







目录
前言
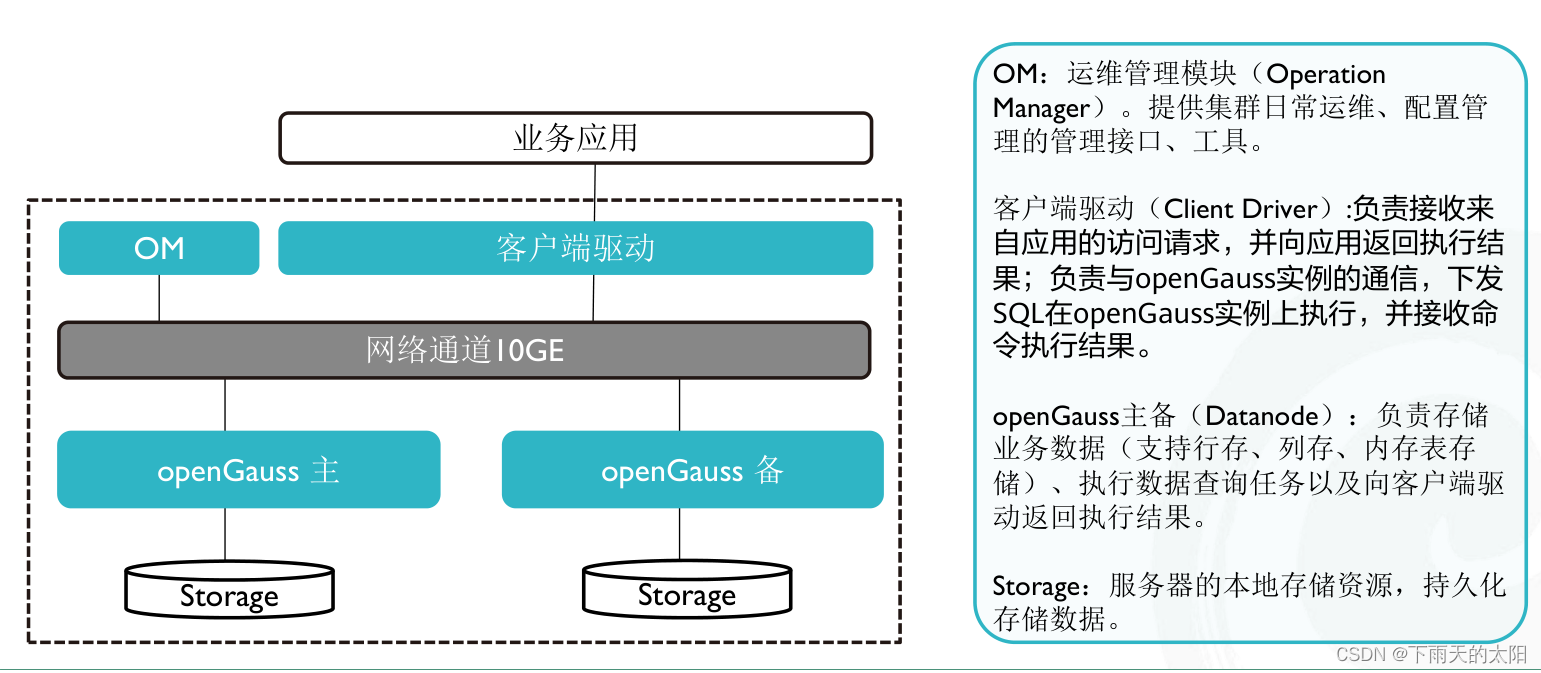
openGauss数据库系统架构
1. 启动/停止/重启数据库
(1)极简版启动/停止/重启命令
启动数据库实例
gs_ctl start -D $GAUSSHOME/data/single_node -Z single_node
停止数据库实例
gs_ctl stop -D $GAUSSHOME/data/single_node -Z single_node
重启数据库实例
gs_ctl restart -D $GAUSSHOME/data/single_node -Z single_node
(2)企业版启动/停止/重启命令
启动数据库实例
gs_om -t start
或者是
gs_ctl start -D /opt/huawei/install/data/dn
停止数据库实例
gs_om -t stop
或者是
gs_ctl stop -D /opt/huawei/install/data/dn
重启数据库实例
gs_om -t restart
或者是
gs_om -t stop && gs_om -t start
查看数据库实例状态
gs_om -t status
或者是
gs_ctl status -D /opt/huawei/install/data/dn
2. 登录数据库
以初始化安装用户登录数据库,不需要输入密码
gsql -d postgres -p 5432
以初始化安装用户登录数据库,不需要输入密码,并且进入之后可编辑操作语句
gsql -d postgres -p 5432 -r
以创建的用户(jamy)登录数据库,需要输入密码
gsql -d test -p 5432 -U jamy
以创建的用户(jamy)登录数据库,需要输入密码,并且进入之后可编辑操作语句
gsql -d test -p 5432 -U jamy -r
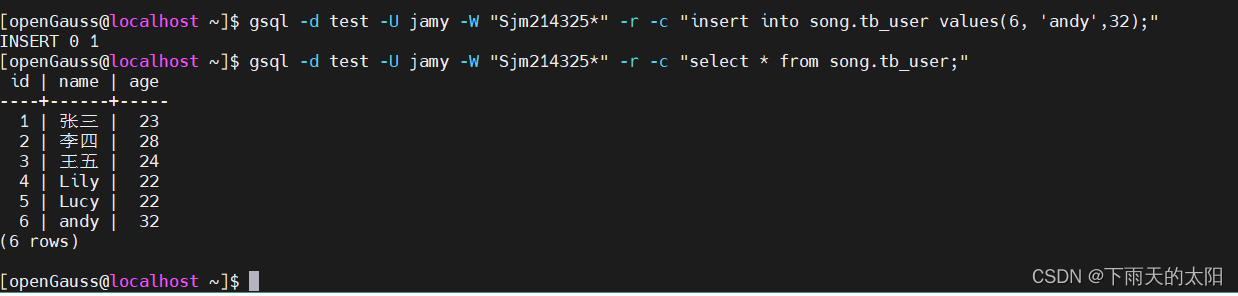
直接非交互模式登录数据库并执行sql,执行完sql立即退出
gsql -d test -U jamy -W "Sjm214325*" -r -c "insert into song.tb_user values(6, 'andy',32);"
gsql -d test -U jamy -W "Sjm214325*" -r -c "select * from song.tb_user;"
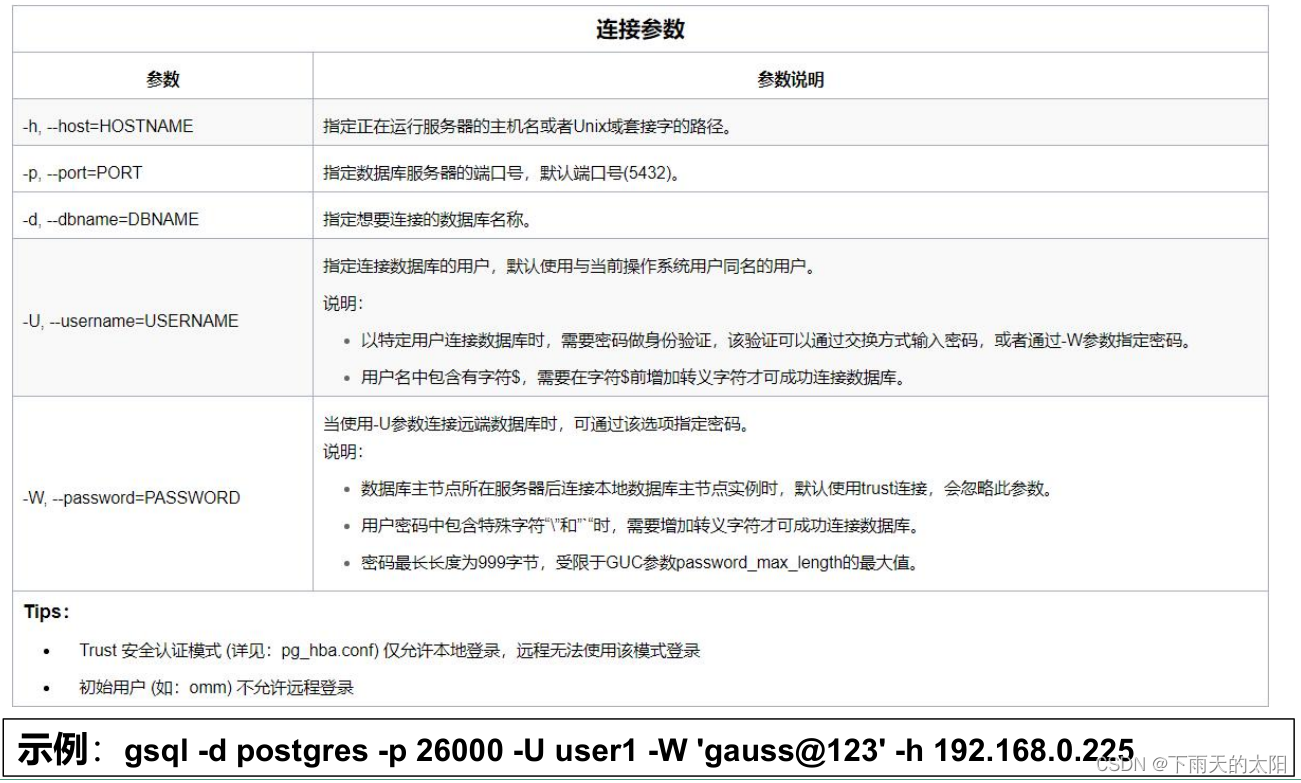
(1)登录数据库时的基本连接参数
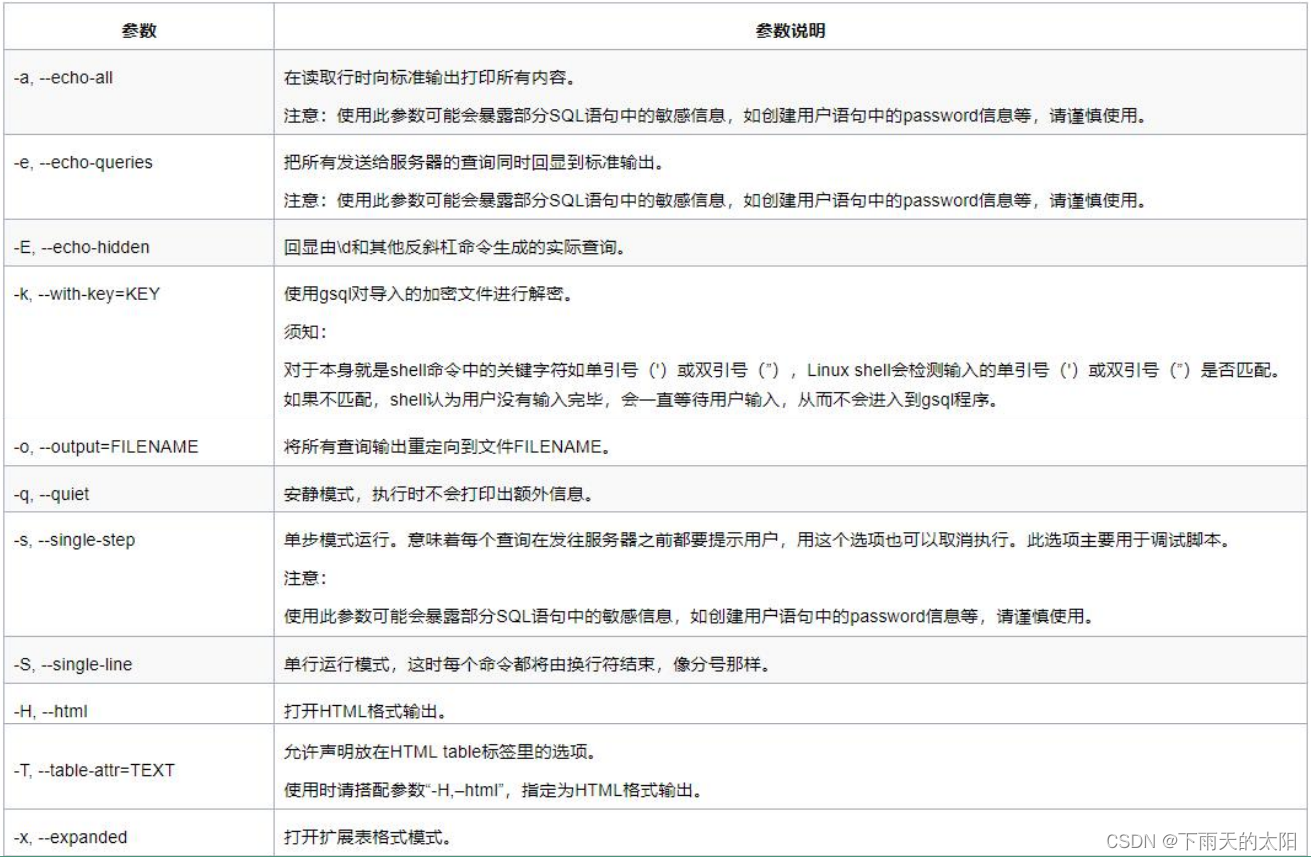
(2)登录数据库时的常用连接参数

(3)登录数据库时的其他连接参数
3. 数据库元命令
(1)登录之后可以输入下面这些命令操作数据库:
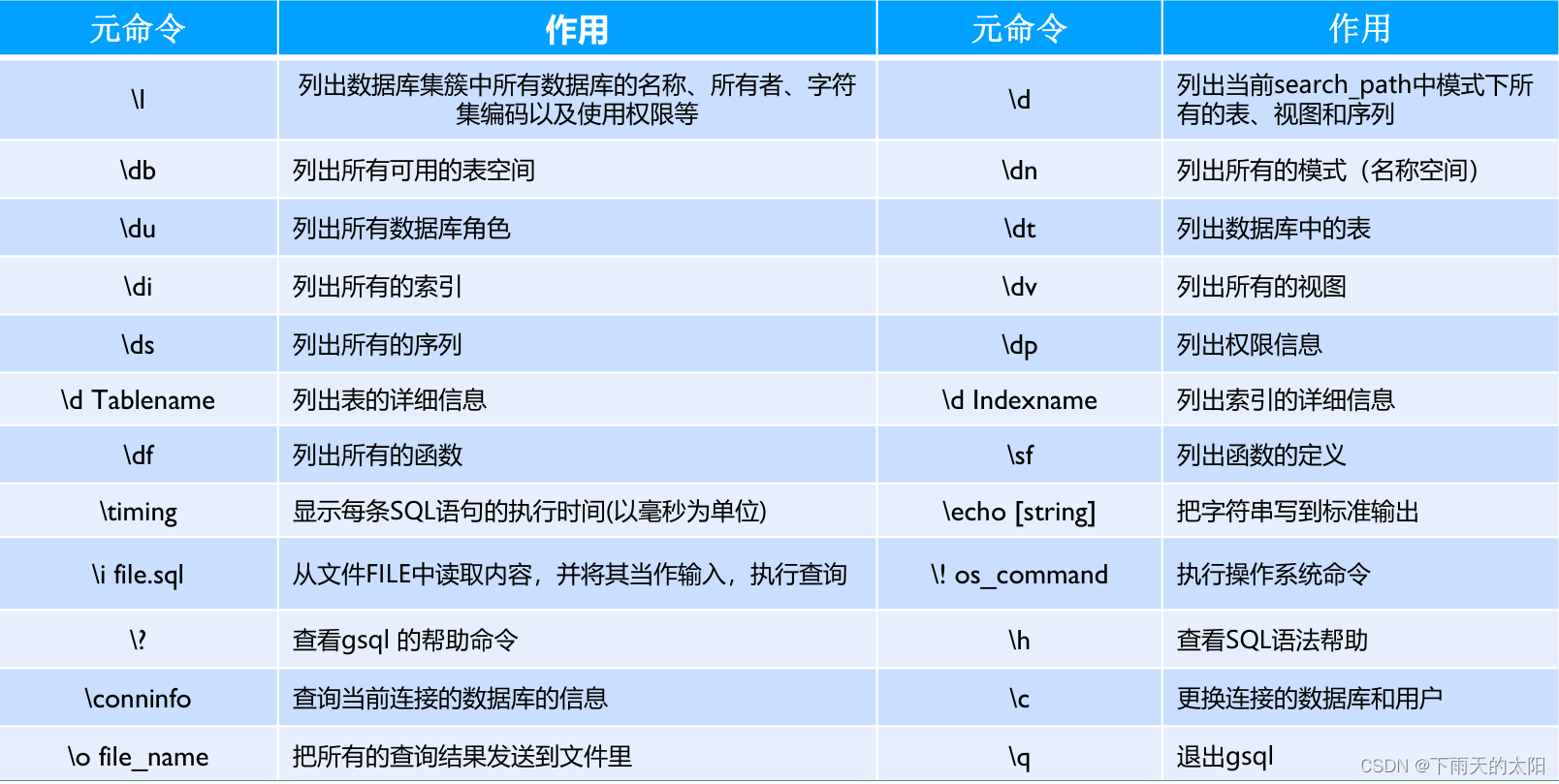
(2)操作案例
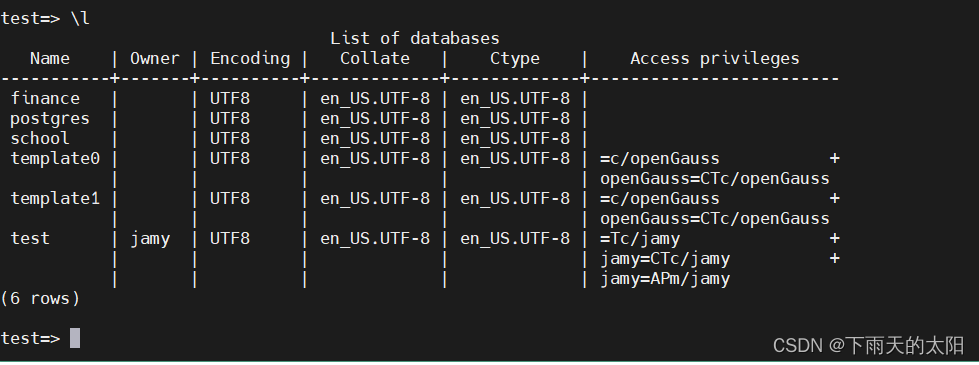
查询所有数据库的信息,包括数据库的名称,属主,字符集编码以及使用权限
\l
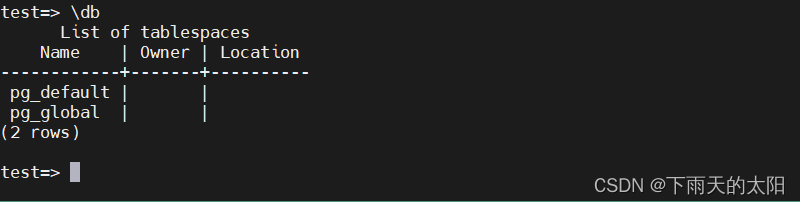
查询出所有可用的表空间
\db
列出所有的数据库角色
\du

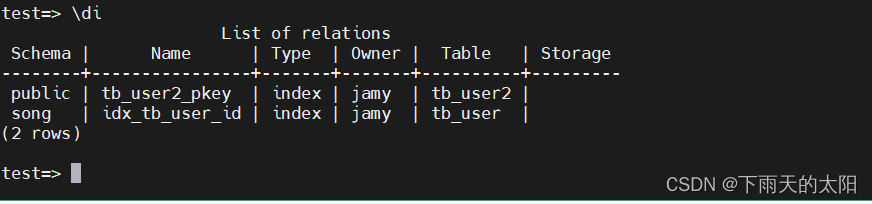
列出所有的索引
\di
列出所有的序列
\ds

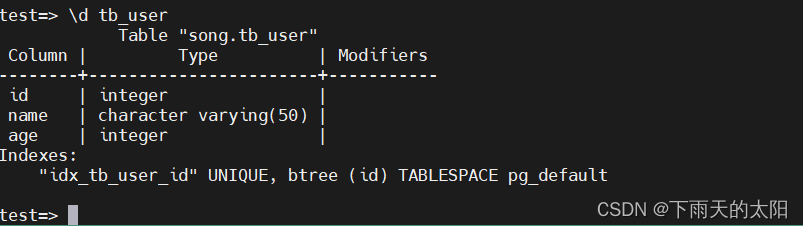
列出具体表的详细信息
\d tableName
列出所有的函数
\df
待更新
在执行结果的最下方显示每条sql语句的执行时间(临时有效),单位毫秒
\timing
