










目录
ItemReaders与ItemWriters
Spring Batch框架提供了很多开箱即用的ItemReaders和ItemWriters。本章将重点介绍将对这些默认实现进行介绍。除了ItemReaders和ItemWriters之外,框架还提供了一个重要的接口:ItemStream,该接口定义了ItemReaders、ItemWriters与执行上下文ExecutionContext交互的能力。一个最最直观的点,就是当Job因为某些错误原因失败后,需要重启时,如果ItemReaders和ItemWriters实现了ItemStream,那么可以直接从上一次的错误位置开始读或者写。
在Spring Batch学习与实践(一)中已经介绍了ExecutionContext(执行上下文),它是Spring Batch框架提供的持久化与控制的key/value对;能够让开发者在Step Execution或Job Execution中保存需要进行持久化的状态。其中,Step的执行上下文数据存放在表BATCH_STEP_EXECUTION_CONTEXT中;Job的执行上下文数据存放在表BATCH_JOB_EXECUTION_CONTEXT中。
在这其中Job Execution 与 StepExecution 之间的关系:
- 一个Job Execution对应一个Job Execution上下文。
- 每个Step Execution对应一个Step Execution上下文。
- 同一个Job的Step Execution共有Job Execution的上下文。
所以,同一个Job的不同Step间需要共享数据时,可以通过Job Execution实现。
三个基本接口如下:
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}
public interface ItemStream {
//根据参数打开需要读取的资源stream
void open(ExecutionContext executionContext) throws ItemStreamException;
//将需要持久化的数据放在上下文中
void update(ExecutionContext executionContext) throws ItemStreamException;
//关闭读取的资源
void close() throws ItemStreamException;
}下面将主要对Flat文件、Json文件、数据库的读写进行描述。如果要读写XML、JSM、混合记录文件、多文件读写等可以参考官方文档。
Flat文件
框架提供的Flat文件读写,支持定长类型、分隔符类型、Json类型、跨多行分隔符、交替记录分隔符文件等。
FlatFileItemReader
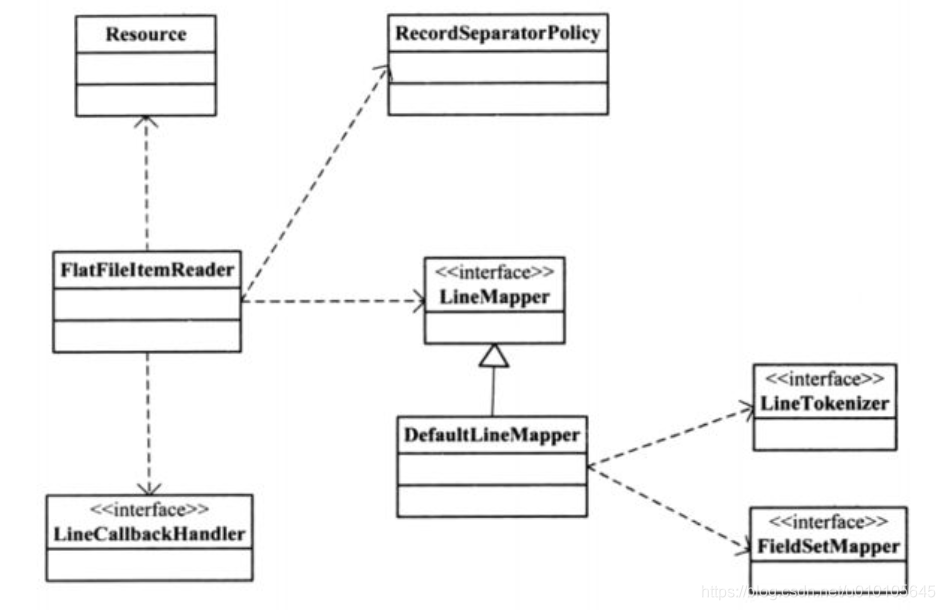
FlatFileItemReader实现ItemReader接口,核心作用是将Flat文件中的记录转换为Java对象。它通过RecordSeparatorPolicy、LineMapper、LineCallbackHandler等关键接口实现转换的目标。FlatFileItemReader引用org.springframework.core.io.Resource负责读取资源信息;通过RecordSeparatorPolicy对文件进行分割;通过LineMapper将文件中的记录转换为Java对象;LineCallbackHandler在文件中行跳过时触发,通常配合属性linesToSkip使用。
| 属性 | 类型 | 描述 |
|---|---|---|
| comments | String[] | 指定指示注释行的行前缀,当某行一这些字符串中的一个开头时,此行将被忽略 |
| encoding | String | 指定要使用的文本编码 |
| lineMapper | LineMapper | 将文件中的一行记录转换为Java对象 |
| linesToSkip | int | 文件顶部要忽略的行数。调过的记录行将会被传递给skippedLinesCallback,执行调过行的回调操作 |
| recordSeparatorPolicy | RecordSeparatorPolicy | 用于确定行尾的位置,并执行诸如在带引号的字符串中继续到行尾的操作。 |
| resource | Resource | 从中读取资源。 |
| skippedLinesCallback | LineCallbackHandler | 传递要跳过的文件中各行的原始行内容的接口。如果linesToSkip设置为2,则此接口被调用两次。 |
| strict | boolean | 在严格模式下,ExecutionContext如果输入资源不存在,则读取器将引发异常。否则,它将记录问题并继续。 |
如下实现一个简单文件读:
1. 文本数据,假设一下数据来自一个“test.csv”的文件
ID,姓氏,名字,位置,出生年份,首次亮相年份
“ AbduKa00,Abdul-Jabbar,Karim,rb,1974,1996”,
“ AbduRa00,Abdullah,Rabih,rb,1975,1999”,
“ AberWa00,Abercrombie,Walter,rb, 1959,1982”,
“ AbraDa00,Abramowicz,Danny,wr,1945,1967”,
“ AdamBo00,Adams,Bob,te,1946,1969”,
“ AdamCh00,Adams,Charlie,wr,1979,2003”2.设计java类:
ublic class Player implements Serializable {
private String ID;
private String lastName;
private String firstName;
private String position;
private int birthYear;
private int debutYear;
public String toString() {
return "PLAYER:ID=" + ID + ",Last Name=" + lastName +
",First Name=" + firstName + ",Position=" + position +
",Birth Year=" + birthYear + ",DebutYear=" +
debutYear;
}
// setters and getters...
}3. 文本记录与java映射类:
protected static class PlayerFieldSetMapper implements FieldSetMapper<Player> {
public Player mapFieldSet(FieldSet fieldSet) {
Player player = new Player();
player.setID(fieldSet.readString(0));
player.setLastName(fieldSet.readString(1));
player.setFirstName(fieldSet.readString(2));
player.setPosition(fieldSet.readString(3));
player.setBirthYear(fieldSet.readInt(4));
player.setDebutYear(fieldSet.readInt(5));
return player;
}
}在这个Mapper的实现中是通过位置来对应的。但是如文件所示,第一行记录指明了每一列属性的名称,那么我们可以通过制定名称的方式来映射数据。如下面代码段实例所示。
tokenizer.setNames(new String[] {"ID", "姓氏", "名字", "位置", "出生年份", "首次亮相年份"}); player.setID(fs.readString("ID")); player.setLastName(fs.readString("lastName")); player.setFirstName(fs.readString("firstName")); player.setPosition(fs.readString("position")); player.setDebutYear(fs.readInt("debutYear")); player.setBirthYear(fs.readInt("birthYear"));
除此之外,在FieldSetMapper的实现中,BeanWrapperFieldSetMapper可以实现字段的自动映射。代码实例如下:
@Bean public FieldSetMapper fieldSetMapper() { BeanWrapperFieldSetMapper fieldSetMapper = new BeanWrapperFieldSetMapper(); fieldSetMapper.setPrototypeBeanName("player"); return fieldSetMapper; } @Bean @Scope("prototype") public Player player() { return new Player(); }
4. FlatFileItemReader并调用read() 来读取文件:
FlatFileItemReader<Player> itemReader = new FlatFileItemReader<>();
itemReader.setResource(new FileSystemResource("test.csv"));
DefaultLineMapper<Player> lineMapper = new DefaultLineMapper<>();
//DelimitedLineTokenizer defaults to comma as its delimiter
lineMapper.setLineTokenizer(new DelimitedLineTokenizer());
lineMapper.setFieldSetMapper(new PlayerFieldSetMapper());
itemReader.setLineMapper(lineMapper);
itemReader.open(new ExecutionContext());
Player player = itemReader.read();5. 过程分析:
在读取文件时,首先要定义合适的类(步骤2),然后定义合适的字段映射类(步骤3);然后调用框架提供的Flat文件读取类(FlatFileItemReader)去读取文件。如步骤4中所示。

LineMapper类似于RowMapper,LineMapper接口定义如何将Flat文件中的一条记录转化为领域对象。该接口仅有一个方法mapLine(String line, int lineNumber),(其中line:表示行内容,lineNumber:表示行号)。Spring Batch提供了四种默认实现DefaultLineMapper, JsonLineMapper, PassThroughLineMapper, PatternMatchingCompositeLineMapper。通过LineMapper将Flat转换为领域对象,需要两个辅助类:LineTokenizer和FieldSetMapper。
