






一.问题描述
在农业运营中,杂草是一种不受欢迎的入侵者,它们会窃取作物所需的营养、水、土地和其他关键资源,从而破坏种植,降低产量并降低资源利用效率。虽然使用杀虫剂是一种清除杂草的方法,但这种方法会给人类带来健康风险。
我们的目标是通过计算机视觉技术自动检测杂草的存在,开发一种只在杂草上喷洒农药的系统,并使用针对性的修复技术将其从田地中清除。这样,我们就可以最小化杂草对环境的负面影响,同时避免对作物造成不必要的损害
二:数据集
Imges:
作物(crop):

杂草(weed):

标签(labels):
作物(crop):0 0.478516 0.560547 0.847656 0.625000
杂草(weed):1 0.508789 0.489258 0.869141 0.861328
三:英特尔® oneAPI AI分析工具套件(Intel® AI Analytics Toolkits)
1.架构图:
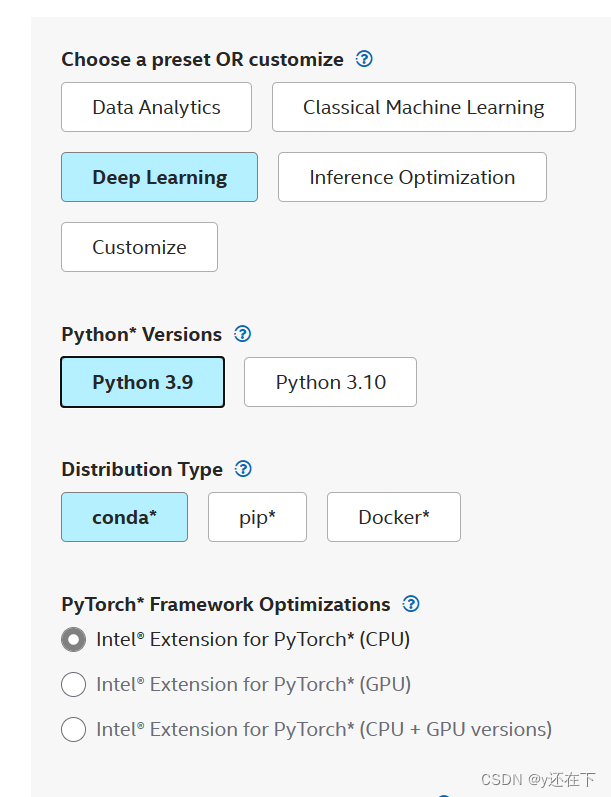
2.DevCloud云测试环境(Overview | Intel® DevCloud)
启动Jupypter 服务,一般推荐使用Python3环境进行,但后面会用到Torch包,这边可以直接使用PyTorch环境,避免后面出现导包错误
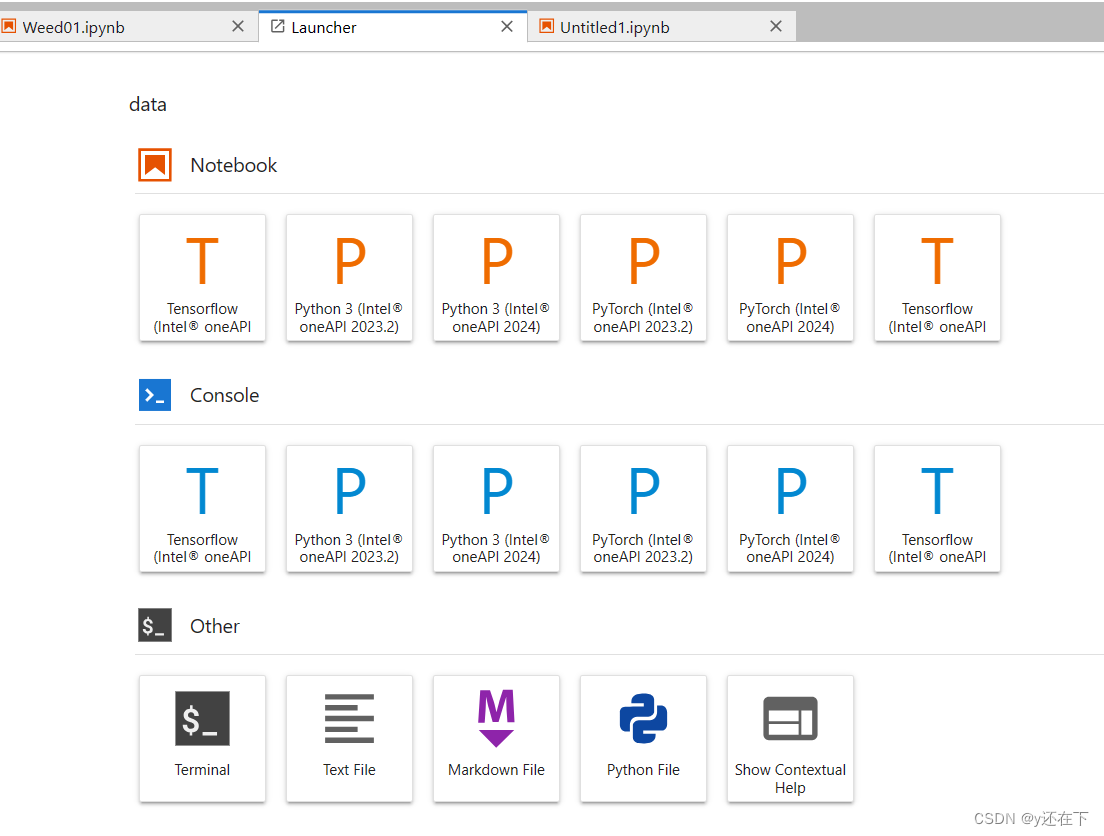
开始前需要把准备好的数据集提前导入
注意:如果数据集非常多,需要分次导入,因为我后面就是因为一次性导入造成数据丢失
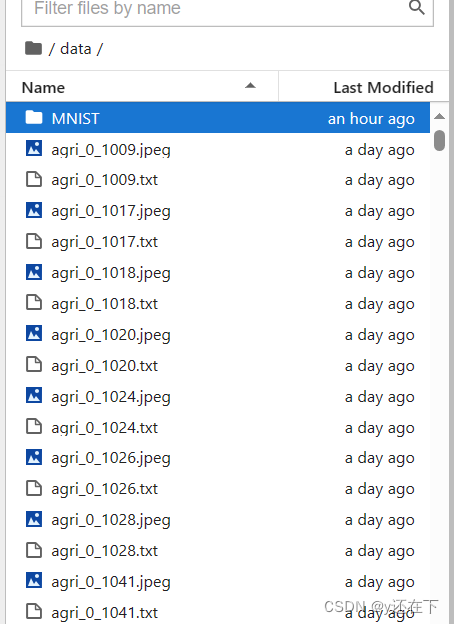
导入数据集后就可以进行后续代码的编写
四.项目代码及神经网络
1.导入需要用到的包
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
import torchvision.models as models
from PIL import Image
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import random
from PIL import ImageEnhance
import itertools
import intel_extension_for_pytorch as ipex
from collections import Counter
import sys
import os为了方便后续观察代码运行进度,我还导入tqdm包,这需要我们下载
pip install tqdm导入
import random
from tqdm import tqdm2.把数据集中的图片数据去掉.jepg后缀名写入classes.txt中,方便后面读取图片数据和划分训练集测试集
def get_file_name(dir):
images_files = [f for f in os.listdir(dir) if f.endswith('.jpeg')]
images_files.sort()
with open(r'./Weed/classes.txt','a') as f:
for i in images_files:
f.write(i+'\n')
f.close()
print('文件写入完成!!!')
get_file_name('./data')3.指定目录中读取图像文件,将它们转换为灰度图并应用一系列转换,然后将处理后的图像分为训练集和测试集
import torch
from torchvision import transforms
from PIL import Image
import os
# 定义图像转换器
transformer = transforms.Compose([
transforms.ToTensor(),
transforms.RandomContrast(0.5), # 增强对比度
transforms.Normalize(mean=[0.5], std=[0.5]) # 归一化
])
# 读取类别文件并获取文件名列表
with open(r'./Weed/classes.txt', 'r') as f:
file_names = [line.strip() for line in f.readlines()]
# 读取图像数据并进行转换
image_dir = 'data'
image_tensors = []
for file_name in file_names:
image_path = os.path.join(image_dir, file_name)
image = Image.open(image_path).convert('L') # 转为灰度图
tensor = transformer(image) # 进行转换
image_tensors.append(tensor)
# 分割训练集和测试集
split_index = int(0.7 * len(image_tensors))
image_train, image_test = image_tensors[:split_index], image_tensors[split_index:]
4.读取图像文件名和对应的标签数据,将标签转换为Tensor格式,再将标签分为训练集和测试集
# 定义图像转换器
transformer = transforms.Compose([
transforms.ToTensor()
])
# 读取类别文件并获取文件名列表
with open(r'./Weed/classes.txt', 'r') as f:
file_names = [i.split('.')[0] for i in f.readlines()]
# 读取标签数据并进行转换
labels_tensors = []
for file_name in file_names:
label_path = './data/' + file_name + '.txt'
with open(label_path, 'r') as label_file:
label = label_file.readline()[0]
label = float(label)
tensor = torch.tensor(label, dtype=torch.float16) # 使用float16数据类型
labels_tensors.append(tensor)
# 分割训练集和测试集
split_index = int(0.7 * len(labels_tensors))
labels_train, labels_test = labels_tensors[:split_index], labels_tensors[split_index:] 5.将图像数据和对应的标签转换为PyTorch的数据格式,并准备用于训练和测试的批量数据加载器,这样可以在训练神经网络时按批次加载和处理数据
train_datas_tensor = torch.stack(image_train)
train_labels_tensor = torch.stack(lables_train)
test_datas_tensor = torch.stack(image_test)
test_labels_tensor = torch.stack(lables_test)
train_dataset = TensorDataset(train_labels_tensor, train_datas_tensor)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataset = TensorDataset(test_labels_tensor, test_datas_tensor)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=True)6.定义一个基于残差块的深度学习模型,用于图像识别等任务
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, in_channels, num_channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, num_channels, kernel_size=3, padding=1, stride=stride)
self.bn1 = nn.BatchNorm2d(num_channels)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_channels)
self.conv_shortcut = nn.Sequential()
if stride != 1 or in_channels != num_channels:
self.conv_shortcut = nn.Sequential(
nn.Conv2d(in_channels, num_channels, kernel_size=1, stride=stride),
nn.BatchNorm2d(num_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.conv_shortcut(x) if self.conv_shortcut else x
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self):
super().__init__()
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.block2 = nn.Sequential(BasicBlock(64, 64))
self.block3 = nn.Sequential(BasicBlock(64, 128, stride=2))
self.block4 = nn.Sequential(BasicBlock(128, 256, stride=2))
self.block5 = nn.Sequential(BasicBlock(256, 512, stride=2))
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.flatten = nn.Flatten()
self.linear = nn.Linear(512, 10)
def forward(self, x):
out = self.block1(x)
out = self.block2(out)
out = self.block3(out)
out = self.block4(out)
out = self.block5(out)
out = self.avg_pool(out)
out = self.flatten(out)
out = self.linear(out)
return out7.对预训练的ResNet-50模型进行微调,将其用于一个二分类任务
通过修改模型的第一个卷积层和全连接层,可以使其适用于新的任务,这边环境不支持使用cuda,要额外下载,所以就用不了GPU,这边改为使用CPU,并行能力就没有GPU这么强
import torch
import torch.nn as nn
import torchvision