test=> \timing
Timing is on.
test=> select * from employee;
em_id | em_name | em_age | em_sex | em_deptno | em_addr
-------+---------+--------+--------+-----------+-----------
1 | andy | 23 | 2 | 100 | 上海市
2 | jamy | 26 | 1 | 101 | 上海市
3 | song | 25 | 1 | 102 | 北京市
4 | rebert | 28 | 1 | 101 | 上海市
5 | Lucy | 21 | 2 | 101 | 上海市
6 | Lily | 21 | 2 | 101 | 北京市
7 | Jim | 25 | 1 | 103 | 成都市
8 | Tom | 27 | 1 | 103 | 重庆市
9 | 张三 | 29 | 1 | 104 | 合肥市
10 | 李四 | 35 | 1 | 103 | 天津市
(10 rows)
Time: 13.241 ms
test=>
从文件FILE中读取内容,文件后缀没有要求,并将其当作输入,执行查询
\i file.sql
omm@28356c4a0750:~$ ls
bak1 bak1.sql bak1.txt data2_all_only.sql data3_all_only.sql data_all_only.sql data_only.sql select.txt
bak1.dump bak1.tar bak_table.sql data2_only.sql data4_all_only.sql data_global_only.sql data_schema_only.sql
omm@28356c4a0750:~$ cat select.txt
select * from employee;
omm@28356c4a0750:~$ pwd
/home/omm
omm@28356c4a0750:~$ gsql -d test -U jamysong -r
Password for user jamysong:
gsql ((openGauss 2.1.0 build 590b0f8e) compiled at 2021-09-30 14:29:04 commit 0 last mr )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
test=> \i /home/omm/select.txt
em_id | em_name | em_age | em_sex | em_deptno | em_addr
-------+---------+--------+--------+-----------+-----------
1 | andy | 23 | 2 | 100 | 上海市
2 | jamy | 26 | 1 | 101 | 上海市
3 | song | 25 | 1 | 102 | 北京市
4 | rebert | 28 | 1 | 101 | 上海市
5 | Lucy | 21 | 2 | 101 | 上海市
6 | Lily | 21 | 2 | 101 | 北京市
7 | Jim | 25 | 1 | 103 | 成都市
8 | Tom | 27 | 1 | 103 | 重庆市
9 | 张三 | 29 | 1 | 104 | 合肥市
10 | 李四 | 35 | 1 | 103 | 天津市
(10 rows)
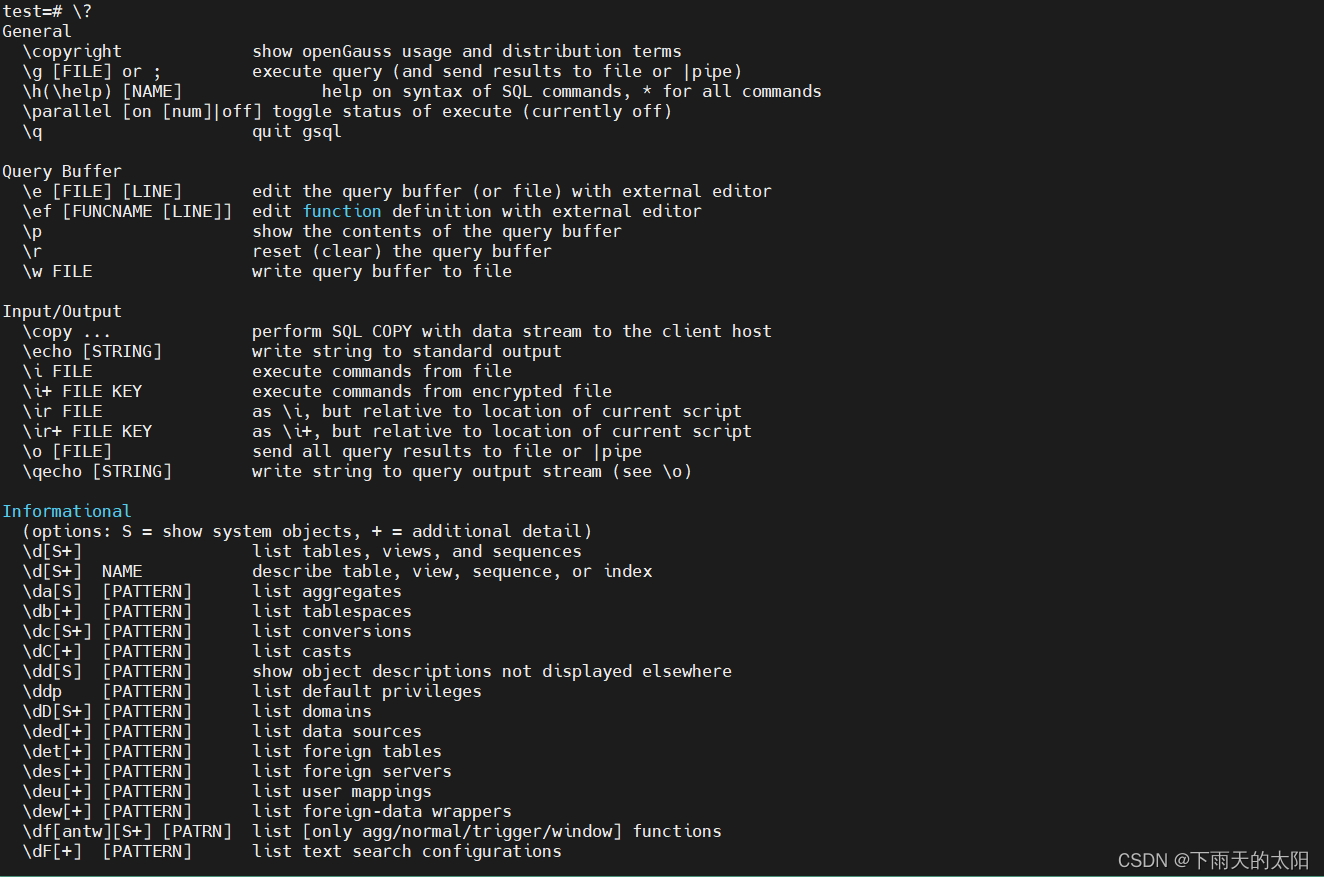
查看gsql 的帮助命令(元命令,其实就是一些查询sql的别名,这样执行非常方便!!!)
\?
