






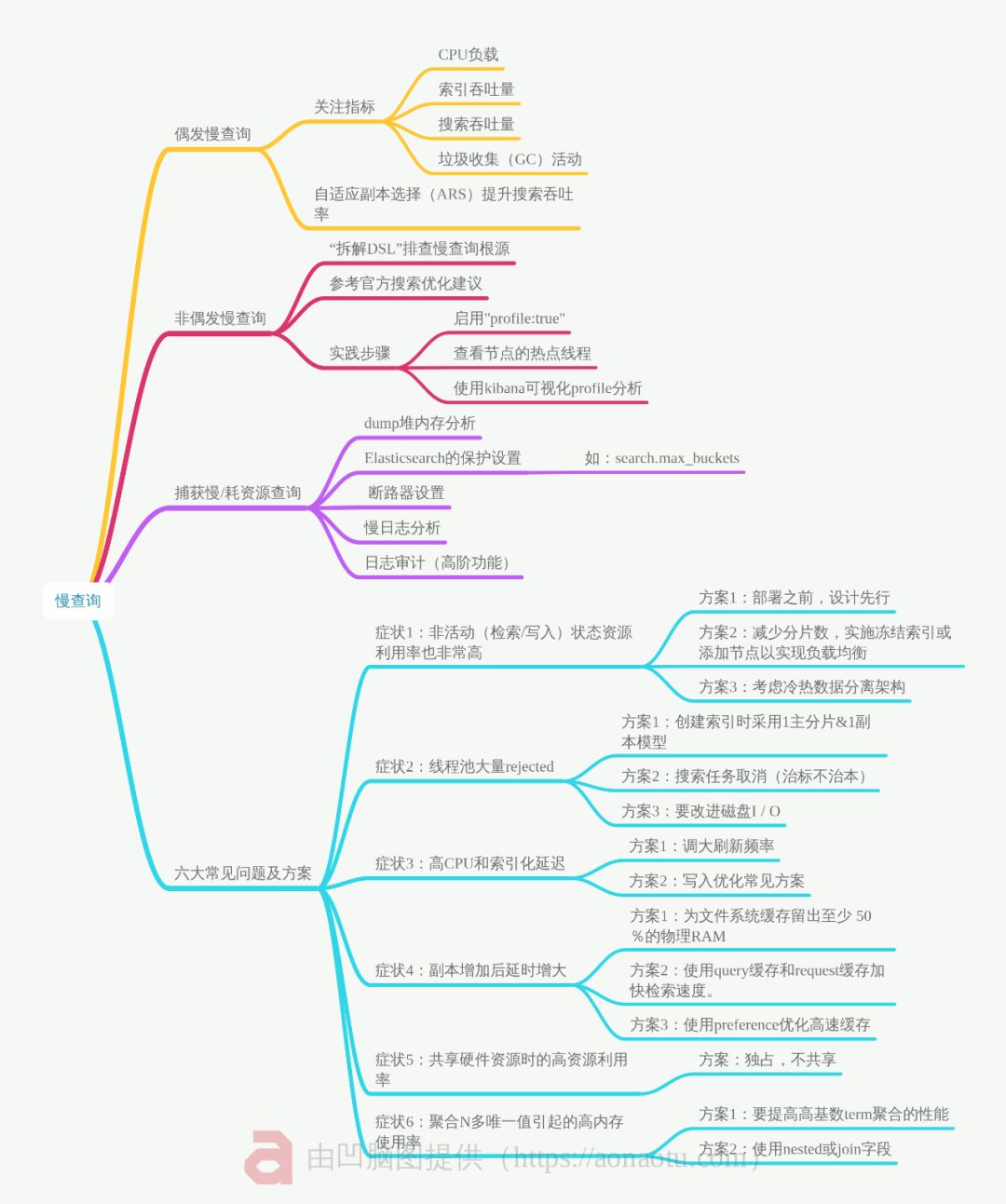
1、引言
Elasticsearch是非常灵活且功能丰富的搜索引擎,它提供了许多不同查询数据的方法。在实战业务场景中,经常会出现远远低于预期查询速度的慢查询。作为分布式系统的Elasticsearch,可能有各种影响查询性能的因素,包括外部因素,如负载均衡设置,网络延迟(带宽,NIC卡/驱动程序)等。
本文主要讨论可能导致慢查询的原因以及如何在Elasticsearch的上下文中识别它们?
