令 键盘——USB控制器——I/O桥——总线接口——寄存器——I/O桥——主存
- 从磁盘加载可执行文件到主存 (敲回车后要执行啦)
- 将输出字符串从主存写到显示器 1步骤倒过来最后I/O桥通过I/O总线指向图形适配器
主存与外设传递信息要通过CPU寄存器
1.6 存储设备层次结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J6STxPeF-1608430770084)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201216085945215.png)]](https://i-blog.csdnimg.cn/blog_migrate/a3ef66ad87719e299d9b2db3183474c4.png)
主要思想:上一层的存储器作为低一层存储器的高速缓存
1.7.3 虚拟内存
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bXN2xO3F-1608430770087)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201216090021649.png)]](https://i-blog.csdnimg.cn/blog_migrate/b84525a4372a9bbf872909f8adccd5f8.png)
制造假象:每个进程都在独立使用内存
看第七章
1.9.1 Amdahl定律
了解加速比公式
按照比例 α \alpha α对 某个部分求出时间占比: α T old \alpha T_{\text {old }} αTold ,根据比例 k k k对该部分进行加速
T new = ( 1 − α ) T old + ( α T old ) / k = T old [ ( 1 − α ) + α / k ] T_{\text {new }}=(1-\alpha) T_{\text {old }}+\left(\alpha T_{\text {old }}\right) / k=T_{\text {old }}[(1-\alpha)+\alpha / k] Tnew =(1−α)Told +(αTold )/k=Told [(1−α)+α/k]
S = 1 ( 1 − α ) + α / k S=\frac{1}{(1-\alpha)+\alpha / k} S=(1−α)+α/k1
要想显著加快整个系统,必须提升全系统相当大部分的速度
第二章 信息表示和处理
基本概念
字长(Word Size)、Unicode、UTF-8、
- Unicode 是「字符集」,•unicode是国际通用编码
- UTF-8 是「编码规则」UTF-8 顾名思义,是一套以 8 位为一个编码单位的可变长编码
算术右移 原码补0,补码补符号位
逻辑右移 补零
IEEE 754标准
2.1.3 大端小端
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7SaWQ83I-1608430770089)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201216092440520.png)]](https://i-blog.csdnimg.cn/blog_migrate/b7362cd000f62f0ea79dc34a68b75b8f.png)
2.2 整数表示
课本又臭又长,看不下去了我赌它不考

2.4 浮点数
小数转二进制