查询当前连接的数据库的信息
\conninfo

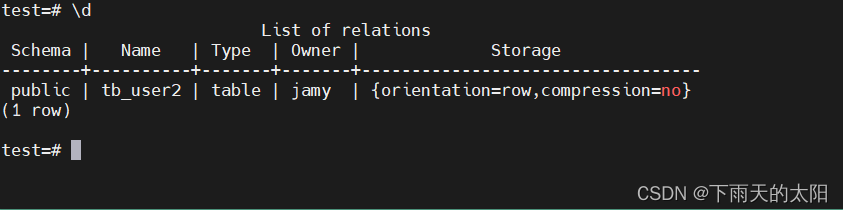
列出当前search_path中模式下所有的表、视图和序列
\d
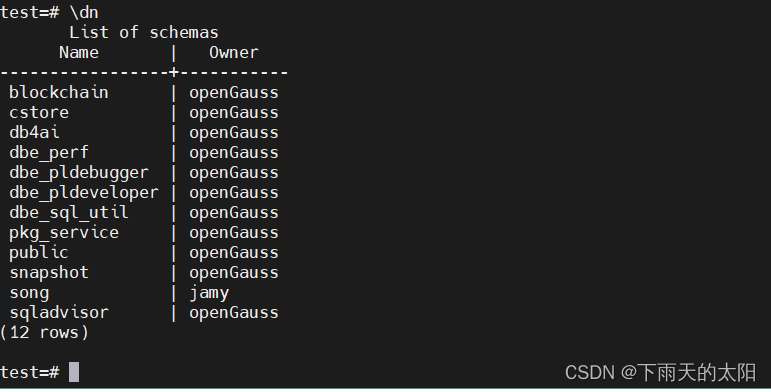
列出所有的模式(名称空间)
\dn
列出数据库中的表
\dt

列出所有的视图
\dv
test=> \dv
List of relations
Schema | Name | Type | Owner | Storage
--------+---------------+------+----------+---------
public | employee_view | view | jamysong |
(1 row)
test=>
列出权限信息
\dp
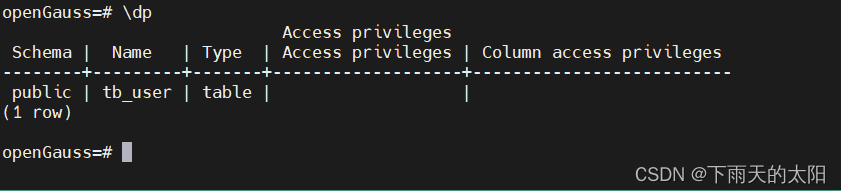
列出索引的详细信息
\d Indexname
test=> \di
List of relations
Schema | Name | Type | Owner | Table | Storage
--------+---------------+-------+----------+----------+---------
public | employee_pkey | index | jamysong | employee |
(1 row)
test=> \di employee_pkey
List of relations
Schema | Name | Type | Owner | Table | Storage
--------+---------------+-------+----------+----------+---------
public | employee_pkey | index | jamysong | employee |
(1 row)
test=>
列出函数的定义
\sf
待更新
执行操作系统命令
\! os_command
test=> \! ls
bak1 bak1.sql bak1.txt data2_all_only.sql data3_all_only.sql data_all_only.sql data_only.sql select.txt
bak1.dump bak1.tar bak_table.sql data2_only.sql data4_all_only.sql data_global_only.sql data_schema_only.sql
test=> \! cat /home/omm/select.txt
select * from employee;
test=>
查看SQL语法帮助
\h
更换连接的数据库和用户
\c 数据库名
例如:\c test

退出gsql
\q

4. 数据库常用操作语句
(1)数据库操作
创建数据库示例1:
create database mydb;
创建数据库示例2(指定数据库属主):
create database mydb owner jamysong;
openGauss=# create database mydb owner jamysong;
CREATE DATABASE
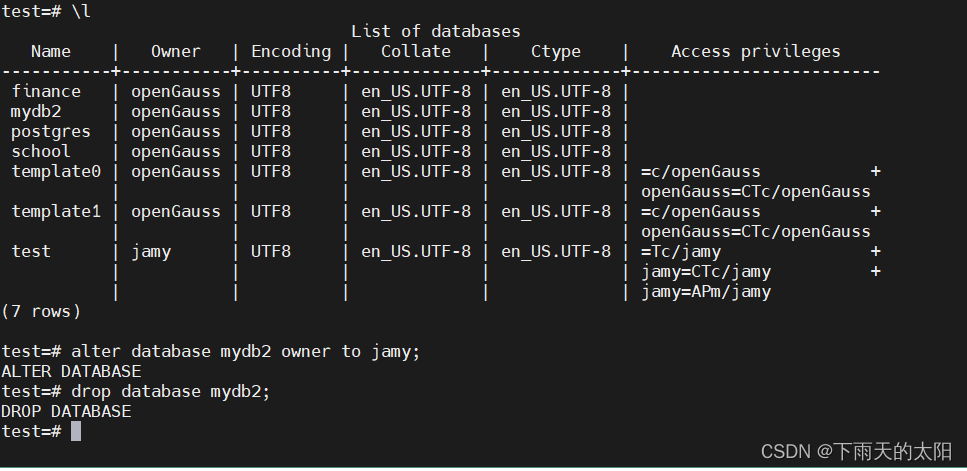
openGauss=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
dev | jamysong | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/jamysong +
| | | | | jamysong=CTc/jamysong+
| | | | | jamysong=APm/jamysong
mydb | jamysong | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
omm | omm | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
postgres | omm | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | omm | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/omm +
| | | | | omm=CTc/omm
template1 | omm | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/omm +
| | | | | omm=CTc/omm
test | jamysong | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/jamysong +
| | | | | jamysong=CTc/jamysong+
| | | | | jamysong=APm/jamysong
uat | jamysong | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/jamysong +
| | | | | jamysong=CTc/jamysong+
| | | | | jamysong=APm/jamysong
(8 rows)
创建数据库示例3:
create database mydb with owner=jack encoding='UTF-8' LC_COLLATE='zh_CN.UTF-8' LC_CTYPE='zh_CN.UTF-8'
DBCOMPATIBILITY='A' TABLESPACE=tbs1 CONNECTION LIMIT=1000;
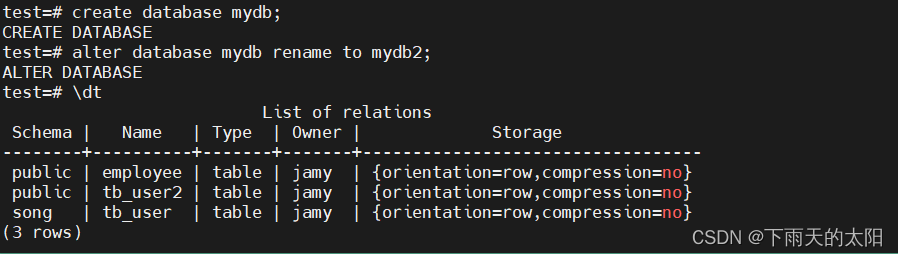
修改数据库名称
alter database mydb rename to mydb2;
修改数据库所有者
alter database mydb2 owner to user1;
修改数据库的表空间
alter database mydb2 set tablespace tbs1;
删除数据库
drop database mydb2;
查询数据库
select * from pg_database;
(2)表空间操作
创建表空间示例1:
create tablespace tbs2 relative location 'tablespace/tbs2' maxsize '100G';
创建表空间示例2:
create tablespace tbs3 owner jack location '/gauss/data/tbs3';
查询表空间
