






本文旨在澄清不同文件操作对文件的影响。
本页面提供具体示例和实用技巧,以有效地管理这些操作。此外,通过对提交(commit)和压实(compact)等操作的深入探讨,我们旨在提供有关文件创建和更新的见解。
前提
对以下几篇有了解:
1、Apache Paimon 介绍
2、Apache Paimon 基础概念
3、Apache Paimon 文件布局设计
4、知道如何在 Flink 中使用 Paimon
创建 catalog
在 Flink lib 中放入 paimon-flink 依赖包,执行 ./sql-client.sh 启动 Flink SQL Client,然后执行下面的命令去创建 Paimon catlog:
CREATE CATALOG paimon WITH (
'type' = 'paimon',
'warehouse' = 'file:///tmp/paimon'
);
USE CATALOG paimon;执行完后会在 file:///tmp/paimon 路径下创建目录 default.db
创建 Table
执行下面的命令会创建一个带有 3 个属性的 Paimon 表:
CREATE TABLE T (
id BIGINT,
a INT,
b STRING,
dt STRING COMMENT 'timestamp string in format yyyyMMdd',
PRIMARY KEY(id, dt) NOT ENFORCED
) PARTITIONED BY (dt);执行后,Paimon 表 T 会在 /tmp/paimon/default.db/T 目录下生成目录,它的 schema 会存放在目录 /tmp/paimon/default.db/T/schema/schema-0 下。
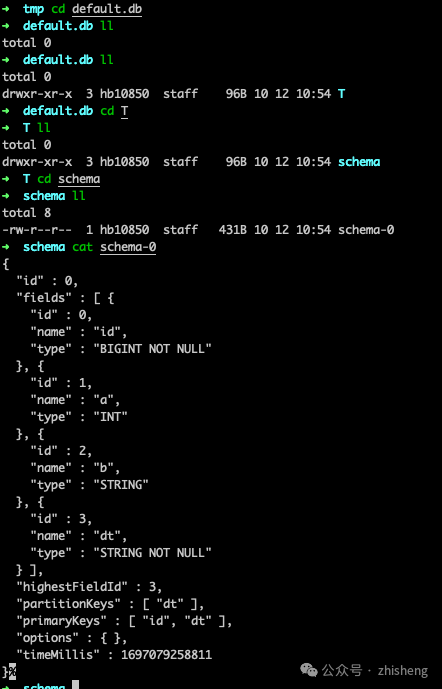
写入数据到 Table
INSERT INTO T VALUES (1, 10001, 'varchar00001', '20230501');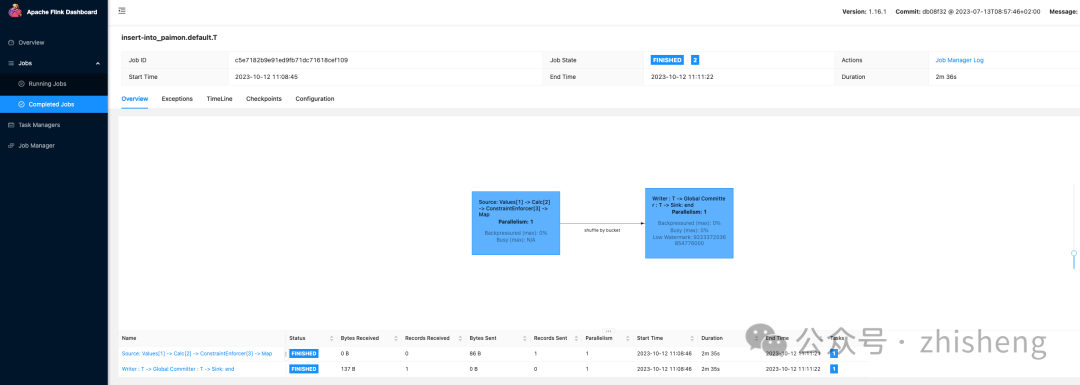
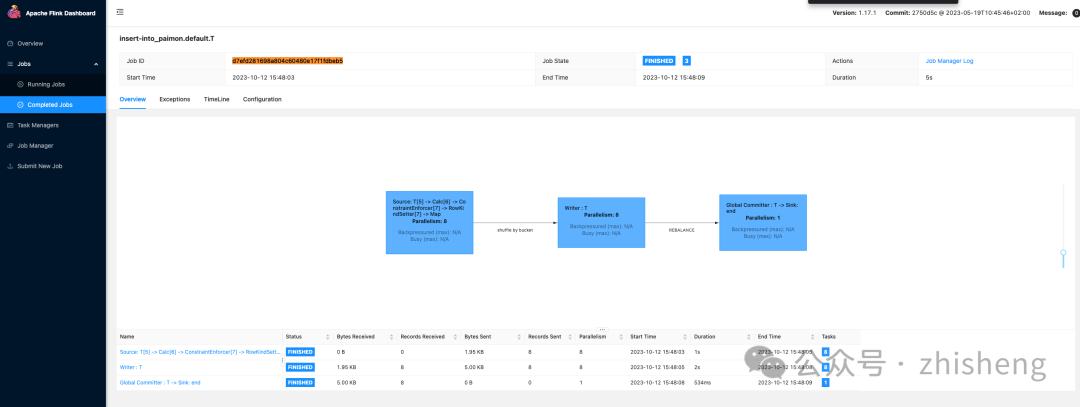
用户可以通过执行查询 SELECT * FROM T 来验证这些记录的可见性,该查询将返回一行结果。提交过程会创建一个位于路径 /tmp/paimon/default.db/T/snapshot/snapshot-1 的快照。快照-1 的文件布局如下所述:
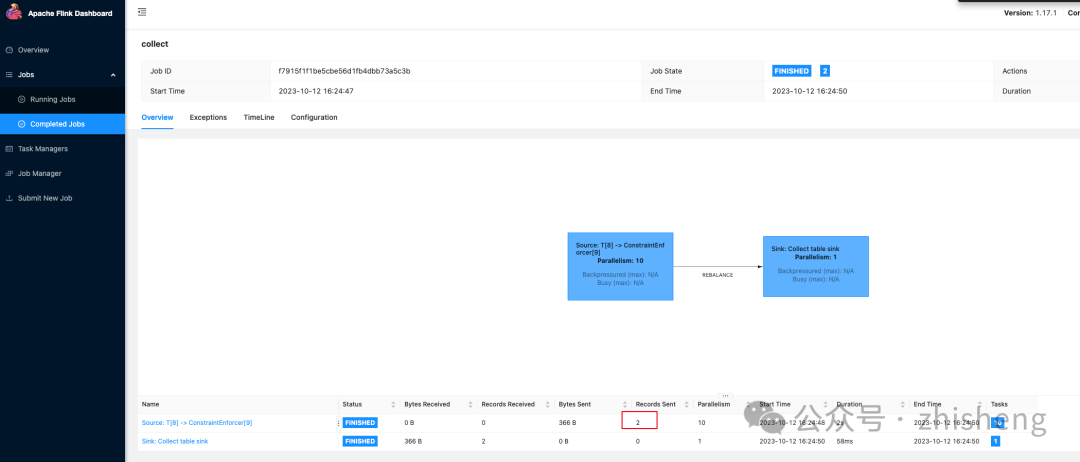
