






1 HBase
1.1 HBase 架构
HBase(Hadoop DataBase),是一种非关系型分布式数据库(NoSQL),支持海量数据存储(官方:单表支持百亿行百万列)。HBase 采用经典的主从架构,底层依赖于 HDFS,并借助 ZooKeeper 作为协同服务,其架构大致如下:
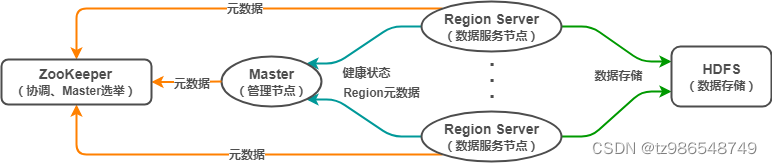
其中,
- Master:HBase 管理节点。管理 Region Server,分配 Region 到 Region
Server,提供负载均衡能力;执行创建表等 DDL 操作。 - Region Server:HBase 数据节点。管理 Region,一个
Region Server 可包含多个 Region,Region 相当于表的分区。客户端可直接与 Region Server
通信,实现数据增删改查等 DML 操作。 - ZooKeeper:协调中心。负责 Master 选举,节点协调,存储 hbase:meta
等元数据。 HDFS:底层存储系统。负责存储数据,Region 中的数据通过 HDFS 存储。
对 HBase 全局有了基本理解后,我认为有几个比较重要的点值得关注:HBase 数据模型、Region 的概念、数据路由。
1.2 HBase 数据模型
HBase 如何管理数据?(逻辑层)
HBase 的数据模型和 MySQL 等关系型数据库有比较大的区别,其是一种 ”Schema-Flexiable“ 的理念。
在表的维度,其包含若干行,每一行以 RowKey 来区分。
在行的维度,其包含若干列族,列族类似列的归类,但不只是逻辑概念,底层物理存储也是以列族来区分的(一个列族对应不同 Region 中的一个 Store)。
在列族的维度,其包含若干列,列是动态的。与其说是列,不如说是一个个键值对,Key 是列名,Value 是列值。
HBase 的表结构如下:
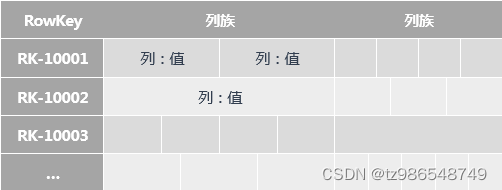
- RowKey(行键):RowKey 是字典有序的,HBase 基于 RowKey 实现索引;
- Column Family(列族):纵向切割,一行可有多个列族,一个列族可有任意个列;
- Key-Value(键值对):每一列存储的是一个键值对,Key 是列名,Value 是列值;
- Byte(数据类型):数据在 HBase 中以 Byte 存储,实际的数据类型交由用户转换;
- Version(多版本):每一列都可配置相应的版本数量,获取指定版本的数据(默认返回最新版本);
- 稀疏矩阵:行与行之间的列数可以不同,但只有实际的列才会占用存储空间。
1.3 Region
HBase 如何管理数据?(物理层)
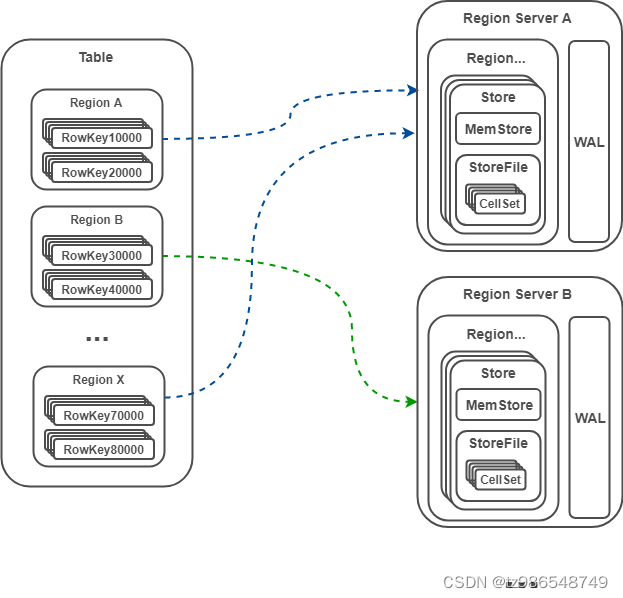
Region 是 HBase 中的概念,类似 RDBMS 中的分区。
Region 是表的横向切割,一个表由一个或多个 Region 组成,Region 被分配到各个 Region Server;
