







矩阵的迹求导法则

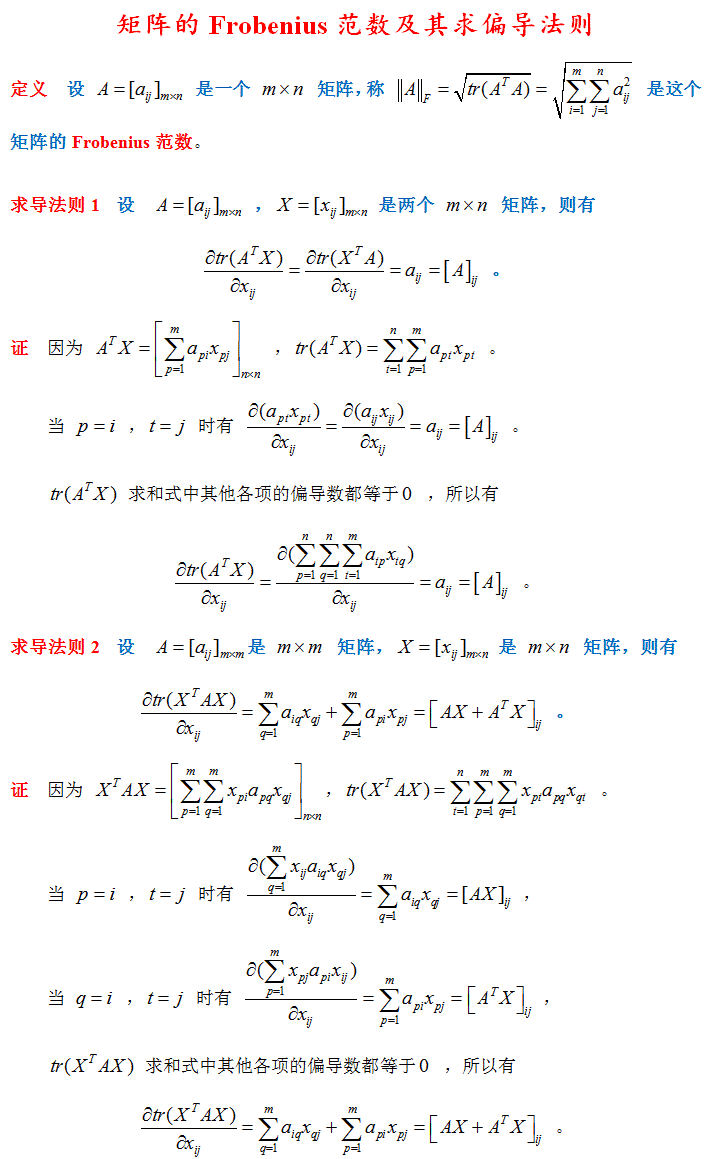
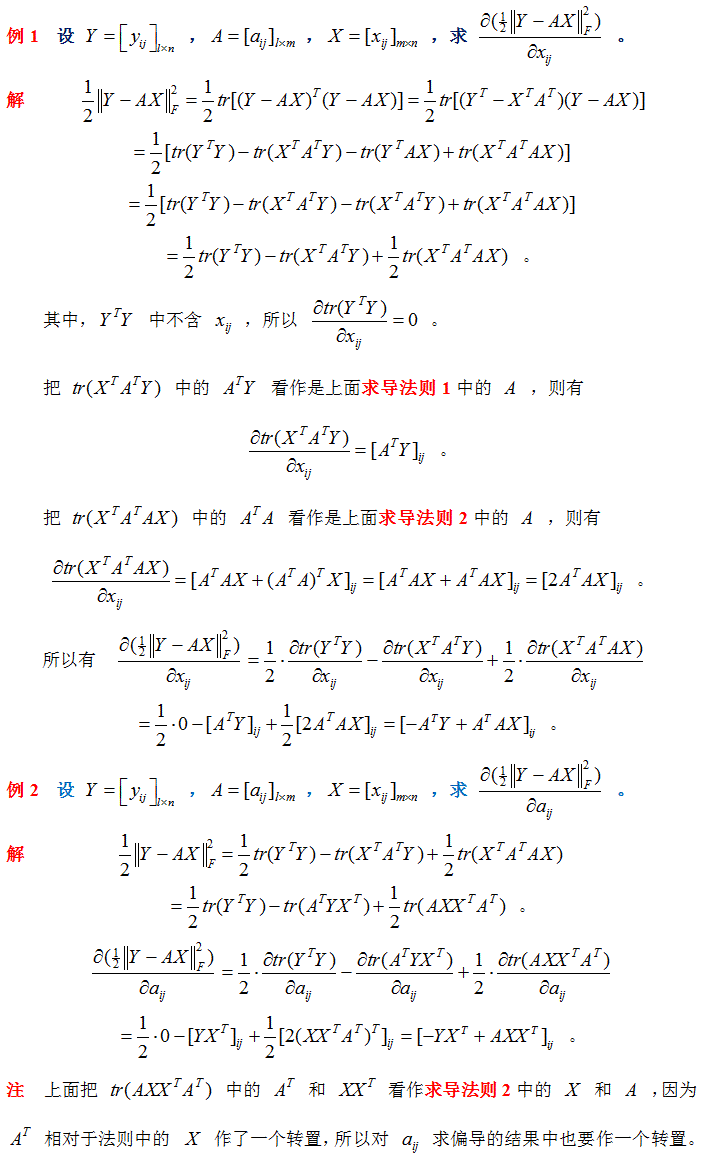
1. 复杂矩阵问题求导方法:可以从小到大,从scalar到vector再到matrix
2. x is a column vector, A is a matrix
d(A∗x)/dx=A
d(xT∗A)/dxT=A
d(xT∗A)/dx=AT
d(xT∗A∗x)/dx=xT(AT+A)
3. Practice:
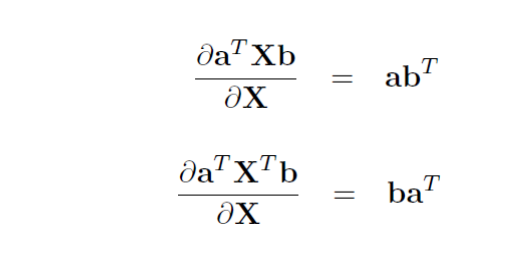
4. 矩阵求导计算法则
求导公式(撇号为转置):
Y = A * X –> DY/DX = A’
Y = X * A –> DY/DX = A
Y = A’ * X * B –> DY/DX = A * B’
Y = A’ * X’ * B –> DY/DX = B * A’
乘积的导数:
d(f*g)/dx=(df’/dx)g+(dg/dx)f’
一些结论:
- 矩阵Y对标量x求导:
相当于每个元素求导数后转置一下,注意M×N矩阵求导后变成N×M了
Y = [y(ij)]–> dY/dx = [dy(ji)/dx] - 标量y对列向量X求导:
注意与上面不同,这次括号内是求偏导,不转置,对N×1向量求导后还是N×1向量
y = f(x1,x2,..,xn) –> dy/dX= (Dy/Dx1,Dy/Dx2,..,Dy/Dxn)’ - 行向量Y’对列向量X求导:
注意1×M向量对N×1向量求导后是N×M矩阵。
将Y的每一列对X求偏导,将各列构成一个矩阵。
重要结论:
dX’/dX =I
d(AX)’/dX =A’ - 列向量Y对行向量X’求导:
转化为行向量Y’对列向量X的导数,然后转置。
注意M×1向量对1×N向量求导结果为M×N矩阵。
dY/dX’ =(dY’/dX)’ - 向量积对列向量X求导运算法则:
注意与标量求导有点不同。
d(UV’)/dX =(dU/dX)V’ + U(dV’/dX)
d(U’V)/dX =(dU’/dX)V + (dV’/dX)U’
重要结论:
d(X’A)/dX =(dX’/dX)A + (dA/dX)X’ = IA + 0X’ = A
d(AX)/dX’ =(d(X’A’)/dX)’ = (A’)’ = A