一旦任务运行完成变成 finished 时,提交成功后数据就写入到 Paimon 表中。用户可以通过执行查询 SELECT * FROM T 来验证数据的可见性,该查询将返回一行结果。
另外可以发现目录的结构发生如下变化,新增 dt=20230501、manifest 和 snapshot三个目录。三个的目录结构如下:
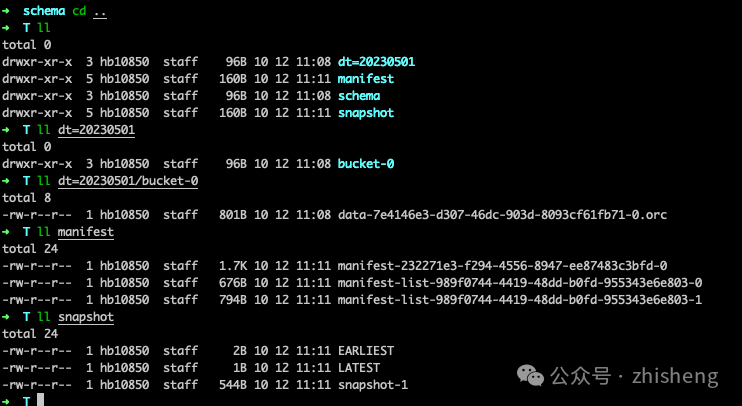
查询目录下的数据如下所示:
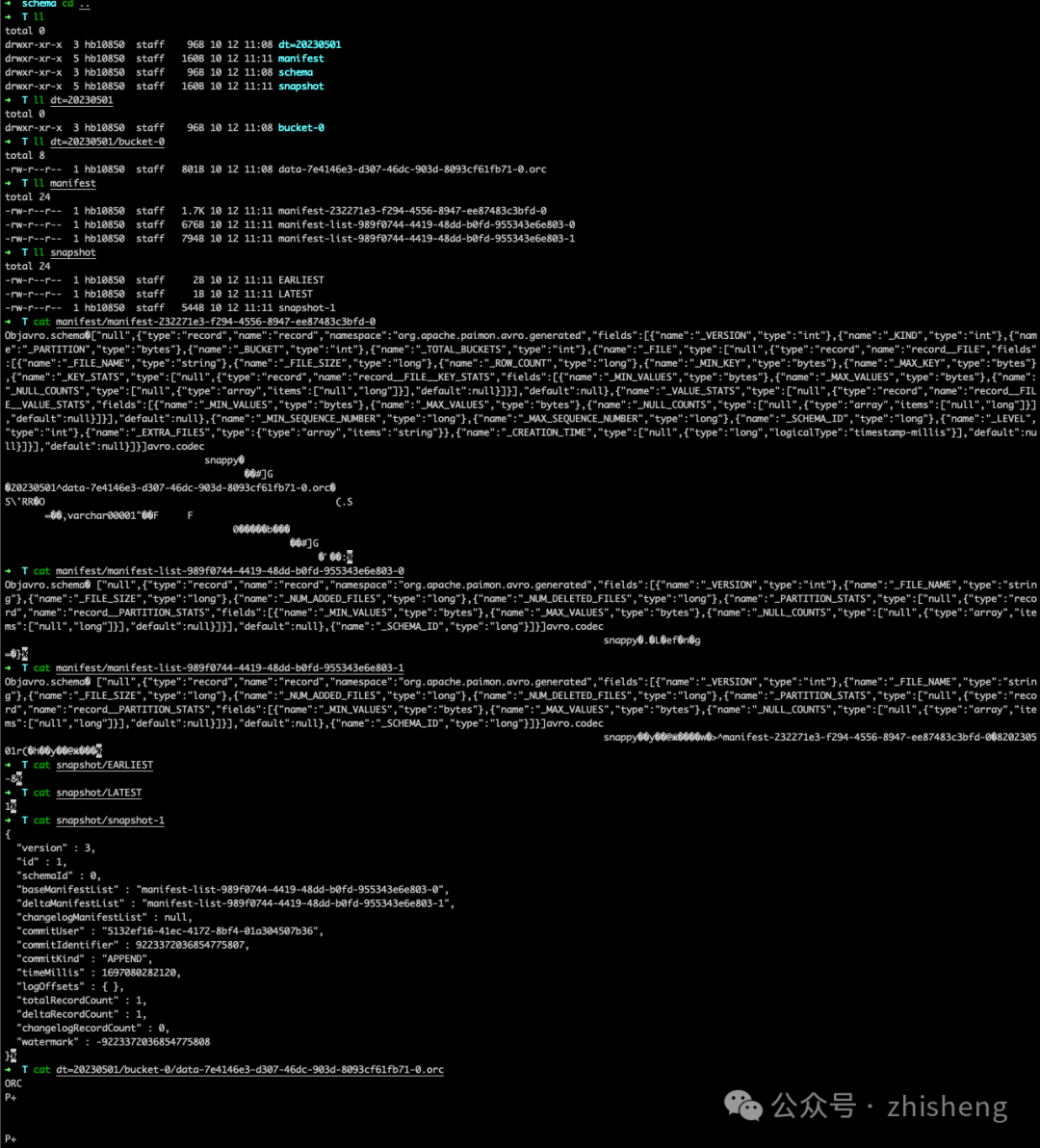
这是因为提交过程中会创建一个位于 /tmp/paimon/default.db/T/snapshot/snapshot-1 的快照。snapshot-1 的文件布局如下所述:
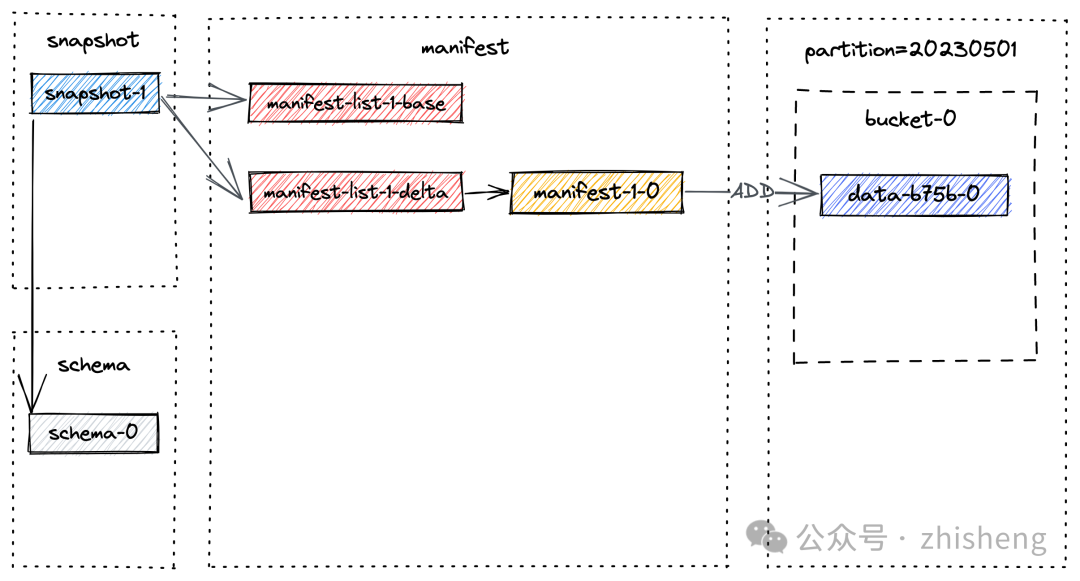
snapshot-1的内容包含了这个 snapshot 的元数据,比如 manifest list 和 schema id:
{
"version" : 3,
"id" : 1,
"schemaId" : 0,
"baseManifestList" : "manifest-list-989f0744-4419-48dd-b0fd-955343e6e803-0",
"deltaManifestList" : "manifest-list-989f0744-4419-48dd-b0fd-955343e6e803-1",
"changelogManifestList" : null,
"commitUser" : "5132ef16-41ec-4172-8bf4-01a304507b36",
"commitIdentifier" : 9223372036854775807,
"commitKind" : "APPEND",
"timeMillis" : 1697080282120,
"logOffsets" : { },
"totalRecordCount" : 1,
"deltaRecordCount" : 1,
"changelogRecordCount" : 0,
"watermark" : -9223372036854775808
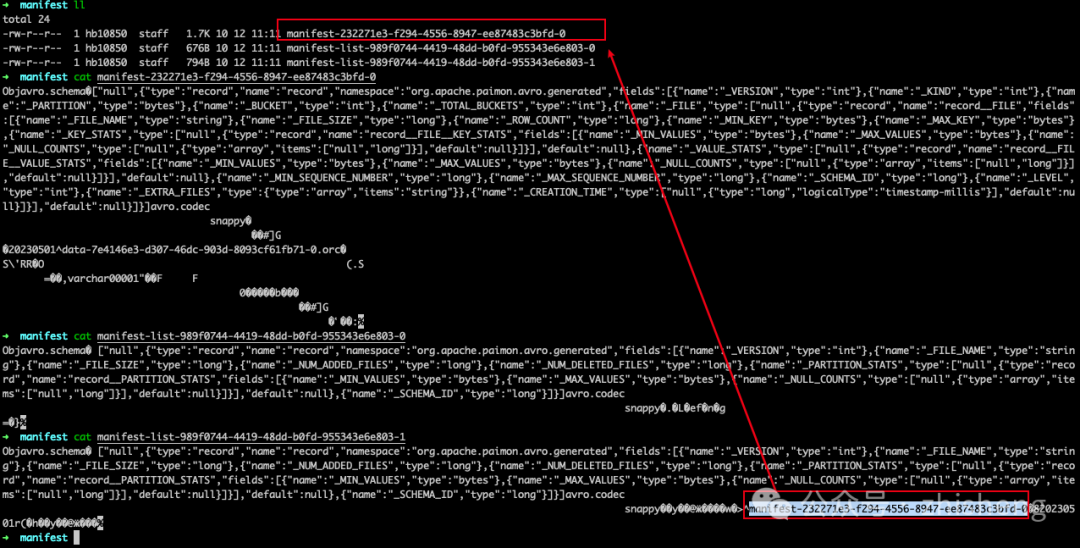
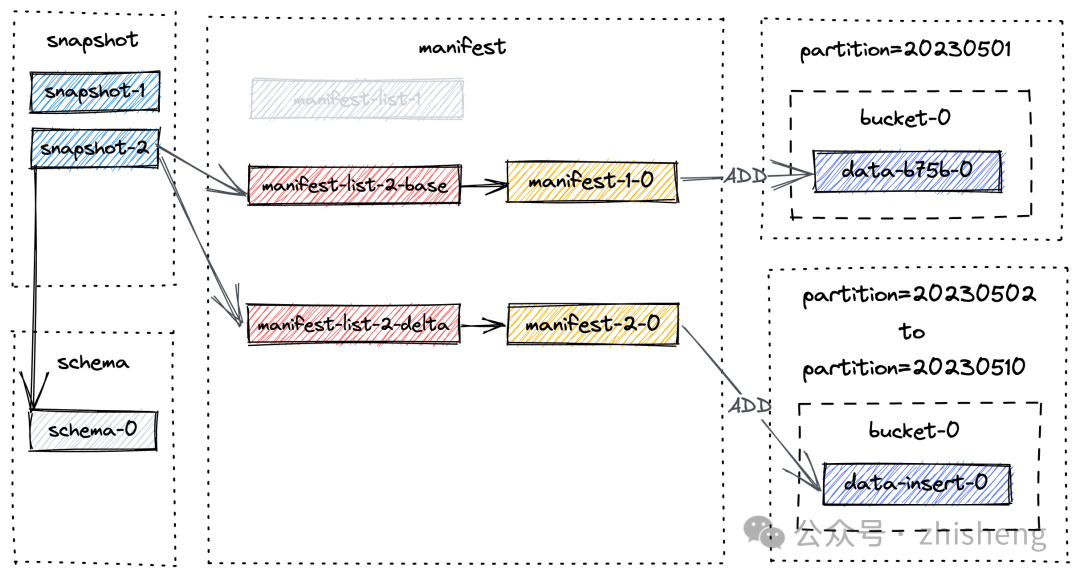
}需要提醒的是,manifest list 包含了 snapshot 的所有更改,baseManifestList 是应用在 deltaManifestList 中的更改所基于的基本文件。第一次提交将导致生成 1 个清单文件,并创建了 2 个清单列表(文件名可能与你的实验中的不同):