select * from pg_tablespace_location((select oid from pg_tablespace where spcname='tbs2'));
select oid,* from pg_tablespace;
修改表空间名称
alter tablespace tbs3 rename to tbs4;
修改表空间所有者
alter tablespace tbs4 owner to jack;
修改表空间大小
alter tablespace tbs4 resize maxsize unlimited;
重置表空间分页
alter tablespace tbs4 reset (random_page_cost);
删除表空间(删除表空间的前提条件是该表空间内容为空)
drop tablespace tbs4;
(3)表模式操作
这里模式,它是针对数据库而言的,如果把数据库看做成一个班级,那么模式就相当于这个班级里面的小组,大家都知道,一个班级里面会有多个小组,所以同理一个数据库里面也会有多个模式,同名的模式只能有一个,一个数据库里面的表可以分布在不同的模式里面,但是一个表只能同时存在于一个模式里面,通俗来说一个班级里面的学生,他只能在一个组里面,不可能同时横跨两个组。我们在查询一个表时,它会按照模式的搜索顺序来查询,第一个模式里面如果没找到,会接着到第二个模式里面找,依次类推。
创建模式示例1:
create schema sch1;
创建模式示例2:
create schema sch2 authorization jack;
openGauss=# create schema sch2 authorization jamysong;
CREATE SCHEMA
openGauss=# \dn
List of schemas
Name | Owner
----------------+----------
blockchain | omm
cstore | omm
db4ai | omm
dbe_perf | omm
dbe_pldebugger | omm
gaussdb | gaussdb
jamysong | jamysong
oracle | omm
pkg_service | omm
public | omm
sch2 | jamysong
snapshot | omm
sqladvisor | omm
(13 rows)
修改模式名称
alter schema sch2 rename to sch3;
修改模式所有者
alter schema sch1 owner to jack;
删除模式
drop schema sch3;
修改模式查询的范围(当前会话有效,临时有效)
set search_path to public,song;
修改数据库里面的模式的访问顺序(搜索路径)
alter database 数据库名 set search_path=模式1,模式2,模式3...;
例如:
alter database test set search_path=ming,jamysong,song;
查询表的时候会按照我们设置的顺序去找到表,如果所有模式都查询了一遍,还没找到这个表,那么说名这个表不存在或者不在当前这个数据库。
注意:
a. 不建议创建以PG_为前缀的schema名,该类的schema是为数据库系统预留的
b. 搜索路径(search_path)始终以pg_temp和pg_catalog这两个schema作为搜索路径顺序中的前两位
(4)创建表
创建表示例1:
create table emp1 as select * from emp where sal<2000;
创建表示例2:
create table emp2 as table emp;
创建表示例3:
CREATE TABLE IF NOT EXISTS tb_student -- 表不存在时才创建,使得当该表存在时该建表语句不会报错
(
id INTEGER NOT NULL,
stu_id CHAR(16) NOT NULL UNIQUE, --唯一约束
stu_name VARCHAR(20) NOT NULL, -- 非空约束
stu_age INTEGER,
stu_address VARCHAR(200) DEFAULT '', -- 缺省值为''
CONSTRAINT stu_age_cons CHECK(stu_age > 0 AND stu_age <150) --检查列约束
) TABLESPACE tbs1;
创建表示例4:
CREATE TABLE tb_warehouse_t4
(
warehose_sk INTEGER NOT NULL,
warehose_id CHAR(16) NOT NULL,
warehose_name VARCHAR(20) UNIQUE USING INDEX TABLESPACE tbs1, -- 指定该列索引存储的表空间
CONSTRAINT w_cstr_key PRIMARY KEY(warehose_sk, warehose_id) -- 复合主键约束w_cstr_key
) ;
创建表示例5:
create table DEPT(
DEPT_NO INTEGER UNIQUE,
DEPT_NAME VARCHAR(50)
);
CREATE TABLE warehouse_t5
(
W_WAREHOUSE_SK INTEGER PRIMARY KEY CHECK (W_WAREHOUSE_SK > 0), -- 检查列约束
W_WAREHOUSE_ID CHAR(16) NOT NULL,
W_WAREHOUSE_NAME VARCHAR(20) CHECK (W_WAREHOUSE_NAME IS NOT NULL), -- 检查列约束
W_DEPT_NO INTEGER REFERENCES DEPT(DEPT_NO) -- 外键约束
);
创建表示例6:
CREATE TABLE warehouse_t6
(
W_WAREHOUSE_SK INTEGER NOT NULL,
W_WAREHOUSE_ID CHAR(16) NOT NULL,
W_WAREHOUSE_NAME VARCHAR(20) ,
W_GMT_OFFSET DECIMAL(5,2),
PARTIAL CLUSTER KEY(W_WAREHOUSE_SK, W_WAREHOUSE_ID) -- 局部聚簇存储
) WITH (ORIENTATION = COLUMN, COMPRESSION=HIGH); -- 带有压缩特性的列存储表(列存储表不支持约束)
修改列属性
alter table emp1 modify sal number(10,2);
重命名列
alter table emp1 rename column ename to name;
(5)创建约束
添加主键约束
alter table emp1 add primary key (empno);
