






数据结构
包装类型
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
Integer x = 2; // 装箱 调用了 Integer.valueOf(2)
int y = x; // 拆箱 调用了 X.intValue()
缓存池
new Integer(123) 与 Integer.valueOf(123) 的区别在于:
new Integer(123) 每次都会新建一个对象;
Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
基本类型对应的包装类型缓冲池如下:
boolean values true and false
all byte values
short values between -128 and 127
int values between -128 and 127
char in the range \u0000 to \u007F
String
String 被声明为 final,因此它不可被继承。(Integer 等包装类也不能被继承)
在 Java 8 中,String 内部使用 char 数组存储数据;在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种编码。
value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
String, StringBuffer and StringBuilder
- 可变性
String 不可变
StringBuffer 和 StringBuilder 可变 - 线程安全
String 不可变,因此是线程安全的
StringBuilder 不是线程安全的
StringBuffer 是线程安全的,内部使用 synchronized 进行同步
String Pool
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
new String(“abc”)
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 “abc” 字符串对象)。
“abc” 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 “abc” 字符串字面量;
而使用 new 的方式会在堆中创建一个字符串对象。
如果abc这个字符串常量不存在,则创建两个对象,分别是abc这个字符串常量,以及new String这个实例对象。
如果abc这字符串常量存在,则只会创建一个对象。
关键字
final
数据
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
对于基本类型,final 使数值不变;
对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
方法
声明方法不能被子类重写。
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
类
声明类不允许被继承。
static
静态变量
静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。
实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
静态方法
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。
只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字,因为这两个关键字与具体对象关联。