一个 Region 根据列族分为多个 Store,每个 Store 由 MemStore 和 StoreFile 组成;数据写入 MemStore,MemStore 类似输入缓冲区,持久化后为 StoreFile;数据写入的同时会更新日志 WAL,WAL 用于发生故障后的恢复,保障数据读写安全;
一个 StoreFile 对应一个 HFile,HFile 存储在 HDFS 。
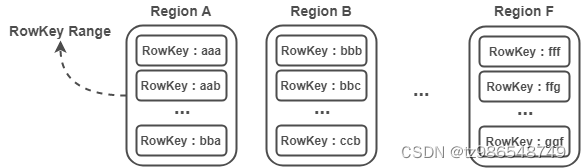
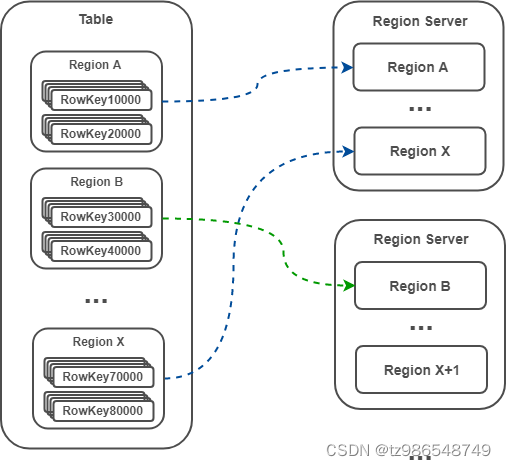
1)Region 是一个 RowKey Range
每个 Region 实际上是一个 RowKey Range,比如 Region A 存放的 RowKey 区间为 [aaa,bbb),Region B 存放的 RowKey 区间为 [bbb,ccc) ,以此类推。Region 在 Region Server 中存储也是有序的,Region A 必定在 Region B 前面。
注:这里将 RowKey 设计为 aaa,而不是 1001 这样的数字,是为了强调 RowKey 并非只能是数字,只要能进行字典排序的字符都是可以的,如:abc-123456 。
2)数据被路由到各个 Region
表由一个或多个 Region 组成(逻辑),Region Server 包含一个或多个 Region(物理)。数据的路由首先要定位数据存储在哪张表的哪个 Region,表的定位直接根据表名,Region 的定位则根据 RowKey(因为每个 Region 都是一个 RowKey Range,因此根据 RowKey 很容易知道其对应的 Region)。
注:Master 默认采用 DefaultLoadBalancer 策略分配 Region 给 Region Server,类似轮询方式,可保证每个 Region Server 拥有相同数量的 Region(这里只是 Region 的数量相同,但还是有可能出现热点聚集在某个 Region,从而导致热点聚集在某个 Region Server 的情况)。
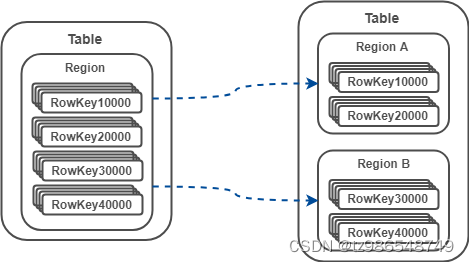
3)当一个表太大时,Region 将自动分裂
-
自动分裂
0.94 版本之前,Region 分裂策略为 ConstantSizeRegionSplitPolicy ,根据一个固定值触发分裂。
0.94 版本之后,分裂策略默认为 IncreasingToUpperBoundRegionSplitPolicy,该策略会根据 Region 数量和 StoreFile 的最大值决策。当 Region 的数量小于 9 且 StoreFile 的最大值小于某个值时,分裂 Region;当Region数量大于9 时,采用 ConstantSizeRegionSplitPolicy 。 -
手动分裂
在 ConstantSizeRegionSplitPolicy 下,通过设置 hbase.hregion.max.filesize 控制 Region 分裂。
1.4 数据路由 hbase:meta
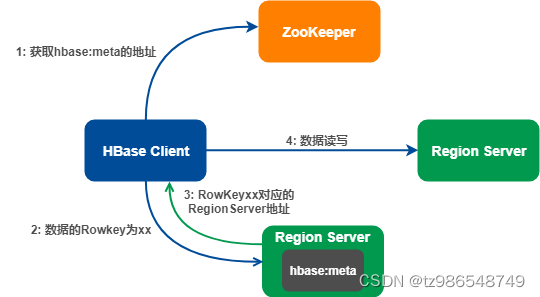
HBase 是分布式数据库,那数据怎么路由?