添加check约束
alter table emp1 add constraint chk_dept check (deptno is not null);
添加外键约束
alter table emp1 add constraint fk_dept foreign key (deptno) references dept(deptno);
修改列约束条件
alter table emp1 modify sal constraint chk_sal not null;
重命名约束
alter table emp1 rename constraint chk_dept to chk_deptno;
设置所属schema
alter table emp1 set schema jack;
重命名表
alter table jack.emp1 rename to emp2;
行级访问控制的目的是控制表中行级数据可见性,行访问控制策略针对特定数据库用户、特定SQL操作生效。
create user alice password 'gauss@123';
create table all_data(id int, role varchar(100), data varchar(100));
insert into all_data values(1, 'alice', 'alice data');
insert into all_data values(2, 'bob', 'bob data' );
insert into all_data values(3, 'peter', 'peter data');
grant select on all_data to alice;
alter table all_data enable row level security;
create row level security policy all_data_rls on all_data using(role = current_user);
\c - alice
select * from all_data; -- 仅能看到指定用户的数据,系统管理员不受行访问控制影响
explain select * from public.all_data;
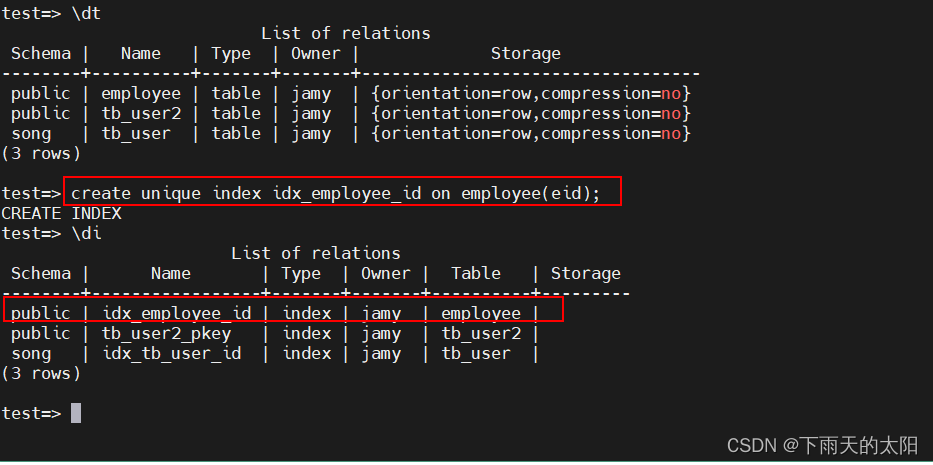
(6)创建索引
创建唯一索引
create unique index t1_fn_idx on t1(relfilenode);
创建复合索引
create index t1_owner_tbs_idx on t1(relowner,reltablespace);
创建部分索引
create index t1_lttbs_idx on t1(reltablespace) where reltablespace<20;
创建函数索引
create index t1_upname_idx on t1(upper(relname));
创建分区表的本地索引
create index pt1_id_idx on pt1(id) local;
创建分区表的全局索引
create index pt1_score_idx on pt1(score) global tablespace tbs1;
修改索引
alter index t1_fn_idx rename to t1_fn_idx2;
alter index t1_fn_idx2 set tablespace tbs2;
alter index t1_lttbs_idx unusable;
alter index t1_lttbs_idx rebuild;
修改分区索引
alter index pt1_id_idx rebuild partition p1_id_idx;
alter index pt1_id_idx modify partition p1_id_idx unusable;
alter index pt1_id_idx rename partition p1_id_idx to p1_id_idx2;
alter index pt1_id_idx move partition p1_id_idx2 tablespace tbs1;
删除索引
drop index t1_lttbs_idx;
(7)创建序列
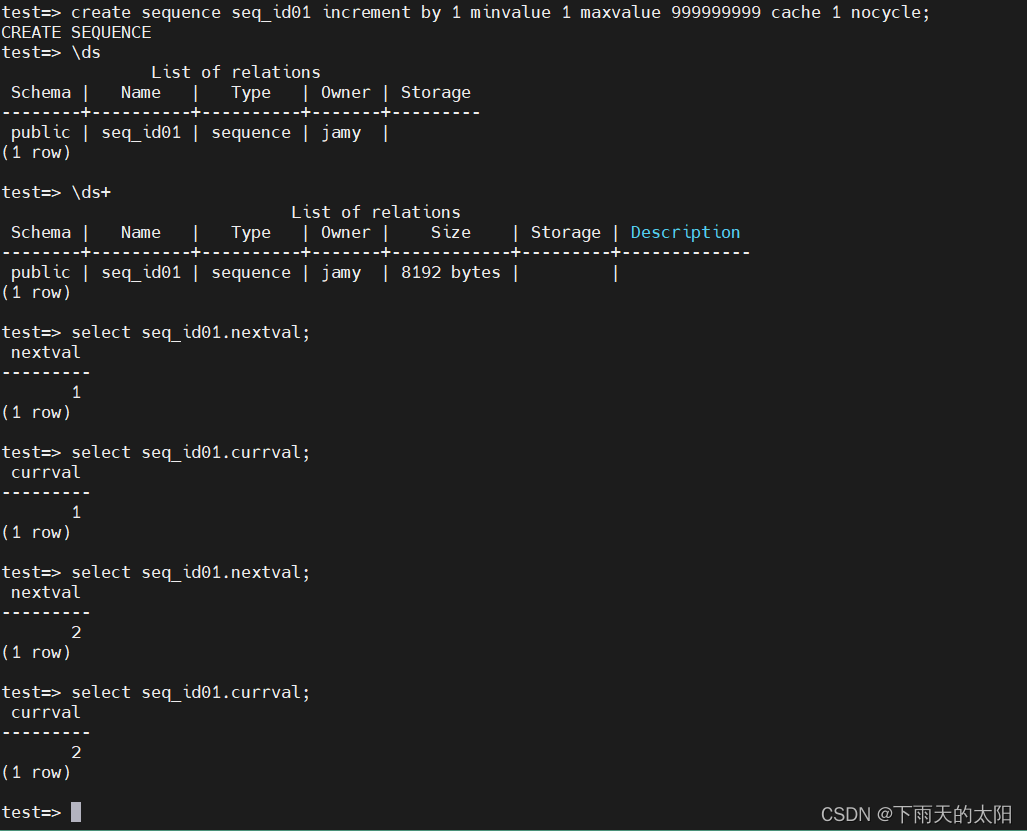
创建序列
create sequence seq01;
create sequence seq02 increment by 1 minvalue 1 maxvalue 99999 cache 1 nocycle;
查看序列
\d t2_id_seq
select * from t2_id_seq;
使用序列
select nextval('seq01'); --递增序列并返回新值
select seq01.nextval;
select currval('seq01'); --最近一次nextval返回的值
select seq01.currval;
select lastval(); --最近一次nextval返回的值
select setval('seq01',1); --设置序列的当前数值
修改序列属性
alter sequence seq01 maxvalue 99999;
alter sequence seq01 owner to jack;
删除序列
drop sequence seq01;
drop sequence seq02 cascade;
(8)查询表数据
整体查询语句跟mysql差不多
#全表查询(一般业务中肯定需要哪些字段就查询哪些字段,不会使用*)
select * from employee;
test=> select * from employee;
em_id | em_name | em_age | em_sex | em_deptno | em_addr
-------+----------+--------+--------+-----------+-----------
1 | andy | 23 | 2 | 100 | 上海市
2 | jamy | 26 | 1 | 101 | 上海市
3 | song | 25 | 1 | 102 | 北京市
4 | rebert | 28 | 1 | 101 | 上海市
5 | Lucy | 21 | 2 | 101 | 上海市
6 | Lily | 21 | 2 | 101 | 北京市
7 | Jim | 25 | 1 | 103 | 成都市
8 | Tom | 27 | 1 | 103 | 重庆市
9 | 张三 | 29 | 1 | 104 | 合肥市
10 | 李四 | 35 | 1 | 103 | 天津市
11 | zhangsan | 24 | 1 | 101 | 北京市
