







静态声明的全局内存变量声明在全局作用域,不能在主机端代码中直接用&取值,所以不能用cudaMemcpy进行内存复制
__device__ Type deviceData; __global__ void kernelFunc() { data = ... } int main() { Type hostData; cudaMemcpyToSymbol(deviceData,&hostData,sizeof(Type); kernelFunc <<<1,1>>>(); cudaMemcpyFromSymbol(&value,deviceData,sizeof(Type));}
动态声明
__global__ void kernelFunc(Type * deviceData) { ... } int main() { Type * deviceData; cudaMalloc(&deviceData,nBytes); cudaMemcpy(deviceData,hostData,nBytes,cudaMemcpyHostToDevice); kernekFunc(deviceData); cudaMemcpy(hostData,deviceData,nBytes,cudaMemcpyDeviceToHost); cudaFree(deviceData); }主机到设备的内存传输实际经过两个步骤:
Pageable Memory -> Pinned Memory
Pinned Memory -> device memory
Pinned Memory是主机中不会被换到虚拟内存中的内存,在数据复制时隐式创建,复制完成后会自动销毁。为了提高主机到设备内存复制的速度,可以手动申请一段Pinned Memory,但也必须手动地释放。cudaError_t cudaMallocHost(void **devPtr, size_t count); cudaError_t cudaFreeHost(void *ptr);零复制内存是主机上一段Pinned Memory,设备端可以直接通过PCI-E总线访问并会缓存在Cache中。由于主机和设备地址空间不同,零复制内存在主机上的地址需要进行地址映射后才能在设备端使用
//零复制内存申请 cudaError_t cudaHostAlloc(void **pHost, size_t count, unsigned int flags); //主机到设备的地址映射 cudaError_t cudaHostGetDevicePointer(void **pDevice, void *pHost, unsigned int flags);零内存复制的使用注意点:
只有当计算足够密集以掩盖PCI-E总线读取的延迟时才使用零复制内存
使用零复制内存时要在主机和设备间进行同步动态分配的内存可以是linear memory(线性内存不一定是一维的,也可以是二维或三维的)或CUDA arrays,后者主要用于存储纹理)
//分配linear memory cudaMalloc cudaMallocPitch cudaMalloc3D cudaHostAlloc //分配CUDA array cudaMallocArray cudaMalloc3DArraycudaMallocPitch一般用于二维线性数组,当width小于k * 128(k为整数)时,cuda会自动为每一行填充内存,实际每行的长度通过pitch返回。所以分配的总内存为height * (width + pitch)
cudaError_t cudaMallocPitch(void ** devPtr, size_t * pitch, size_t width, size_t height)- 全局内存传输
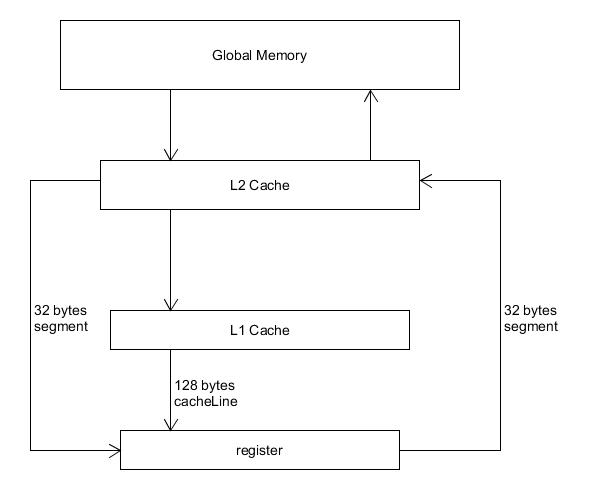
cudaArray
- cudaArray是专门用于作为纹理内存的一种全局内存,对GPU而言只读,可以是一维,二维或三维的。kernel不能直接访问cudaArray,需要将纹理对象或纹理引用与cudaArray绑定后,访问纹理对象或纹理引用
计算能力2.0以上的显卡架构能够利用surfaces,在gpu端修改cudaArray
创建CUDAMallocArray
cudaError_t cudaMallocArray(struct cudaArray ** array, const struct cudaChannelFormatDesc * desc, size_t width, size_t height = 0, unsigned int flags = 0); struct cudaChannelFormatDesc { int x, y, z, w; //每个通道的位数 enum cudaChannelFormatKind f; //通道的数据类型 };















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