d(X’AX)/dX =(dX’/dX)AX + (d(AX)’/dX)X = AX + A’X - 矩阵Y对列向量X求导:
将Y对X的每一个分量求偏导,构成一个超向量。
注意该向量的每一个元素都是一个矩阵。 - 矩阵积对列向量求导法则:
d(uV)/dX =(du/dX)V + u(dV/dX)
d(UV)/dX =(dU/dX)V + U(dV/dX)
重要结论:
d(X’A)/dX =(dX’/dX)A + X’(dA/dX) = IA + X’0 = A - 标量y对矩阵X的导数:
类似标量y对列向量X的导数,
把y对每个X的元素求偏导,不用转置。
dy/dX = [Dy/Dx(ij) ]
重要结论:
y = U’XV= ΣΣu(i)x(ij)v(j) 于是 dy/dX = [u(i)v(j)] =UV’
y = U’X’XU 则dy/dX = 2XUU’
y =(XU-V)’(XU-V) 则 dy/dX = d(U’X’XU - 2V’XU + V’V)/dX = 2XUU’ - 2VU’ +0 = 2(XU-V)U’ - 矩阵Y对矩阵X的导数:
将Y的每个元素对X求导,然后排在一起形成超级矩阵。
10.乘积的导数
d(f*g)/dx=(df’/dx)g+(dg/dx)f’
结论
d(x’Ax)=(d(x”)/dx)Ax+(d(Ax)/dx)(x”)=Ax+A’x (注意:”是表示两次转置)
矩阵求导 属于 矩阵计算,应该查找 Matrix Calculus 的文献:
http://www.psi.toronto.edu/matrix/intro.html#Intro
http://www.psi.toronto.edu/matrix/calculus.html
http://www.stanford.edu/~dattorro/matrixcalc.pdf
http://www.colorado.edu/engineering/CAS/courses.d/IFEM.d/IFEM.AppD.d/IFEM.AppD.pdf
http://www4.ncsu.edu/~pfackler/MatCalc.pdf
http://center.uvt.nl/staff/magnus/wip12.pdf

















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