12 | lisi | 25 | 1 | 109 | 北京市
(12 rows)
#查询最前面的几条记录
select * from employee limit 4;
test=> select * from employee limit 4;
em_id | em_name | em_age | em_sex | em_deptno | em_addr
-------+---------+--------+--------+-----------+-----------
1 | andy | 23 | 2 | 100 | 上海市
2 | jamy | 26 | 1 | 101 | 上海市
3 | song | 25 | 1 | 102 | 北京市
4 | rebert | 28 | 1 | 101 | 上海市
(4 rows)
#从第四条记录查询,连续查询四条记录,(索引从0开始,一般用于分页查询)
select * from employee limit 3,4;
test=> select * from employee limit 3,4;
em_id | em_name | em_age | em_sex | em_deptno | em_addr
-------+---------+--------+--------+-----------+-----------
4 | rebert | 28 | 1 | 101 | 上海市
5 | Lucy | 21 | 2 | 101 | 上海市
6 | Lily | 21 | 2 | 101 | 北京市
7 | Jim | 25 | 1 | 103 | 成都市
(4 rows)
#分组查询,group by后面的字段必须要出现在select子句中(一般用来分组统计)
select em_deptno ,count(*) from employee group by em_deptno;
test=> select em_deptno ,count(*) from employee group by em_deptno;
em_deptno | count
-----------+-------
103 | 3
109 | 1
101 | 5
100 | 1
102 | 1
104 | 1
(6 rows)
#排序查询,默认升序,加desc为倒叙查询
select * from employee order by em_age desc;
test=> select * from employee order by em_age desc;
em_id | em_name | em_age | em_sex | em_deptno | em_addr
-------+----------+--------+--------+-----------+-----------
10 | 李四 | 35 | 1 | 103 | 天津市
9 | 张三 | 29 | 1 | 104 | 合肥市
4 | rebert | 28 | 1 | 101 | 上海市
8 | Tom | 27 | 1 | 103 | 重庆市
2 | jamy | 26 | 1 | 101 | 上海市
12 | lisi | 25 | 1 | 109 | 北京市
3 | song | 25 | 1 | 102 | 北京市
7 | Jim | 25 | 1 | 103 | 成都市
11 | zhangsan | 24 | 1 | 101 | 北京市
1 | andy | 23 | 2 | 100 | 上海市
6 | Lily | 21 | 2 | 101 | 北京市
5 | Lucy | 21 | 2 | 101 | 上海市
(12 rows)
#自连接查询
select * from employee e1 join employee e2 on e1.em_id = e2.em_id;
test=> select * from employee e1 join employee e2 on e1.em_id = e2.em_id;
em_id | em_name | em_age | em_sex | em_deptno | em_addr | em_id | em_name | em_age | em_sex | em_deptno | em_addr
-------+----------+--------+--------+-----------+-----------+-------+----------+--------+--------+-----------+-----------
1 | andy | 23 | 2 | 100 | 上海市 | 1 | andy | 23 | 2 | 100 | 上海市
2 | jamy | 26 | 1 | 101 | 上海市 | 2 | jamy | 26 | 1 | 101 | 上海市
3 | song | 25 | 1 | 102 | 北京市 | 3 | song | 25 | 1 | 102 | 北京市
4 | rebert | 28 | 1 | 101 | 上海市 | 4 | rebert | 28 | 1 | 101 | 上海市
5 | Lucy | 21 | 2 | 101 | 上海市 | 5 | Lucy | 21 | 2 | 101 | 上海市
6 | Lily | 21 | 2 | 101 | 北京市 | 6 | Lily | 21 | 2 | 101 | 北京市
7 | Jim | 25 | 1 | 103 | 成都市 | 7 | Jim | 25 | 1 | 103 | 成都市
8 | Tom | 27 | 1 | 103 | 重庆市 | 8 | Tom | 27 | 1 | 103 | 重庆市
9 | 张三 | 29 | 1 | 104 | 合肥市 | 9 | 张三 | 29 | 1 | 104 | 合肥市
10 | 李四 | 35 | 1 | 103 | 天津市 | 10 | 李四 | 35 | 1 | 103 | 天津市
11 | zhangsan | 24 | 1 | 101 | 北京市 | 11 | zhangsan | 24 | 1 | 101 | 北京市
12 | lisi | 25 | 1 | 109 | 北京市 | 12 | lisi | 25 | 1 | 109 | 北京市
(12 rows)
#内连接查询(查询出两张表的交集部分)
select * from employee e inner join dept d on e.em_deptno = d.deptno;
test=> select * from employee e inner join dept d on e.em_deptno = d.deptno;
em_id | em_name | em_age | em_sex | em_deptno | em_addr | deptno | deptname