数据路由借助 hbase:meta 表完成,hbase:meta 记录的是所有 Region 的元数据信息,hbase:meta 的位置记录在 ZooKeeper 。
注:一些比较老的帖子可能会提到 .root 和 .meta 两个表。事实上, .root 和 .meta 两个表是 HBase 0.96 版本之前的设计。在 0.96 版本后,.root 表已经被移除,.meta 表更名为 hbase:meta。
hbase:meta 表的格式如下:

其中,
table:表名;
region start key:Region 中的第一个 RowKey,如果 region start key 为空,表示该 Region 是第一个 Region;
region id:Region 的 ID,通常是 Region 创建时的 timestamp;
regioninfo:该 Region 的 HRegionInfo 的序列化值;
server:该 Region 所在的 Region Server 的地址;
serverstartcode:该 Region 所在的 Region Server 的启动时间。
一条数据的写入流程:
数据写入时需要指定表名、Rowkey、数据内容。
- HBase 客户端访问 ZooKeeper,获取 hbase:meta 的地址,并缓存该地址;
- 访问相应 Region Server 的hbase:meta;
- 从 hbase:meta 表获取 RowKey 对应的 Region Server 地址,并缓存该地址;
- HBase 客户端根据地址直接请求 Region Server 完成数据读写。
注 1:数据路由并不涉及Master,也就是说 DML 操作不需要 Master 参与。借助 hbase:meta,客户端直接与 Region Server 通信,完成数据路由、读写。
注 2:客户端获取 hbase:meta 地址后,会缓存该地址信息,以此减少对 ZooKeeper 的访问。同时,客户端根据 RowKey 查找 hbase:meta,获取对应的 Region Server 地址后,也会缓存该地址,以此减少对 hbase:meta 的访问。因为 hbase:meta 是存放在 Region Server 的一张表,其大小可能很大,因此不会缓存 hbase:meta 的完整内容。
1.5 HBase 适用场景
- 不需要复杂查询的应用。HBase 原生只支持基于 RowKey 的索引,对于某些复杂查询(如模糊查询,多字段查询),HBase可能需要全表扫描来获取结果。
- 写密集应用。HBase 是一个写快读慢(慢是相对的)的系统。HBase 是根据 Google 的BigTable 设计的,典型应用就是不断插入新数据(如 Google 的网页信息)。
- 对事务要求不高的应用。HBase 只支持基于RowKey 的事务。
- 对性能、可靠性要求高的应用。HBase 不存在单点故障,可用性高。 数据量特别大的应用。HBase支持百亿行百万列的数据量,单个 Region 过大将自动触发分裂,具备较好的伸缩能力。
2 HBase 与 MySQL 的区别?
2.1 MySQL
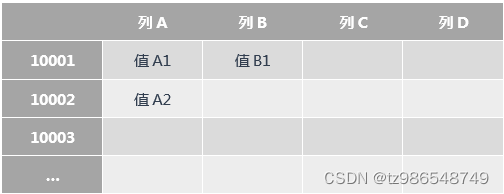
MySQL 表结构规整,每一行有固定的列。
创建表时,需要指定表名,预设字段(列)个数以及数据类型,Schema 是固定的。
插入数据时,只需根据表的 Schema 填充每个列的值即可。如果 Schema 没有该列,则无法插入。
2.2 HBase
HBase 支持动态列,不同行可拥有不同数量的列,可动态增加新的列。HBase 的表结构看起来杂乱无章,但却有利于存储稀疏数据。
创建表时,需指定表名、列族,无需指定列的个数、数据类型,Schema 是灵活的。
插入数据时,需要指定表名、列族、RowKey、若干个列(列名和列值),这里列的个数可以是一个或多个。
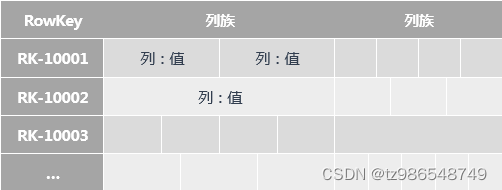
2.3 对比
进一步,假设 ct_account_info_demo 表中只有一条记录(account_id=1,account_owner=Owner1,account_amount=23.0,is_deleted=n),分别通过 MySQL 、HBase 查找该记录。
MySQL 返回的结果:
mysql> select * from ct_account_info_demo;