➜ T
manifest-232271e3-f294-4556-8947-ee87483c3bfd-0
manifest-list-989f0744-4419-48dd-b0fd-955343e6e803-0
manifest-list-989f0744-4419-48dd-b0fd-955343e6e803-1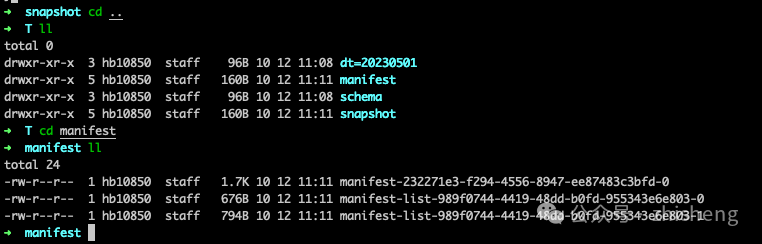
manifest-232271e3-f294-4556-8947-ee87483c3bfd-0: 如前面文件布局图中的 manifest-1-0,存储了关于 snapshot 中数据文件信息的 manifest。
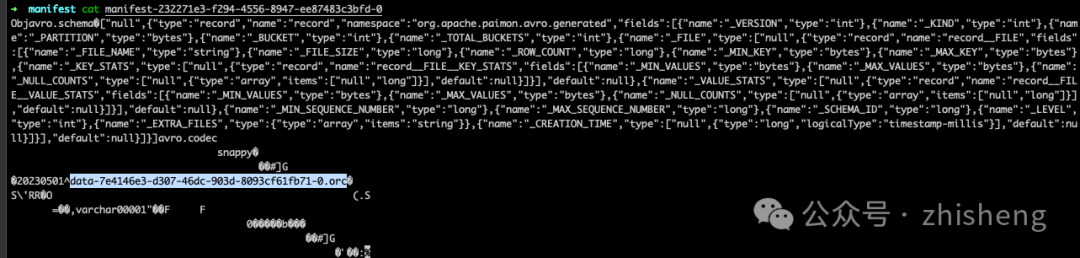
manifest-list-989f0744-4419-48dd-b0fd-955343e6e803-0: 是基础的 baseManifestList,如前面文件布局图中的 manifest-list-1-base,实际上是空的。

manifest-list-989f0744-4419-48dd-b0fd-955343e6e803-1:是deltaManifestList,如前面文件布局图中的 manifest-list-1-delta,其中包含一系列对数据文件执行操作的清单条目,而在这种情况下,清单条目为 manifest-1-0。
在不同分区中插入一批记录,在 Flink SQL 中执行以下语句:
INSERT INTO T VALUES
(2, 10002, 'varchar00002', '20230502'),
(3, 10003, 'varchar00003', '20230503'),
(4, 10004, 'varchar00004', '20230504'),
(5, 10005, 'varchar00005', '20230505'),
(6, 10006, 'varchar00006', '20230506'),
(7, 10007, 'varchar00007', '20230507'),
(8, 10008, 'varchar00008', '20230508'),
(9, 10009, 'varchar00009', '20230509'),
(10, 10010, 'varchar00010', '20230510');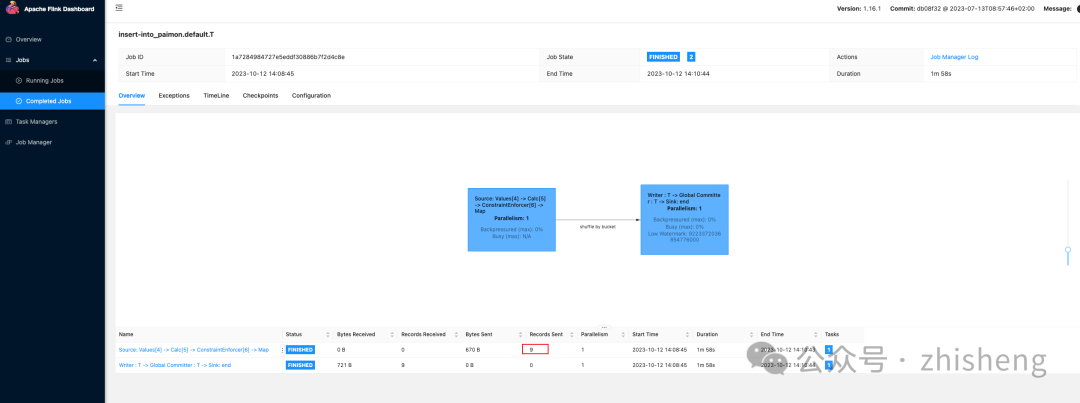
等任务执行完成并提交快照后,执行 SELECT * FROM T 将返回 10 行数据。

