







一、Excel -> Html
需求如下:
对现有excel文档做分类处理,处理了结果以邮件形式发送!
分析:
因为是excel文件处理,处理的结果需要展示在邮件中。
截图实现:打开处理的excel结果文件,截图,添加截图。因excel无法展示放弃。
文件转换:将excel结果文件转为邮件源码Html代码进行展示。
代码实现:
import openpyxl
from dominate.tags import *
import dominate
def excel_html(file_path):
wd = openpyxl.load_workbook(file_path)
ws = wd.active
data = get_data(ws)
return to_html(data)
def get_data(wt):
ws_data = []
for row in wt:
row_data = []
for cell in row:
if isinstance(cell, openpyxl.cell.cell.Cell):
row_data.append(cell.value)
else:
row_data.append("merge")
ws_data.append(row_data)
data = []
for row_index, row in enumerate(ws_data):
row_data = []
for cell_index, cell in enumerate(row):
if cell != "merge":
row_span = 1
col_span = 1
for cell_back in row[cell_index:]:
if cell_back == "merge":
row_span+=1
continue
break
for row_back in ws_data[row_index+1:]:
if row_back[cell_index] == "merge":
col_span+=1
continue
break
row_data.append({"value": cell, "rowspan":row_span, "colspan": col_span})
data.append(row_data)
return data
def to_html(data):
doc = dominate.document(title='excel-to-html')
with doc:
with div(id='excel_table').add(table(style="border-collapse: collapse; border-color: rgb(102, 102, 102); border-width: 1px; border-style: solid;")):
for row in data:
table_row = tr()
for value in row:
with table_row.add(td(
style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);",
rowspan=value.get("colspan"),
align="center",
colspan=value.get("rowspan"))):
p(value.get("value"))
return str(doc)
if __name__ == '__main__':
file_path = r"/Users/Young/Downloads/AS1-发票分类明细.xlsx"
ret = excel_html(file_path)
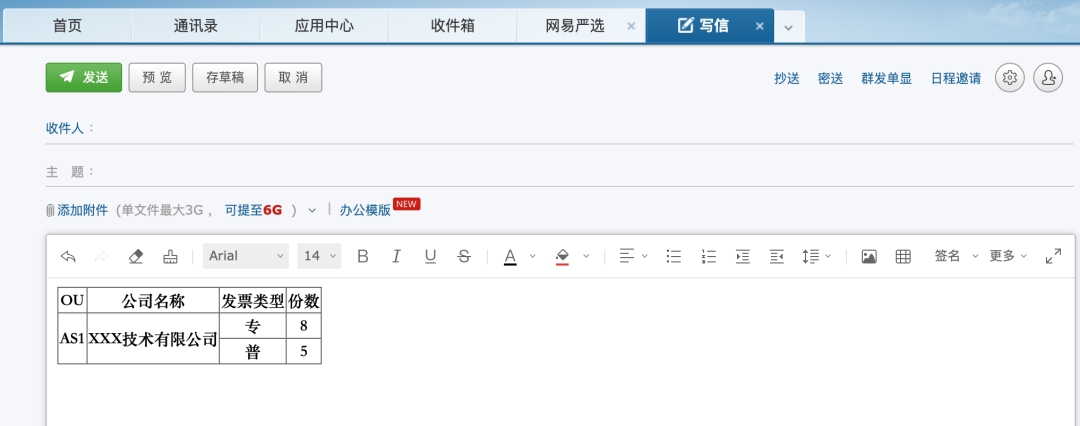
print(ret)原excel文件

转换后的代码:
<!DOCTYPE html>
<html>
<head>
<title>excel-to-html</title>
</head>
<body>
<div id="excel_table">
<table style="border-collapse: collapse; border-color: rgb(102, 102, 102); border-width: 1px; border-style: solid;">
<tr>
<td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>OU</p>
</td>
<td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>公司名称</p>
</td>
<td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>发票类型</p>
</td>
<td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>份数</p>
</td>
</tr>
<tr>
<td align="center" colspan="1" rowspan="2" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>AS1</p>
</td>
<td align="center" colspan="1" rowspan="2" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>XXX技术有限公司</p>
</td>
<td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>专</p>
</td>
<td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>8</p>
</td>
</tr>
<tr>
<td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>普</p>
</td>
<td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
<p>5</p>
</td>
</tr>
</table>
</div>
</body>
</html>效果图:

