






1.在Ubuntu14.04下创建hadoop组和hadoop用户
增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop的操作时,均使用该用户。
1、创建hadoop用户组

2、创建hadoop用户
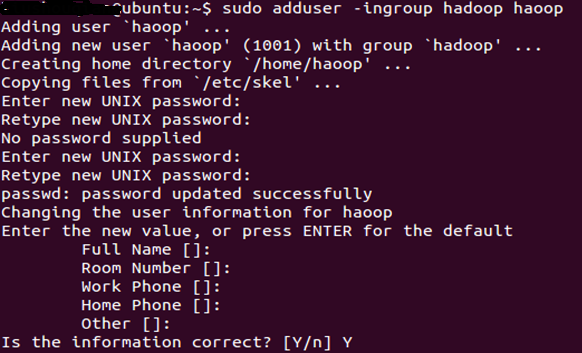
sudo adduser -ingroup hadoop hadoop
回车后会提示输入新的UNIX密码,这是新建用户hadoop的密码,输入回车即可。
如果不输入密码,回车后会重新提示输入密码,即密码不能为空。
最后确认信息是否正确,如果没问题,输入 Y,回车即可。
3、为hadoop用户添加权限
输入:sudo gedit /etc/sudoers
回车,打开sudoers文件
给hadoop用户赋予和root用户同样的权限

