






一、避免生产端丢失消息
1、生产者使用带回调函数的方法,发送消息,根据回调函数返回的信息判断消息是否成功发送到kafka,如若失败则将数据保存起来,等服务正常了尝试重新发送
System.out.println("主线程:"+Thread.currentThread().getName());
ListenableFuture<SendResult> future = kafkaTemplate.send(newTopic.name(),1,null,"value"+num);
//SendResult sr = future.get(); //同步阻塞等待发送结果
future.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable throwable) {
KafkaProducerException kpe = (KafkaProducerException)throwable;
//拿到发送失败的记录
System.out.println(kpe.getProducerRecord());
System.out.println(":fail");
}
@Override
public void onSuccess(Object o) {
System.out.println(":success"+Thread.currentThread().getName());
}
});2、设置acks参数,acks参数的意义
- acks=0,表示生产者不等待任何服务器节点的响应,只要发送消息就认为成功。
- acks=1,表示生产者收到 leader 分区的响应就认为发送成功。
- acks=-1,表示只有当 ISR(主节点中记录的所有副节点信息)中的副本全部收到消息时,生产者才会认为消息生产成功了。这种配置是最安全的,因为如果 leader 副本挂了,当 follower 副本被选为 leader 副本时,消息也不会丢失。但是系统吞吐量会降低,因为生产者要等待所有副本都收到消息后才能再次发送消息
ISR是什么
每个分区都有自己的一个 ISR 集合。但不是所有的副本都会在这个集合里,首先 leader 副本是在 ISR 集合里的,如果一个 follower 副本的消息没有落后 leader 副本太长时间,那这个 follower 副本也在 ISR 集合里;可是如果有一个 follower 副本长时间没有同步 leader 的数据,就会从 ISR 集合里被淘汰出去。
当 ISR 中的 follower 完成数据的同步之后,leader 就会给 producer 发送 ack,而如果Leader 发生故障,就会从 ISR 中选举出新的 leader
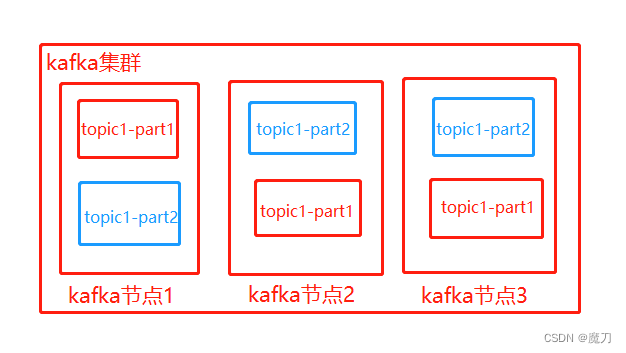
如上图,三个kafka服务集群,topic1有两个partition(part1、part2),每个partition分区有3个副本(注意:三个其实都是副本,只不过有leadr、follower的区别,如上可能kafka节点1的分区是leader副本,其他两个是follower副本)
二、kafka服务端不丢失消息
unclean.leader.election.enable 设置为 false(否则可能丢失消息),只有这样非 ISR 集合的副本才不会被选为分区的 leader 副本。但是这样做也降低了可用性,因为如果ISR集合的副本全挂了,那这个分区就没有 leader了,就无法收发消息了,但是消息会发送到别的分区 leader 副本,也就是说分区的数量实际上减少了。
三、消费端不少消费消息
设置enable.auto.commit=false,手动向服务端提交消息偏移量;
- 消费者消费消息是有两个步骤的,1、拉取消息,然后再处理消息。2、向服务端提交消息偏移量(可以手动提交也可以自动提交)。如果把参数 enable.auto.commit 设置为 true 就表示消息偏移量是由消费端自动提交,由异步线程去完成的,业务线程无法控制。如果刚拉取了消息之后,业务处理还没进行完,这时提交了消息偏移量但是消费者却挂了,这就造成这部分业务消息的丢失;
- 当然手动提交偏移量,虽然不会丢失数据,但是有可能出现重复消费的情况,比如:消费者消费完一组业务数据后,提交偏移量时消费者服务宕机了,等消费者再次上线,由于偏移量未提交成功,那这部分业务数据就会被重复处理
不能少消费当然也不能重复消费
在生产者端,为每个消息生成唯一标识符,用以检测每条消息是否已经被消费过,即参考幂等性的思想解决该问题
除此之外,还有另外一种情况也会出现重复消费,在Kafka里面有一个叫Partition Balance的一个机制,就是把多个Partition均衡地分配给多个消费者。那么Comsumer会从分配的Partition里面去消费消息。如果Consumer在默认的5分钟以内没办法处理完这一批消息的时候,就会触发Kafka的Rebalance的一个机制,从而导致Offset自动提交失败,而在重新Rebalance以后,Consumer端还是会从之前没有提交的Offset的位置开始去消费,从而导致重复消费的一个问题。

















 1114
1114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