举例:22.8125 转二进制的计算过程:
整数部分:除以2,商继续除以2,得到0为止,将余数逆序排列。
22 / 2 11 余0
11/2 5 余 1
5 /2 2 余 1
2 /2 1 余 0
1 /2 0 余 1
得到22的二进制是10110
小数部分:乘以2,取整,小数部分继续乘以2,取整,得到小数部分0为止,将整数顺序排列。
0.8125x2=1.625 取整1,小数部分是0.625
0.625x2=1.25 取整1,小数部分是0.25
0.25x2=0.5 取整0,小数部分是0.5
0.5x2=1.0 取整1,小数部分是0,
得到0.8125的二进制是0.1101
结果:十进制22.8125等于二进制00010110.1101
浮点表示
IEEE754标准包含一组实数的二进制表示法。它有三部分组成:
- 符号位
- 指数位(阶码)
- 尾数位
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-97ycebmy-1608430770099)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201216102719710.png)]](https://i-blog.csdnimg.cn/blog_migrate/721b66b502c76231ac3bebcd5e17cfb9.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9VeRKNyi-1608430770102)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201216103025949.png)]](https://i-blog.csdnimg.cn/blog_migrate/4cd4133a05ad851787e834a181cdce3f.png)
第三章 程序的机器级表示

数据格式
bwlq 分别代表1248字节
Intel用字word表示16位数据类型
通用目的寄存器
指令以寄存器为目标,结果小于八字节,寄存器剩下字节的处理:2种
生成的是1、2字节大小的则目的寄存器其他位不变,若生成4字节指令将目的寄存器高位置零
操作数指示符
p121那个图
mov
第一个源操作数 复制到第二个目的操作数
较小源复制到较大目的:
MOVZ零拓展,
MOVS符号拓展(源操作最高位进行复制)
练习3.2 3.3
栈
栈向下增长
栈指针存的是栈顶元素的地址
一个指令代表俩汇编(push需要 1.指针-8 2.mov值
加载有效地址
leaq 将有效地址写入目的操作数
简洁地描述普通的算数操作
后面的过程调用参数有&xx的时候会用到,感受一波,看下课本
一元和二元操作数
练习3.8 (%rax)在二元操作当目的数时,地址为%rax存的值,然后结果存在在地址对应的内存值里
%rax目的地址就是%rax,数存在寄存器里
移位
移位量要么立即数,要么 单字节寄存器%c1,移多少位,看要移动的数有几位。
128位算术操作
乘法的时候一个操作数放在寄存器%rax里,另一个作为指令源操作数给出,结果高位放在%rdx,低位放在%rax
看那几个例题
条件码
leaq指令不改变,算术指令改变
CMP,TEST只设置条件码但不改变其他寄存器
条件码的使用:
- 根据条件码的某种组合将一个字节设置为0或者1 set的使用
- 条件跳转到程序的某个其他部分
- 有条件的传送数据
访问条件码
g(greater)? l(less)是对有符号数
seta,setb对无符号数
先cmp或者test
