







____tz_zs
- nltk文档:http://www.nltk.org/
- nltk github:https://github.com/nltk/nltk
- 《Natural Language Processing with Python》(需翻墙):http://www.nltk.org/book/
Natural Language Toolkit,自然语言处理工具包
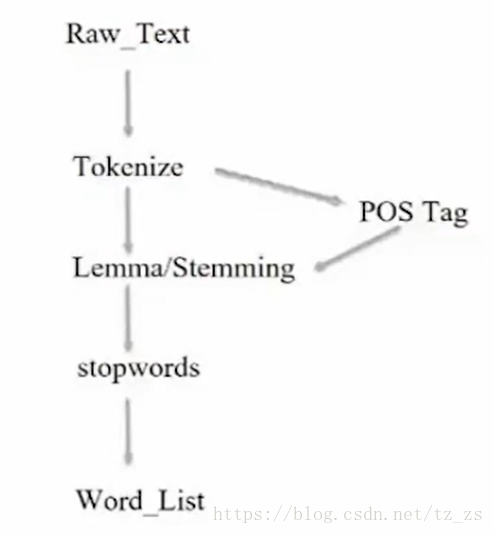
文本预处理流程
·
·
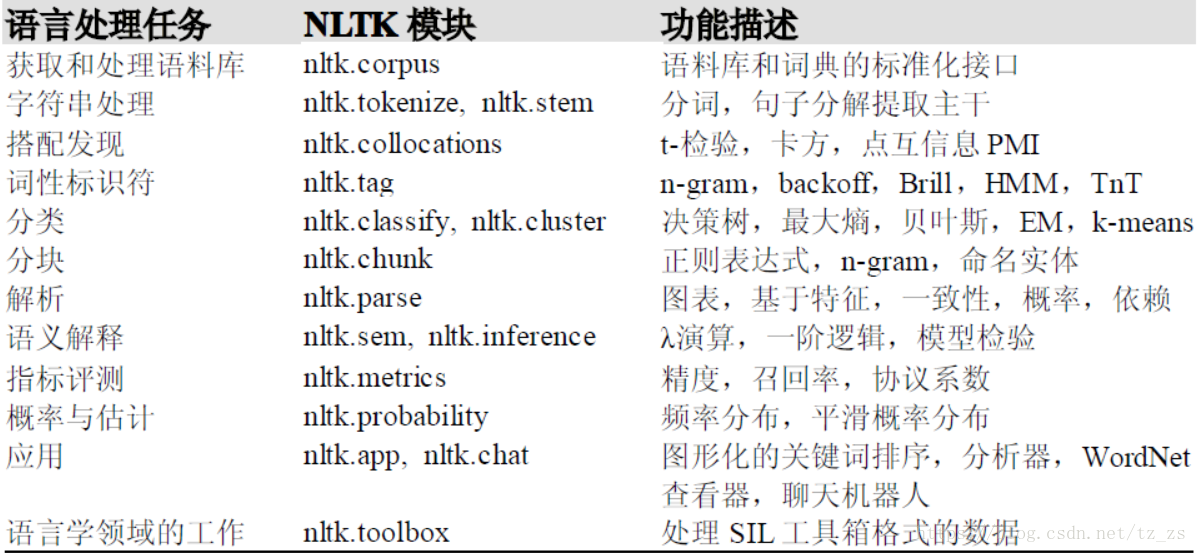
NLTK 模块
NLTK 的一些最重要的模块:
·
# Installing NLTK Data
# 首次安装好nltk时,需要运行 nltk.download() 下载扩展包
# https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
# 保存在 C:\Users\wang\AppData\Roaming\nltk_data 文件夹
nltk.download()·
语料库 nltk.corpus
在nltk.corpus包下,提供了几类标注好的语料库。见下表:
| 语料库 | 说明 |
|---|---|
| gutenberg | 一个有若干万部的小说语料库,多是古典作品 |
| webtext | 收集的网络广告等内容 |
| nps_chat | 有上万条聊天消息语料库,即时聊天消息为主 |
| brown | 一个百万词级的英语语料库,按文体进行分类 |
| reuters | 路透社语料库,上万篇新闻方档,约有1百万字,分90个主题,并分为训练集和测试集两组 |
| inaugural | 演讲语料库,几十个文本,都是总统演说 |
·
语料库提供的方法
print(brown.categories()) # 语料库中的所有的类别
'''
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore',
'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
'''·
| 方法名 | 说明 |
|---|---|
fileids() | 返回语料库中文件名列表 |
| fileids(catergories=[c1,c2]) | 返回指定类别的文件名列表 |
| raw(fileids=[f1,f2]) | 返回指定文件名的文本字符串 |
| raw(catergories=[c1,c2]) | 返回指定分类的原始文本 |
| sents(fileids=[f1,f2]) | 返回指定文件名的语句列表 |
| sents(catergories=[c1,c2]) | 按分类返回语句列表 |
| words(fileids=[f1,f2]) | 返回指定文件名的单词列表 |
| words(categories=[c1,c2]) | 返回指定分类的单词列表 |
·
# -*- coding: utf-8 -*-
"""
@author: tz_zs
语料库
"""
from nltk.corpus import brown
import nltk
# brown 布朗大学的语料库
print(brown.categories()) # 语料库中的所有的类别
'''
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore',
'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
'''
print(brown.fileids()) # 语料库中的所有文件名
print(brown.fileids(categories=['adventure', 'belles_lettres'])) # 返回指定类别的文件名列表
print(brown.words()) # 语料库中的所有单词列表
print(brown.words(categories='news')) # 返回指定类别的单词列表
print(brown.words(fileids=['ca01'])) # 返回指定文件中的单词列表
'''
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
'''
print(brown.sents()) # 语料库中的句子
'''
[['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', 'Friday', 'an', 'investigation', 'of', "Atlanta's", 'recent',
'primary', 'election', 'produced', '``', 'no', 'evidence', "''", 'that', 'any', 'irregularities', 'took', 'place', '.'],
['The', 'jury', 'further', 'said', 'in', 'term-end', 'presentments', 'that', 'the', 'City', 'Executive',
'Committee', ',', 'which', 'had', 'over-all', 'charge', 'of', 'the', 'election', ',', '``', 'deserves', 'the',