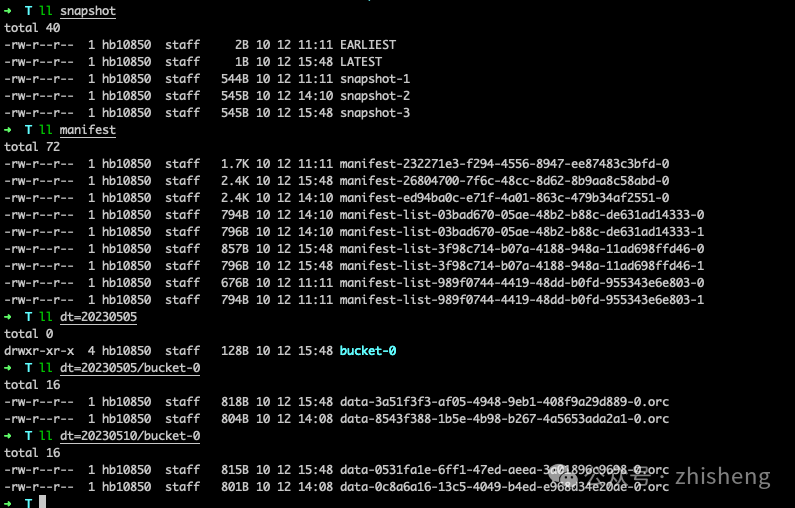
创建了一个新的快照,即 snapshot-2,并给出了以下物理文件布局:
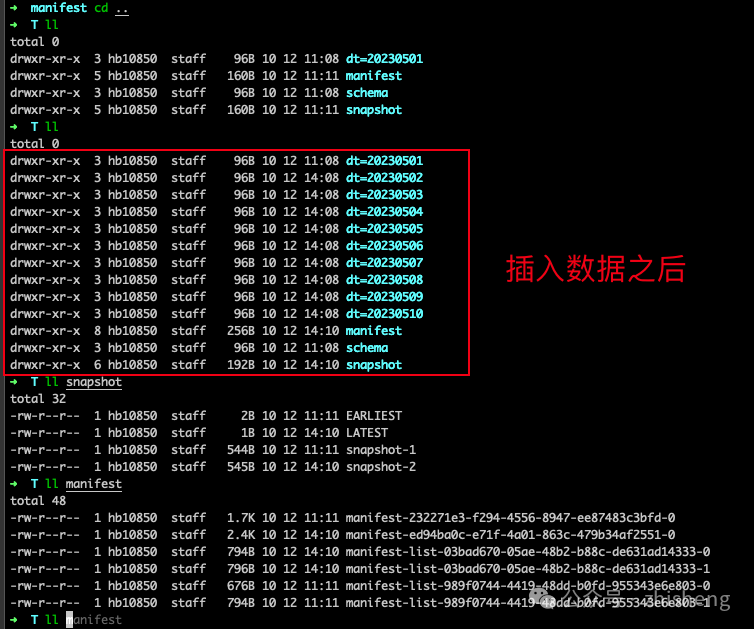
dt=20230501
dt=20230502
dt=20230503
dt=20230504
dt=20230505
dt=20230506
dt=20230507
dt=20230508
dt=20230509
dt=20230510
manifest
schema
snapshot
➜ T ll snapshot
EARLIEST
LATEST
snapshot-1
snapshot-2
➜ T ll manifest
manifest-232271e3-f294-4556-8947-ee87483c3bfd-0 //snapshot-1 manifest file
manifest-list-989f0744-4419-48dd-b0fd-955343e6e803-0 //snapshot-1 baseManifestList
manifest-list-989f0744-4419-48dd-b0fd-955343e6e803-1 //snapshot-1 deltaManifestList
manifest-ed94ba0c-e71f-4a01-863c-479b34af2551-0 //snapshot-2 manifest file
manifest-list-03bad670-05ae-48b2-b88c-de631ad14333-0 //snapshot-2 baseManifestList
manifest-list-03bad670-05ae-48b2-b88c-de631ad14333-1 snapshot-2 baseManifestList新的快照文件布局图如下:
删除数据
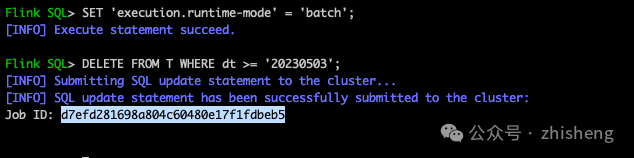
接下来删除满足条件 dt>=20230503 的数据。在 Flink SQL Client 中,执行以下语句:
DELETE FROM T WHERE dt >= '20230503';注意⚠️:
1、需使用 Flink 1.17 及以上版本,否则不支持该语法
Flink SQL> DELETE FROM T WHERE dt >= '20230503';
>
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: Unsupported query: DELETE FROM T WHERE dt >= '20230503';