静态语句块
静态语句块在类初始化时运行一次。
静态内部类
非静态内部类依赖于外部类的实例,也就是说需要先创建外部类实例,才能用这个实例去创建非静态内部类。而静态内部类不需要。
静态内部类不能访问外部类的非静态的变量和方法。
静态导包
在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
初始化顺序
静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
存在继承的情况下,初始化顺序为:
父类(静态变量、静态语句块)
子类(静态变量、静态语句块)
父类(实例变量、普通语句块)
父类(构造函数)
子类(实例变量、普通语句块)
子类(构造函数)
异常
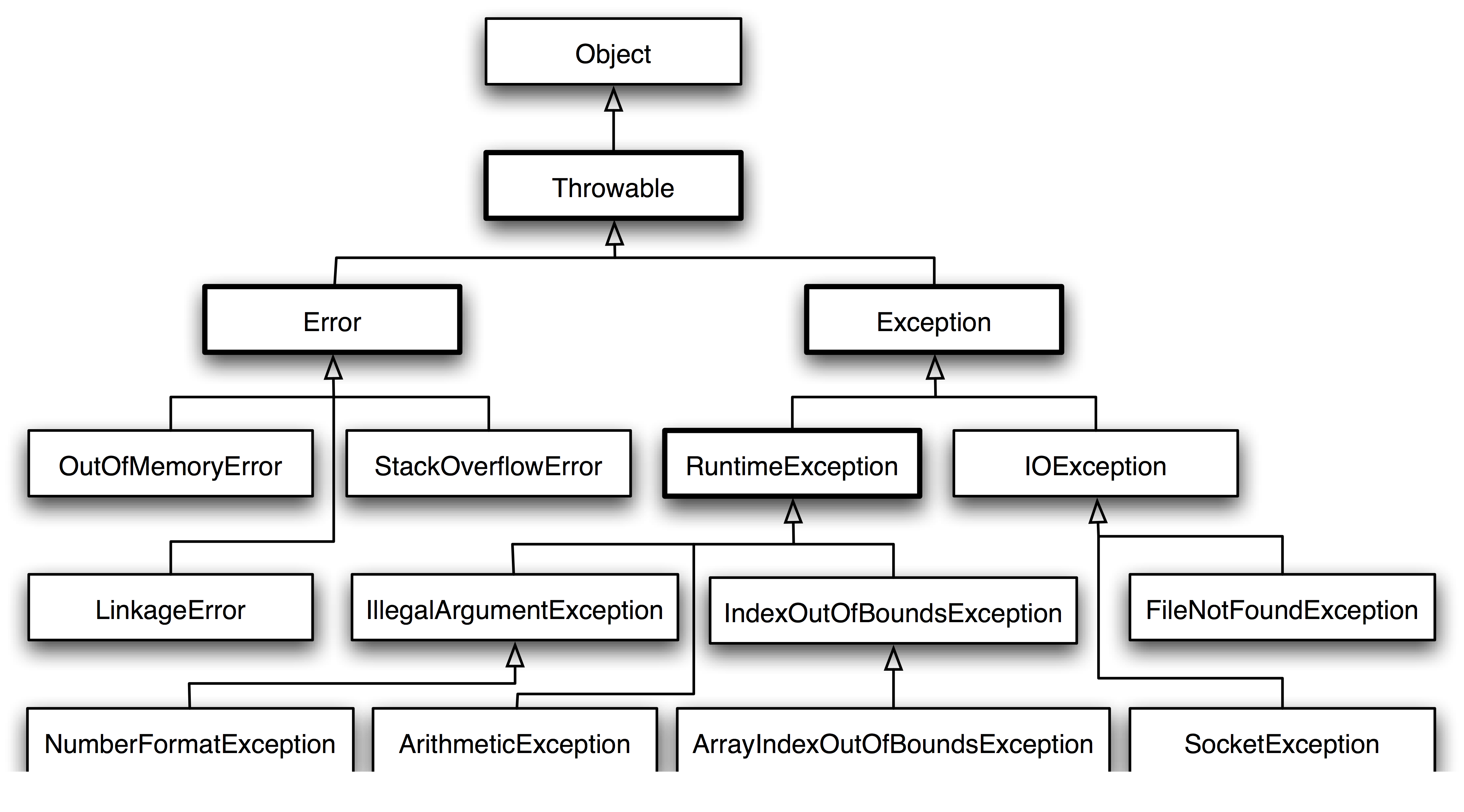
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
受检异常 :需要用 try…catch… 语句捕获并进行处理,并且可以从异常中恢复;
非受检异常 :是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
泛型
什么是泛型
泛型的本质就是"参数化类型"。一提到参数,最熟悉的就是定义方法的时候需要形参,调用方法的时候,需要传递实参。那"参数化类型"就是将原来具体的类型参数化
泛型的作用
泛型的出现避免了强转的操作,在编译器完成类型转化,也就避免了运行的错误。
泛型擦除
为了向下兼容。类型擦除使得类型参数只存在于编译期,在运行时,jvm是并不知道泛型的存在的。
并发
线程创建方式
Runnable 接口(无返回值)
需要实现接口中的 run() 方法。
public class MyRunnable implements Runnable {
@Override
public void run() {
// ...
}
}
使用 Runnable 实例再创建一个 Thread 实例,然后调用 Thread 实例的 start() 方法来启动线程。
public static void main(String[] args) {
MyRunnable instance = new MyRunnable();
Thread thread = new Thread(instance);
thread.start();
}
Callable 接口(带返回值)
与 Runnable 相比,Callable 可以有返回值,返回值通过 FutureTask 进行封装。
public class MyCallable implements Callable<Integer> {
public Integer call() {
return 123;
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyCallable mc = new MyCallable();
FutureTask<Integer> ft = new FutureTask<>(mc);
Thread thread = new Thread(ft);
thread.start();
System.out.println(ft.get());
}
继承 Thread 类(单继承)
同样也是需要实现 run() 方法,因为 Thread 类也实现了 Runable 接口。
当调用 start() 方法启动一个线程时,虚拟机会将该线程放入就绪队列中等待被调度,当一个线程被调度时会执行该线程的 run() 方法。
public class MyThread extends Thread {
public void run() {
// ...