'praise', 'and', 'thanks', 'of', 'the', 'City', 'of', 'Atlanta', "''", 'for', 'the', 'manner', 'in', 'which', 'the',
'election', 'was', 'conducted', '.'], ...]
'''
print(brown.tagged_words()) # 标记了词性的所有单词列表,同样,可指定类别和文件名
'''
[('The', 'AT'), ('Fulton', 'NP-TL'), ...]
'''·
词频统计、停用词
·
FreqDist 这个类对每个词计数。查看 Python 源码可知,他是 dict 的子类(Counter)的子类,其结构内部是用一个有序词典(OrderedDict)实现的。dict 拥有的方法 FreqDist 类也能使用。
B() 返回词典的长度
plot(title,cumulative=False) 绘制频率分布图,若cumu为True,则是累积频率分布图
tabulate() 生成频率分布的表格形式
most_common() 返回出现次数最频繁的词与频度
hapaxes() 返回只出现过一次的词
nltk语料库 corpus 下自带了一个停用词库 stopword。
·
# -*- coding: utf-8 -*-
"""
@author: tz_zs
词频统计 停用词
"""
import urllib.request
from bs4 import BeautifulSoup
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
# 使用BeautifulSoup模块清理掉HTML标签,得到干净的文本
soup = BeautifulSoup(html, 'html5lib')
text = soup.get_text(strip=True)
# 将文本转换为tokens
tokens = text.split()
# 使用Python NLTK统计token的频率分布
freq = nltk.FreqDist(tokens)
# for k, v in freq.items():
# print(str(k), ":", str(v))
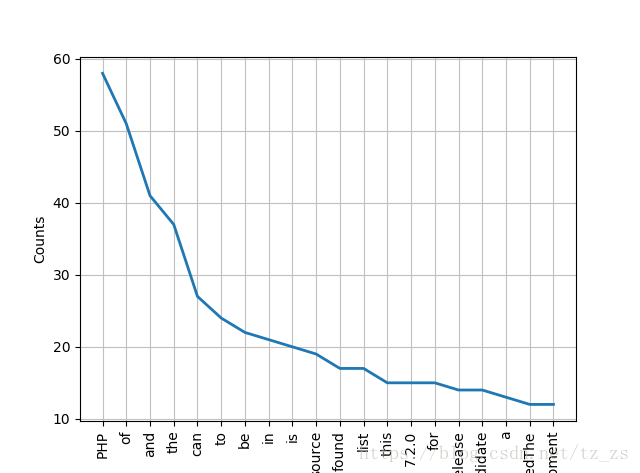
freq.plot(20, cumulative=False) # 频率分布图,需要安装matplotlib库
# 处理停用词(如of,a,an等等,这些词都属于停用词)
clean_tokens = list()
sr = stopwords.words('english') # NLTK语料库自带的停用词列表
print(sr)
'''
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your',
'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it',
"it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this',
'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had',
'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until',
'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before',
'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further',
'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most',
'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can',
'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren',
"aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven',
"haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't",
'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
'''
for token in tokens:
if token not in sr:
clean_tokens.append(token)
# clean_tokens2 = [token for token in tokens if token not in sr]
freq_dist = nltk.FreqDist(clean_tokens)
# for k, v in freq_dist.items():
# print(str(k), ":", str(v))
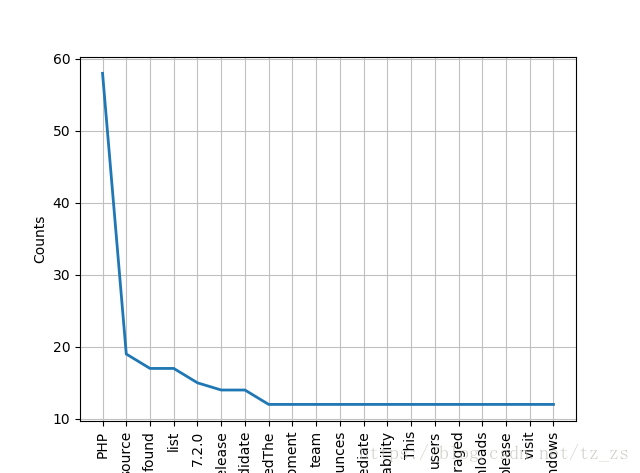
freq_dist.plot(20, cumulative=False)
freq_dist_most_common = freq_dist.most_common(5)
print(freq_dist_most_common) # 以list形式返回频率最高的n个,key、value以元组形式
'''
[('PHP', 58), ('source', 19), ('found', 17), ('list', 17), ('7.2.0', 15)]