2、使用 batch 模式,否则报错不支持
Flink SQL> DELETE FROM T WHERE dt >= '20230503';
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: DELETE statement is not supported for streaming mode now.
需要设置 SET 'execution.runtime-mode' = 'batch';
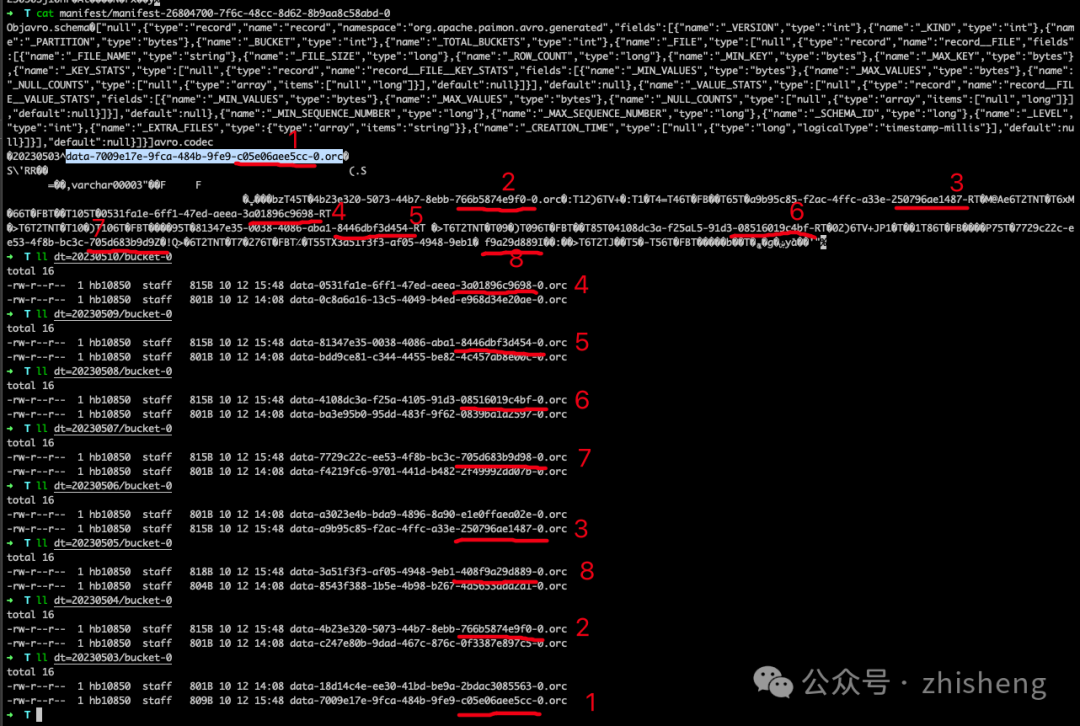
第三次提交完成,并生成了快照 snapshot-3。现在,表下的目录,会发现没有分区被删除。相反,为分区 20230503 到 20230510 创建了一个新的数据文件:
➜ T ll dt=20230510/bucket-0
data-0531fa1e-6ff1-47ed-aeea-3a01896c9698-0.orc # newer data file created by the delete statement
data-0c8a6a16-13c5-4049-b4ed-e968d34e20ae-0.orc # older data file created by the insert statement这是有道理的,因为我们在第二次提交中插入了一条数据(为 +I[10, 10010, 'varchar00010', '20230510'] ),然后在第三次提交中删除了数据。现在再执行一下 SELECT * FROM T只能查询到两条数据。
+I[1, 10001, 'varchar00001', '20230501']
+I[2, 10002, 'varchar00002', '20230502']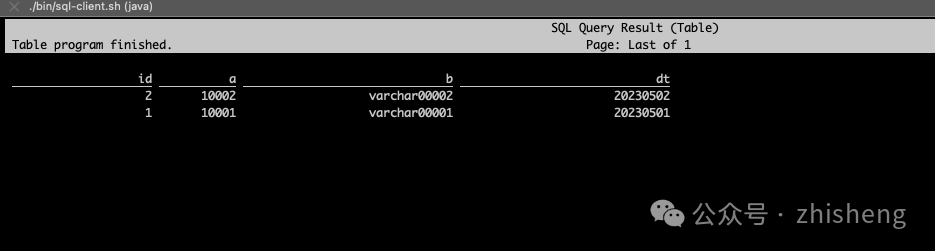
snapshot-3后新的文件布局如下图:
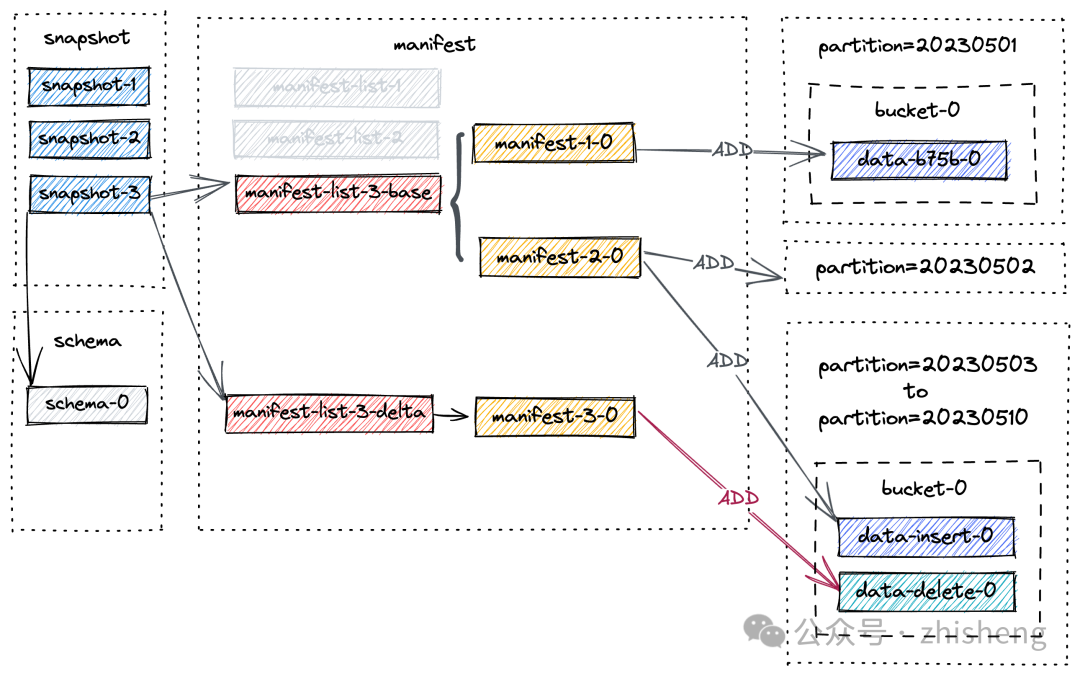
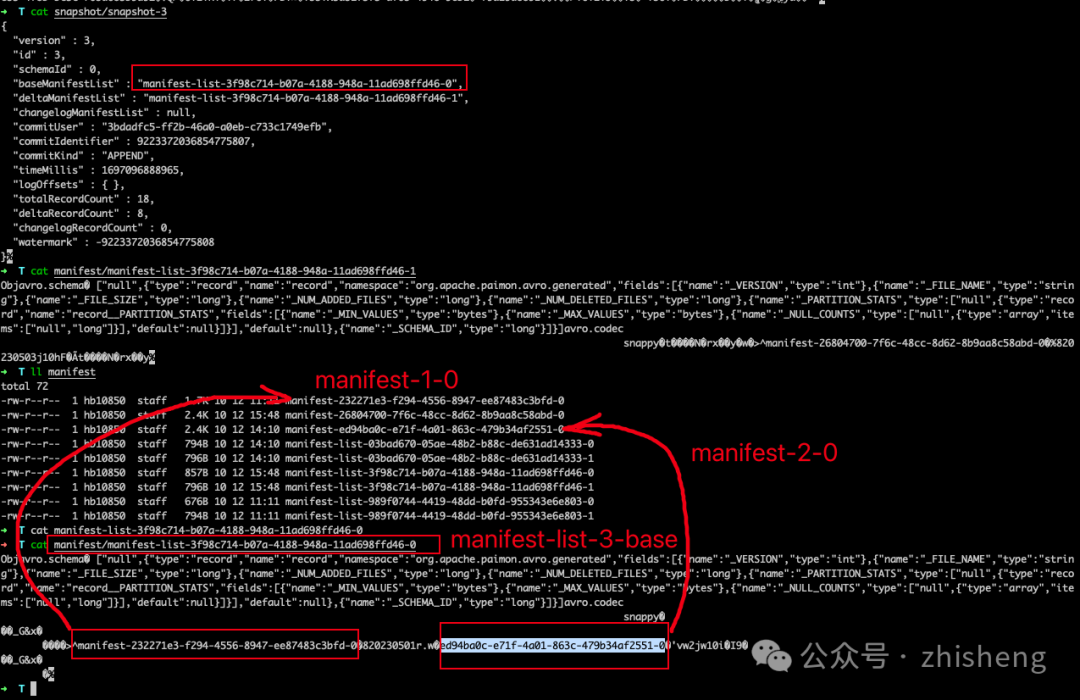
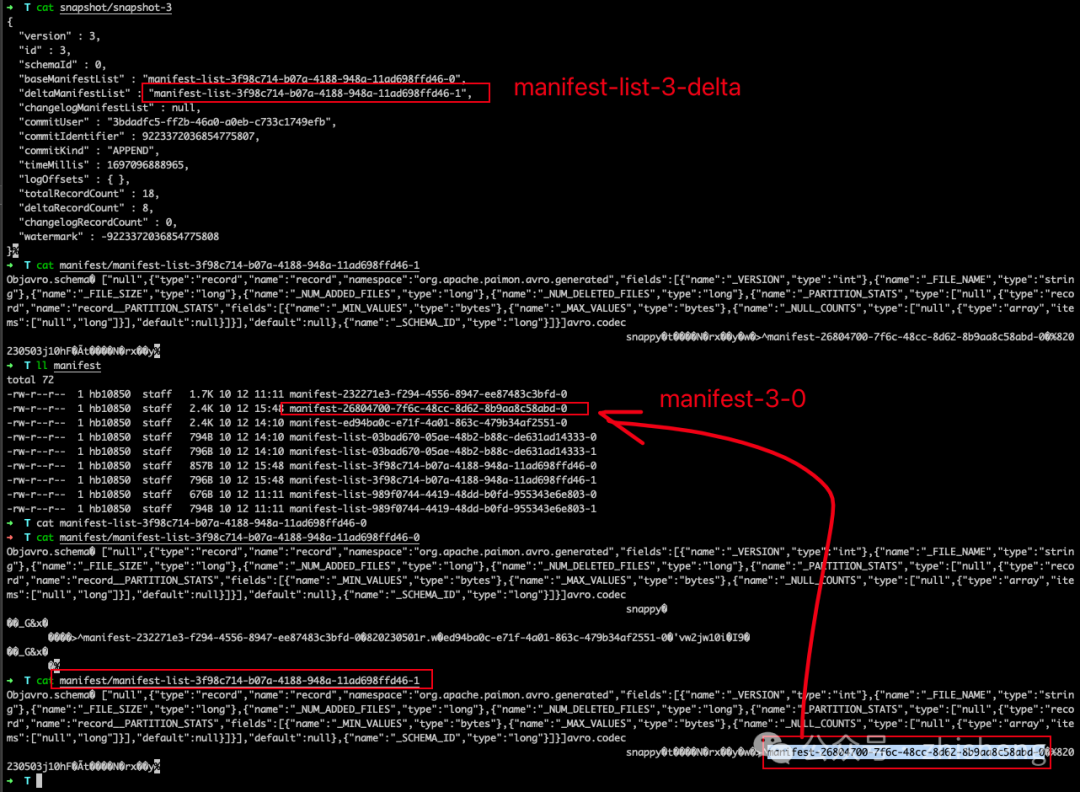
请注意,manifest-3-0 包含了 8 个 ADD 操作类型的清单条目,对应着 8 个新写入的数据文件。
Compact Table
你可能已经注意到的,随着连续 snapshot 的增加,小文件的数量会增加,这可能会导致读取性能下降。因此,需要进行全量压缩以减少小文件的数量。
通过 flink run 运行一个专用的合并小文件任务:
<FLINK_HOME>/bin/flink run \
-D execution.runtime-mode=batch \
./paimon-flink-action-0.6-SNAPSHOT.jar \
compact \
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition <partition-name>] \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]] \
[--table-conf <paimon-table-dynamic-conf> [--table-conf <paimon-table-dynamic-conf>] ...]例如(提前下载好压缩任务 jar 在 Flink 客户端下):
./bin/flink run \
-D execution.runtime-mode=batch \
./paimon-flink-action-0.6-20231012.001913-36.jar \
compact \
--path file:///tmp/paimon/default.db/T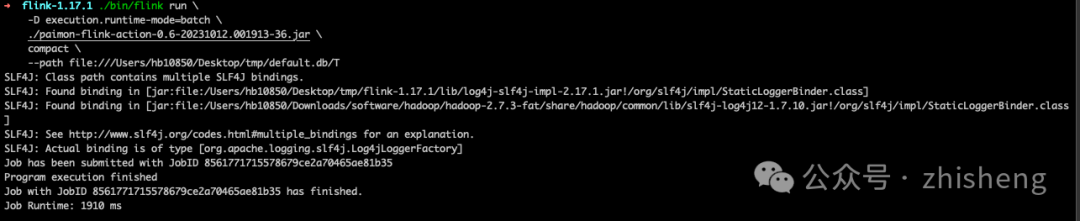
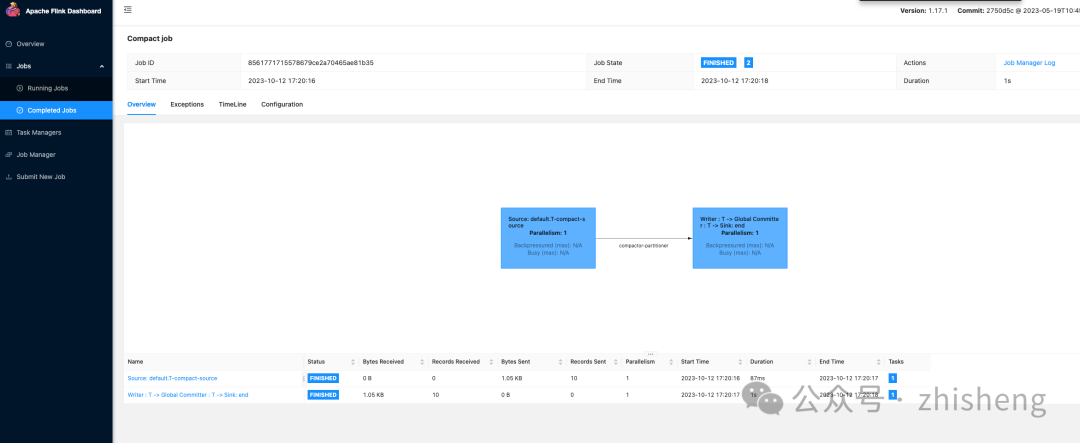
压缩任务结束后,再来看下 snapshot-4 文件结构:
{
"version" : 3,
"id" : 4,
"schemaId" : 0,
"baseManifestList" : "manifest-list-00af18ef-486d-4046-be60-25533e078333-0",
"deltaManifestList" : "manifest-list-00af18ef-486d-4046-be60-25533e078333-1",
"changelogManifestList" : null,
"commitUser" : "ab094a14-17e0-4215-8e79-cd0651436dee",
"commitIdentifier" : 9223372036854775807,
"commitKind" : "COMPACT",
"timeMillis" : 1697102418177,
"logOffsets" : { },
"totalRecordCount" : 2,
"deltaRecordCount" : -16,
"changelogRecordCount" : 0,
"watermark" : -9223372036854775808