}
}
public static void main(String[] args) {
MyThread mt = new MyThread();
mt.start();
}
使用线程池(底层都是实现run方法)
参数
| 参数 | 作用 |
|---|---|
| corePoolSize | 核心线程池大小 |
| maximumPoolSize | 最大线程池大小 |
| keepAliveTime | 线程池中超过 corePoolSize 数目的空闲线程最大存活时间 |
| TimeUnit | keepAliveTime 时间单位 |
| workQueue | 阻塞任务队列 |
| threadFactory | 新建线程工厂 |
| RejectedExecutionHandler | 拒绝策略。当提交任务数超过 maxmumPoolSize+workQueue 之和时,任务会交给RejectedExecutionHandler 来处理 |
执行过程
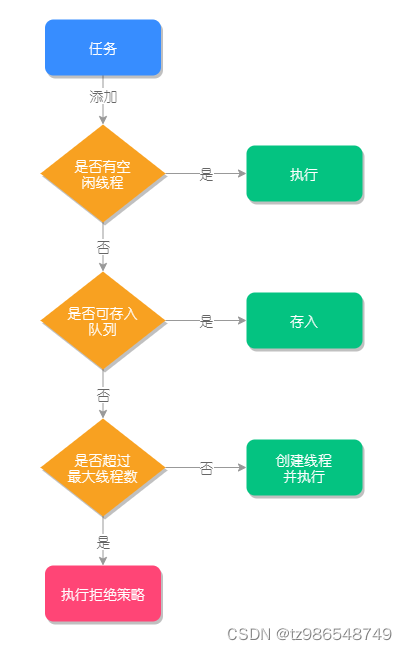
拒绝策略
| 策略名 | 描述 |
|---|---|
| AbortPolicy | 直接抛出异常,阻止系统正常运行 |
| CallerRunsPolicy | 只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。 不会造成任务丢失,同时减缓提交任务的速度,给执行任务缓冲时间。但是阻塞工作线程影响性能 |
| DiscardOldestPolicy | 丢弃最老的一个请求,也就是即将被执行的任务,并尝试再次提交当前任务。 |
| DiscardPolicy | 丢弃无法处理的任务,不予任何处理 |
Execuors问题
FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列⻓度为 Integer.MAX_VALUE,会导致OOM。
CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE,会导致OOM。
手动创建的线程池底层使用的是ArrayBlockingQueue可以防止OOM
线程池大小设置
CPU 密集型(n+1)
CPU 密集的意思是该任务需要大量的运算,而没有阻塞,CPU 一直全速运行。一般为 CPU 核数 + 1 个线程的线程池,多的一个是为了某个线程在处理缺页中断等异常时能保证所有CPU都能继续工作
IO 密集型(2*n)
由于 IO 密集型任务线程并不是一直在执行任务,可以多分配一点线程数,如 CPU * 2
也可以使用公式:CPU 核心数 *(1+平均等待时间/平均工作时间)。
JAVA容器
Collection
-
Set
TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。 -
List
ArrayList:基于动态数组实现,支持随机访问。
Vector:和 ArrayList 类似,但它是线程安全的。
LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。 -
Queue
LinkedList:可以用它来实现双向队列。
PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
Set
HashSet
HashSet是基于HashMap实现的,区别就在于在HashMap中输入一个键值对,而在HashSet中只输入一个值。value为一个常量
public HashSet()
{
// Creating internally backing HashMap object
map = new HashMap();
}
public boolean add(E e)
{
return map.put(e, PRESENT) == null;
}
Map
TreeMap
基于红黑树实现。
HashMap
HashMap
存储结构
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对,是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
插入
应该注意到链表的插入是以头插法方式进行的。
查找
查找需要分成两步进行:
计算键值对所在的桶;
在链表上顺序查找,时间复杂度显然和链表的长度成正比。
null key
HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
扩容
HashMap 采用动态扩容来降低hash冲突。
当 size 大于等于 threshold 时
loadFactor负载因子,table 能够使用的比例低于0.75时
扩容时,令 capacity 为原来的两倍。同样需要把 oldTable 的所有键值对重新插入 newTable 中,因此这一步是很费时的。
jdk1.8扩容时采用尾插法避免死循环
链表转红黑树
从 JDK 1.8 开始,一个桶存储的链表长度大于等于 8 时会将链表转换为红黑树。
HashMap和HashTable差异
Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。
Hashtable是同步(synchronized)的,适用于多线程环境,而hashmap不是同步的。
初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
扩容机制不同:当已用容量>总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 +1。
ConcurrentHashMap
ConcurrentHashMap 和 HashMap 实现上类似,最主要的差别是 ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是 Segment 的个数)。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
LinkedHashMap
LRU 缓存