'''
·
·
·
tokenize文本
- 句子tokenizer:sent_tokenize
- 单词tokenizer:word_tokenize
·
# -*- coding: utf-8 -*-
"""
@author: tz_zs
tokenize文本
句子tokenizer:sent_tokenize
单词tokenizer:word_tokenize
Tokenize时可以指定语言
"""
from nltk.tokenize import sent_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
tokens1 = sent_tokenize(mytext)
# tokens1 = sent_tokenize(mytext, language='english')
print(tokens1)
'''
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
'''
from nltk.tokenize import word_tokenize
tokens2 = word_tokenize(mytext)
print(tokens2)
'''
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going',
'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']
'''
·
同义词、反义词
·
# -*- coding: utf-8 -*-
"""
@author: tz_zs
WordNet是一个为自然语言处理而建立的数据库。它包括一些同义词组和一些简短的定义。
同义词、反义词
wordnet.synsets()
"""
from nltk.corpus import wordnet
syn = wordnet.synsets('pain')
print(syn[0].definition())
print(syn[0].examples())
'''
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']
'''
# 获取同义词
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)
'''
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer',
'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
'''
# 获取反义词
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)
'''
['large', 'big', 'big']
'''
·
词干提取、单词变体还原
- 词干提取 Stemmer
- 单词变体还原 Lemmatizer
对于提取词词干,提供了Porter和Lancaster两个stemer。另个还提供了一个WordNetLemmatizer做词形归并。Stem通常基于语法规则使用正则表达式来实现,处理的范围广,但过于死板。而Lemmatizer实现采用基于词典的方式来解决,因而更慢一些,处理的范围和词典的大小有关。
·
# -*- coding: utf-8 -*-
"""
@author: tz_zs
词干提取
Stemmer
语言形态学和信息检索里,词干提取是去除词缀得到词根的过程,例如working的词干为work。
单词变体还原
Lemmatizer
"""
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('working'))
print(stemmer.stem('worked'))
'''
work
work
'''
from nltk.stem import SnowballStemmer
# 其他语言的词干提取
snowball_stemmer = SnowballStemmer('french') # 法语
print(snowball_stemmer.stem('français'))
# SnowballStemmer支持的语言
print(SnowballStemmer.languages)
'''
franc
('danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian',
'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish')
'''
# 单词变体还原
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('dogs'))
'''
dog
'''
# 有时候将一个单词做变体还原时,总是得到相同的词。
print(lemmatizer.lemmatize('are'))
print(lemmatizer.lemmatize('is'))
'''
are
is
'''
# 这是因为默认是当作名词。可以指定为动词(v)、名词(n)、形容词(a)或副词(r)
print(lemmatizer.lemmatize('playing', pos='v'))
print(lemmatizer.lemmatize('are', pos='v'))
print(lemmatizer.lemmatize('is', pos='v'))
'''
play
be
be
'''
