







俗话说的好:“好记性不如烂笔头” 开发了很长时间,突然对MapReduce的处理过程中详细的步骤和细节内容忘的差不错,只记得大概是什么样的,突然问道弄得思路不清晰,真是 。
。
本文只对MapReduce 执行过程做分析,例如:两个文件 test1.txt test2.txt ;
test1.txt 中的内容为 :
Hello World
Bye World
test2.txt 中的内容为 :
Hello Hadoop
Bye Hadoop
把 上面的文件放在hdfs上某个目录下具体怎么放不做讲述。
主要解剖一下整个过程MapReduce 是怎么计算和处理的。
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如图4-1所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。
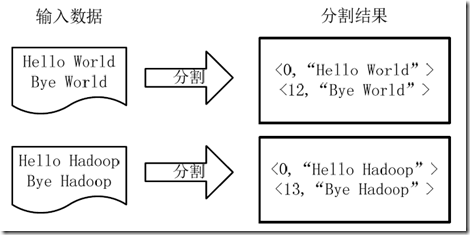
图4-1 分割过程
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如图4-2所示。

图4-2 执行map方法
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,分组,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如图4-3所示。

图4-3 Map端排序及Combine过程
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,处理过程包括合并,排序,得到新的<key,value>对,并作为WordCount的输出结果,如图4-4所示。
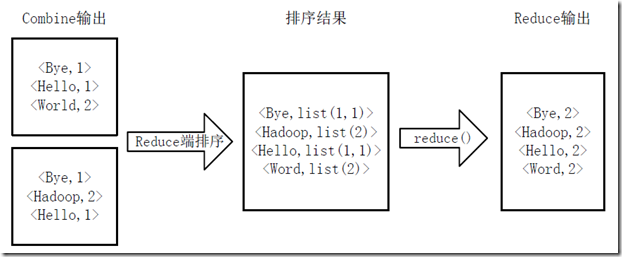
图4-4 Reduce端排序及输出结果
Map 分为几个步骤:
1、 第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值128MB,输入文件有两个,一个是64MB,一个是144MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper进程处理。这里的三个输入片,会有三个Mapper进程处理。
2、 第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
3、 第三阶段是对第二阶段分割好的键值对,交给Map方法去处理,可以根据相应的分隔符(制表符\t、,、;、@@)等等形成新的键值对
4、 对新的键值对进行分区,默认为一个分区形成
5、 Mapper 会将他们按照key 的方式排序,形成图4-2的形式,然后进行分组 形成
<hello {1 2 3 4 }>
<world {1 1 3 5}>
<Bye {1 3 5 6}>
6、(可选)对分组后的进行归纳(Combiner)
Reduce 阶段
1、 多个Map的任务的输出,按照不同的分区,通过网络copy到不同的Reduce节点上。
2、 对多个map输出的结果进行合并,排序,分组,处理后产生新的键值对
3、 多Reduce输出的键值对写到HDFS上
参考文章:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}