本文主要源于常见慢查询故障的排除方法,阅读本文的前提需要你对Elasticsearch的原理有大致的了解。
如果不了解Elastic相关原理,可以移步:elastic.blog.csdn.net 或 历史文章。
如果不了解慢查询,可以移步:为什么Elasticsearch查询变得这么慢了?
本文的目的:根治慢查询。
2、Elasticsearch慢查询六大症状及解决方案
在我们研究一些棘手的案例之前,让我们从一些最常见的慢查询及其解决方案开始。
2.1 症状1:非活动(检索/写入)状态资源利用率也非常高
症状详情:每个分片都消耗资源(CPU /内存)。即使没有索引/搜索请求,分片的存在也会消耗集群开销。
2.1.1 问题描述
集群中的分片太多,以至于任何查询执行起来都很慢。一个好的经验法则——确保每个节点的非冻结分片数量保持在:20以下/每GB堆内存。
2.1.2 解决方案
1、部署之前,设计先行。
正如VIVO搜索技术总监振涛兄所说:“集群规划核心是容量预估,就好比你建个楼,必须规划好容量,不然说用多少就建多高,吃在地基撑不住!!”。任何部署的良好开端都是执行适当的容量规划,以帮助确定每个搜索用例的最佳分片数。
2、减少分片数,实施冻结索引或添加其他节点以实现负载均衡。
3、考虑冷热数据分离架构(适用于基于时间的索引)以及Elasticsearch中的翻转索引(rollover)/压缩索引(shrink)功能,以有效管理分片计数。
推荐阅读:我在 Elasticsearch 集群内应该设置多少个分片?
https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
Elasticsearch5.x冷热架构实现
https://www.elastic.co/cn/blog/hot-warm-architecture-in-elasticsearch-5-x
容量规划最佳实践(必读)
https://www.elastic.co/guide/en/elasticsearch/guide/master/capacity-planning.html
2.2 症状2:线程池存在大量rejected
搜索线程池显示“拒绝”计数的持续增加,该计数基于上次群集重新启动而累积。
1GET / _cat / thread_pool / search?v&h = node_name,name,active,rejected,completed
响应如下:
1node_name name active rejected completed
2instance-0000000001 search 0 10 0
3instance-0000000002 search 0 20 0
4instance-0000000003 search 0 30 0
2.2.1 问题描述
场景1:查询的目标是太多分片,超过集群中的CPU核数。这会在搜索线程池中创建排队任务,从而导致搜索拒绝。
场景2:磁盘I/O速度慢或在某些情况下完全饱和的CPU导致搜索排队。
2.2.2 解决方案
1、创建索引时采用1主分片&1副本模型。
使用索引模板是在创建索引阶段做好设置是个好方法。(7.0及更高版本默认1主1副)。
2、 Elasticsearch 5.1或更高版本支持搜索任务取消,这对于取消显示在任务管理API中慢查询任务非常有用。
任务管理:
1GET _tasks?nodes=nodeId1,nodeId2
取消任务
1POST _tasks/oTUltX4IQMOUUVeiohTt8A:12345/_cancel
3、要改进磁盘I / O,请查看我们的存储建议,并确保使用推荐的硬件以获得最佳性能。
存储优化建议:
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/tune-for-indexing-speed.html#_use_faster_hardware
2.3 症状3:高CPU和索引化延迟
当集群不堪重负时,度量标准关联显示CPU利用率高和索引化延迟大(如下图)。

Metric指标Kibana核查方法:
https://www.elastic.co/guide/en/kibana/7.0/elasticsearch-metrics.html
2.3.1 问题描述
写入数据量大(索引化)会影响搜索性能。
2.3.2 解决方案
1、调大刷新频率
将index.refresh_ interval(文档被索引到数据搜索可见时间间隔)增加到 30 s,通常有助于提高索引性能。
实战中要结合具体业务场景,可能会有所不同,因此测试是关键。这样避免了缺省一秒生成一个分段的麻烦。
2、对于重型索引用例,请检查我们的索引调整建议,以优化索引和搜索性能。
包含但不限于:
1)数据初始化阶段refresh设置 -1、副本设置为 0,以提升写入速度;写入完毕后复原。
2)关闭swapping。
3)使用文件系统缓存。
4)使用自动生成ID。
性能调优实践:
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/tune-for-indexing-speed.html#_disable_refresh_and_replicas_for_initial_loads