一、Pdf -> Text
需求:
获取pdf文件部分信息
处理方式:
先转为text内容,然后通过正则获取关键信息
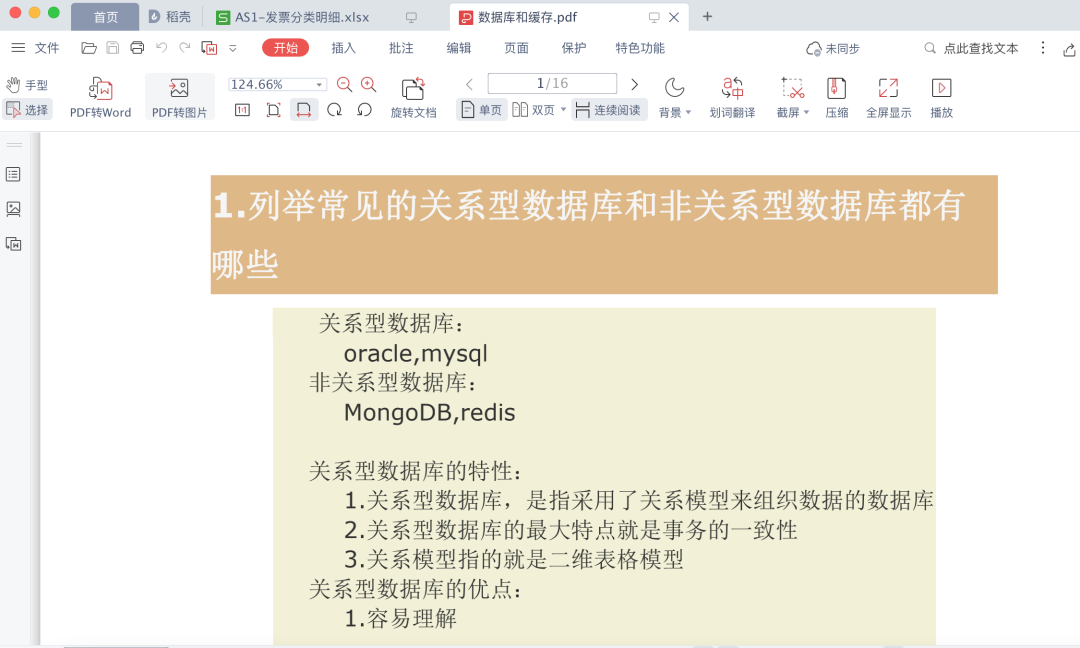
pdf转文本代码:
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import XMLConverter, HTMLConverter, TextConverter
from pdfminer.layout import LAParams
import io
class PDFParser(object):
"""PDF 解析器类"""
pdf_file_path: str
def __init__(self, pdf_file_path):
"""
:param pdf_file_path: pdf文件路径
:return:
"""
self.pdf_file_path = pdf_file_path
def to_text(self):
"""
将pdf转化为文字
:return: 文件文本信息
"""
fp = open(self.pdf_file_path, 'rb')
rsrcmgr = PDFResourceManager()
retstr = io.StringIO()
codec = 'utf-8'
laparams = LAParams()
# device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
# Create a PDF interpreter object.
interpreter = PDFPageInterpreter(rsrcmgr, device)
# Process each page contained in the document.
for page in PDFPage.get_pages(fp):
interpreter.process_page(page)
fp.close()
return retstr.getvalue()
if __name__ == '__main__':
file_path = r"/Users/Young/Downloads/数据库和缓存.pdf"
pdf = PDFParser(file_path)
ret = pdf.to_text()
print(ret)处理结果
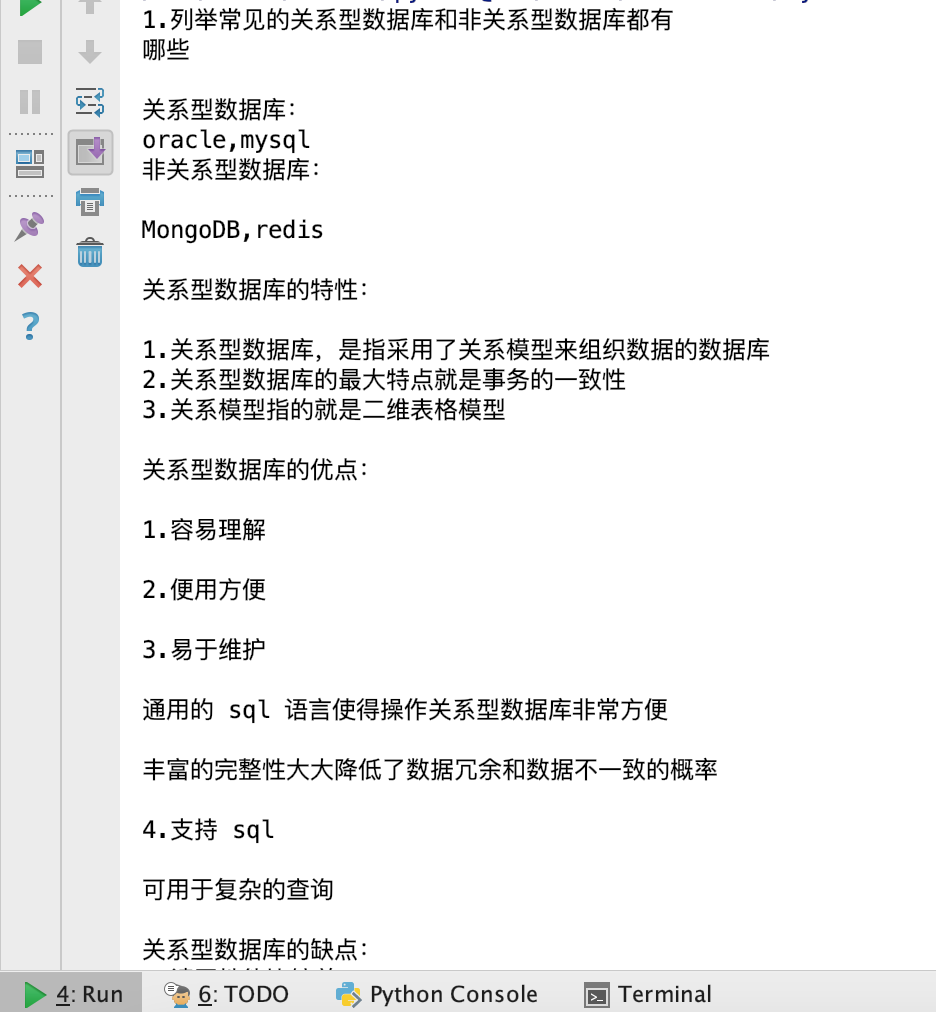
















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