以下是使用 LinkedHashMap 实现的一个 LRU 缓存:
设定最大缓存空间 MAX_ENTRIES 为 3;
使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private static final int MAX_ENTRIES = 3;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
LRUCache() {
super(MAX_ENTRIES, 0.75f, true);
}
}
WeakHashMap
WeakHashMap 的 Entry 继承自 WeakReference,被 WeakReference 关联的对象在下一次垃圾回收时会被回收。
WeakHashMap 主要用来实现缓存,通过使用 WeakHashMap 来引用缓存对象,由 JVM 对这部分缓存进行回收。
-
HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
-
LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
List
ArrayList
ArrayList 是基于数组实现的
扩容
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),即 oldCapacity+oldCapacity/2。其中 oldCapacity >> 1 需要取整,所以新容量大约是旧容量的 1.5 倍左右。(oldCapacity 为偶数就是 1.5 倍,为奇数就是 1.5 倍-0.5)
扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的。
Vector
同步
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
扩容
Vector 的构造函数可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
与 ArrayList 的比较
Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
替代方案
可以使用 Collections.synchronizedList(); 得到一个线程安全的 ArrayList。也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
CopyOnWriteArrayList
读写分离
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
写操作需要加锁,防止并发写入时导致写入数据丢失。
写操作结束之后需要把原始数组指向新的复制数组。
适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
但是 CopyOnWriteArrayList 有其缺陷:
内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
ThreadLocal
ThreadLocal意为线程本地变量,用于解决多线程并发时访问共享变量的问题。
实现
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
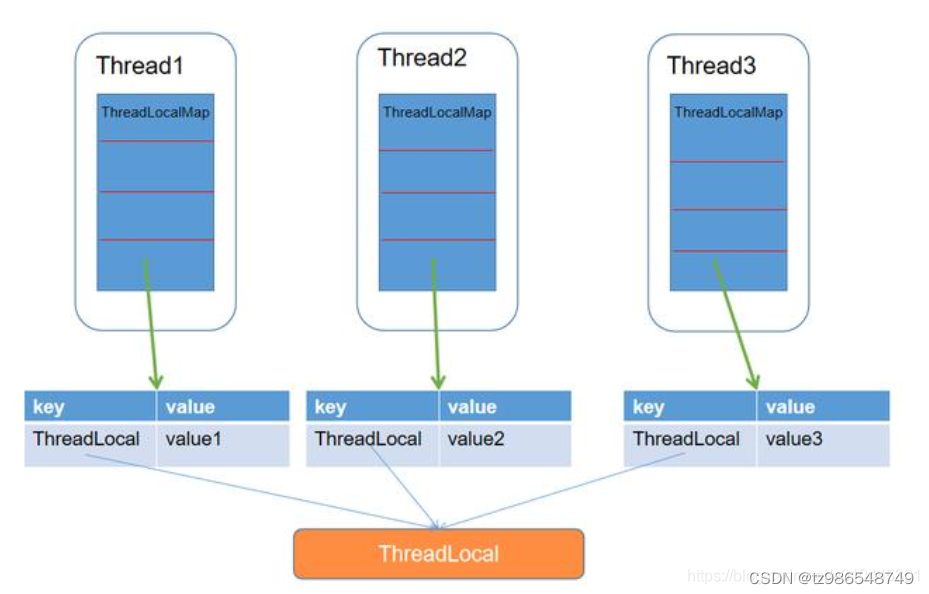
原来是通过ThreadLocal都有一个map对象,将线程作为map对象的key,要存储的变量作为map的value
JDK8之后,ThreadLocal对象中,每个Thread引用一个ThreadLocalMap对象,这个Map的key是ThreadLocal实例本身,value是存储的值要隔离的变量,是泛型
好处
每个Map存储的Entry的数量变少,在实际开发过程中,ThreadLocal的数量往往要少于Thread的数量,Entry的数量减少就可以减少哈希冲突。
当Thread销毁的时候,ThreadLocalMap也会随之销毁,减少内存使用,早期的ThreadLocal并不会自动销毁。
常用的方法
set(T value):设置线程本地变量的内容。
get():获取线程本地变量的内容。
remove():移除线程本地变量。注意在线程池的线程复用场景中在线程执行完毕时一定要调用remove,避免在线程被重新放入线程池中时被本地变量的旧状态仍然被保存。
引用
弱引用的作用:如果在业务场景中,需要设置threadLocal=null,让垃圾回收器回收掉ThreadLocal对象。
假设Entry对象中的对threadlocal是强引用的话,由于Entry对象还有一个强引用作用于ThreadLocal对象,即使设置了threadLocal=null,垃圾回收器也不会对threadLocal对象进行回收。从而造成内存泄漏。
使用ThreadLocal造成内存泄露的问题是因为:ThreadLocalMap的生命周期与Thread一致,如果不手动清除掉Entry对象的话就可能会造成内存泄露问题
事实上,在ThreadLocalMap中的set/getEntry方法中,会对key为null(也即是ThreadLocal为null)进行判断,如果为null的话,那么是会对value置为null的。
这就意味着使用完ThreadLocal,CurrentThread依然运行的前提下,就算忘记调用remove方法,弱引用比强引用可以多一层保障:弱引用的ThreadLocal会被回收,对应的value在下一次ThreadLocalMap调用set,get,remove中的任一方法的时候会被清除,从而避免内存泄漏。
value泄漏:当Entry的key=null时,由于Entry对value的强引用,导致value不会被垃圾回收器回收,所以回收ThreadLocal前,需要调用一下remove方法。
为什么不随线程结束的时候进行销毁?线程池复用场景不好处理。















 3361
3361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