再set 满足条件就set
跳转
test判断数是否为0,jmp后面的g、l等代表是大于0还是小于0
条件控制
条件传送实现条件分支:
在这种情况下,指令流水线不会因为分支指令错误预测造成严重惩罚
使用数据的条件转移,计算一个条件操作的两种结果,根据条件从中选择一个
循环
-
do-while
-
while:
第一种方法:jump to middle
核心:if(t) 先跳转到test,如果满足条件就loop
每次loop完都会再test一次
goto test loop: body-statement test: t = test-expr if(t) goto loop第二种方法: guarded-do
核心:if(!t) 先检查,如果不满足条件,直接goto done,否则do-while
和do-while区别在于,需要先检查一次test
t=test-expr if(!t) goto done do body-statement while(t)//这里do-while还可以再翻译成goto代码 done -
for
和while区别就是多了个init,while里面多了个update
init-expr while(test-expr){ body-statement update-expr } -
switch
定义一个指针数组,数组每个元素都是指向一个代码块的地址(&&daimakuai)的指针
通过n与case的取值的差值关系,作为数组的索引-index,取相应的数组元素(也就是代码块地址)
如果index越界指向default,否则,goto 数组[index]
3.7 过程
传递控制
在进入过程Q的时候,程序计数器必须被设置为Q的代码的起始地址,然后在返回时,要把程序计数器设置为p中调用Q后面那条指令的地址。
传递数据
P必须能够向Q提供一个或多个参数,Q必须能够向p返回一个值。
分配和释放内存
在开始时,Q可能需要为局部变量分配空间,而在返回前,又必须释放这些存储空间
3.7.1 运行时栈
Q栈帧:Q的代码可以保存寄存器的值,分配局部变量空间
P中定义的变量要放在P的栈帧里。如果调用Q,把这些值再复制到寄存器中。
P最多传递六个整数值,如果多了,可以在调用Q之前把参数放在自己的栈帧里
3.7.2 转移控制
callQ 把返回地址(P调用Q后面的那条指令的地址)压入栈中,把PC设置为Q的起始地址
ret 弹出A,PC设为A
3.7.3 数据传送
P调用Q时,P的代码要把参数复制到适当的寄存器,多于6个放在自己栈帧里
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L7CIVesm-1608430770103)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201215204855770.png)]](https://i-blog.csdnimg.cn/blog_migrate/4f7cebf5f40646c0bf64edd12da890c8.png)
3.7.4 栈上的局部存储
对一个局部变量使用&,必须为它产生一个地址,当P调用Q传递参数的时候,使用leaq语句,传递的是%rsp代表的地址
3.7.5 寄存器中的局部存储空间
确保:调用者调用被调用者时,被调用者不回覆盖稍后调用者会使用的寄存器
被调用者保护寄存器,%rbx,%rbp,%r12~15, 实现方法:要么不去改变那个寄存器,要么把原始值压入栈中,改变寄存器,最后弹出原始值。
调用者保护寄存器
一些基本概念
&a 给出该对象地址的一个指针 *a给出该地址的值,a和 *&a是等价的