2.4 症状4:副本增加后延时增大
在增加副本分片计数(例如,从1到2)之后可以观察到查询等待时间。如果存在更多数据,则缓存的数据将很快被逐出,导致操作系统层面页面错误增加。
2.4.1 问题描述
文件系统缓存没有足够的内存来缓存经常查询的索引部分。
Elasticsearch的查询缓存实现了LRU置换算法:当缓存变满时,最近最少使用的数据被置换以便为新数据腾出空间。
请求缓存:
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/query-cache.html
2.4.2 解决方案
1、为文件系统缓存留出至少 50 %的物理RAM。
内存越多,可以缓存的越多,尤其是在集群遇到I / O问题时。假设堆大小已正确配置,剩下的任何可用于文件系统缓存的剩余物理RAM都可以大大加快搜索性能。
堆内存大小配置建议:Min(32 GB,物理机器内存 / 2)。
例如,128 GB内存服务器为堆提供 30GB空间,为文件系统缓存(有时称为OS缓存)留出剩余内存,假设操作系统缓存最近访问的4KB数据块,如果你再一次读取相同的文件,不需要花很长时间去磁盘上读,直接在内存上读来的更快。
2、使用query缓存和request缓存加快检索速度。
节点级别的query缓存默认是开启的。对应配置:
1index.queries.cache.enabled
请求缓存默认是开启的,如果被强制关闭了,可以动态设置开启。
1PUT /my_index/_settings
2{ "index.requests.cache.enable": true }
3、使用preference优化高速缓存
可以使用搜索请求首选项preference来优化所有这些高速缓存。以便每次将某些搜索请求路由到同一组分片,而不是在可用的不同副本之间交替。
这将更好地利用请求缓存、节点查询缓存和文件系统缓存。
2.5 症状5:共享硬件资源时的高资源利用率。
操作系统显示始终较高的CPU 、磁盘、I / O使用率。
停止第三方应用程序后可以看到性能提升。
2.5.1 问题描述
其他进程(例如Logstash)和Elasticsearch本身之间存在资源(CPU、内存、或磁盘I / O)争用。
2.5.2 解决方案
给Elasticsearch隔离的硬件环境或虚拟环境。
避免在共享硬件上与其他资源密集型应用程序一起运行Elasticsearch。
2.6 症状6:聚合N多唯一值引起的高内存使用率
查询包含唯一值(例如,ID,用户名,电子邮件地址等)的聚合字段时性能不佳。
在堆内存分析时发现:Java对象使用"search", "buckets", "aggregation"等术语,消耗大量的堆内存。
2.6.1 问题原因
聚合在高基数(high-cardinality)字段上运行,需要大量资源来获取许多存储桶。
还可以存在涉及nested字段和/或join字段的嵌套聚合。
注解:high-cardinality中文解读为高基数不好理解。举个例子:
高基数——列中有很多唯一值(),如主键
低基数——与之相反,如性别列(只有男、女)。
2.6.2 解决方案
1、要提高高基数term聚合的性能,推荐阅读:
https://www.elastic.co/cn/blog/improving-the-performance-of-high-cardinality-terms-aggregations-in-elasticsearch
核心:使用eager_global_ordinals: true 提升性能。
2、有关进一步调整,请查看官网nested字段类型和join字段类型的使用建议,以更好地提高聚合性能。
3 偶发慢查询解决方案
一般而言,偶尔或间歇性慢查询可以从官网的优化索引、优化检索建议中中受益。
3.1 偶发慢查询关联监控指标
偶发慢查询应与这些监控指标中的一个或多个密切相关:
1)CPU负载
2)索引吞吐量
3)搜索吞吐量
4)垃圾收集(GC)活动
5)搜索线程池队列大小
线程池查看方法:
1GET /_cat/thread_pool
3.2 ARS提升检索吞吐率
Elasticsearch还有另一个有用的功能,称为自适应副本选择(ARS),它允许协调节点了解数据节点上的负载,并允许它选择最佳的分片副本来执行搜索,从而提高搜索吞吐量、降低延迟。
通过在查询时间内更均匀地分散负载,ARS可以对偶尔的减速有很大帮助。
在Elasticsearch 7.0及更高版本中,默认情况下将启用ARS。
4 非偶发慢查询解决方案
对于非偶发慢查询的场景,我们可以尝试逐个删除查询中的功能,并检查查询是否仍然很慢。
4.1 “拆解DSL”排查慢查询根源
查找最简单查询以重现性能问题有助于隔离和识别问题:
1)没有高亮显示它仍然很慢吗?
2)没有聚合,它仍然很慢吗?
3)如果size设置为0,它仍然很慢吗?
当size设置为0时,Elasticsearch会缓存搜索请求的结果,以便更快地进行搜索
4.2 参考官方搜索优化建议,看是否凑效?