±-----------±--------------±---------------±-----------+
| account_id | account_owner | account_amount | is_deleted |
±-----------±--------------±---------------±-----------+
| 1 | Owner1 | 23.0 | n |
±-----------±--------------±---------------±-----------+
1 rows in set (0.01 sec)
HBase 返回的结果:
hbase(main):001:0> scan ‘ct_account_info_demo’;
ROW COLUMN+CELL
1 column=CT:account_amount, timestamp=1532502487735, value=23.0
1 column=CT:account_id, timestamp=1532909576152, value=1
1 column=CT:account_owner, timestamp=1532502487528, value=Owner1
1 column=CT:is_deleted, timestamp=1532909576152, value=n
上述结果都表示一行数据,MySQL 的返回结果比较直观,容易理解。
HBase 返回的结果其实是多个键值对,ROW 表示数据的 RowKey,COLUMN+CELL 表示该 RowKey 对应的内容。
COLUMN+CELL 中又是多个键值对,如:
column=CT:account_amount, timestamp=1532502487735, value=23.0
表示列族 CT 的列 account_amount 的值为 23.0,时间戳为 1532502487735 。
注:ROW 为 1 是因为这里 RowKey = {account_id},CT 是提前定义的列族(HBase 在插入数据时需要指定 RowKey、Column Family)。
总的来说,
HBase 比 MySQL 多了 RowKey 和 Column Family 的概念,这里的 RowKey 类似 MySQL 中的主键,Column Family 相当于多个列的“归类”。
列族只有一个的情况下,HBase 的 Schema 和 MySQL 可以保持一致,但 HBase 允许某些字段为空或动态增加某个列,而 MySQL 只可根据 Schema 填充相应的列,不能动态增减列。
因为 HBase 的 Schema 是不固定的,所以每次插入、查找数据不像 MySQL 那么简洁,HBase 需要指定行键、列族、列等信息。
更为详细的对比如下表:
| RDBMS | HBase | |
|---|---|---|
| 硬件架构 | 传统的多核系统,硬件成本昂贵 | 类似于 Hadoop 的分布式集群,硬件成本低廉 |
| 容错性 | 一般需要额外硬件设备实现 HA 机制 | 由软件架构实现,因为多节点,所以不担心单点故障 |
| 数据库大小 | GB、TB | PB |
| 数据排布 | 以行和列组织 | 稀疏的、分布的多维的 Map |
| 数据类型 | 丰富的数据类型 | Bytes |
| 事务支持 | 全面的 ACID 支持,对 Row 和表 | ACID 只支持单个 Row 级别 |
| 查询语言 | SQL | 只支持 Java API (除非与其他框架一起使用,如 Phoenix、Hive) |
| 索引 | 支持 | 只支持 Row-key(除非与其他技术一起应用,如 Phoenix、Hive) |
| 吞吐量 | 数千查询/每秒 | 百万查询/每秒 |
3 HBase为什么写比读快
3.1、LSM树
LSM树结构
LSM树的核心特点是利用顺序写来提高写性能,但因为分层(此处分层是指的分为内存和文件两部分)的设计会稍微降低读性能,但是通过牺牲小部分读性能换来高性能写,使得LSM树成为非常流行的存储结构。
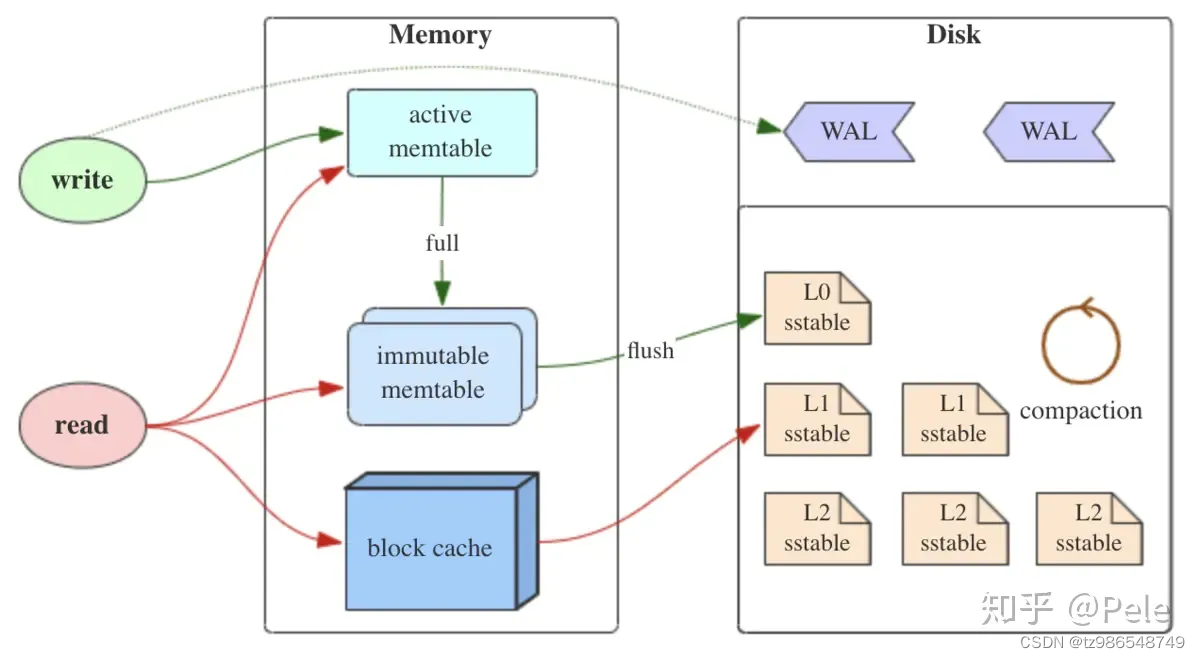
LSM树有以下三个重要组成部分:
- MemTable
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
- Immutable MemTable