ISA
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-btQTdfFi-1608430770104)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201215215714691.png)]](https://i-blog.csdnimg.cn/blog_migrate/85ff9fe8d8a719f89842fcb3ef4ccc84.png)
结构
struct声明一个数据结构,将可能不同类型的对象聚合到一个对象中
指向结构的指针是结构第一个字节的地址。
联合
联合表示几个变量公用一个内存位置, 在不同的时间保存不同的数据类型
和不同长度的变量。
对于联合的不同成员赋值, 将会对其它成员重写, 原来成员的值就不存
在了, 而对于结构的不同成员赋值是互不影响的。
对齐
要求某种类型对象的地址必须是某个值K的倍数
强制对齐
缓冲区溢出
在栈中分配某个字符数组来保存一个字符串,但是字符串的长度超出了为数组分配的空间
MMX、SSE、AVX
P204
第四章 流水线CA 附录C.1 和C.2
什么是流水线
流水线是一种将多条指令 重叠执行的实现技术,利用了操作之间的并行性。一个时钟周期,可以执行多条指令的不同操作。
吞吐率:单位时间内流水线所完成的任务数量或输出结果的数量 1/▲t
加速比:使用顺序处理方式处理一批任务所用的时间与按流水处理方式处理同一 批任务所用的时间之比
效率:即流水线设备的利用率,指流水线中的设备实际使用时间与整个运行时间的比值
CPI:每条指令时钟周期数
流水化处理器理想CPI为1
RISC指令集简单实现
IF,ID,EX,MEM,WB
经典五级流水线
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zJi3ikdM-1608430770105)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201214193518974.png)]](https://i-blog.csdnimg.cn/blog_migrate/b9a06c6937c72aa38ae9deb535d6d93e.png)
各有所需,互不干扰
1.主要功能单位在一个时钟周期内是不同的,多条指令的重叠执行不会造成硬件资源的冲突
2.不同流水级中的指令不会相互干扰:
引入流水线寄存器,每一个时钟周期的输入输出都由流水线寄存器实现
流水线冒险
冒险:会阻止指令流的下一条指令在其自己的指定时钟周期内执行,降低流水线能获得的理想加速比
1.结构冒险:
重叠执行过程中,出现资源冲突,不能容许某些指令组合。比如IF和MEM阶段同时访存
2.数据冒险:
流水线各级指令因为重叠操作,可能改变对操作数的读写访问顺序,
当一条指令取决于先前指令的结果,可能导致数据冒险。
- 转发
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vx65eVdQ-1608430770106)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201214202210560.png)]](https://i-blog.csdnimg.cn/blog_migrate/108b8f14d26ef49b4413b270962c8d82.png)
转发的推广,可以将一个功能单元输出到寄存器的结果直接转发到另外一个功能单元的输入
-