·
词性标注 POS Tag (Part-of-speech tagging)
词性标注 POS Tag (Part-of-speech tagging)
是一种分析句子成分的方法,通过它来识别每个词的词性。
主要是用于标注词在文本中的成分。
参考文章:
·
# -*- coding: utf-8 -*-
"""
@author: tz_zs
词性标注 POS Tag (Part-of-speech tagging)
是一种分析句子成分的方法,通过它来识别每个词的词性。
"""
import nltk
from nltk.corpus import brown
sentence = "At eight o'clock on Thursday morning Arthur didn't feel very good."
tokens = nltk.word_tokenize(sentence)
tag = nltk.pos_tag(tokens)
print(tag)
'''
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'NN'), ('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
('Arthur', 'NNP'), ('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'), ('very', 'RB'), ('good', 'JJ'), ('.', '.')]
'''
# 查看文档
nltk.help.upenn_tagset()
"""
$ -$ --$ A$ C$ HK$ M$ NZ$ S$ U.S.$ US$
'': closing quotation mark
' ''
(: opening parenthesis
( [ {
): closing parenthesis
) ] }
,: comma
,
--: dash
--
.: sentence terminator
. ! ?
:: colon or ellipsis
: ; ...
CC: conjunction, coordinating
& 'n and both but either et for less minus neither nor or plus so
therefore times v. versus vs. whether yet
CD: numeral, cardinal
mid-1890 nine-thirty forty-two one-tenth ten million 0.5 one forty-
seven 1987 twenty '79 zero two 78-degrees eighty-four IX '60s .025
fifteen 271,124 dozen quintillion DM2,000 ...
DT: determiner
all an another any both del each either every half la many much nary
neither no some such that the them these this those
EX: existential there
there
FW: foreign word
gemeinschaft hund ich jeux habeas Haementeria Herr K'ang-si vous
lutihaw alai je jour objets salutaris fille quibusdam pas trop Monte
terram fiche oui corporis ...
IN: preposition or conjunction, subordinating
astride among uppon whether out inside pro despite on by throughout
below within for towards near behind atop around if like until below
next into if beside ...
JJ: adjective or numeral, ordinal
third ill-mannered pre-war regrettable oiled calamitous first separable
ectoplasmic battery-powered participatory fourth still-to-be-named
multilingual multi-disciplinary ...
JJR: adjective, comparative
bleaker braver breezier briefer brighter brisker broader bumper busier
calmer cheaper choosier cleaner clearer closer colder commoner costlier
cozier creamier crunchier cuter ...
JJS: adjective, superlative
calmest cheapest choicest classiest cleanest clearest closest commonest
corniest costliest crassest creepiest crudest cutest darkest deadliest
dearest deepest densest dinkiest ...