}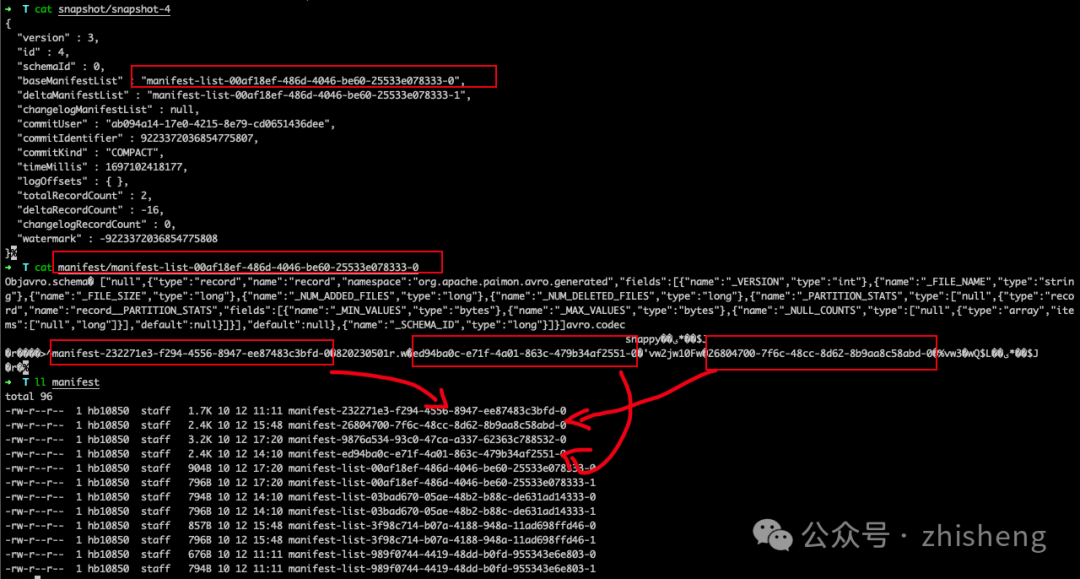
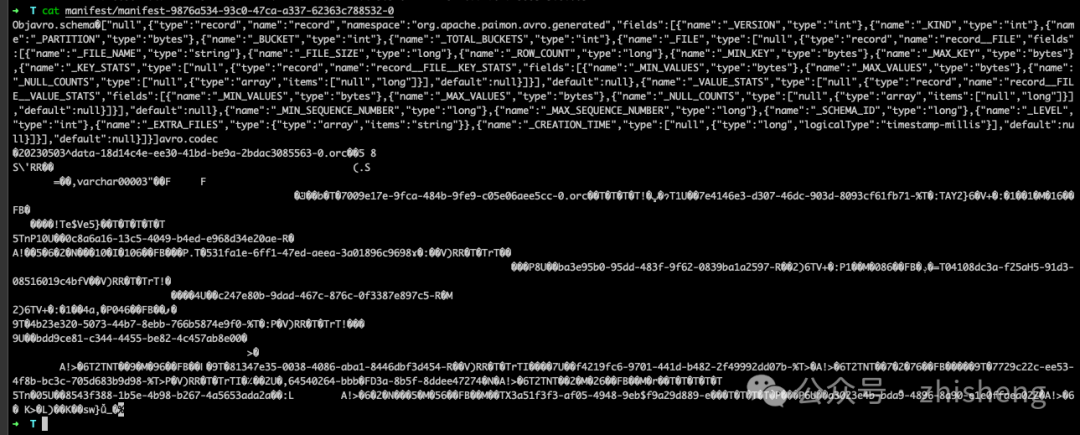
manifest-4-0 包含 20 个清单条目(18 个 DELETE 操作和 2 个 ADD 操作):
对于分区 20230503 到 20230510,有两个删除操作,对应两个数据文件
对于分区 20230501 到 20230502,有一个删除操作和一个添加操作,对应同一个数据文件。
Alter Table
执行以下语句来配置全量压缩:
ALTER TABLE T SET ('full-compaction.delta-commits' = '1');这将为 Paimon 表创建一个新的 schema,即 schema-1,但在下一次提交之前,不会有任何 snapshot 使用此模式。
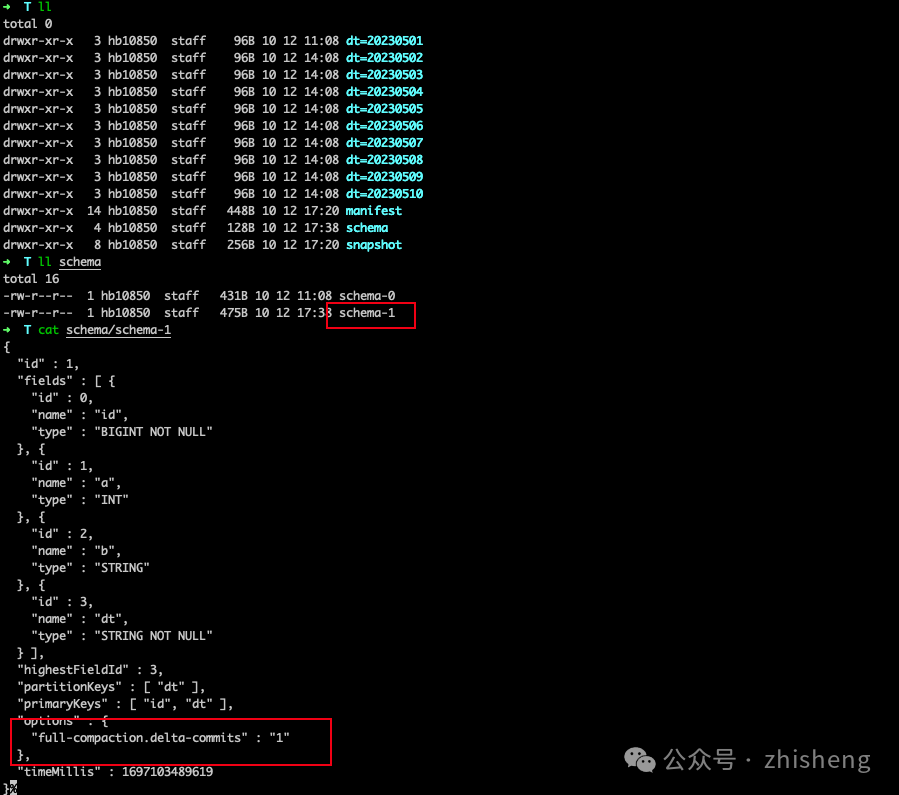
过期 snapshot
请注意,标记为删除的数据文件直到 snapshot 过期且没有任何消费者依赖于该 snapshot 时才会真正被删除。参考 Manage Snapshots 可以查阅更多信息。
在 snapshot 过期过程中,首先确定 snapshot 的范围,然后标记这些 snapshot 内的数据文件以进行删除。只有当存在引用特定数据文件的 DELETE 类型的清单条目时,才会标记该数据文件进行删除。这种标记确保文件不会被后续的 snapshot 使用,并且可以安全地删除。
假设上图中的所有 4 个 snapshot 即将过期。过期过程如下:
1、首先删除所有标记为删除的数据文件,并记录任何更改的 bucket。
2、然后删除所有的 changelog 文件和关联的 manifests。
3、最后,删除快照本身并写入最早的提示文件。
如果删除过程后留下的空目录,也将被删除。
假设创建了另一个快照 snapshot-5,并触发了快照过期。将删除 snapshot-1 到 snapshot-4。为简单起见,我们只关注以前快照的文件,快照过期后的最终布局如下:
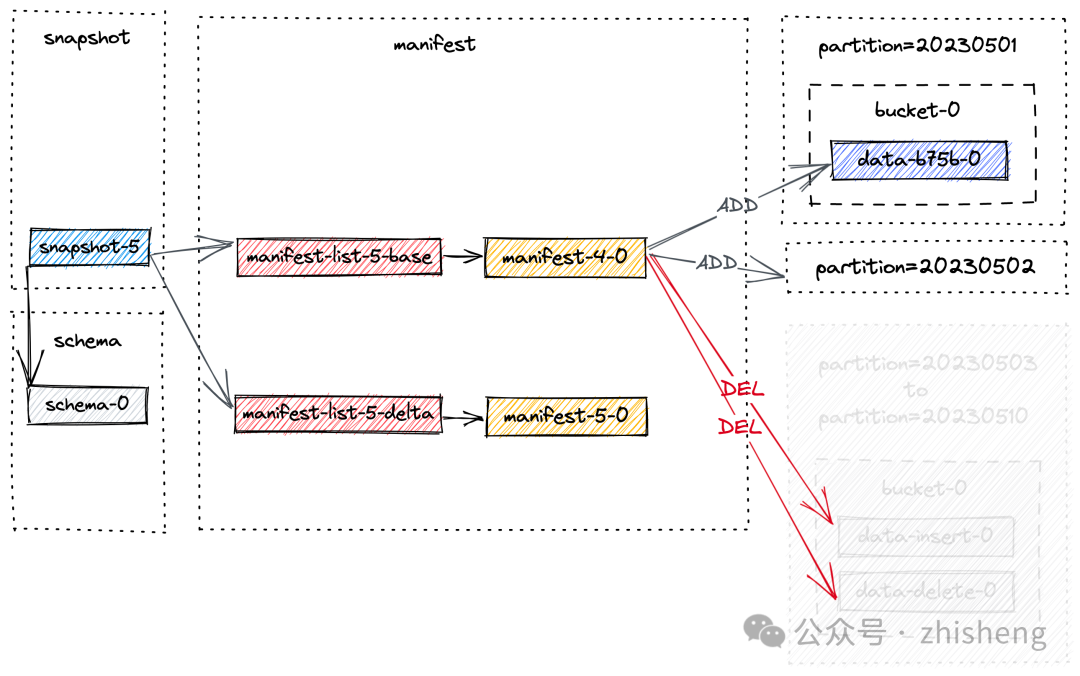
因此,分区 20230503 到 20230510 的数据被物理删除了。
Flink 流式写入
我们通过利用 CDC 数据的示例来测试 Flink 流式写入,将介绍将变更数据捕获并写入 Paimon 的过程,以及异步压缩、快照提交和过期的机制背后的原理。帮我们更详细地了解 CDC 数据摄取的工作流程以及每个参与组件所扮演的独特角色。