-------+----------+--------+--------+-----------+-----------+--------+-----------
11 | zhangsan | 24 | 1 | 101 | 北京市 | 101 | 市场部
6 | Lily | 21 | 2 | 101 | 北京市 | 101 | 市场部
5 | Lucy | 21 | 2 | 101 | 上海市 | 101 | 市场部
4 | rebert | 28 | 1 | 101 | 上海市 | 101 | 市场部
2 | jamy | 26 | 1 | 101 | 上海市 | 101 | 市场部
1 | andy | 23 | 2 | 100 | 上海市 | 100 | 行政部
3 | song | 25 | 1 | 102 | 北京市 | 102 | 后勤部
10 | 李四 | 35 | 1 | 103 | 天津市 | 103 | 研发部
8 | Tom | 27 | 1 | 103 | 重庆市 | 103 | 研发部
7 | Jim | 25 | 1 | 103 | 成都市 | 103 | 研发部
9 | 张三 | 29 | 1 | 104 | 合肥市 | 104 | 工程部
(11 rows)
#左连接查询(以左边表为主表)
select * from employee e left join dept d on e.em_deptno = d.deptno;
test=> select * from employee e left join dept d on e.em_deptno = d.deptno;
em_id | em_name | em_age | em_sex | em_deptno | em_addr | deptno | deptname
-------+----------+--------+--------+-----------+-----------+--------+-----------
11 | zhangsan | 24 | 1 | 101 | 北京市 | 101 | 市场部
6 | Lily | 21 | 2 | 101 | 北京市 | 101 | 市场部
5 | Lucy | 21 | 2 | 101 | 上海市 | 101 | 市场部
4 | rebert | 28 | 1 | 101 | 上海市 | 101 | 市场部
2 | jamy | 26 | 1 | 101 | 上海市 | 101 | 市场部
1 | andy | 23 | 2 | 100 | 上海市 | 100 | 行政部
3 | song | 25 | 1 | 102 | 北京市 | 102 | 后勤部
10 | 李四 | 35 | 1 | 103 | 天津市 | 103 | 研发部
8 | Tom | 27 | 1 | 103 | 重庆市 | 103 | 研发部
7 | Jim | 25 | 1 | 103 | 成都市 | 103 | 研发部
9 | 张三 | 29 | 1 | 104 | 合肥市 | 104 | 工程部
12 | lisi | 25 | 1 | 109 | 北京市 | |
(12 rows)
#右连接查询(以右边的表为主表)
select * from employee e right join dept d on e.em_deptno = d.deptno;
test=> select * from employee e right join dept d on e.em_deptno = d.deptno;
em_id | em_name | em_age | em_sex | em_deptno | em_addr | deptno | deptname
-------+----------+--------+--------+-----------+-----------+--------+-----------
11 | zhangsan | 24 | 1 | 101 | 北京市 | 101 | 市场部
6 | Lily | 21 | 2 | 101 | 北京市 | 101 | 市场部
5 | Lucy | 21 | 2 | 101 | 上海市 | 101 | 市场部
4 | rebert | 28 | 1 | 101 | 上海市 | 101 | 市场部
2 | jamy | 26 | 1 | 101 | 上海市 | 101 | 市场部
1 | andy | 23 | 2 | 100 | 上海市 | 100 | 行政部
3 | song | 25 | 1 | 102 | 北京市 | 102 | 后勤部
10 | 李四 | 35 | 1 | 103 | 天津市 | 103 | 研发部
8 | Tom | 27 | 1 | 103 | 重庆市 | 103 | 研发部
7 | Jim | 25 | 1 | 103 | 成都市 | 103 | 研发部
9 | 张三 | 29 | 1 | 104 | 合肥市 | 104 | 工程部
| | | | | | 105 | 总裁办
(12 rows)
(9)插入表数据
insert into employee values(seq1.nextval, 'jamysong',30,1,111,'上海市');
test=> insert into employee values(seq1.nextval, 'jamysong',30,1,111,'上海市');
INSERT 0 1
test=>
(10)修改表数据
update employee set em_addr = 'shanghai' where em_id = 13;
test=> update employee set em_addr = 'shanghai' where em_id = 13;
UPDATE 1
test=>
(11)删除表数据
test=> delete from employee where em_id = 13;
DELETE 1
test=>
5. 数据库权限管理
(1)用户
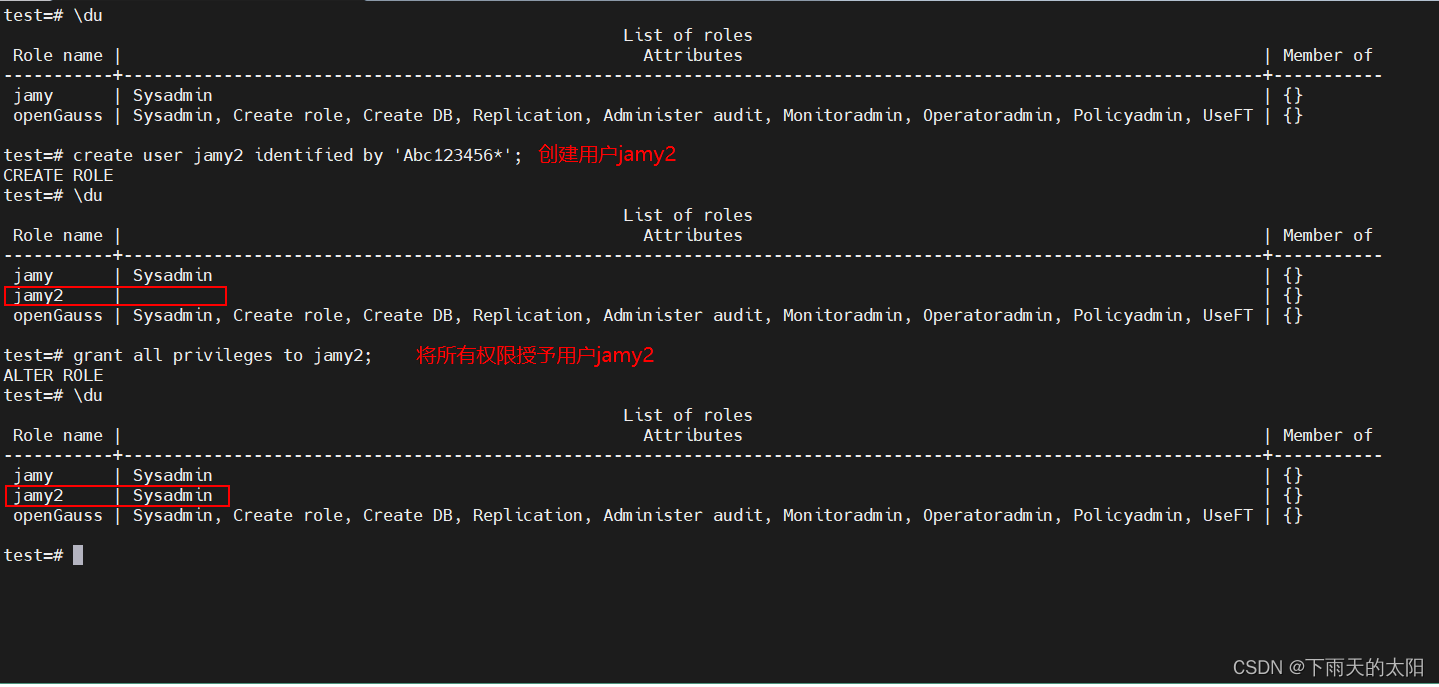
创建用户示例1(普通用户):
create user jamy2 identified by 'Abc123456*';
授予用户所有权限(将sysadmin权限赋予指定的角色或者用户)
grant all privileges to jamy2;
将角色或用户的权限授权给其他角色或用户
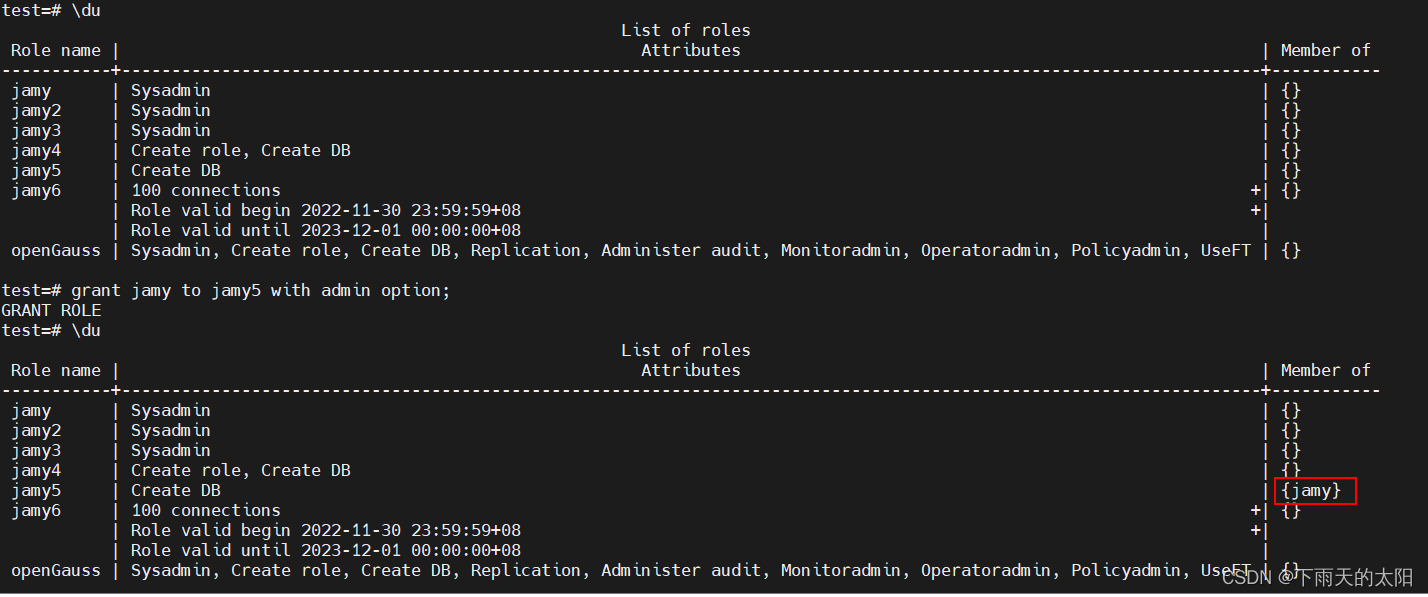
grant jamy to jamy5 with admin option;
创建用户示例2(直接创建带有管理员权限的用户):
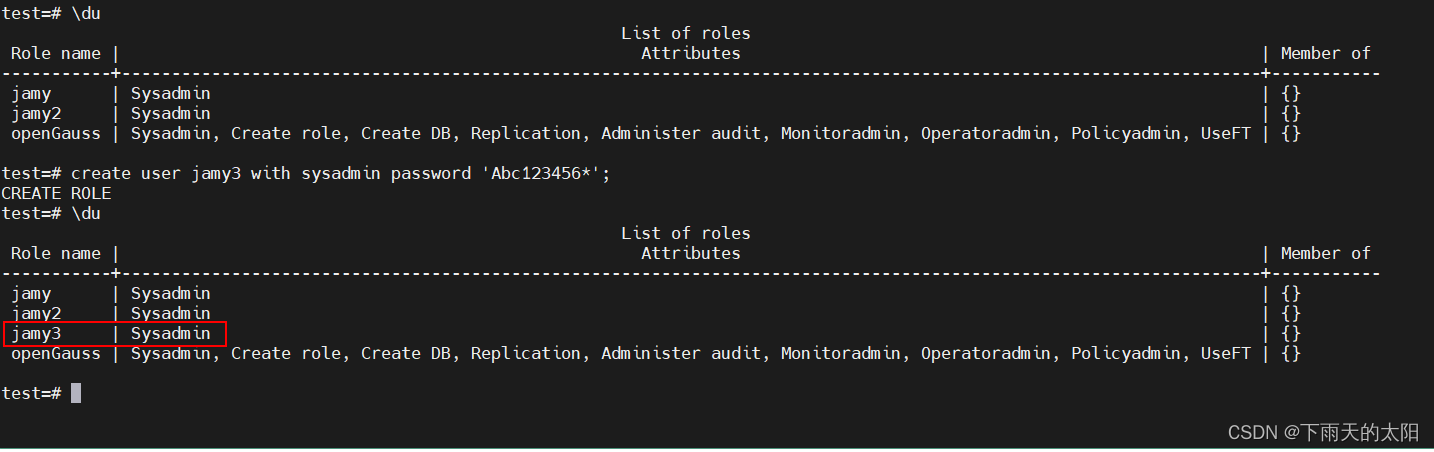