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/tune-for-search-speed.html
4.3 慢查询排除实践
1)启用"profile:true"。
1GET /twitter/_search
2{
3 "profile": true,
4 "query" : {
5 "match" : { "message" : "some number" }
6 }
7}
2)查看节点的热点线程。
这有助于了解CPU时间的使用情况。
1GET /_nodes/hot_threads
3)使用kibana可视化profile分析工具
https://www.elastic.co/guide/en/kibana/7.0/xpack-profiler.html
5 捕获慢查询、耗费资源查询
5.1 慢查询、耗费资源查询难捕获
在Elasticsearch中同时处理不同的请求/线程时,很难捕获慢查询、耗费资源查询。
实际N多人应用的业务场景,当无法定位耗费资源查询的用户时,情况变得更加复杂,这些查询会降低集群性能(例如,长垃圾收集(GC)周期)或更糟糕的是内存不足(OOM)情况。
在Elasticsearch 7.0版中,我们引入了一种新的内存熔断策略,用于在保留内存时测量实际堆内存使用情况。
此新策略可提高节点对资源耗费高查询导致集群过载的弹性支持,并在默认情况下处于打开状态,并可使用新的集群设置:
indices.breaker.total.use_real_memory 进行控制。
内存熔断策略推荐:
https://github.com/elastic/elasticsearch/pull/31767
5.2 dump堆内存分析
以上方案并未覆盖全部业务场景。借助dump文件有助于更好地理解根本原因。
在JVM OOM后Dump操作实战参考:
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/heap-dump-path.html
Linux捕获dump文件的方法
1ps -ef|egrep 'elasticsearch|logstash' | grep -v grep
5.3 Elasticsearch的保护设置
Elasticsearch具有另一个保护设置(最大桶search.max_buckets限制),以保护集群出现OOM。
当超过桶的数量(在版本7.0中默认为10,000)时(例如,当运行多层聚合时),
该最大桶聚合设置停止执行并且使搜索请求失败。
5.4 断路器设置
为了进一步识别潜在的耗费资源的查询,我们可以设置断路器(indices.breaker.request.limit)。
设置方法:逐步缩放查询范围,从低阈值开始隔离查询并逐渐向上移动阈值以缩小到特定的查询。
断路器设置参考:
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/circuit-breaker.html#request-circuit-breaker
5.5 慢日志分析
可以通过启用Elasticsearch中的慢速日志来识别运行缓慢的查询。
Slowlogs专门用于分片级别,这意味着只应用数据节点。
仅协调 Coordinating-only/客户client节点不具备慢日志分析功能,因为它们不保存数据(索引/分片)。
Slowlogs有助于回答以下问题:
1)查询需要多长时间?
2)查询请求正文的内容是什么?
Slowlogs输出举例:
1[][TRACE][index.search.slowlog.query] [2g1yKIZ] [logstash-20190211][4] took[10.4s], took_millis[10459], total_hits[16160], types[], stats[],
2search_type[QUERY_THEN_FETCH], total_shards[10], source[{"size":0,"query":{"bool":{"must":[{"range":{"timestamp":{"from":1549266459837,"to":1549871259837,"include_lower":true,
3"include_upper":true,"format":"epoch_millis","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},"_source":{"includes":[],"excludes":[]},"stored_fields":"*","docvalue_fields":
4[],"script_fields":{"hour_of_day":{"script":{"source":"doc['timestamp'].value.getHourOfDay()",
5"lang":"painless"},"ignore_failure":false}},"aggregations":{"maxAgg":{"max":{"field":"bytes"}},"minAgg":{"min":{"field":"bytes"}}}}], id[]],
Slowlog 日志拆解:
| 日志拆分项 | 描述 |
[2019-02-11T16:47:39,882] | 检索时间 |
[TRACE] | 日志级别 |
[index.search.slowlog.query] | 属于search的query阶段慢日志 |
[2g1yKIZ] | 节点名称 |
[logstash-20190211] | 索引名称 |
[4] | query执行的分片序号 |
took[10.4s] | 在分片4所需的处理时间。注意:在查看慢速日志时,我们希望避免从不同的分片中添加所有时间,因为每个分片可能并行执行。 |
took_millis[10459] | 耗费时间(毫秒) |
total_hits[16160] | 命中数 |
search_type[QUERY_THEN_FETCH] | search类型(query_then_fetch) |
total_shards[10] | 索引的总分片大小 |
source[] | 执行检索的请求body体 |
5.6 日志审计(高阶功能,低版本非付费会员建议跳过)
拥有金牌会员或铂金会员订阅的客户(包括Elastic安全功能)可以打开审核日志以捕获有关查询的更多详细信息。(用户可以开始为期30天的试用版来测试Elastic安全功能。)
注意:6.8和7.1之后,基础安全功能已免费。之上的高版本可以使用该功能。低版本的非会员不建议使用。
审计日志记录有助于回答以下问题:
1)查询是什么时候发生的?