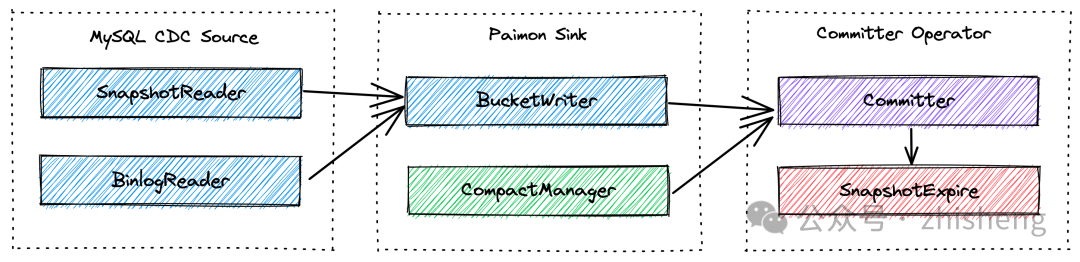
1、MySQL CDC Source 统一读取快照数据和增量数据,其中 SnapshotReader 读取快照数据,而 BinlogReader 读取增量数据。
2、Paimon Sink 将数据按 Bucket 级别写入 Paimon 表中。其中的 CompactManager 将异步触发压缩操作。
3、Committer Operator 是一个单例,负责提交和过期快照。
接下来,我们将逐步介绍端到端的数据流程:

MySQL CDC Source 首先读取快照数据和增量数据,然后对它们进行规范化处理,并将其发送到下游。
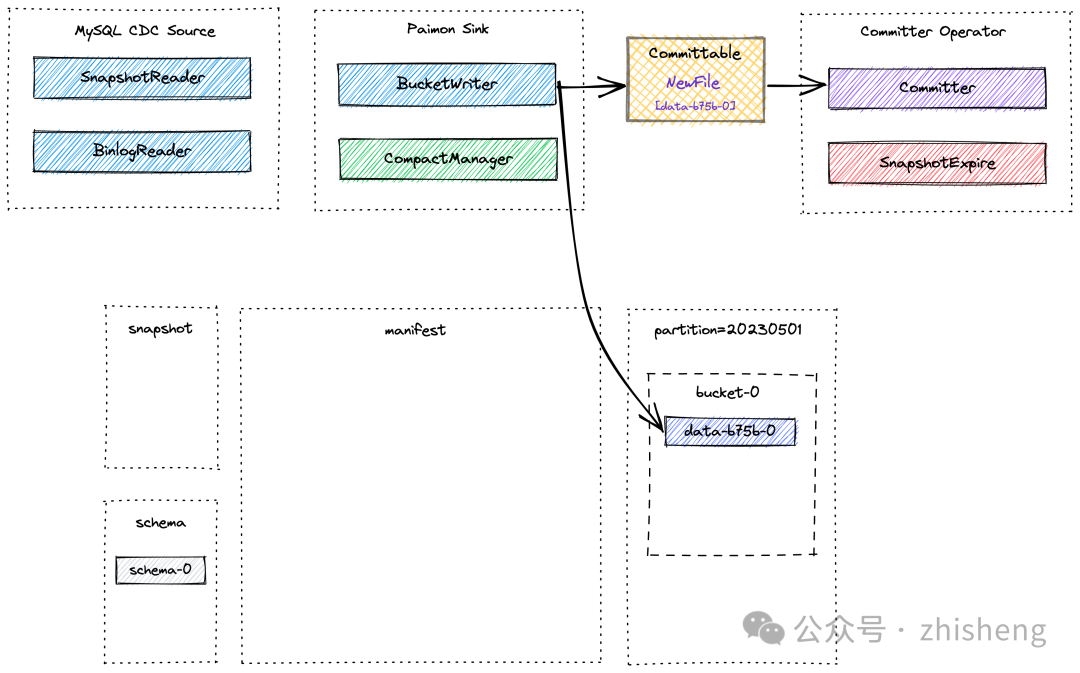
Paimon Sink 首先将新记录缓存在基于堆的 LSM 树中,并在内存缓冲区满时将其 flush 到磁盘上。请注意,每个写入的数据文件都是一个 sorted run。在这个阶段,还没有创建 manifest 文件和 snapshot。在 Flink 执行 Checkpoint 之前,Paimon Sink 将 flush 所有缓冲的记录并发送可提交的消息到下游,下游会在 Checkpoint 期间由 Committer Operator 读取并提交。
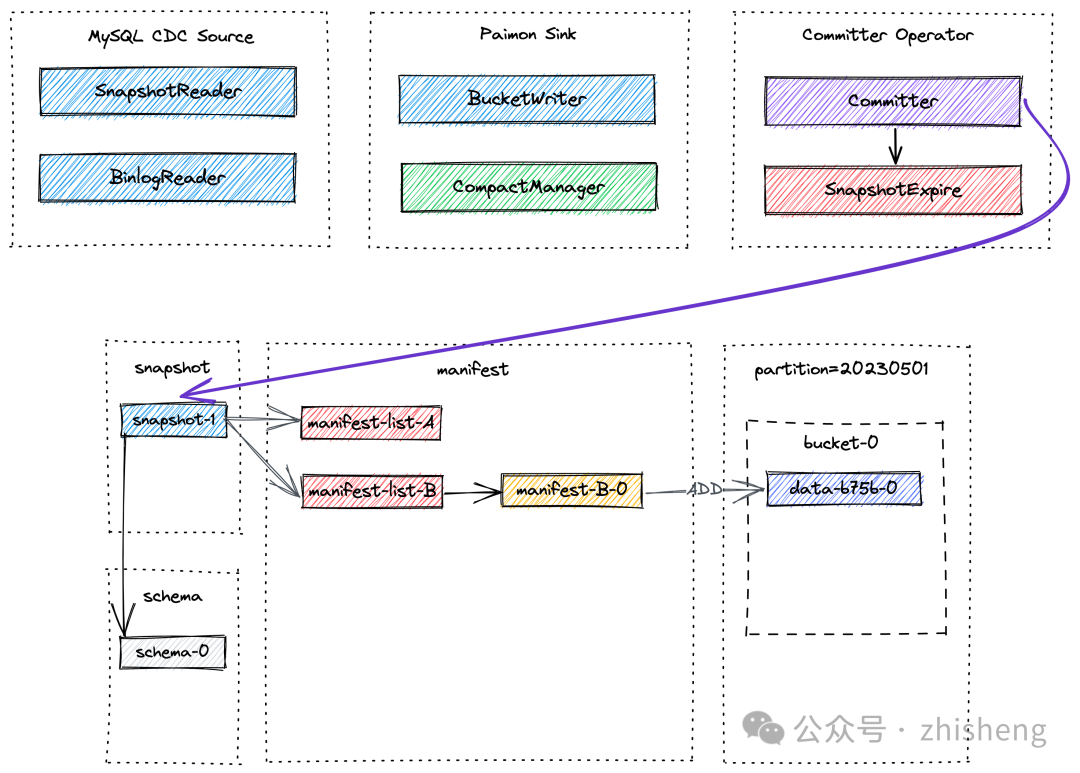
在 Checkpoint 期间,Committer Operator 将创建一个新的 snapshot,并将其与 manifest lists 关联,以便snapshot 包含表中所有数据文件的信息。
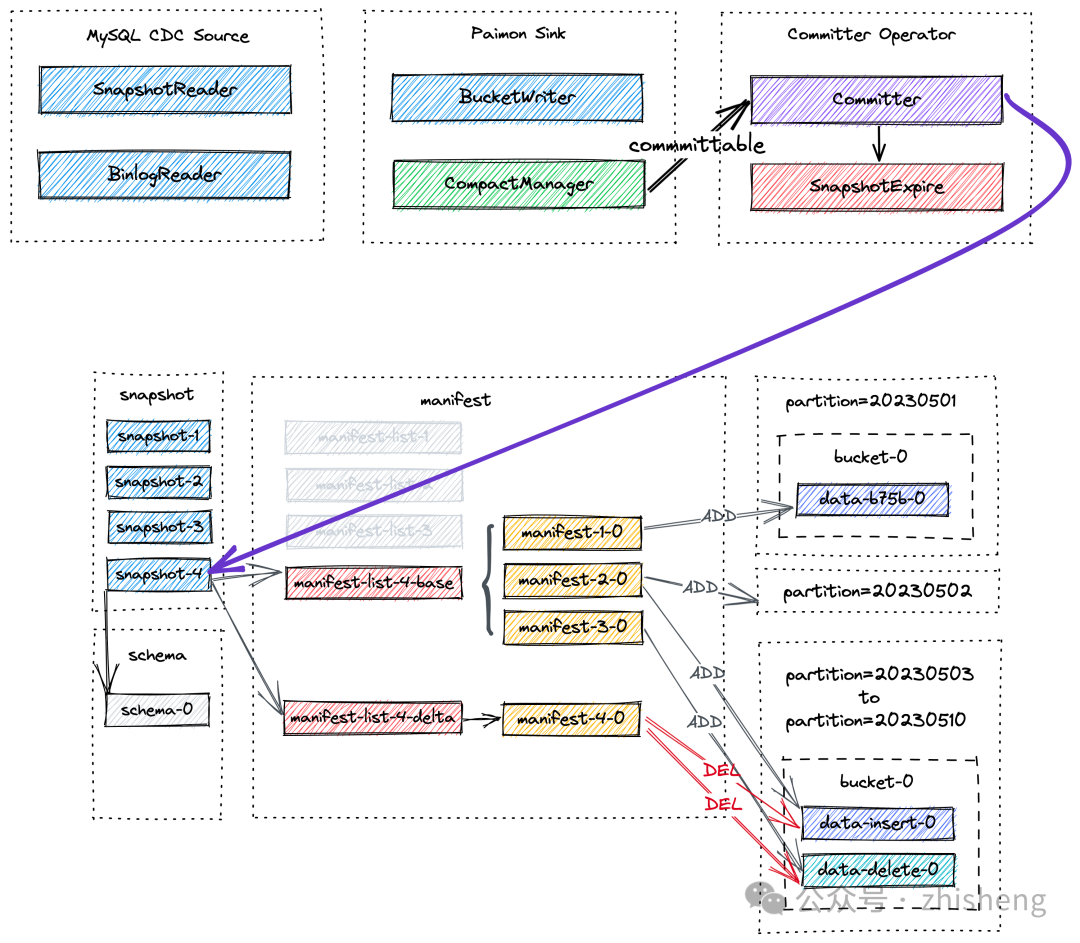
稍等一会后,可能会进行异步压缩,CompactManager 生成的可提交消息包含有关先前文件和合并文件的信息,以便 Committer Operator 可以构建相应的 manifest entries。在这种情况下,Committer Operator 在Flink Checkpoint 期间可能会生成两个 snapshot,一个用于写入的数据(类型为 Append 的快照),另一个用于压缩(类型为 Compact 的快照)。如果在 Checkpoint 间隔期间没有写入数据文件,则只会创建类型为Compact 的快照。Committer Operator 将检查 snapshot 的过期情况,并对标记为删除的数据文件执行物理删除操作。
















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











