









http://blog.csdn.net/jinzhuojun/article/details/8579416
本文将基于OpenCV实现简单的数字识别。这里以游戏Angry Birds为例,通过以下几个主要步骤对其中右上角的分数部分进行自动识别。
1. 学习分类器
根据训练样本,选取模型训练产生数字分类器。这里的样本可以是通用的数字样本库(如NIST等),也可以是针对应用场景而制作的专门训练样本。前者优在泛化性,后者强在准确率,当然常用做法是将这两者结合,即在通用数字库基础上做修改。另外这里由于模式并不复杂,计算量也不大,所以不对样本进行特征提取,对原始样本作简单变换后直接作为训练样本。
具体地,首先是生成训练样本矩阵,一般样本是以二维矩阵的方式存在文件当中,现在要将它们读出来,进行适当的预处理,然后生成OpenCV能理解的数据结构。
train_X = cvCreateMat(sample_num * class_num, size * size, CV_32FC1);
train_Y = cvCreateMat(sample_num * class_num, 1, CV_32FC1);
for(i = 0; i < class_num; i++){
for(j = 0; j < sample_num; j++){
src_image = cvLoadImage(file,0);
pimage = preprocessing(src_image, size, size);
...
cvGetRow(train_X, &row, i * sample_num + j);
row_vec = cvReshape(&data, &mathdr, 0, 1);
cvCopy(row_vec, &row, NULL);
...
cvGetRow(train_Y, &row, i * sample_num + j);
cvSet(&row, cvRealScalar(i));
}
} 训练样本中的数字位置形态各异,因此读入时需要进行规整化。主要方法是先找到数字的边界框,然后以宽和高中大的一边为基准进行缩放和拉伸,从而使得其可以占满整个表示单个样本的矩阵。
IplImage preprocessing(IplImage* img, int w, int h){
...
bb = findBoundingBox(img);
cvGetSubRect(img, &data, cvRect(bb.x, bb.y, bb.width, bb.height));
size = (bb.width > bb.height) ? bb.width : bb.height;
res = cvCreateImage(cvSize(size, size), 8, 1);
x = floor((float)(size - bb.width) / 2.0f);
y = floor((float)(size - bb.height) / 2.0f);
cvGetSubRect(res, &subdata, cvRect((int)x, (int)y, bb.width, bb.height));
cvCopy(&data, &subdata, NULL);
ret = cvCreateImage(cvSize(w, h), 8, 1);
cvResize(res, ret, CV_INTER_NN);
return *ret;
} 假设单个样本可表示为0/1矩阵,那findBoundingBox()只要从x和y方向分别扫描最大最小的非0值就可以了。 训练样本准备好后,在OpenCV中创建相应的分类器非常方便。这里用的是KNN,当然除了KNN外还有其它很多封装好的分类器(如NN, SVM等)
knn = new CvKNearest(train_X, train_Y, 0, false, K); 2. 图像预处理
前面通过学习产生了分类器,但我们输入图像中的数字并不能直接作为测试输入。图像中的数字笔画有时并不规整,还可能相互重叠。因为本文例子为了简化用的是屏幕截图,所以位置形变校正,色彩亮度校正等等都省去了,但仍需要一些简单处理。下面先对输入图像进行一把简单的预处理,主要目的是将数字之间两两分开。方法很简单,首先将图像转成二值图,然后腐蚀一把,数字之间就分离得比较开了,这样便于我们下一步分割和识别。这样做还有个好处,就是把其余的噪声也顺带去掉了。
cvtColor(input, out_img, CV_BGR2GRAY);
threshold(out_img, out_img, 0, 255, CV_THRESH_OTSU + CV_THRESH_BINARY);
...
erode(out_img, out_img, elem); 结果:
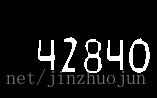
3. 图像分割
接下来,就可以对图像进行分割了。由于我们的分类器只能对数字一个一个地识别,所以首先要把每个数字分割出来。基本思想是先用findContours()函数把基本轮廓找出来,然后通过简单验证以确认是否为数字的轮廓。对于那些通过验证的轮廓,接下去会用boundingRect()找出它们的包围盒。
vector< vector< Point> > contours;
findContours(contour_img, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
vector<vector<Point> >::iterator it = contours.begin();
while (it!=contours.end()) {
RotatedRect rect = minAreaRect(Mat(*it));
if(verifyRect(rect)){
++it; // A valid rectangle found
} else {
it= contours.erase(it);
}
}
...
vector<Rect> boundRect(contours.size());
for (int i = 0; i < contours.size(); ++i) {
Scalar color = Scalar(200, 200, 200);
boundRect[i] = boundingRect(Mat(contours[i]));
rectangle(out_img, boundRect[i].tl(), boundRect[i].br(), color, 0.2, 8, 0);
CvRect roi = CvRect(boundRect[i]);
IplImage orig = out_img;
IplImage *res = cvCreateImage(cvSize(roi.width, roi.height), orig.depth, orig.nChannels);
cvSetImageROI(&orig, roi);
cvCopy(&orig, res);
cvResetImageROI(&orig);
IplImage *bininv_img;
bininv_img = cvCreateImage(cvSize(128, 128), IPL_DEPTH_8U, 1);
cvResize(res, bininv_img);
cvThreshold(bininv_img, bininv_img, 100, 255, CV_THRESH_BINARY_INV);
int ret = do_ocr(bininv_img);
res_elem elem;
elem.num = ret;
elem.xpos = boundRect[i].tl().x;
res_vec.push_back(elem);
...
} 结果:

4. 应用分类器
分割完后就可以应用我们前面训练好的分类器对分割结果进行识别了。当然,如果感觉结果不满意,可以将分类错误的样本加上正确的标签后放入训练样本重新生成分类器,使得分类器能够有更好的识别率。上一步中的do_ocr()函数就是利用先前训练好的分类器识别单个数字。注意训练样本进行过怎么样的预处理,这里也一样要做。
int do_ocr(IplImage *img)
{
...
pimage = preprocessing(img, size, size);
...
cvGetSubRect(pimage, &data, cvRect(0, 0, size, size));
CvMat mathdr, *vec;
vec = cvReshape(&data, &mathdr, 0, 1);
ret = knn->find_nearest(vec, K, 0, 0, nearest, 0);
return (int)ret;
}
5. 后期处理
因为分割图像时查找数字轮廓并不保证是按顺序来的,所以这儿要将识别结果按分割时输出的包围盒位置信息进行排序,最后将它们转换成数字输出。
sort(res_vec.begin(), res_vec.end(), sort_func);
int j, num = 0;
for (j = 0; j < res_vec.size(); ++j) {
num = num * 10 + res_vec[j].num;
}
char resbuf[256];
sprintf(resbuf, "%d", num);
putText(show_img, resbuf, Point(OUTPUT_X, OUTPUT_Y), FONT_HERSHEY_SIMPLEX, 0.8, Scalar(0, 255, 0), 2);
imshow("show", show_img); 结果:
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