2)谁执行了查询?
3)查询的内容是什么?
我们需要调整审核设置,因为默认设置相当繁琐:
1)启用安全审计日志:
在elasticsearch.yml中设置
xpack.security.audit.enabled:true。
2)在安全审计输出中启用日志或索引:
在elasticsearch.yml中设置
xpack.security.audit.outputs:[logfile,index]。
出于故障排除的目的,我们建议选择logfile而不是索引,因为审计日志记录的详细程度可能会对集群性能造成不必要的压力。
审计模式可能非常冗长,因此请在完成故障排除后将其关闭。
3)在事件列表中包含authentication_success访问权限
在elasticsearch.yml中设置xpack.security.audit.logfile.events.include: authentication_success
6、小结
本文翻译自Elastic官方博文,添加了自己的实践解读和星球内部讨论总结内容。
在本文中,我们讨论了慢查询的常见原因以及解决方案。我们还讨论了偶发慢查询和非偶发慢查询的解决方案。通常会将慢查询视为更广泛集群性能出问题的典型症状。
8月24日北京Meetup上medcl列举了10个原因升级7.X,如果你还是6.X、5.X甚至更低版本,推荐升级。Elasticsearch7.X高级版本在搜索 qps 上提升很大,相同配置下慢查询也还会有较大改善。
Elasticsearch性能优化非一朝一夕之功,“认准病根才能根除病痛”。
原文地址:
https://www.elastic.co/cn/blog/advanced-tuning-finding-and-fixing-slow-elasticsearch-queries
官方优化:
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/how-to.html
END
关注我

公众号(zhisheng)里回复 面经、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章
Flink 实战
1、《从0到1学习Flink》—— Apache Flink 介绍
2、《从0到1学习Flink》—— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、《从0到1学习Flink》—— Flink 配置文件详解
4、《从0到1学习Flink》—— Data Source 介绍
5、《从0到1学习Flink》—— 如何自定义 Data Source ?
6、《从0到1学习Flink》—— Data Sink 介绍
7、《从0到1学习Flink》—— 如何自定义 Data Sink ?
8、《从0到1学习Flink》—— Flink Data transformation(转换)
9、《从0到1学习Flink》—— 介绍 Flink 中的 Stream Windows
10、《从0到1学习Flink》—— Flink 中的几种 Time 详解
11、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 ElasticSearch
12、《从0到1学习Flink》—— Flink 项目如何运行?
13、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 Kafka
14、《从0到1学习Flink》—— Flink JobManager 高可用性配置
15、《从0到1学习Flink》—— Flink parallelism 和 Slot 介绍
16、《从0到1学习Flink》—— Flink 读取 Kafka 数据批量写入到 MySQL
17、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 RabbitMQ
18、《从0到1学习Flink》—— 你上传的 jar 包藏到哪里去了
19、大数据“重磅炸弹”——实时计算框架 Flink
20、《Flink 源码解析》—— 源码编译运行
21、为什么说流处理即未来?
22、OPPO数据中台之基石:基于Flink SQL构建实数据仓库
23、流计算框架 Flink 与 Storm 的性能对比
24、Flink状态管理和容错机制介绍
25、原理解析 | Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
26、Apache Flink 是如何管理好内存的?
27、《从0到1学习Flink》——Flink 中这样管理配置,你知道?
28、《从0到1学习Flink》——Flink 不可以连续 Split(分流)?
29、Flink 从0到1学习—— 分享四本 Flink 的书和二十多篇 Paper 论文
30、360深度实践:Flink与Storm协议级对比
31、Apache Flink 1.9 重大特性提前解读
32、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
33、美团点评基于 Flink 的实时数仓建设实践
34、Flink 灵魂两百问,这谁顶得住?
35、一文搞懂 Flink 的 Exactly Once 和 At Least Once
36、你公司到底需不需要引入实时计算引擎?
37、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
Flink 源码解析
知识星球里面可以看到下面文章
 喜欢就点个"在看"呗^_^
喜欢就点个"在看"呗^_^















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









