







转载自:vector03
2.3 Chunk (arena_chunk_t)
chunk是仅次于arena的次级内存结构. 如果有了解过dlmalloc, 就会知道在dlmalloc中同样定义了名为’chunk’的基础结构. 但这个概念在两个分配器中含义完全不同, dlmalloc中的chunk指代最低级分配单元, 而jemalloc中则是一个较大的内存区域.
2.3.1 overview
从前面arena的数据结构可以发现, 它是一个非常抽象的概念, 其大小也不代表实际的内存分配量. 原始的内存数据既非挂载在arena外部, 也并没有通过内部指针引用, 而是记录在chunk中. 按照一般的思路, chunk包含原始内存数据, 又从属于arena, 因此arena应该会有一个数组之类的结构以记录所有chunk信息. 但事实上同样找不到这样的记录. 那jemalloc又如何获得chunk指针呢?
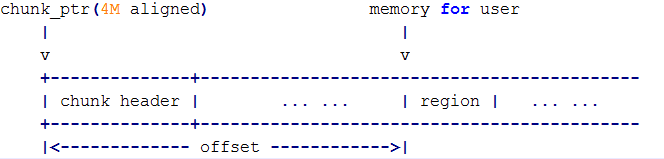
所谓的chunk结构, 只是整个chunk的一个header, bookkeeping以及user memory都挂在header外面. 另外jemalloc对chunk又做了规定, 默认每个chunk大小为4MB, 同时还必须对齐到4MB的边界上.
#define LG_CHUNK_DEFAULT 22这个宏定义了chunk的大小. 注意到前缀’LG_’, 代表log即指数部分. jemalloc中所有该前缀的代码都是这个含义, 便于通过bit操作进行快速的运算.
有了上述规定, 获得chunk就变得几乎没有代价. 因为返回给user程序的内存地址肯定属于某个chunk, 而该chunk header对齐到4M边界上, 且不可能超过4M大小(即向上对齐到最近的4M整数倍地址), 所以只需要对该地址做一个下对齐就得到chunk指针, 如下,
#define CHUNK_ADDR2BASE(a) \
((void *)((uintptr_t)(a) & ~chunksize_mask))
计算相对于chunk header的偏移量,
#define CHUNK_ADDR2OFFSET(a) \
((size_t)((uintptr_t)(a) & chunksize_mask))
以及上对齐到chunk边界的计算,
#define CHUNK_CEILING(s) \
(((s) + chunksize_mask) & ~chunksize_mask)
用图来表示如下,
###2.3.2 Chunk结构
struct arena_chunk_s {
arena_t *arena;
rb_node(arena_chunk_t) dirty_link;
size_t ndirty;
size_t nruns_avail;
size_t nruns_adjac;
arena_chunk_map_t map[1];
}
arena: chunk属于哪个arena.
dirty_link: 用于arena chunks_dirty(rb tree)的链接节点. 如果某个chunk内部含有任何dirty page, 就会被挂载到arena中的chunks_dirty tree上.
ndirty: 内部dirty page数量.
nruns_avail: 内部available runs数量.
nruns_adjac: available runs又分为dirty和clean两种, 相邻的两种run是无法合并的,除非其中的dirty runs通过purge才可以. 该数值记录的就是可以通过purge合并的run数量.
map: 动态数组, 每一项对应chunk中的一个page状态(不包含header即map本身的占用). chunk(包括内部的run)都是由page组成的. page又分为unallocated, small, large三种.unallocated指的那些还未建立run的page. small/large分别指代该page所属run的类型是small/large run.这些page的分配状态, 属性, 偏移量, 及其他的标记信息等等, 都记录在arena_chunk_map_t中.
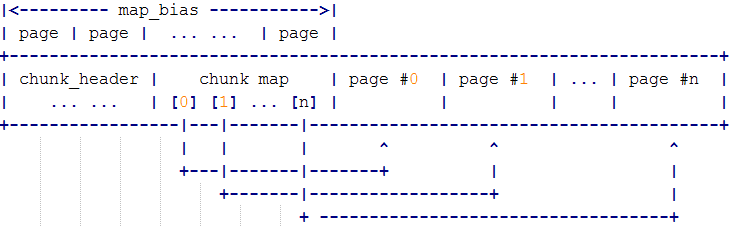
至于由chunk header和chunk map占用的page数量, 保存在map_bias变量中. 该变量是jemalloc在arena boot时通过迭代算法预先计算好的, 所有chunk都是相同的.迭代方法如下:
- 第一次迭代初始map_bias等于0, 计算最大可能大小, 即
header_size + chunk_npages * map_size获得header+map需要的page数量, 结果肯定高于最终的值.
2. 第二次将之前计算的map_bias迭代回去, 将最大page数减去map_bias数, 重新计算
header+map大小, 由于第一次迭代map_bias过大, 第二次迭代必定小于最终结果.
3. 第三次再将map_bias迭代回去, 得到最终大于第二次且小于第一次的计算结果.
相关代码如下,
void arena_boot(void)
{
......
map_bias = 0;
for (i = 0; i < 3; i++) {
header_size = offsetof(arena_chunk_t, map) +
(sizeof(arena_chunk_map_t) * (chunk_npages-map_bias));
map_bias = (header_size >> LG_PAGE) + ((header_size & PAGE_MASK)
!= 0);
}
......