create user jamy3 with sysadmin password 'Abc123456*';
创建用户示例3(普通用户)
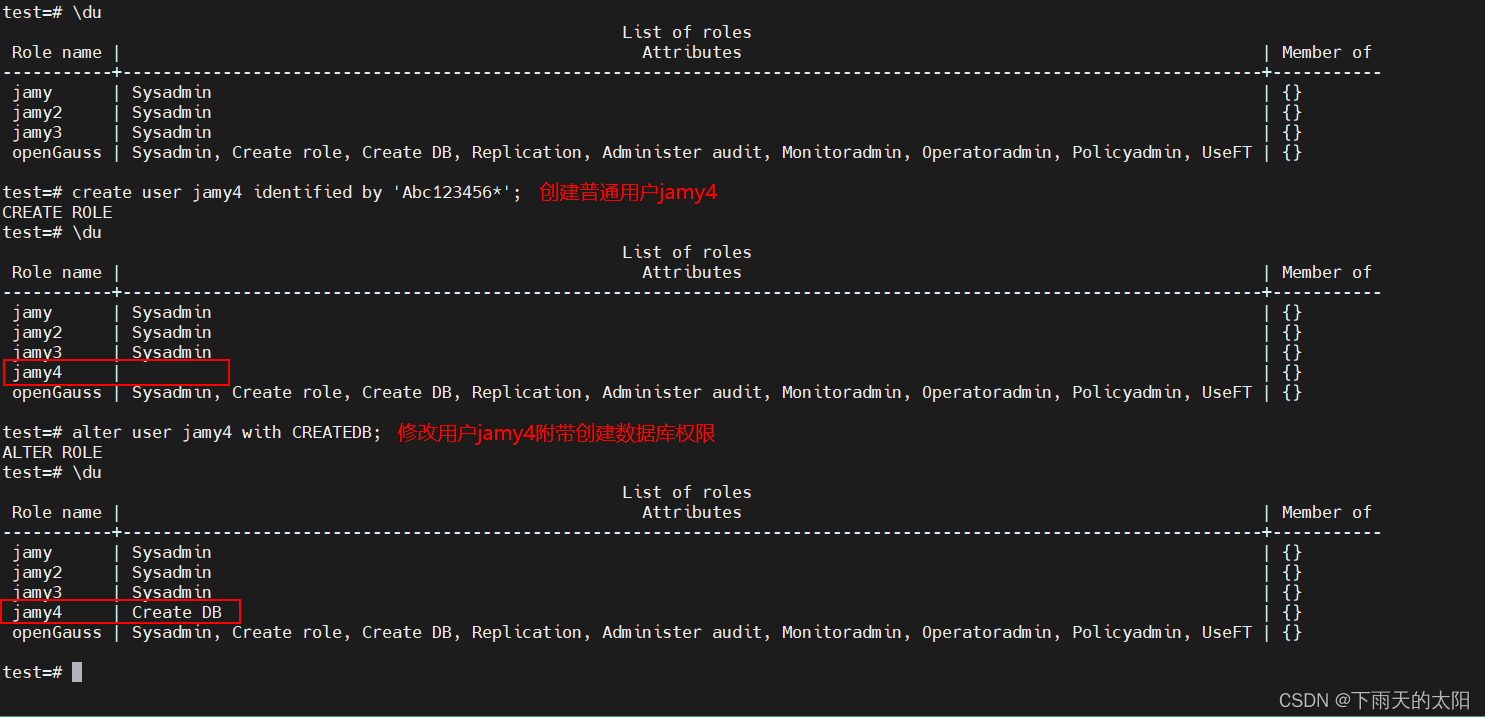
create user jamy4 identified by 'Abc123456*';
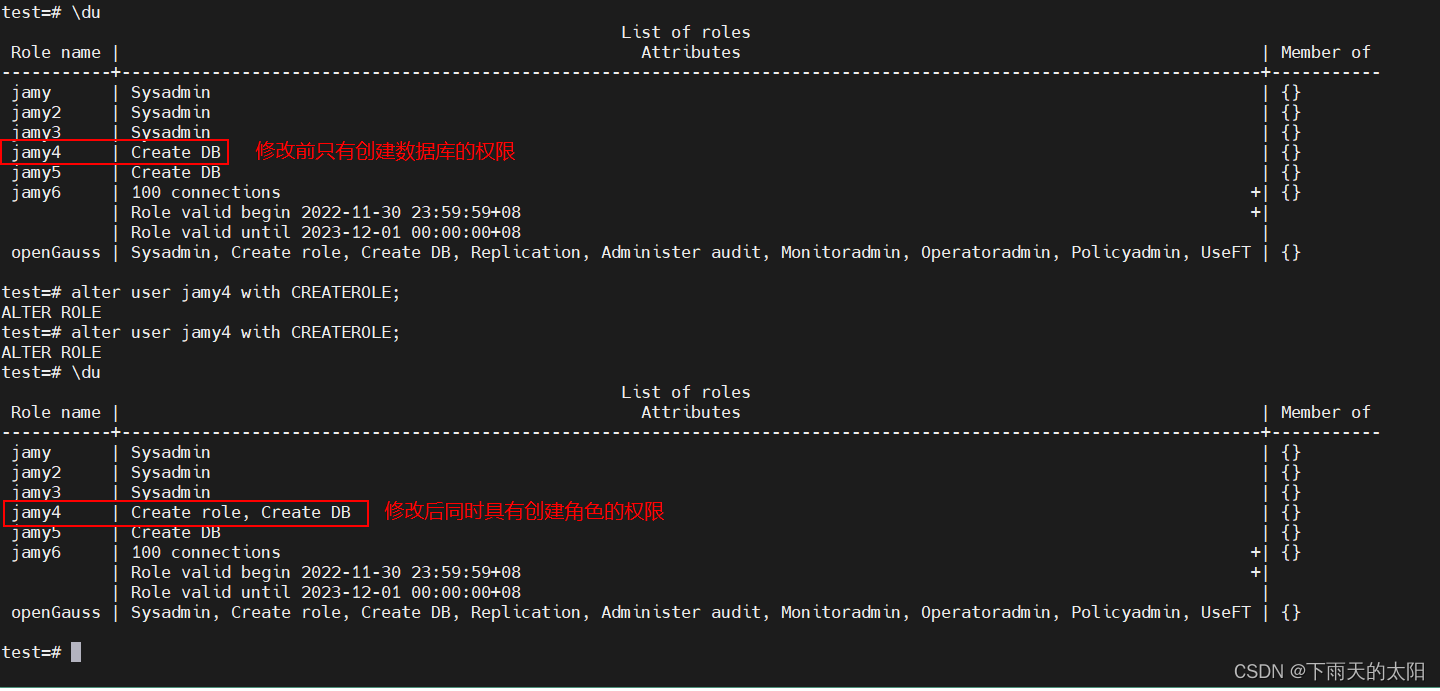
修改用户权限
alter user jamy4 with CREATEDB;
创建用户示例4(直接创建带有创建数据库权限的用户)
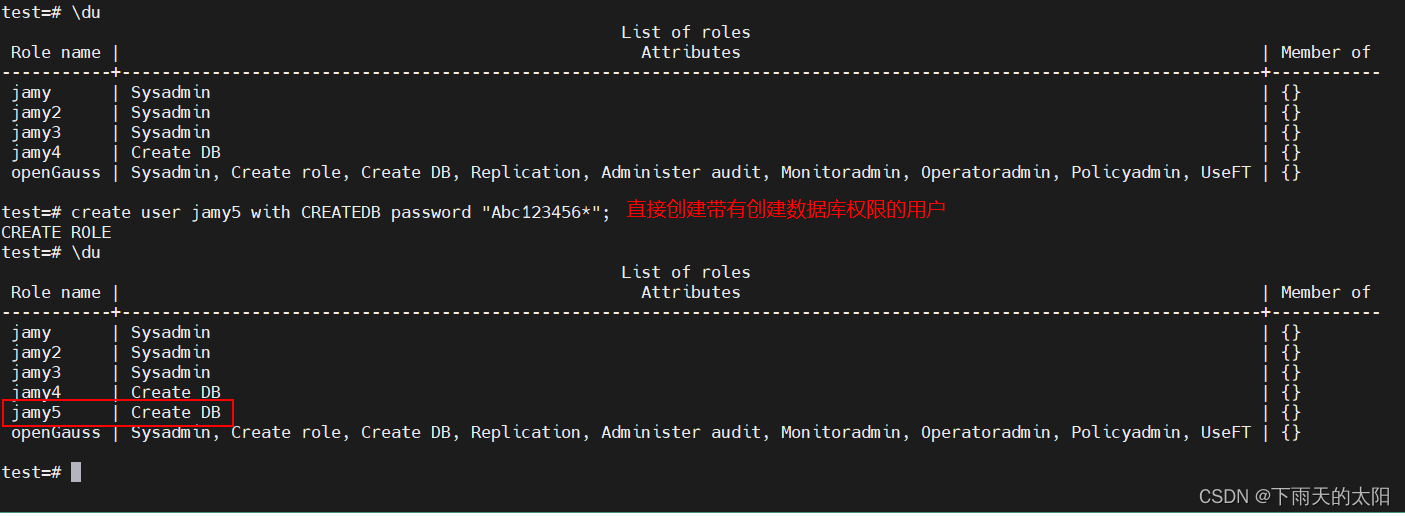
create role jamy5 with CREATEDB password "Abc123456*";
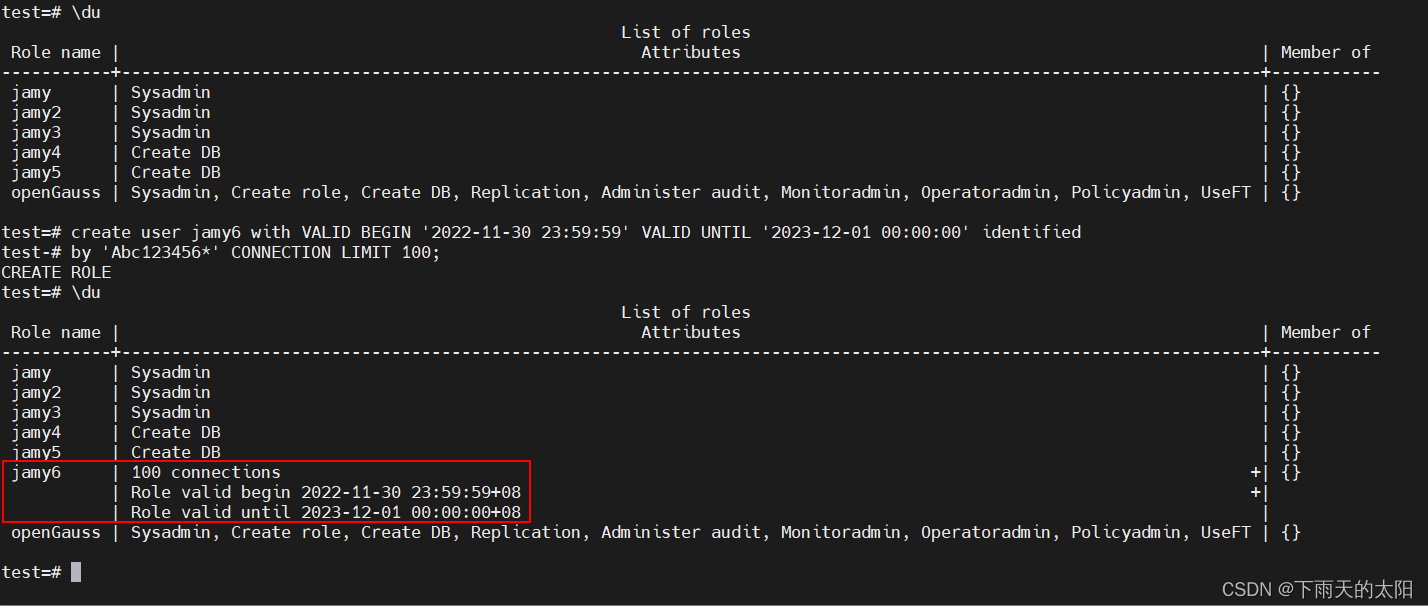
创建用户示例5(创建用户带有限制条件:有效期、连接数):
create user jamy6 with VALID BEGIN '2022-11-30 23:59:59' VALID UNTIL '2023-12-01 00:00:00' identified
by 'Abc123456*' CONNECTION LIMIT 100;
修改用户权限,拥有创建角色的权限
alter user jamy4 with CREATEROLE;
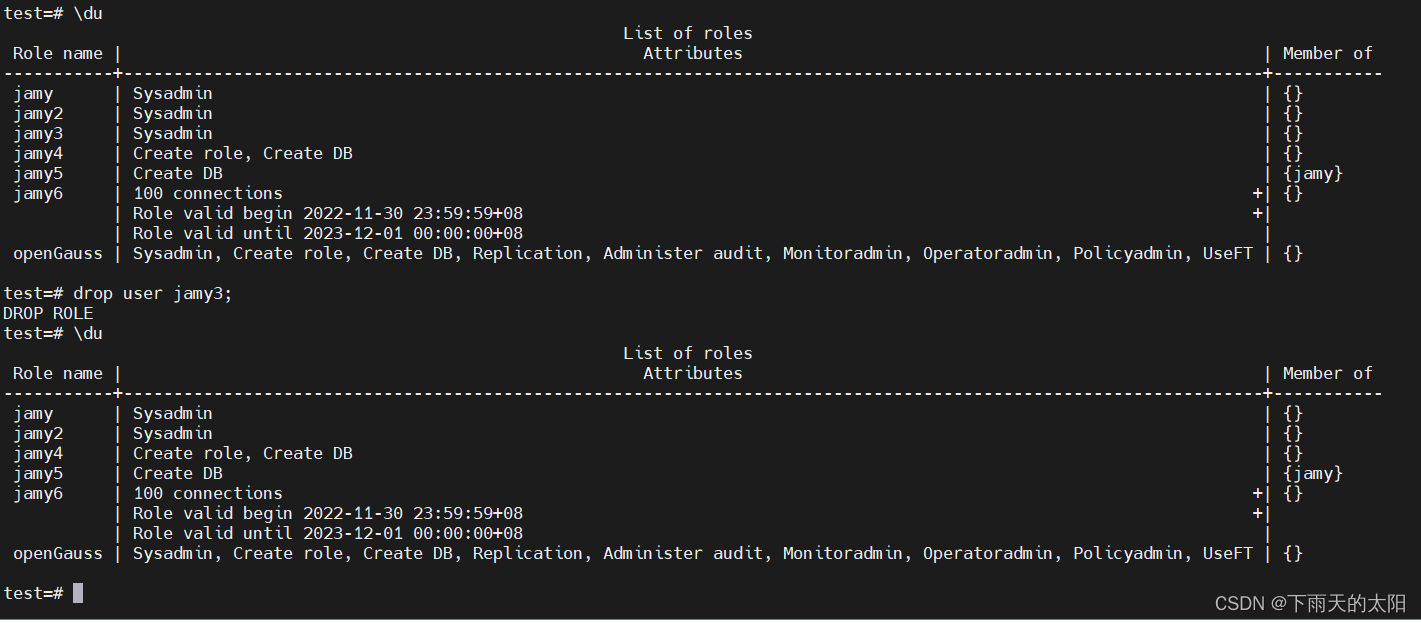
删除用户
drop user jamy4;
(2)授权
数据库授权
grant all privileges on database mydb to jamy3;
表空间授权
grant all privileges on tablespace tbs1 to jamy3;
schema授权
grant usage on schema sch1 to jamy3;
函数授权
grant execute on function func_add_sql(int,int) to jamy3;
grant execute on function proc_emp(var_empno int, OUT v_name varchar, OUT v_job varchar) to jamy3;
表授权
grant select (empno,ename,sal),update (comm) on emp TO jamy3;
grant select,insert,update,delete on all tables in schema sch1 to jamy3;
grant all privileges on emp to jamy3 with grant option;
授权jack角色给jamy1用户,且jamy1用户可授权其他用户
grant jack to jamy1 with admin option;
将管理员权限授予给用户jamy
grant all privileges to jamy;
权限回收
revoke jack from jamy1;
6. 图形化客户端
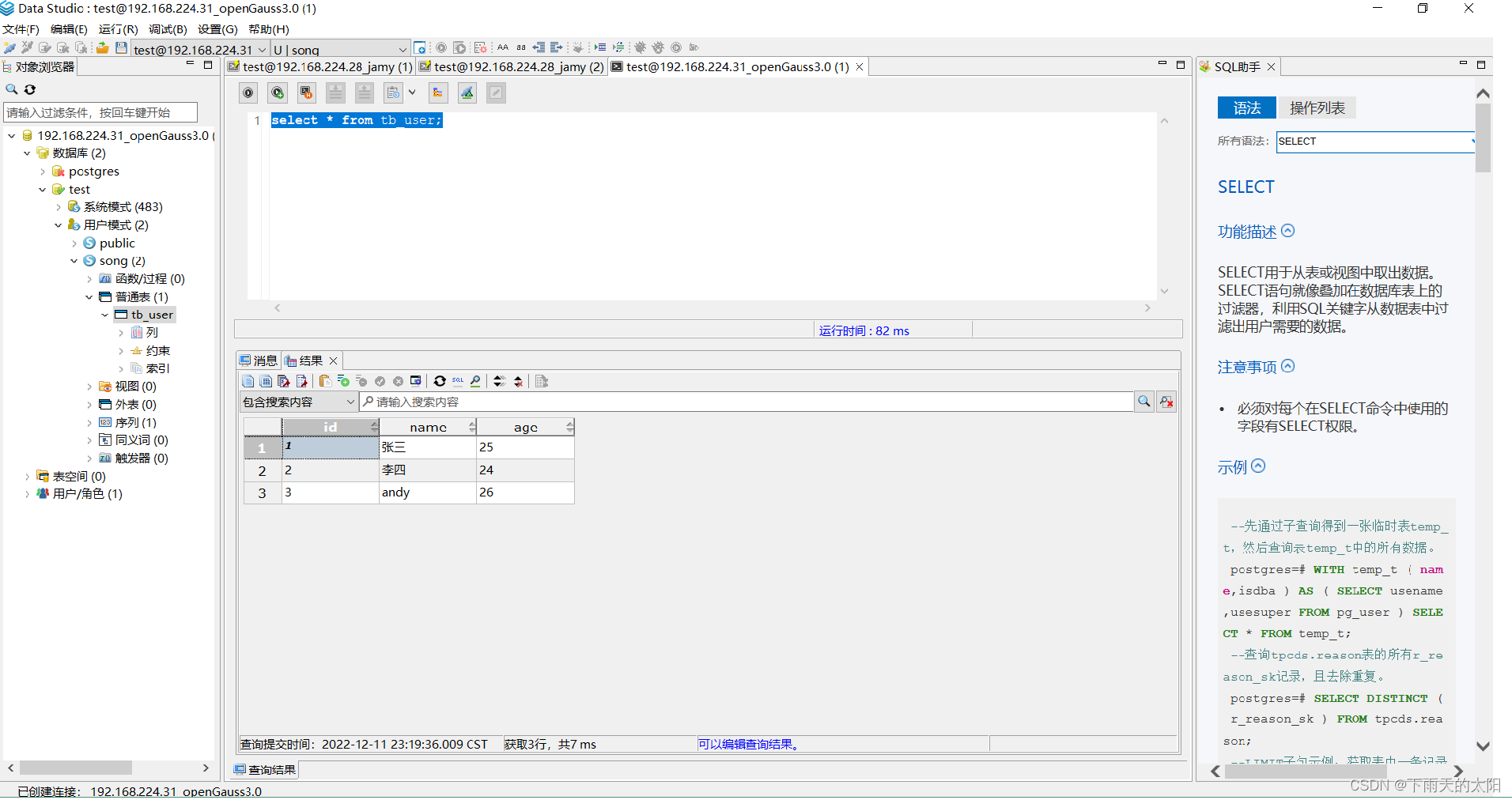
(1)Data Studio客户端
Data Studio是华为openGauss数据库连接的官方图形化客户端,登录只需要做如下两步步操作即可:
(1)编辑postgresql.conf文件
将listen_addresses这一行修改成:
listen_addresses = '*'
(2)编辑pg_hba.conf文件
在# IPv4 local connections这一行下面添加如下内容
host all all 0.0.0.0/0 sha256
注意:完成以上两步需要重启数据库
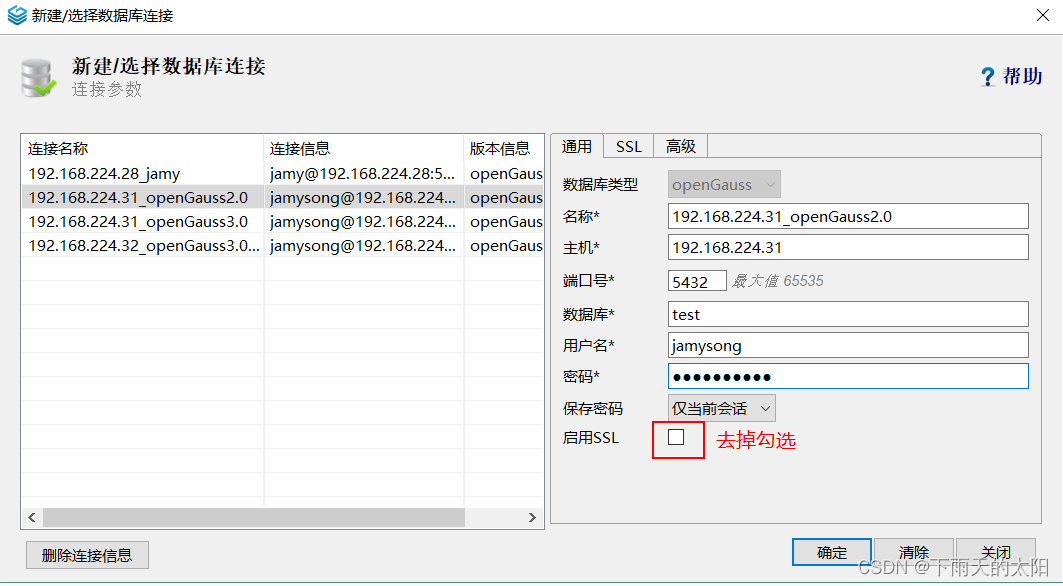
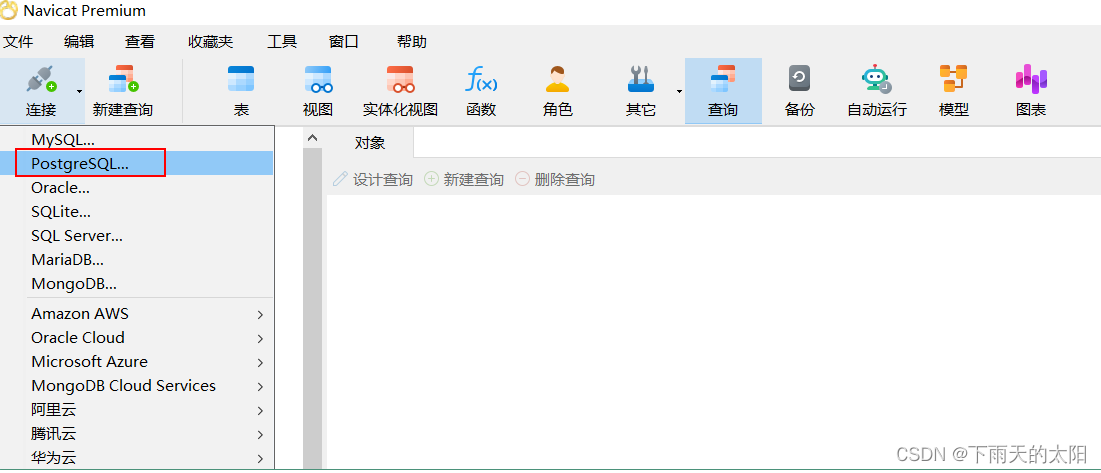
(2)navicat客户端
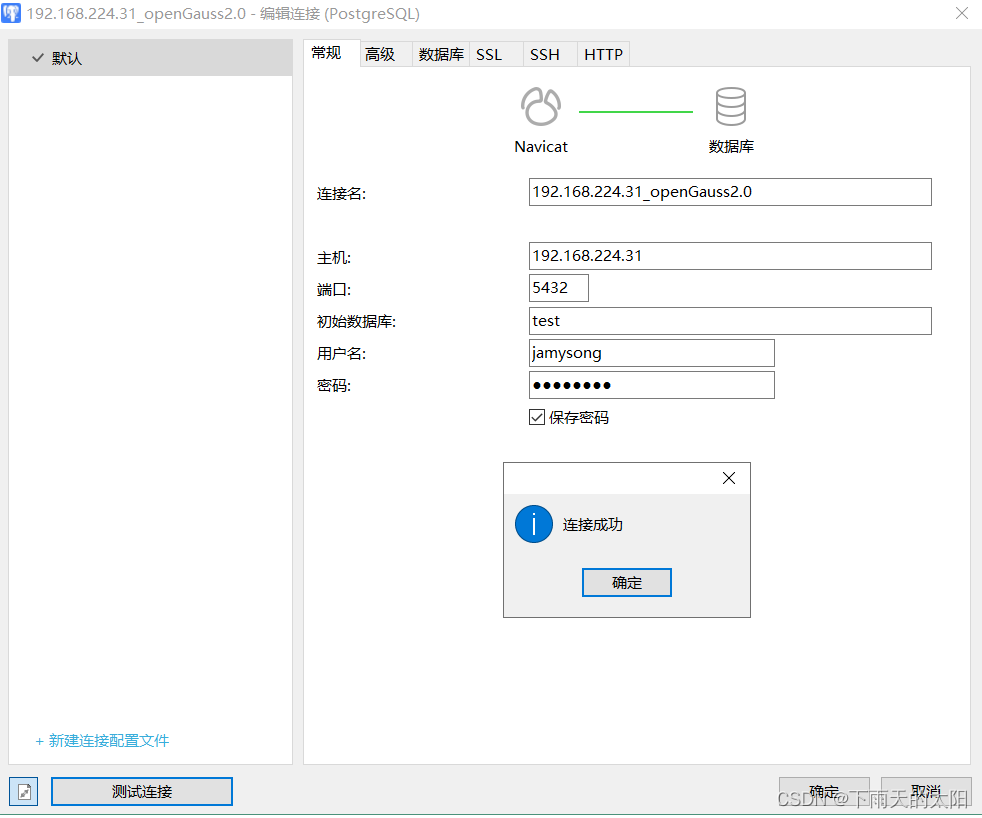
要想使用navicat登录openGauss数据库,需要做如下三步操作
(1)编辑postgresql.conf文件
将listen_addresses这一行修改成:
listen_addresses = '*'
将password_encryption_type这一行修改成:
password_encryption_type = 1
(2)编辑pg_hba.conf文件
在# IPv4 local connections这一行下面添加如下内容
host all all 0.0.0.0/0 md5
注意:以上两步步完成后重启数据库
gs_om -t restart

(3)修改用户登录密码
因为加密方式改变了,所以需要重新设置密码(采用了新的加密方式)
修改密码,新密码不能和原密码一样
alter user jamysong identified by 'Sjm214325*';

以上三步完成后就可以使用navicat登录openGauss数据库了
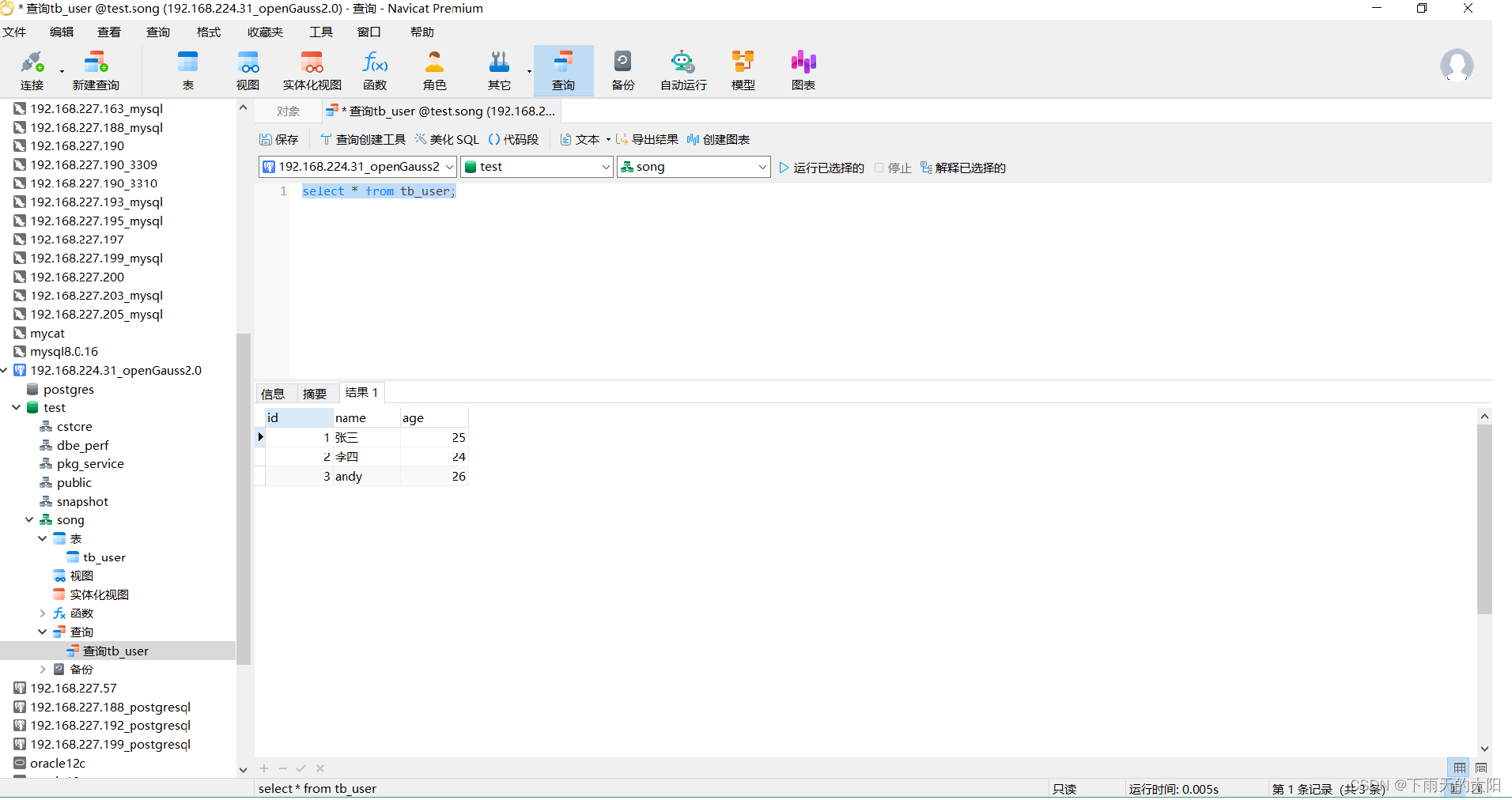
(3) Dbeaver客户端
需要做如下三步配置操作:
(1)编辑postgresql.conf文件
将listen_addresses这一行修改成:
listen_addresses = '*'
(2)编辑pg_hba.conf文件
在# IPv4 local connections这一行下面添加如下内容
host all all 0.0.0.0/0 sha256
注意:完成以上两步需要重启数据库
(3)启动 Dbeaver.exe,并选择菜单->数据库->驱动管理器,在弹出对话框中,选择新建
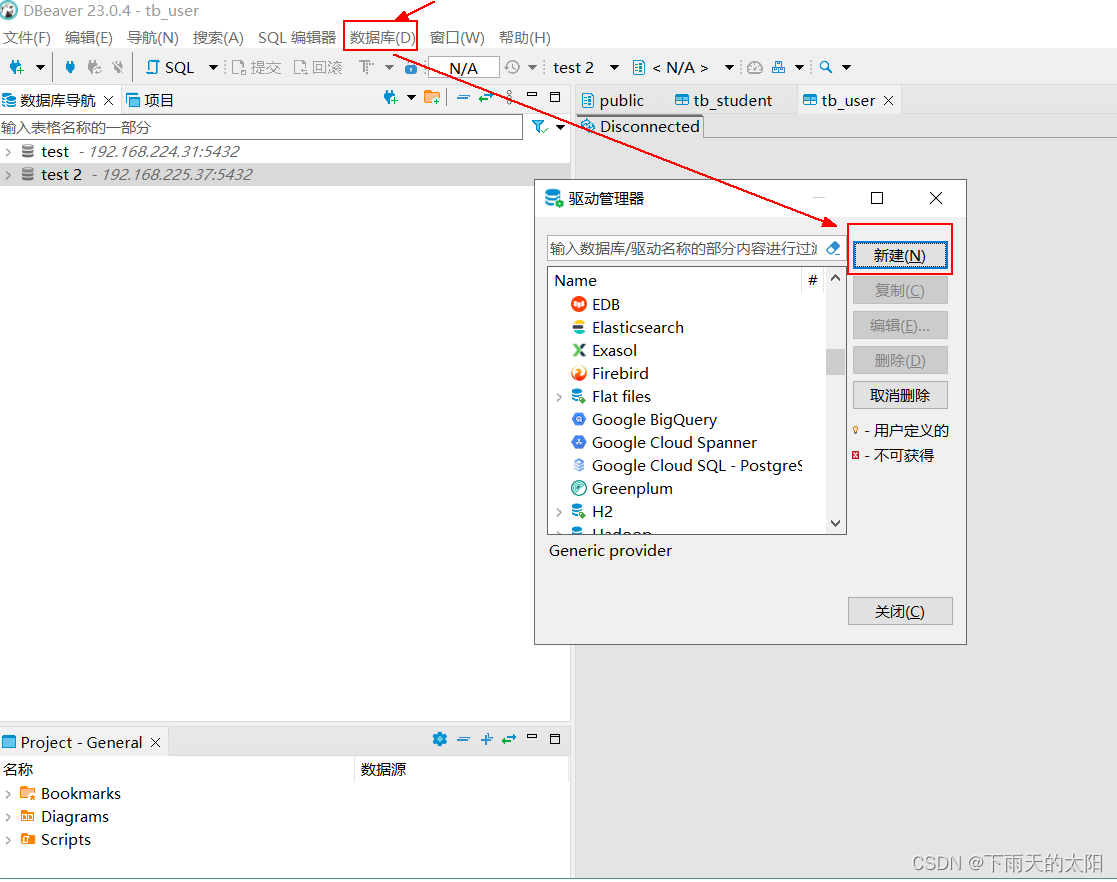
添加jdbc驱动文件,从openGauss官网下载对应系统和版本的驱动即可
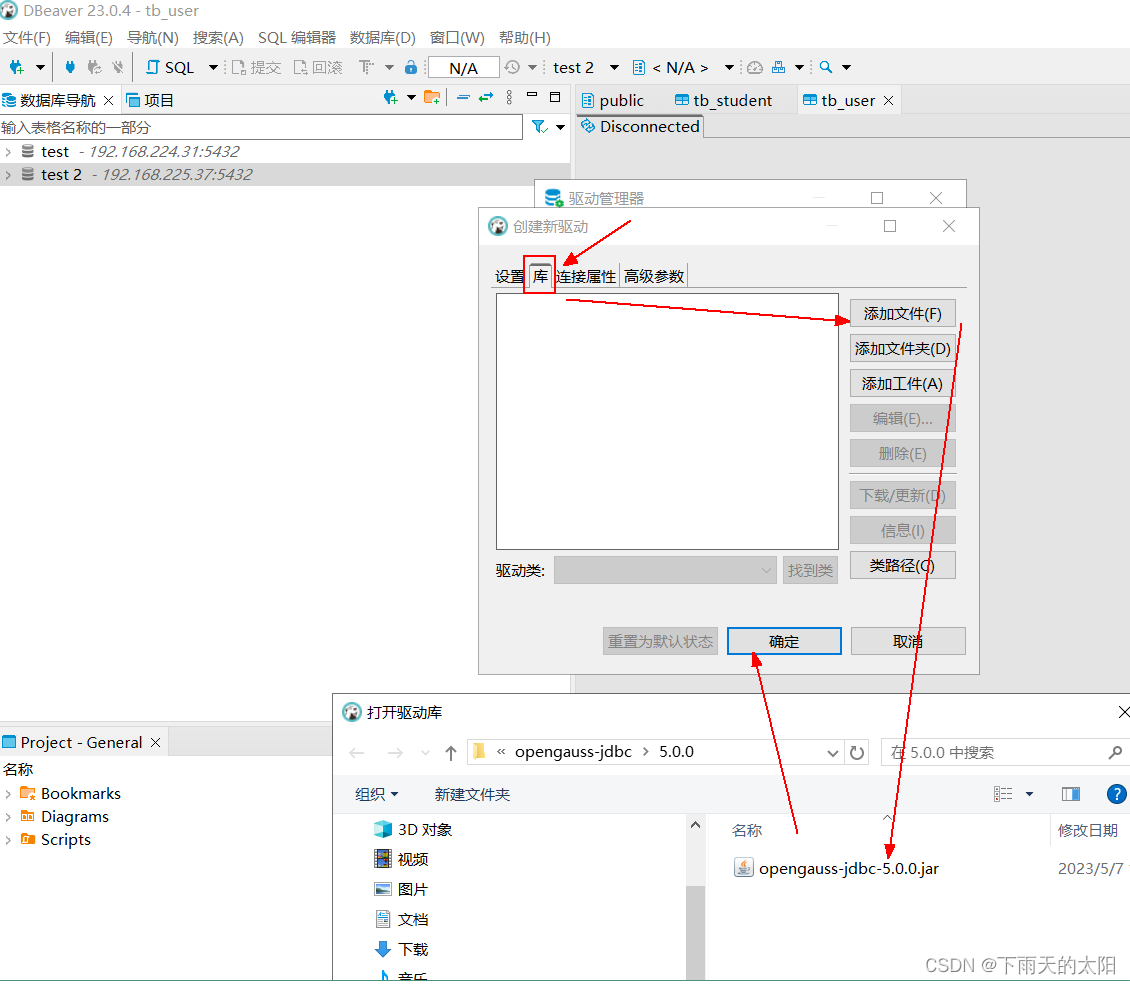
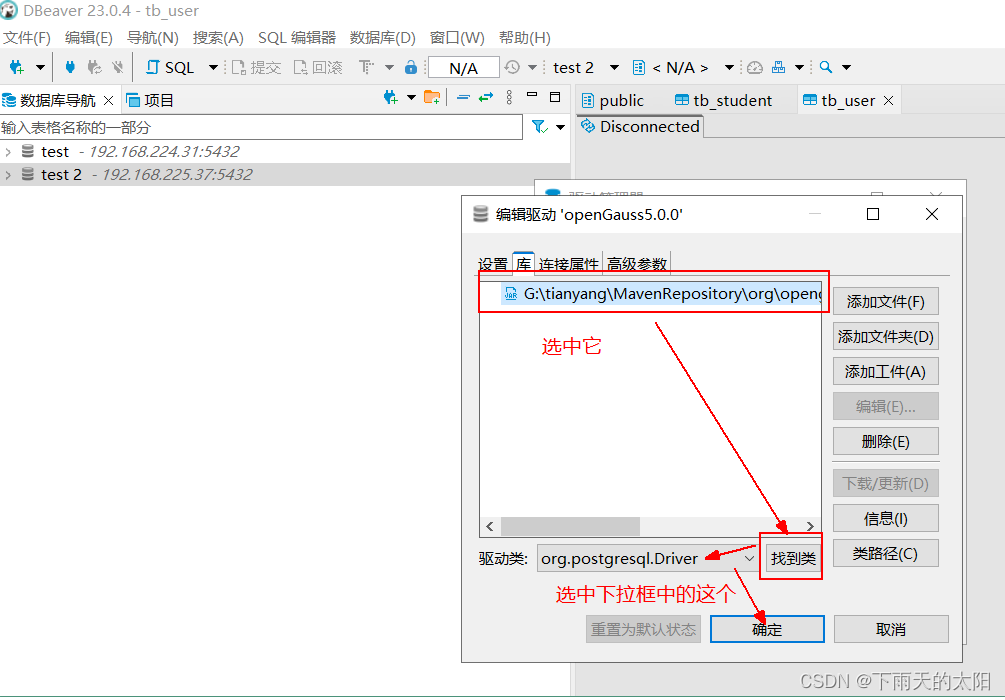

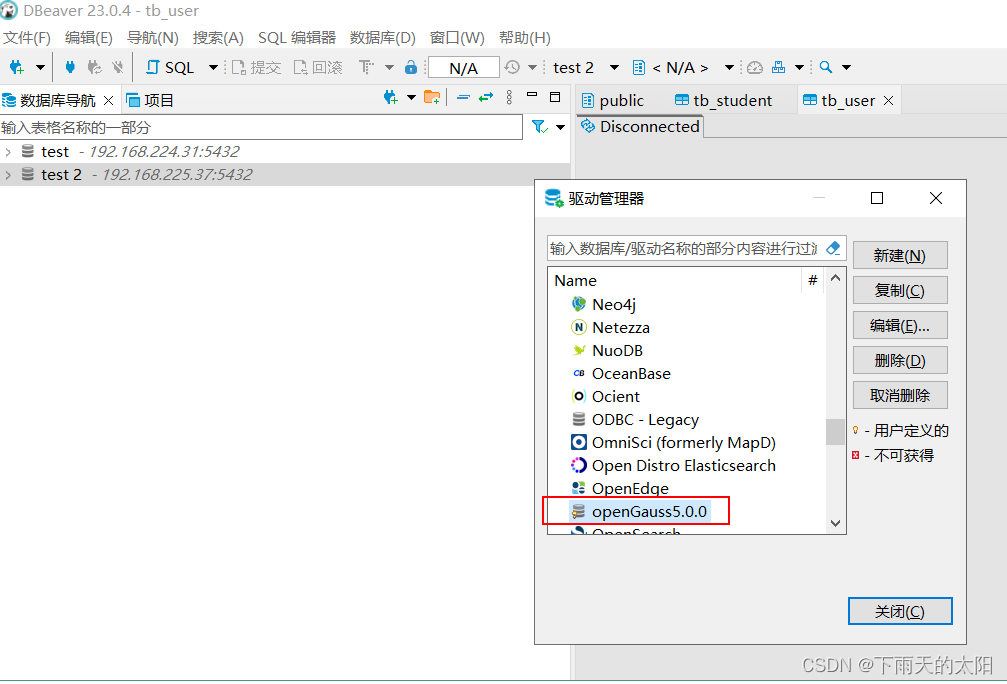
以上三步完成既可登录数据库了,建立数据库连接
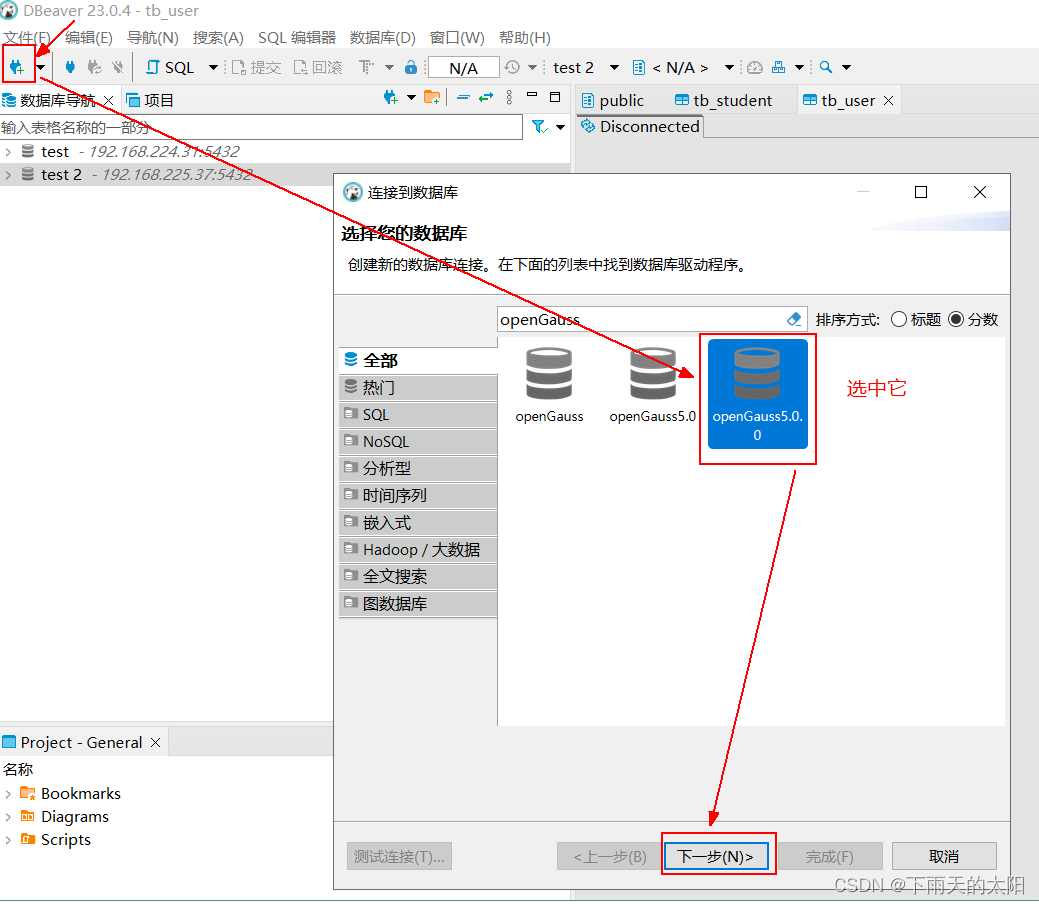
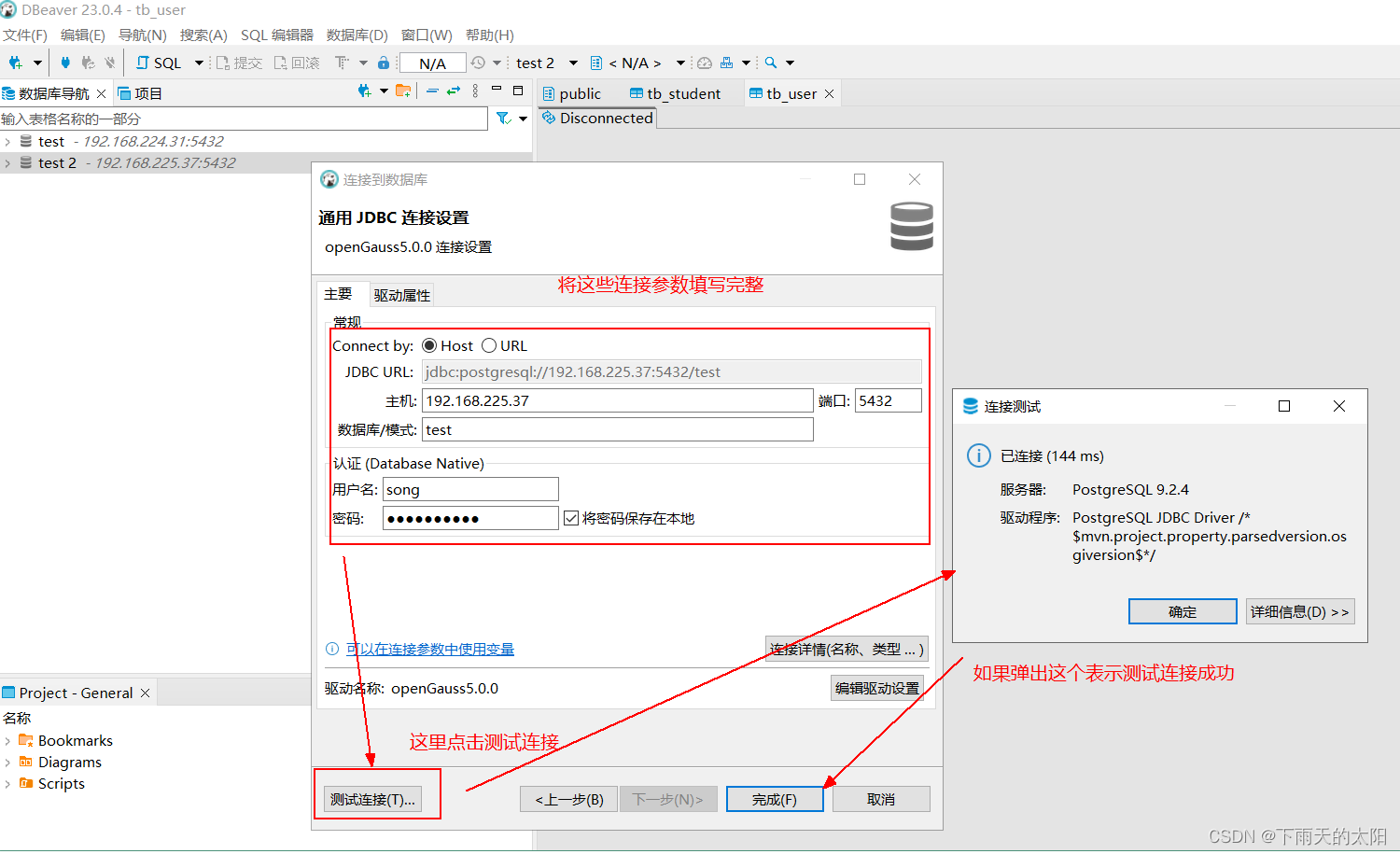
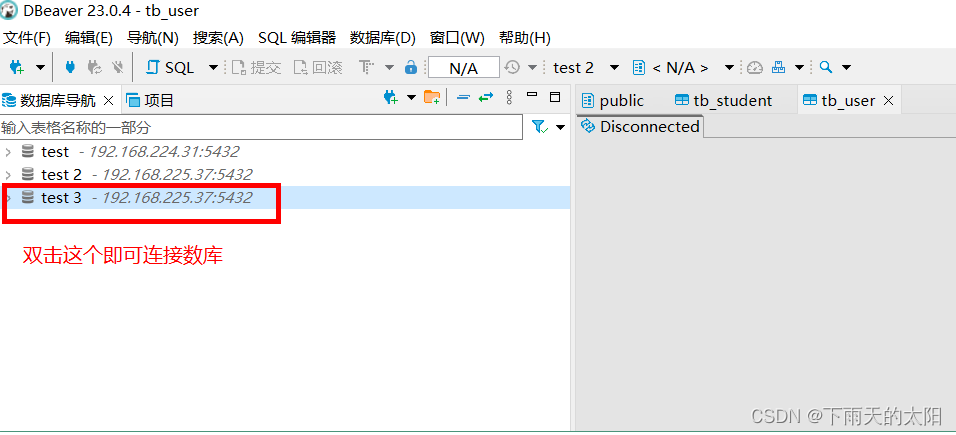
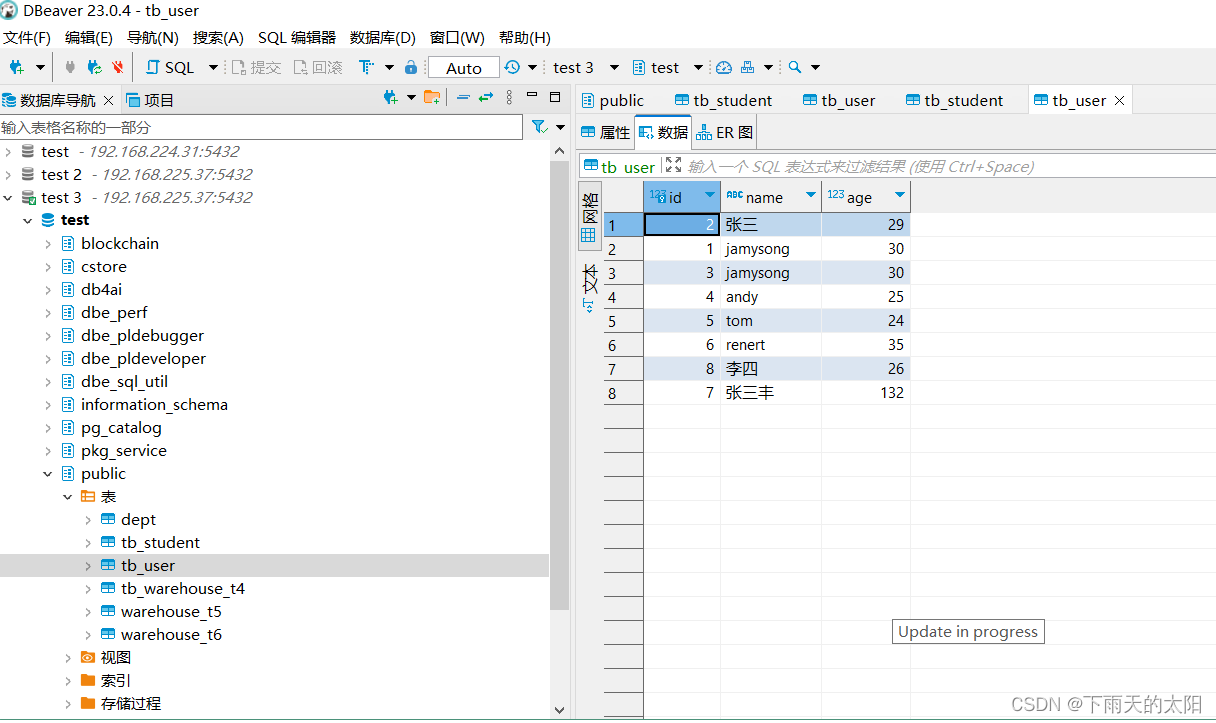
如下显示连接成功!!!
















 1383
1383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