创建hadoop用户
如果你安装Ubuntu的时候不是用的hadoop用户,那么需要增加一个名为hadoop的用户,并将密码设置为hadoop。
创建用户
sudo useradd hadoop
修改密码为hadoop,按提示输入两次密码
sudo passwd hadoop
给hadoop用户创建目录,方可登陆
sudo mkdir /home/hadoop
sudo chown hadoop /home/hadoop
可考虑为 hadoop 用户增加管理员权限,方便部署,避免一些权限不足的问题:
sudo adduser hadoop sudo
最后注销当前用户,使用hadoop用户进行登陆。
安装SSH server、配置SSH无密码登陆
Ubuntu默认安装了SSH client,还需要安装SSH server。
sudo apt-get install openssh-server
集群、单节点模式都需要用到SSH无密码登陆,首先设置SSH无密码登陆本机。
输入命令
ssh localhost
会有如下提示(SSH首次登陆提示),输入yes。
SSH首次登陆提示SSH首次登陆提示
然后按提示输入密码hadoop,这样就登陆到本机了。但这样的登陆是需要密码的,需要配置成无密码登陆。
先退出刚才的ssh,然后生成ssh证书:
exit # 退出 ssh localhost
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
ssh-keygen -t rsa # 一直按回车就可以
cp id_rsa.pub authorized_keys
此时再用ssh localhost命令,就可以直接登陆了。
http://www.linuxidc.com/Linux/2015-02/113487.htm
四、安装hadoop
1.首先到https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/下载hadoop-2.7.2.tar.gz
2.解压并放在你希望的目录中。我放到了/usr/local/hadoop
sudotarxzfhadoop−2.7.2.tar.gz
sudo mv hadoop-2.7.2 /usr/local/hadoop
3.要确保所有的操作都是在用户hdsuer下完成的:
sudochown−Rhduser:hadoop/usr/local/hadoop五、配置 /.bashrc1.切换到hadoop用户,我的是hduser
su - hduser
2..查看java安装路径
update-alternatives - -config java
完整的路径为: /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
我们只取前面的部分 /usr/lib/jvm/java-7-openjdk-amd64
3.修改配置文件bashrc
$ sudo gedit ~/.bashrc
在文件末尾追加下面内容
HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=
PATH:
HADOOP_INSTALL/bin
export PATH=
PATH:
HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=
HADOOPINSTALLexportHADOOPCOMMONHOME=
HADOOP_INSTALL
export HADOOP_HDFS_HOME=
HADOOPINSTALLexportYARNHOME=
HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=
HADOOPINSTALL/lib/nativeexportHADOOPOPTS=”−Djava.library.path=
HADOOP_INSTALL/lib”
HADOOP VARIABLES END
4.修改/usr/local/hadoop/etc/hadoop/hadoop-env.sh
sudogedit/usr/local/hadoop/etc/hadoop/hadoop−env.sh找到JAVAHOME变量,修改此变量如下exportJAVAHOME=/usr/lib/jvm/java−7−openjdk−amd64至此,单机模式配置完毕,下面进行wordcount测试六、wordcount测试1.首先在hadoop目录下新建文件夹input
cd /usr/local/hadoop/
mkdirinput2.将README.txt文件拷贝到input文件夹下,以统计文件中单词的频数
sudo cp README.txt input
3.运行wordcount程序,并将输出结果保存在output文件夹下
每次重新执行wordcount程序的时候,都需要先把output文件夹删除!否则会出错
$ bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.2-sources.jar org.apache.hadoop.examples.WordCount input output
4.查看字符统计结果
$ cat output/*
七、伪分布模式配置
1.修改2个配置文件 core-site.xml 和 hdfs-site.xml,配置文件位于 /usr/local/hadoop/etc/hadoop/ 中
首先在hadoop目录下创建几个文件夹:
cd/usr/local/hadoop
mkdir tmp
mkdirtmp/dfs
mkdir tmp/dfs/data
mkdirtmp/dfs/name修改core−site.xml:
sudo gedit etc/hadoop/core-site.xml
修改为以下配置:
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
修改hdfs-site.xml:
$ sudo gedit etc/hadoop/hdfs-site.xml
修改为以下配置:
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
2.执行NameNode 的格式化
./bin/hdfs namenode -format
注意!只有刚创建hadoop集群的时候才需要格式化,不能对一个运行中的hadoop文件系统(HDFS)格式化,否则会丢失数据!!
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
3.启动hadoop
执行start-all.sh来启动所有服务,包括namenode,datanode.
start−all.sh在这里,如果出现了Error:Cannotfindconfigurationdirectory:/etc/hadoop,则通过下面方法解决:在hadoop−env.sh配置一条hadoop配置文件所在目录
sudo gedit etc/hadoop/hadoop-env.sh
加上export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
修改后如下图:
sourceetc/hadoop/hadoop−env.sh再次启动所有服务就好了 start-all.sh
启动时可能会出现如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable。该 WARN 提示可以忽略,并不会影响正常使用
4.通过jps命令判断是否成功启动:
出现这种情况后,在计算机中搜索jps,由于我的java安装路径是:/opt/jdk1.8.0_91,所以jps位于:/opt/jdk1.8.0_91/bin
cd/opt/jdk1.8.091/bin
./jps
若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”
5.通过web界面查看hdfs信息
转到http://localhost:50070/即可查看
如果不能加载出http://localhost:50070/,则可能通过下面的方法解决:
先执行NameNode 的格式化
./bin/hdfsnamenode−format出现提示输入Y/N时一定要输入大写Y!!!出现提示输入Y/N时一定要输入大写Y!!!出现提示输入Y/N时一定要输入大写Y!!!再执行start−all.sh来启动所有服务
start-all.sh
然后执行jps命令
cd/opt/jdk1.8.091/bin
./jps
再次转到网址http://localhost:50070/,就可以正常加载了。
6.停止运行hadoop
$ stop-all.sh
出现了no datanode to stop的提示:
解决方法:
在stop-all.sh之后,删除/tmp/dfs/data以及/tmp/dfs/name下的所有内容,如下图所示,均包含一个current文件夹:
因此只需删除current文件夹
删除之后,再次格式化namenode、启动所有服务start-all.sh、并停止stop-all.sh,就可以正常stop datanode了。
http://www.cnblogs.com/kinglau/p/3794433.html
http://blog.csdn.net/panglinzhuo/article/details/51317719














 3370
3370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