需要停顿的数据冒险
当转发路径需要进行时间上的回退(也就是还没生产出来的数下级指令就要用了),增加 流水线互锁,检测冒险,使流水线停顿
3.控制冒险:
分支指令及其他改变程序计数器的指令实现流水化时可能导致控制冒险
分支将程序计数器改为其目标地址,就是选中分支,否则未选中分支
冻结或冲刷流水线
预测未选中
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n7XSEOoV-1608430770107)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201215092401317.png)]](https://i-blog.csdnimg.cn/blog_migrate/443975a148c99c85e04880f154b4a35c.png)
预测选中
延迟分支
无论该分支是否被选中,依序后续指令都会执行
编译器的任务是让后续指令有效并且可用
C-8
来自分支之前,来自分支目标,来自未选中命令
经过这个改进,我们在分支那不是会有延时么
b执行的是选中后的下一条,c执行的是未选中的下一条

流水线加速比
C2.1P479
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NEIoZvvq-1608430770108)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201215094340413.png)]](https://i-blog.csdnimg.cn/blog_migrate/fdb43abc6d737b1ba0d878330f34d1e3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fkrn1Hv4-1608430770109)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201215093110600.png)]](https://i-blog.csdnimg.cn/blog_migrate/11cc8a361f82bc40d8639eea97861d21.png)
通过预测降低分支成本
动态分支预测和分支预测缓冲区
建立一个分支预测缓冲区,采用2位预测机制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bbbMCcte-1608430770110)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201215093950146.png)]](https://i-blog.csdnimg.cn/blog_migrate/3917d6063dea031892863e93da6c8a48.png)
第五章 优化程序性能
优化编译器的能力和局限性
安全的优化
内存别名使用:两个指针被指向同一个内存位置
count++,在f()调用,然后调用f()+f()+f()和3*f()结果是不一样的
5.4 消除循环的低效率
代码移动:识别要执行多次,但是结果不会改变的计算。将该计算移到循环外部。
5.5 减少过程调用
每次循环都要调用一个函数,这个函数可以通过一些方法消除。
5.6 消除不必要内存引用
比如循环里的指针运算,都要把指针指向的内存的数据取出来再运算再写回去,可以直接定义一个值存在寄存器里。循环结束再赋值给指针。
5.8 循环展开
增加每次迭代计算的元素的数量,减少循环的迭代次数(比如本来是i++,改成i+=2)