}
2.2.3 chunk map (arena_chunk_map_t)
chunk记录page状态的结构为arena_chunk_map_t, 为了节省空间, 使用了bit压缩存储信息.
struct arena_chunk_map_s {
#ifndef JEMALLOC_PROF
union {
#endif
union {
rb_node(arena_chunk_map_t) rb_link;
ql_elm(arena_chunk_map_t) ql_link;
} u;
prof_ctx_t *prof_ctx;
#ifndef JEMALLOC_PROF
};
#endif
size_t bits;
}
chunk map内部包含两个link node, 分别可以挂载到rb tree或环形队列上, 同时为了节省空间又使用了union. 由于run本身也是由连续page组成的, 因此chunk map除了记录page状态之外, 还负责run的基址检索.
举例来说, jemalloc会把所有已分配run记录在内部rb tree上以快速检索, 实际地操作是将该run中第一个page对应的chunk_map作为rb node挂载到tree上. 检索时也是先找出将相应的chunk map, 再进行地址转换得到run的基址.
按照通常的设计思路, 我们可能会把run指针作为节点直接保存到rb tree(bins结构中的rb tree)中. 但jemalloc中的设计明显要更复杂. 究其原因, 如果把link node放到run中, 后果是bookkeeping和user memory将混淆在一起, 这对于分配器的安全性是很不利的. 包括dlmalloc在内的传统分配器都具有这样的缺陷. 而如果单独用link node记录run, 又会造成空间浪费. 正因为jemalloc中无论是chunk还是run都是连续page组成, 所以用首个page对应的chunk map就能同时代表该run的基址.
jemalloc中通常用mapelm换算出pageind, 再将pageind << LG_PAGE + chunk_base, 就能得到run指针, 代码如下,
arena_chunk_t *run_chunk = CHUNK_ADDR2BASE(mapelm);
size_t pageind = arena_mapelm_to_pageind(mapelm);
run = (arena_run_t *)((uintptr_t)run_chunk + (pageind <<
LG_PAGE));
JEMALLOC_INLINE_C size_t arena_mapelm_to_pageind(arena_chunk_map_t *mapelm)
{
uintptr_t map_offset =
CHUNK_ADDR2OFFSET(mapelm) - offsetof(arena_chunk_t, map);
return ((map_offset / sizeof(arena_chunk_map_t)) + map_bias);
}
chunk map对page状态描述都压缩记录到bits中, 由于内容较多, 直接引用jemalloc代码
中的注释,
下面是一个假想的ILP32系统下的bits layout,
???????? ???????? ????nnnn nnnndula“?”的部分分三种情况, 分别对应unallocated, small和large.
? : Unallocated: 首尾page写入该run的地址, 而内部page则不做要求. Small: 全部是page的偏移量. Large: 首page是run size, 后续的page不做要求.
n : 对于small run指其所在bin的index, 对large run写入BININD_INVALID.
d : dirty?
u : unzeroed?
l : large?
a : allocated?
下面是对三种类型的run page做的举例,
p : run page offset
s : run size
n : binind for size class; large objects set these to BININD_INVALID
x : don't care
- : 0
+ : 1
[DULA] : bit set
[dula] : bit unset
Unallocated (clean):
ssssssss ssssssss ssss++++ ++++du-a
xxxxxxxx xxxxxxxx xxxxxxxx xxxx-Uxx
ssssssss ssssssss ssss++++ ++++dU-a
Unallocated (dirty):
ssssssss ssssssss ssss++++ ++++D--a
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx
ssssssss ssssssss ssss++++ ++++D--a
Small:
pppppppp pppppppp ppppnnnn nnnnd--A
pppppppp pppppppp ppppnnnn nnnn---A
pppppppp pppppppp ppppnnnn nnnnd--A
Small page需要注意的是, 这里代表的p并非是一个固定值, 而是该page相对于其所在run的第一个page的偏移量, 比如可能是这样,
00000000 00000000 0000nnnn nnnnd--A
00000000 00000000 0001nnnn nnnn---A
00000000 00000000 0010nnnn nnnn---A
00000000 00000000 0011nnnn nnnn---A
...
00000000 00000001 1010nnnn nnnnd--A
Large:
ssssssss ssssssss ssss++++ ++++D-LA
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx
-------- -------- ----++++ ++++D-LA
Large (sampled, size <= PAGE):
ssssssss ssssssss ssssnnnn nnnnD-LA
Large (not sampled, size == PAGE):
ssssssss ssssssss ssss++++ ++++D-LA
为了提取/设置map bits内部的信息, jemalloc提供了一组函数, 这里列举两个最基本的,剩下的都是读取mapbits后做一些位运算而已,
读取mapbits,
JEMALLOC_ALWAYS_INLINE size_t
arena_mapbits_get(arena_chunk_t *chunk, size_t pageind)
{
return (arena_mapbitsp_read(arena_mapbitsp_get(chunk, pageind)));
}
根据pageind获取对应的chunk map,
JEMALLOC_ALWAYS_INLINE arena_chunk_map_t *
arena_mapp_get(arena_chunk_t *chunk, size_t pageind)
{
......
return (&chunk->map[pageind-map_bias]);
}














 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









