







 本文介绍如何使用Selenium和Python实现企查查网站的自动化登录过程,通过微博账号授权登录绕过滑块验证,成功获取并打印腾讯公司详细信息,包括名称、注册资本、成立日期、邮箱及电话等。
本文介绍如何使用Selenium和Python实现企查查网站的自动化登录过程,通过微博账号授权登录绕过滑块验证,成功获取并打印腾讯公司详细信息,包括名称、注册资本、成立日期、邮箱及电话等。

从企查查爬取企业信息,如果没有登录直接检索,邮箱、电话都被隐藏了
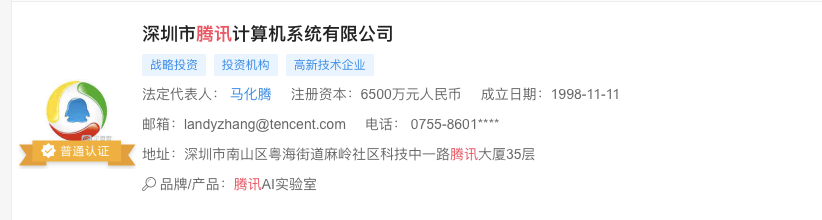
点击详情,部分信息同样会被隐藏
毕竟只是打工的,没钱不能任性!
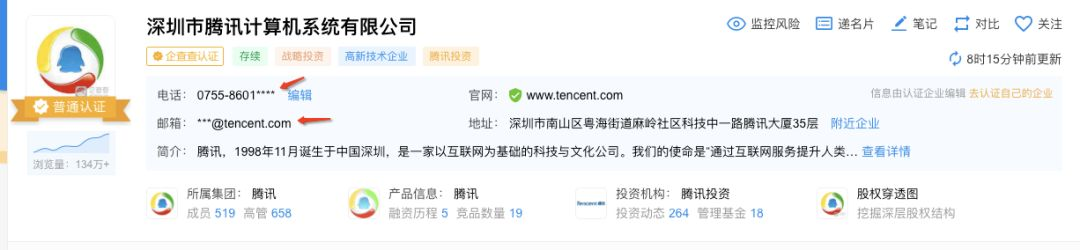
想要查看更完整的企业信息,只有登录了。
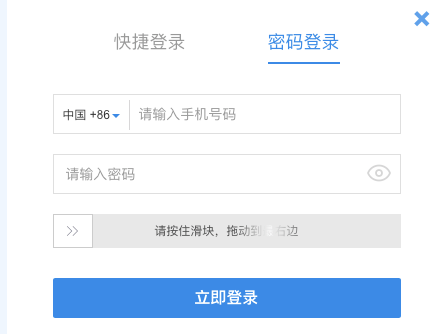
但登录需要滑块验证,有时可能还会有图片验证码

但我干不过他们,老大不提供资金支持,那就只能另辟蹊径了。
突然看到右下角有三小只,不禁有点想法了
是不是可以通过授权的形式进行登录呢,那就开始吧
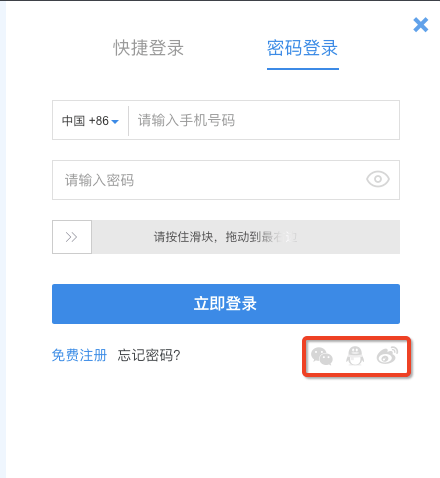
那就拿三小只试试:

首先通过微博登录,将该绑定的绑定,该授权的授权,避免登录后让验证
(微博授权 + 手机号绑定 + 竟然还让关注了公众号)
账号准备完毕,上代码
from selenium import webdriver
import time
import xlwt
import sys
import imp
imp.reload(sys)
# 伪装成浏览器,防止被识破
option = webdriver.ChromeOptions()
option.add_argument(
'--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"')
driver = webdriver.Chrome(chrome_options=option)
# 打开登录页面
driver.get('https://www.qichacha.com/user_login')
# 单击用户名密码登录的标签
tag = driver.find_element_by_xpath('//*[@id="normalLogin"]')
tag.click()
tag = driver.find_element_by_xpath('//*[@class="btn-weibo m-l-xs"]')
tag.click()
# 将用户名、密码注入
driver.find_element_by_id('userId').send_keys('微博账号')
driver.find_element_by_id('passwd').send_keys('微博密码')
time.sleep(3) # 休眠,人工完成验证步骤,等待程序单击“登录”
# 单击登录按钮
btn = driver.find_element_by_xpath('//*[@id="outer"]/div/div[2]/form/div/div[2]/div/p/a[1]')
btn.click()
time.sleep(10)
# inc_list = ['阿里巴巴', '腾讯', '今日头条', '滴滴', '美团']
# inc_len = len(inc_list)
driver.find_element_by_id('searchkey').send_keys("腾讯")
# 单击搜索按钮
srh_btn = driver.find_element_by_xpath('//*[@id="indexSearchForm"]/div/span/input')
srh_btn.click()
# 获取首个企业文本
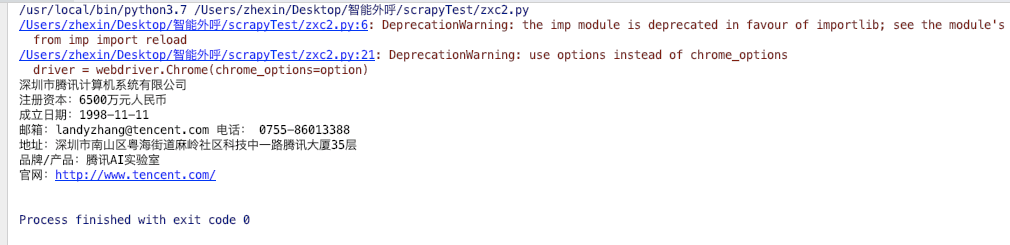
inc_full = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/a').text
print(inc_full)
money = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[1]/span[1]').text
print(money)
date = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[1]/span[2]').text
print(date)
mail_phone = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[2]').text
print(mail_phone)
addr = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[3]').text
print(addr)
try:
stock_or_others = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[4]').text
print(stock_or_others)
except:
pass
# 获取网页地址,进入
inner = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/a').get_attribute("href")
driver.get(inner)
# 单击进入后 官网 通过href属性获得:
inc_web = driver.find_element_by_xpath(
'//*[@id="company-top"]/div[2]/div[2]/div[3]/div[1]/span[3]/a').get_attribute("href")
print("官网:" + inc_web)
print(' ')
driver.close()
信息获取完整,ok




















 2230
2230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