C3.2
P134页例题的停顿:
冯涵 11:04:45
你比如说第一步LD
冯涵 11:05:00
他下面的ADD是不是得用到F0
冯涵 11:05:18
而LD指令这时候肯定没load完,就停顿了
循环展开后,删除每次迭代都要的指针递减和判断循环终止。
看P135例题
第六章 存储器层次结构
6.1 存储技术
随机访问存储器(Random-Access Memory, RAM)分两类:
- 静态的:SRAM,高速缓存存储器,既可以在CPU,也可以在片下。
- 动态的:DRAM,用于主存或者图形系统帧缓冲区。
通常情况下,SRAM的容量都不会太大,而相比之下DRAM容量可以大得离谱。
静态RAM
SRAM将每个位存储在一个双稳态存储器单元里,每个单元用一个六晶体管电路实现。
这种电路有一个属性,它可以无限期地保持两个不同的状态的其中一个,其他状态都是不稳定的
因为它的双稳态特性,即使有干扰,等到干扰消除,电路就能恢复成稳定值。
只要有电,它就会永远的保持它的值
动态RAM
DRAM的每个存储是一个电容和访问晶体管组成,每次存储相当于对电容充电。
因为每个存储单元比较简单,DRAM可以造的非常密集。但它对干扰非常敏感,被干扰后不会恢复。
因此它必须周期性地读出重写来刷新内存的每一位。或者使用纠错码来纠正任何单个错误
传统的DRAM:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MXxQViAn-1608430770111)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201218204030717.png)]](https://i-blog.csdnimg.cn/blog_migrate/118686f994e6eba4e3aa480120573258.png)
DIMM
DRAM芯片疯狂在内存模块,DIMM:双列直插内存模块
以64位为块传送数据到内存控制器和从内存控制器传入数据
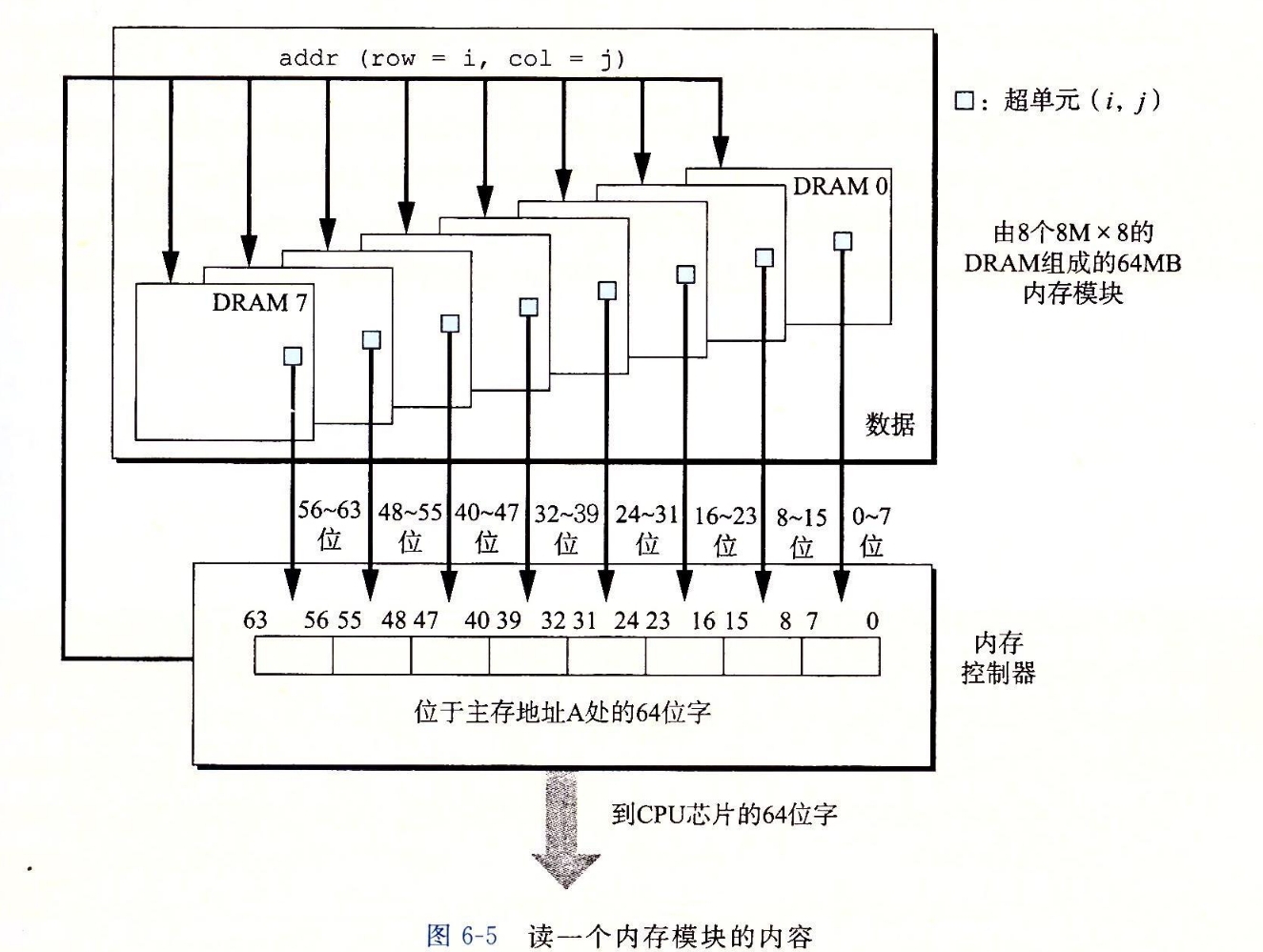
同步DRAM(SDRAM)
传统的DRAM是异步传输地址的(内存控制器先发送行地址让行内容复制到行缓冲区,再发送列地址)。而这个利用一些技术达成了同步传输地址,它能比传统的异步存储器更快地输出单元信息。
双倍数据速率同步DRAM(DDR SDRAM)
对SDRAM的一种增强,能使DRAM速度翻倍
非易失性存储器ROM
如果断电,DRAM和SRAM会丢失它们的信息,他们属于易失性存储器。
因此,非易失性存储器就是关电之后仍然保存它们的信息。他们统称只读存储器Read−only Memory ,ROMRead−only Memory ,ROM 。
它们是以能够被重编程的次数和重编程的机制来区分的。
- PROM( Programmable ROM )( Programmable ROM ) 可编程ROM:只能被编程一次,PROM的每个存储器单元有一种熔丝,只能用高电流熔断一次。
- 可擦写可编程ROM(Erasable Programmable ROM, EPROM(Erasable Programmable ROM, EPROM) :可反复擦写编程1000次以上。
- 电子可擦除PROM(Electrically Erasable PROM, EEPROM)(Electrically Erasable PROM, EEPROM) :可擦写编程的数量级为105105 次。
- 闪存(flash memory)(flash memory) :非易失性存储器,基于EEPROM。