LS: list item marker
A A. B B. C C. D E F First G H I J K One SP-44001 SP-44002 SP-44005
SP-44007 Second Third Three Two * a b c d first five four one six three
two
MD: modal auxiliary
can cannot could couldn't dare may might must need ought shall should
shouldn't will would
NN: noun, common, singular or mass
common-carrier cabbage knuckle-duster Casino afghan shed thermostat
investment slide humour falloff slick wind hyena override subhumanity
machinist ...
NNP: noun, proper, singular
Motown Venneboerger Czestochwa Ranzer Conchita Trumplane Christos
Oceanside Escobar Kreisler Sawyer Cougar Yvette Ervin ODI Darryl CTCA
Shannon A.K.C. Meltex Liverpool ...
NNPS: noun, proper, plural
Americans Americas Amharas Amityvilles Amusements Anarcho-Syndicalists
Andalusians Andes Andruses Angels Animals Anthony Antilles Antiques
Apache Apaches Apocrypha ...
NNS: noun, common, plural
undergraduates scotches bric-a-brac products bodyguards facets coasts
divestitures storehouses designs clubs fragrances averages
subjectivists apprehensions muses factory-jobs ...
PDT: pre-determiner
all both half many quite such sure this
POS: genitive marker
' 's
PRP: pronoun, personal
hers herself him himself hisself it itself me myself one oneself ours
ourselves ownself self she thee theirs them themselves they thou thy us
PRP$: pronoun, possessive
her his mine my our ours their thy your
RB: adverb
occasionally unabatingly maddeningly adventurously professedly
stirringly prominently technologically magisterially predominately
swiftly fiscally pitilessly ...
RBR: adverb, comparative
further gloomier grander graver greater grimmer harder harsher
healthier heavier higher however larger later leaner lengthier less-
perfectly lesser lonelier longer louder lower more ...
RBS: adverb, superlative
best biggest bluntest earliest farthest first furthest hardest
heartiest highest largest least less most nearest second tightest worst
RP: particle
aboard about across along apart around aside at away back before behind
by crop down ever fast for forth from go high i.e. in into just later
low more off on open out over per pie raising start teeth that through
under unto up up-pp upon whole with you
SYM: symbol
% & ' '' ''. ) ). * + ,. < = > @ A[fj] U.S U.S.S.R * ** ***
TO: "to" as preposition or infinitive marker
to
UH: interjection
Goodbye Goody Gosh Wow Jeepers Jee-sus Hubba Hey Kee-reist Oops amen
huh howdy uh dammit whammo shucks heck anyways whodunnit honey golly
man baby diddle hush sonuvabitch ...
VB: verb, base form
ask assemble assess assign assume atone attention avoid bake balkanize
bank begin behold believe bend benefit bevel beware bless boil bomb
boost brace break bring broil brush build ...
VBD: verb, past tense
dipped pleaded swiped regummed soaked tidied convened halted registered
cushioned exacted snubbed strode aimed adopted belied figgered
speculated wore appreciated contemplated ...
VBG: verb, present participle or gerund
telegraphing stirring focusing angering judging stalling lactating
hankerin' alleging veering capping approaching traveling besieging
encrypting interrupting erasing wincing ...
VBN: verb, past participle
multihulled dilapidated aerosolized chaired languished panelized used
experimented flourished imitated reunifed factored condensed sheared
unsettled primed dubbed desired ...
VBP: verb, present tense, not 3rd person singular
predominate wrap resort sue twist spill cure lengthen brush terminate
appear tend stray glisten obtain comprise detest tease attract
emphasize mold postpone sever return wag ...
VBZ: verb, present tense, 3rd person singular
bases reconstructs marks mixes displeases seals carps weaves snatches
slumps stretches authorizes smolders pictures emerges stockpiles
seduces fizzes uses bolsters slaps speaks pleads ...
WDT: WH-determiner
that what whatever which whichever
WP: WH-pronoun
that what whatever whatsoever which who whom whosoever
WP$: WH-pronoun, possessive
whose
WRB: Wh-adverb
how however whence whenever where whereby whereever wherein whereof why
``: opening quotation mark
` ``
"""
·
参考文章:

















 6884
6884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









