







 本文介绍了魔兽世界插件开发中的Table Of Contents (TOC) 文件,包括其重要性、格式、各部分解释,如Interface、Title、Notes、依赖管理等,以及如何影响插件的加载和功能。
本文介绍了魔兽世界插件开发中的Table Of Contents (TOC) 文件,包括其重要性、格式、各部分解释,如Interface、Title、Notes、依赖管理等,以及如何影响插件的加载和功能。
魔兽世界插件开发 插件教程 插件编写 Table Of Contents TOC文件介绍
更多信息请关注:鸿石散人
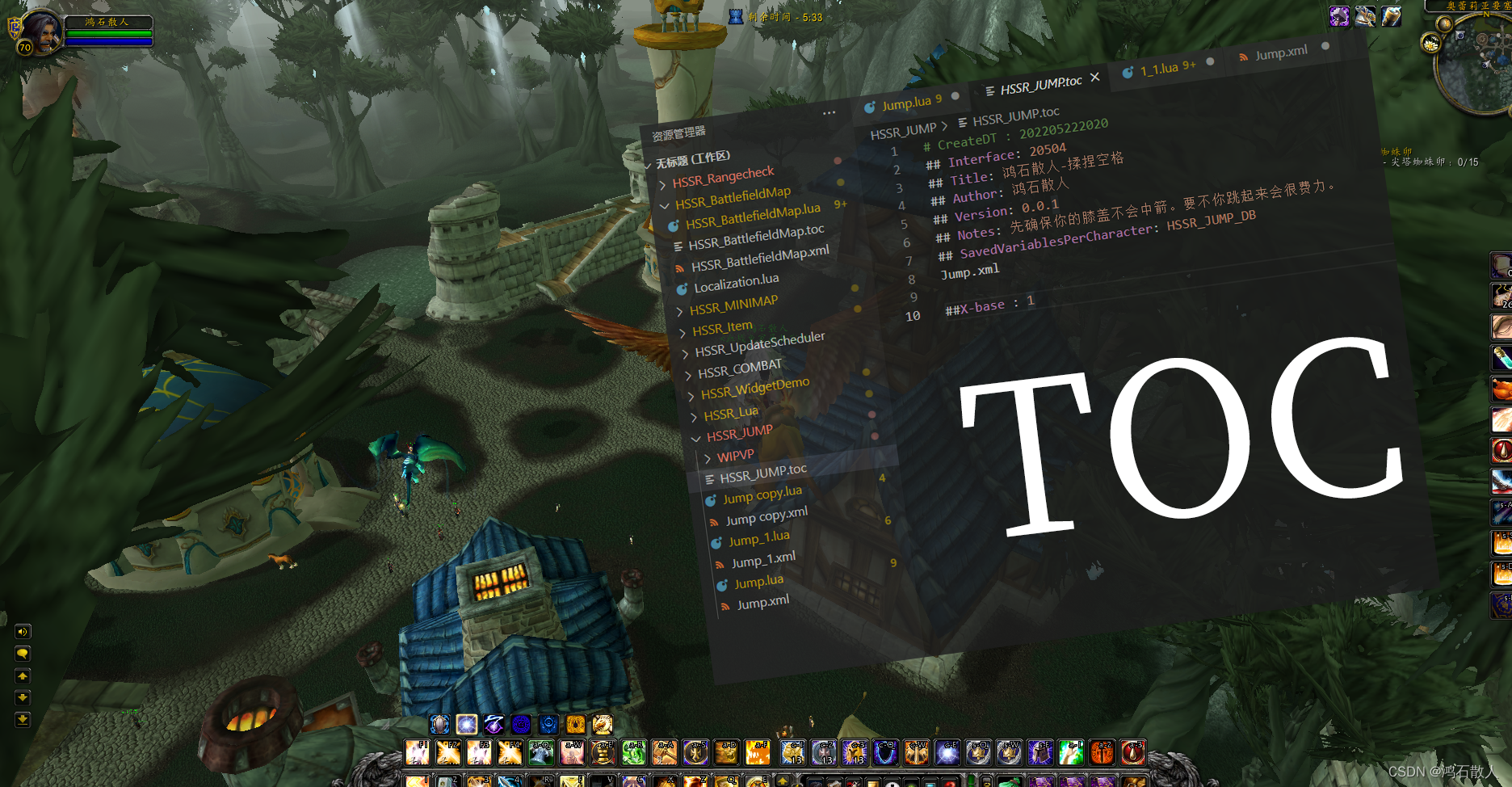
Table Of Contents
Table Of Contents.TOC文件插件的清单文件。它包含了关于插件的特定信息,如名称,描述,存储,环境,插件文件的加载顺序。
TOC 文件必须存在,否则魔兽客户端不能识别。
TOC 文件名称必须和插件目录名称一致。
TOC 文件格式
- TOC文件内容以行为执行单元
- 以“#”开头的行: 注释行 加载时会被忽略
- 以“##”开头的行:标记行 提供有关 AddOn 的元数据
- 非# 和 ## 的行: 文件行 提供顺序加载的文件的名称
- 每行最多读取前 1024 个字符。其他字符将被忽略,不会导致错误。
- 文件行中的文件可使用相对路径,相对路径起始值是TOC文件的路径。
- 文件行引用的是 Lua 文件和 XML 文件。
- LUA和XML文件的编写顺序也是加载的加载顺序,靠前的文件先加载。
示例
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5987
5987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











