







简介
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,支持大型数据的存储和处理,可在廉价 PC 上搭建起大规模结构化存储集群。
HBase 是 Google Bigtable 的开源实现,但是也有很多不同之处。比如:Google Bigtable利用 GFS 作为其文件存储系统,HBase 利用 Hadoop HDFS 作为其文件存储系统;Google运行 MAPREDUCE 来处理 Bigtable 中的海量数据,HBase 同样利用 Hadoop MapReduce 来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
特点
1 海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。
2 列式存储
Hbase 是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3 极易扩展
Hbase 的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加 RegionSever 的机器,进行水平扩展,提升 Hbase 上层的处理能力,提升 Hbsae服务更多 Region 的能力。
备注:RegionServer 的作用是管理 region、承接业务的访问,这个后面会详细的介绍通过横向添加 Datanode 的机器,进行存储层扩容,提升 Hbase 的数据存储能力和提升后端存储的读写能力。
4 高并发
由于目前大部分使用 Hbase 的架构,都是采用的廉价 PC,因此单个 IO 的延迟其实并不小,一般在几十到上百 ms 之间。这里说的高并发,主要是在并发的情况下,Hbase 的单个IO 延迟下降并不多。能获得高并发、低延迟的服务。
5 稀疏
稀疏主要是针对 Hbase 列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
组件架构
Hbase架构如下

1 Client
Client 包含了访问 Hbase 的接口,另外 Client 还维护了对应的 cache 来加速 Hbase 的访问,比如 cache 的.META.元数据的信息。
2 Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
- 通过 Zoopkeeper 来保证集群中只有 1 个 master 在运行,如果 master 异常,会通过竞争机制产生新的 master 提供服务
- 通过 Zoopkeeper 来监控 RegionServer 的状态,当 RegionSevrer 有异常的时候,
- 通过回调的形式通知 Master RegionServer 上下线的信息
- 通过 Zoopkeeper 存储元数据的统一入口地址
3 Hmaster
master 节点的主要职责如下:
- 监控 RegionServer,为 RegionServer 分配 Region
- 维护整个集群的负载均衡,在空闲时间进行数据的负载均衡
- 维护集群的元数据信息
- 处理 RegionServer 故障转移,发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上
- 当 RegionSever 失效的时候,协调对应 Hlog 的拆分
- 通过 Zookeeper 发布自己的位置给客户端
4 HregionServer
HregionServer 直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
- 代表一个物理服务器
- 管理 master 为其分配的 Region
- 处理来自客户端的读写请求
- 维护 Hlog,一个region server具有一个独立的Hlog
- 负责和底层 HDFS 的交互,存储数据到 HDFS
- 负责 Region 变大以后的拆分
- 负责 Storefile 的合并工作
- 执行数据压缩
5 Region
- Hbase扩展和负载均衡的基本单元,将表根据RowKey值被切分成不同的region存储在RegionServer中
6 Hlog(Write-Ahead logs)
- HBase 的修改记录,当对 HBase 读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。
- 数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入内存中
- 在系统出现故障的时候,数据可以通过这个日志文件重建。
7 Store
- HFile 存储在 Store 中,一个 Store 对应 HBase 表中的一个列族。
8 MemStore
- 就是内存存储,位于内存中,用来保存当前的数据操作,
- 所以当数据保存在WAL 中之后,RegsionServer 会在内存中存储键值对。
9 HFile
- 这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
- StoreFile 是以 Hfile的形式存储在 HDFS 的。
10 HDFS
HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高可用(Hlog 存储在HDFS)的支持,具体功能概括如下:
提供元数据和表数据的底层分布式存储服务数据多副本,保证的高可靠和高可用性
数据结构
- 最基本的单位是列,column
- 一列和多列组成一行,row
- 一行有唯一的行健,rowkey
- 每列可能有多个版本,多个版本存储在单元格(cell)中,
- 行序是按照字典顺序进行排序的,意思是从左到右一次对比每一个键
- 若干列又构成了一个列族,一个列族的所有列存储在同一个底层文件中
列簇
- 构建数据的语义边界或者局部边界
- 有助于设置压缩或者指示他们存储在内存中
- 一个列族的所有列存储在同一个底层存储文件里面,这个文件叫做HFile
使用注意点:
- 列族不能修改的太频繁,数量也不能太多,在当前的实现中如果列族大于几十个会出现bug,实际情况可能还小的多
- 引用列的格式为 family:qualifier , family 就是列族名, qualifier就是列名,比如 log:time 是获取 log这个列族中的time列,列是无限的可以达到几百万
单元格cell
- 一个单元格内可以存储一列值的过个版本,每个版本对应一个时间戳,系统默认指定,用户也可以显示制定
- 用户可以设置单元格内版本数量,在查询时默认返回最新的值
命名空间
命名空间的结构:
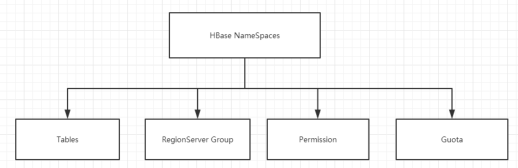
1) Table:表,所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定,则在 default 默认的命名空间中。
2) RegionServer group :一个命名空间包含了默认的 RegionServer Group。
3) Permission :权限,命名空间能够让我们来定义访问控制列表 ACL( Access Control List )。
例如,创建表,读取表,删除,更新等等操作。
4) Quota :限额,可以强制一个命名空间可包含的 region 的数量。
自动分区
Hbase的表数据由region负责管理,region是Hbase扩展和负载均衡的基本单元,具有以下特点:
- region本质上是以行健排序的连续存储的区间;
- 如果region太大就会动态拆分
- 如果region太小就会合并以节省空间
- region相当于传统数据库的分区表
- 每台服务器的最佳加载数量是 10~1000
分区过程:
- 一开始是有一个region,当这个region大到一定的值的时候就会从中间的那个行键(rowkey的中间值)处将这个region拆分为大致相等的两个子region。
- 一个服务器可以包含region。
- Hbase不支持在线的region合并,但是可以离线合并
- region的拆分非常快,接近于瞬间,因为并没有改变存储的位置
- 如果一个region server的负载过大会触发region迁移,它会将region迁移到别的region server上















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