USB
通用串行总线,连接各种外围I/O设备
固态硬盘(Solid State Disk, SSD)读写原理
SSD是一种基于闪存的存储技术。一个SSD封装一个或者多个闪存芯片和闪存翻译层
- 一个闪存由B个块组成
- 一个块由P个页组成
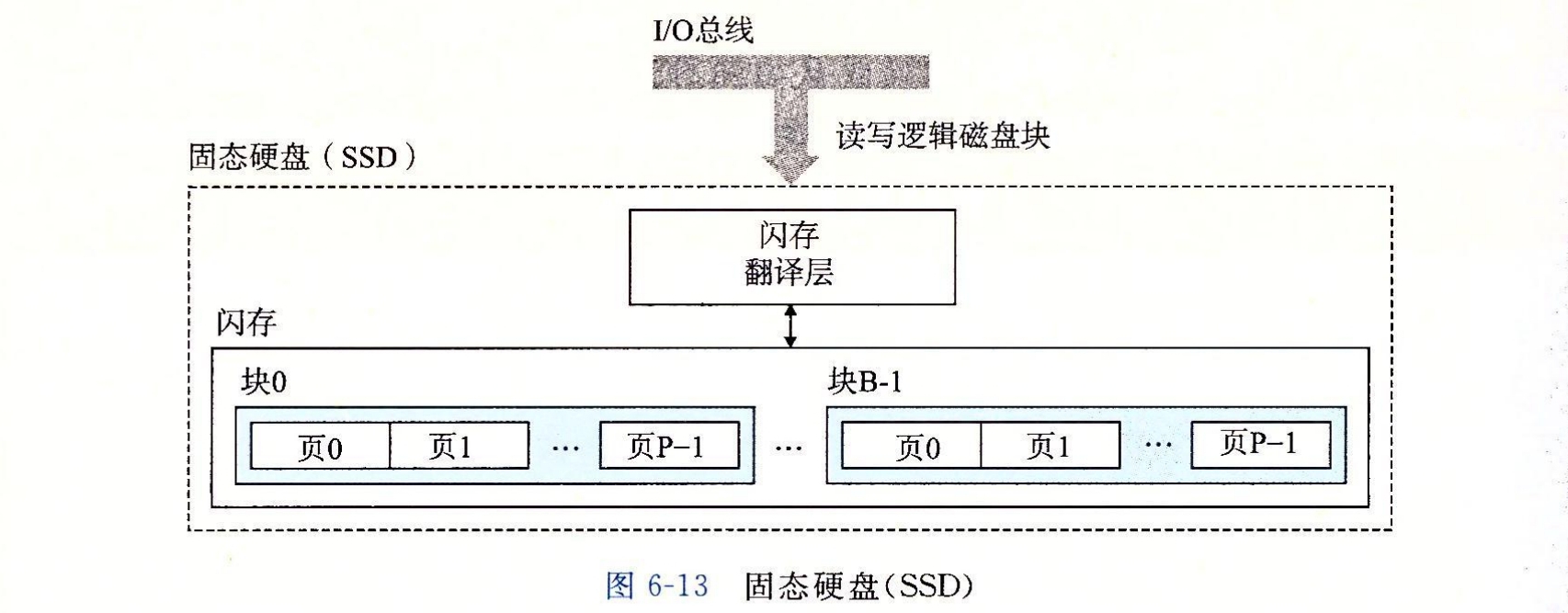
数据是以页为读写基本单位,只有在一个块被擦除之后,才能写其中一页。不过一旦块被擦除,块中的每一个页都不用再擦除。
随机写的速度明显比随机读要慢。原因是:
- 擦除块要很久,1ms级。
- 如果写入的页已经有有用的数据在块中的其他页中,则需要先将块中的数据复制到别的块,再对进行擦写。
6.2 局部性
一种更喜欢引用最近引用过的数据项,或者邻近其他最近引用过的数据项的数据项,的倾向性,被称为局部性原理。
局部性通常由两种不同的形式:
- **时间局部性:**被引用过一次的数据很可能在不远的将来再次被引用
- **空间局部性:**被引用过一次的数据很可能在不远的将来引用其附近的数据
有良好局部性的程序比局部性差的程序运行的更快。
局部性小结
- 重复引用相同变量的程序具有良好的时间局部性。
- 对于具有k步的引用模式的程序,步长越小,空间局部性越好。反之越差。
- 对于取指令来说,循环体越小,迭代次数越多,其空间局部性和时间局部性越好
6.3 存储器层次结构
6.4 高速缓存存储器
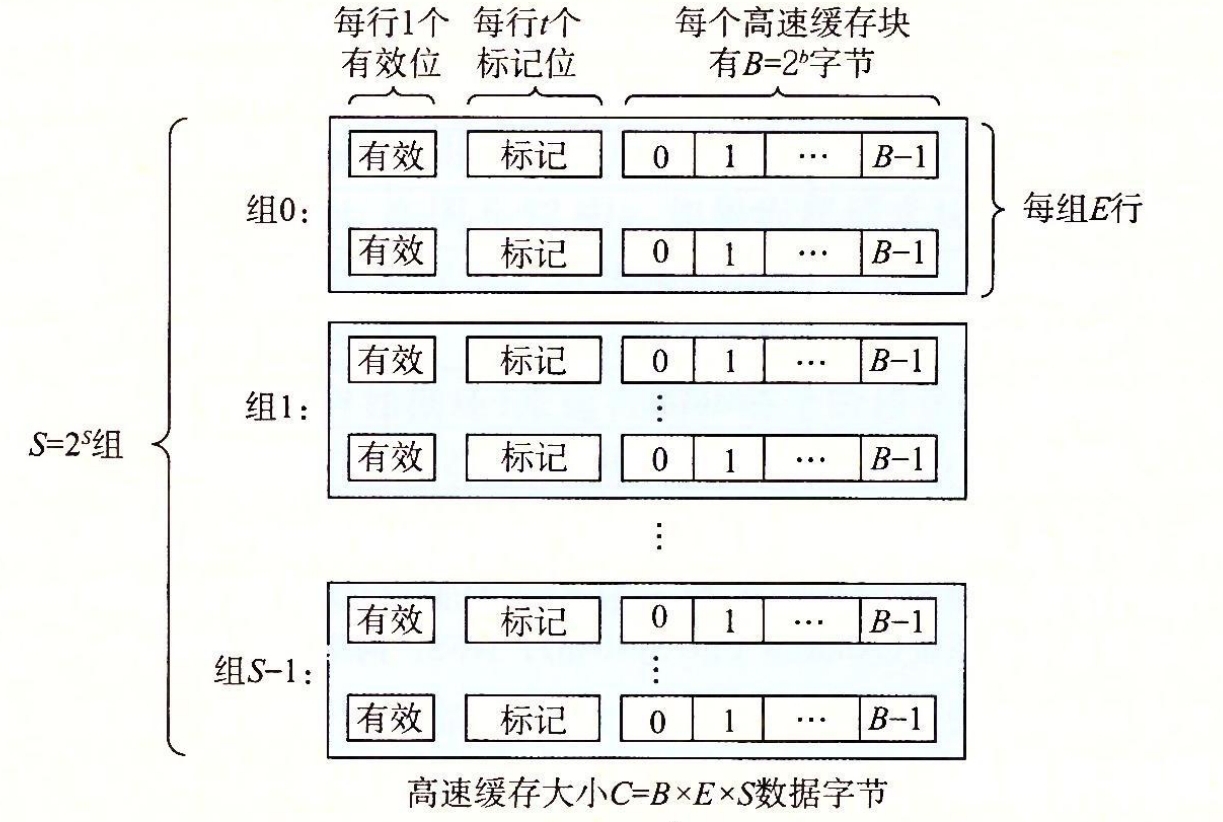
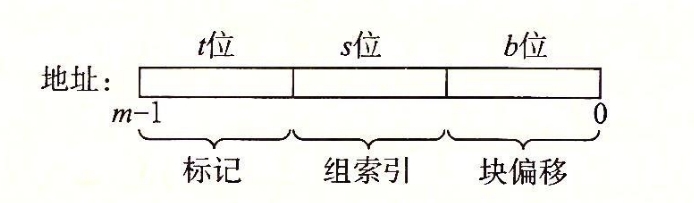
m位的地址分为三块
标记位决定了在一组的哪一行
有关写的问题
写命中:直写,写回
写不命中:写分配,非写分配
CA B.1.2 4个存储器层次结构问题
问题一:块在缓存位置存放
组相联映射,直接映射,全相联映射
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BFQIyYg5-1608430770116)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201215171005229.png)]](https://i-blog.csdnimg.cn/blog_migrate/a4dea250fbadba8ed3f4e4be16d025e4.png)
问题二:如何在缓存中找到块
这个图就是和上面那个6.4的是一样的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yXwez9zv-1608430770117)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201215171102279.png)]](https://i-blog.csdnimg.cn/blog_migrate/fc23f9f3cc9edef8eed97be23218e6f3.png)
问题三: 缓存缺失时替换哪个快
近似LRU:
缓存中,每个组都有一组对应比特来对应每个块,使用一个块就开启一个bit,当最后一个比特被开启时,其他所有比特全部关闭。替换时从这些关闭的比特对应的块里去找
4C(4种缺失模型)
-
强制缺失 第一次访问块,该块一定不在缓存中
-
容量缺失 缓存放不开
-
冲突缺失 对组来说,有太多快被映射到一个组,放不开
抖动:高速缓存反复地驱逐和加载相同的高速缓存快的组
-
一致性缺失 保持多个缓存一致进行缓存刷新
CA 2.2.10 用编译器控制预取,降低缺失代价或缺失率
看懂例题就好了