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
- SSTable(Sorted String Table)
有序键值对集合,是LSM树组在磁盘中的数据结构。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。

这里需要关注一个重点,LSM树(Log-Structured-Merge-Tree)正如它的名字一样,LSM树会将所有的数据插入、修改、删除等操作记录(注意是操作记录)保存在内存之中,当此类操作达到一定的数据量后,再批量地顺序写入到磁盘当中。这与B+树不同,B+树数据的更新会直接在原数据所在处修改对应的值,但是LSM数的数据更新是日志式的,当一条数据更新是直接append一条更新记录完成的。这样设计的目的就是为了顺序写,不断地将Immutable MemTable flush到持久化存储即可,而不用去修改之前的SSTable中的key,保证了顺序写。
因此当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
1)冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。
2)读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。
LSM树的Compact策略
从上面可以看出,Compact操作是十分关键的操作,否则SSTable数量会不断膨胀。在Compact策略上,主要介绍两种基本策略:size-tiered和leveled。
不过在介绍这两种策略之前,先介绍三个比较重要的概念,事实上不同的策略就是围绕这三个概念之间做出权衡和取舍。
1)读放大:读取数据时实际读取的数据量大于真正的数据量。例如在LSM树中需要先在MemTable查看当前key是否存在,不存在继续从SSTable中寻找。
2)写放大:写入数据时实际写入的数据量大于真正的数据量。例如在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。
3)空间放大:数据实际占用的磁盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key来说,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的。
size-tiered 策略
size-tiered策略保证每层SSTable的大小相近,同时限制每一层SSTable的数量。每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层成为一个更大的sstable。
由此可以看出,当层数达到一定数量时,最底层的单个SSTable的大小会变得非常大。并且size-tiered策略会导致空间放大比较严重。即使对于同一层的SSTable,每个key的记录是可能存在多份的,只有当该层的SSTable执行compact操作才会消除这些key的冗余记录。
leveled策略
leveled策略也是采用分层的思想,每一层限制总文件的大小。
但是跟size-tiered策略不同的是,leveled会将每一层切分成多个大小相近的SSTable。这些SSTable是这一层是全局有序的,意味着一个key在每一层至多只有1条记录,不存在冗余记录。之所以可以保证全局有序,是因为合并策略和size-tiered不同,接下来会详细提到。
当某一Level的容量超过阈值时,从中选取至少一个文件与下层相关文件进行compact,合并放到下一层,如果下一层容量超限则继续往下合并,直到存储完成。多个不相干的合并是可以并发进行的。
leveled策略相较于size-tiered策略来说,每层内key是不会重复的,即使是最坏的情况,除开最底层外,其余层都是重复key,按照相邻层大小比例为10来算,冗余占比也很小。因此空间放大问题得到缓解。但是写放大问题会更加突出。举一个最坏场景,如果LevelN层某个SSTable的key的范围跨度非常大,覆盖了LevelN+1层所有key的范围,那么进行Compact时将涉及LevelN+1层的全部数据。














 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