from torch.optim import SGD
net = torchvision.models.resnet50(pretrained=True)
net.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
num_features = net.fc.in_features
net.fc = nn.Linear(num_features, 2)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
if device.type == 'cuda':
net = net.half()
criterion = nn.CrossEntropyLoss()
optimizer = SGD(net.parameters(), lr=0.001, momentum=0.9)
上面代码是可供选择的,在有条件使用GPU的情况下推荐使用GPU
8.使用交叉熵损失进行训练
交叉熵损失函数(CrossEntropy Loss)是分类问题中经常使用的一种损失函数,主要用于度量两个概率分布间的差异性。在信息论中,交叉熵是用来衡量模型学习到的分布和真实分布的差异。具体来说,交叉熵损失函数原理如下:
首先,需要了解交叉熵损失函数涉及到计算每个类别的概率。在分类问题中,模型会输出每个类别的预测概率,这些概率之和为1。然后,使用这些预测概率与真实标签之间的差异来计算损失。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义神经网络模型
class SimpleNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 定义超参数
input_size = 784 # 输入层大小(例如,MNIST数据集中的28x28像素)
hidden_size = 500 # 隐藏层大小
num_classes = 10 # 输出层大小(例如,MNIST数据集中的10个类别)
num_epochs = 10 # 训练轮数
batch_size = 64 # 批处理大小
learning_rate = 0.001 # 学习率
# 加载数据集(此处以MNIST为例)
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True)
# 对数据集中的每一个图像进行转换
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor() # 将PIL图像转换为张量
])
train_dataset = torchvision.datasets.ImageFolder(root=train_dataset.root, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# 实例化模型、损失函数和优化器
model = SimpleNet(input_size, hidden_size, num_classes)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # Adam优化器
# 训练模型
for epoch in range(num_epochs):
running_loss = 0.0
num_images = 0
model.train() # 设置模型为训练模式
for step, data in enumerate(train_loader, 0):
inputs, labels = data[0].to('cuda'), data[1].to('cuda') # 将数据移至GPU上(如果有可用的GPU)
optimizer.zero_grad() # 清零梯度缓存
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失值
loss.backward() # 反向传播,计算梯度值
optimizer.step() # 更新权重参数
num_images += inputs.size(0) # 计算处理过的图像数量
running_loss += loss.item() # 累计损失值
print(f'Epoch [{epoch+1}/{num_epochs}] Loss: {running_loss / num_images}') # 输出当前轮的平均损失值9.计算精度
correct = 0
total = 0
with torch.no_grad():
for data in test_dataloader:
images, labels = data[1].to('cpu').float(), data[0].to('cpu').long() # 将标签转换为整数类型
net = net.float()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Accuracy on test set: {accuracy:.2f}%')五.OneAPI组件的使用
Intel Optimization for PyTorch: PyTorch优化套件支持自动混合精度,这有助于减少模型的内存占用,提高计算性能。
Intel Extension for PyTorch :提供了专门针对英特尔 CPU 和加速器的硬件优化,以充分利用英特尔处理器的性能。这些优化可以显著提高深度学习模型的推理和训练性能。















 1901
1901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