一个块16字节,一个数组元素8字节,一次缺失将邻近两个元素放入缓存。

第七章 链接
链接:把各种代码和数据收集起来并组合成一个单一的文件(可执行文件),该文件可以被加载到内存中执行
7.1 编译器驱动程序
就是1.2内容,驱动程序控制那四个过程
注意,汇编程序会将引入的函数经过相同过程也变为.o文件
加载器
在命令行输入./xx ,shell调用操作系统的一个叫做加载器的函数,它将可执行文件中的代码和数据复制到内存中,然后将控制转移到这个程序的开头。
7.2 静态链接
静态链接器 输入:输出:
可重定位 目标文件由不同的代码和数据节组成,每一节都是连续字节序列
为了生成 可执行目标文件:
链接器任务:
-
符号解析 理解符号是啥,目的: 关联符号的定义和 引用
-
重定位 编译器和汇编器生成的数据节和代码地址 是从0开始的,把符号定义与一个内存位置关联起来,重定位这些节, 然后修改该符号引用,指向对应内存位置
符号解析将符号和引用对应起来,重定位使引用指向向符号对应的内存位置
目标文件纯粹是字节快的组合
7.3 目标文件
目标文件三种形式
7.4 可重定位目标文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tJ9JNBJW-1608430770118)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201212105812444.png)]](https://i-blog.csdnimg.cn/blog_migrate/cea76266fd16e1a936324af1bf7f4e2d.png)
各个部位功能
.text/.data/.bss/.symtab/.rel.text/.rel.data
7.5 符号和符号表
可重定位目标模块 有符号表
链接器上下文有三种符号 //上下文是什么东西?
两种全局符号,一种局部符号(都是对于全局变量来说的)
static函数和全局变量是局部符号
对 局部变量来说: static和非static分情况
符号表包含一个 条目的数组,条目有格式,每个变量代表一个含义(看课本)、
7.6 符号解析
链接器如何解析多重定义的全局符号
三种情况
与静态库链接
7.8 可执行目标文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tfO5Ksxw-1608430770118)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201212113443863.png)]](https://i-blog.csdnimg.cn/blog_migrate/6216fe2818ae83834aadbe173ef1421e.png)
段头部表、节头部表
7.9 加载可执行目标文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6uQJUN6Y-1608430770119)(C:\Users\yandalao\AppData\Roaming\Typora\typora-user-images\image-20201212113730050.png)]](https://i-blog.csdnimg.cn/blog_migrate/7e157240c32297bd2d5c8ff003e7a232.png)

















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