- LineTokenizer负责将一条记录转换为FieldSet对象。该接口仅有一个方法FieldSet tokenize(String line); 框架同样提供了4中默认实现DelimitedLineTokenizer, FixedLengthTokenizer, PatternMatchingCompositeLineTokenizer, RegexLineTokenizer,如果这些接口不能满足业务需要也可以自定义,此时既可以实现接口LineTokenizer,也可以继承AbstractLineTokenizer。
- FieldSetMapper负责将FieldSet对象转换为领域对象,它同样也仅有一个方法T mapFieldSet(FieldSet fieldSet) throws BindException; 框架提供了3个默认实现BeanWrapperFieldSetMapper, PassThroughFieldSetMapper, RecordFieldSetMapper,如果这些接口不能满足业务需要也可以自定义,此时既可以实现接口FieldSetMapper,也可以继承ArrayFieldSetMapper,在本例中,自定义了FieldSetMapper。
FieldSet类似于ResultSet,FieldSet是Spring Batch的抽象,用于启用文件资源中字段的绑定。它使开发人员可以像处理数据库输入一样使用文件输入。
FlatFileItemWriter
FlatFileItemWriter实现ItemWriter接口,核心作用是将ItemReader或者ItemProcessor处理的Java对象转换为Flat文件中的一行记录,写入到指定的文件中。FlatFileItemWriter通过引用LineAggregator、FieldExtractor、FlatFileHeaderCallback关键接口实现前述目标。FieldExtractor将Java对象转换为文本记录时主要有两步:首先,根据FieldExtractor将Java对象根据属性抽取出Object数组,其次使用LineAggregator将Object数组转换为Flat文本的一行记录。
- LineAggregator的逻辑与LineTokenizer相反,LineTokenizer将FieldSet转换为Java对象;LineAggregator将Java对象转换成String。
public interface LineAggregator<T> { public String aggregate(T item); }
- FieldExtractor将领域对象聚合为数组,然后将数组聚合为一行。
public interface FieldExtractor<T> { Object[] extract(T item); }
public class PassThroughLineAggregator<T> implements LineAggregator<T> {
public String aggregate(T item) {
return item.toString();
}
}
@Bean
public FlatFileItemWriter itemWriter() {
return new FlatFileItemWriterBuilder<Foo>()
.name("itemWriter")
.resource(new FileSystemResource("target/test-outputs/output.txt"))
.lineAggregator(new PassThroughLineAggregator<>())
.build();
}Json文件
JsonItemReader
JsonItemReader将JSON解析和绑定委托给org.springframework.batch.item.json.JsonObjectReader接口的实现。此接口旨在通过使用流API以块的形式读取JSON对象来实现。目前提供两种实现:JacksonJsonObjectReader和GsonJsonObjectReader。
@Bean
public JsonItemReader<Trade> jsonItemReader() {
return new JsonItemReaderBuilder<Trade>()
.jsonObjectReader(new JacksonJsonObjectReader<>(Trade.class))
.resource(new ClassPathResource("trades.json"))
.name("tradeJsonItemReader")
.build();
}JsonItemWriter
@Bean
public JsonFileItemWriter<Trade> jsonFileItemWriter() {
return new JsonFileItemWriterBuilder<Trade>()
.jsonObjectMarshaller(new JacksonJsonObjectMarshaller<>())
.resource(new ClassPathResource("trades.json"))
.name("tradeJsonFileItemWriter")
.build();
}数据库读写
数据库读
Spring Batch框架对读取数据库提供了非常好的支持,包括基于JDBC和ORM的读取方式;基于游标和分页的读取数据的ItemReader组件。
游标:提供了一种对从表中检索出的数据库进行操作的灵活手段,它能够从检索出的多条数据记录的结果集中每次提取一条记录。
| 基于游标读 | 基于分页读 |
| 基于JDBC的JdbcCursorItemReader 基于Hibernate的HibernateCursorItemReader 基于存储过程的StoredProcedureItemReader | 基于JDBC的JdbcPagingItemReader 基于Hibernate的HibernatePagingItemReader 基于Ibatis的IbatisPagingItemReader 基于Jpa的JpaPagingItemReader |
1. JdbcCursorItemReader通过引用PreparedStatement、RowMapper、PreparedStatementSetter实现数据库记录向Java对象的转换。该过程主要两步:首先,根据PreparedStatement从数据库中获取结果集ResultSet;其次使用RowMapper将结果集ResultSet转换为Java对象。
public class CustomerCreditRowMapper implements RowMapper<CustomerCredit> {
public static final String ID_COLUMN = "id";
public static final String NAME_COLUMN = "name";
public static final String CREDIT_COLUMN = "credit";
public CustomerCredit mapRow(ResultSet rs, int rowNum) throws SQLException {
CustomerCredit customerCredit = new CustomerCredit();
customerCredit.setId(rs.getInt(ID_COLUMN));
customerCredit.setName(rs.getString(NAME_COLUMN));
customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN));
return customerCredit;
}
}
JdbcCursorItemReader itemReader = new JdbcCursorItemReader();
itemReader.setDataSource(dataSource);
itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER");
itemReader.setRowMapper(new CustomerCreditRowMapper());
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();2.HibernateCursorItemReader:使用该组件至少需要配置sessionFactory和queryString两个属性;sessionFactory是Hibernate的会话工厂类,用于与数据库进行交互访问;queryString用于指定查询的HQL语句。
HibernateCursorItemReader itemReader = new HibernateCursorItemReader();
itemReader.setQueryString("from CustomerCredit");
//For simplicity sake, assume sessionFactory already obtained.
itemReader.setSessionFactory(sessionFactory);
itemReader.setUseStatelessSession(true);
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();
@Bean
public HibernateCursorItemReader itemReader(SessionFactory sessionFactory) {
return new HibernateCursorItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.sessionFactory(sessionFactory)
.queryString("from CustomerCredit")
.build();
}3. 其他组件可以参考官网。
数据库写
与读取一样,数据库的写组件包括基于JDBC和ORM的写入方式。跟官方文档相同,此处没有给出写实例;在将来的应用篇将会给出。但是此处要注意官网所说的两个问题。
原文: Batching database output does not have any inherent flaws, assuming we are careful to flush and there are no errors in the data. However, any errors while writing can cause confusion, because there is no way to know which individual item caused an exception or even if any individual item was responsible.
大意:正常情况下写入没有任何问题,但是在批处理过程中如果存在写入数据错误的情况,很难确定是按个子项引起的。
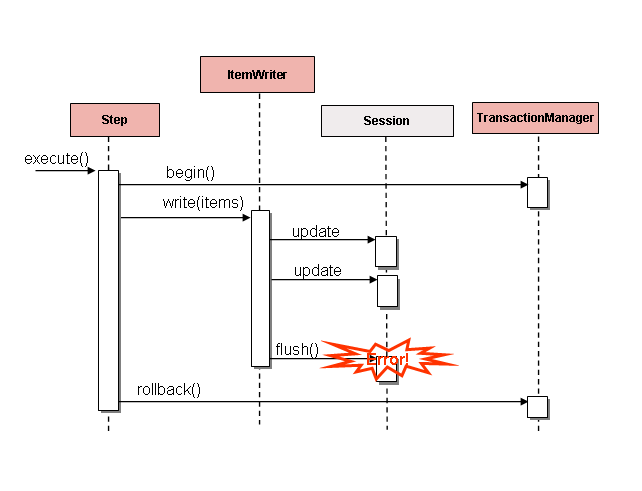
原文:If items are buffered before being written, any errors are not thrown until the buffer is flushed just before a commit. For example, assume that 20 items are written per chunk, and the 15th item throws a
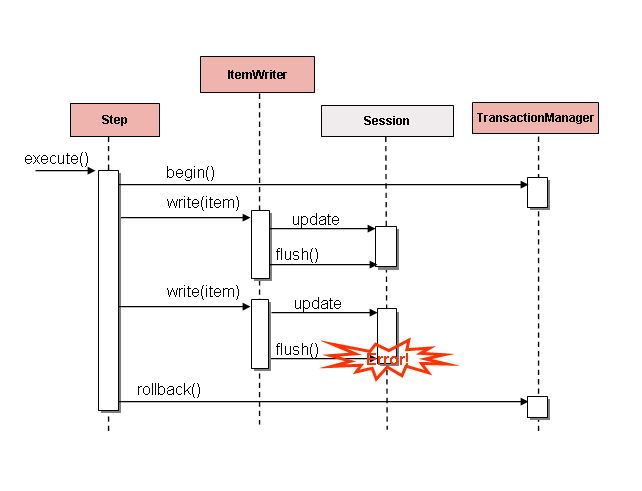
DataIntegrityViolationException. As far as theStepis concerned, all 20 item are written successfully, since there is no way to know that an error occurs until they are actually written. OnceSession#flush()is called, the buffer is emptied and the exception is hit. At this point, there is nothing theStepcan do. The transaction must be rolled back. Normally, this exception might cause the item to be skipped (depending upon the skip/retry policies), and then it is not written again. However, in the batched scenario, there is no way to know which item caused the issue. The whole buffer was being written when the failure happened. The only way to solve this issue is to flush after each item.大意:如果在写入前缓冲了项,则只有在提交前刷新缓冲区时才会抛出任何错误。例如,假设每个块写入20个条目,第15个条目抛出一个DataIntegrityViolationException异常。就该步骤而言,所有20项都已成功写入,因为在实际写入它们之前,无法知道是否发生了错误。调用会话#flush()后,将清空缓冲区并命中异常。此时,该步骤什么也做不了。事务必须回滚。通常,此异常可能导致跳过该项(取决于跳过/重试策略),然后不再写入该项。但是,在批处理场景中,无法知道是哪一项导致了问题。当失败发生时,整个缓冲区正在被写入。解决这个问题的唯一方法是在每个项目后冲洗。
服务复用
Spring Batch框架的读写组件提供了复用现有服务的能力,框架通过 ItemReaderAdapter和ItemWriterAdapter实现复用业务服务、Spring Bean 或者其他远程服务等功能。这两个类都通过调用委托模式来实现标准的Spring方法,并且设置起来非常简单。如下代码所示配置起来相对容易,只需要将业务对象和业务方法委托给Adapter即可。但是需要注意的重要一点是,targetMethod的契约必须与read的契约相同:当用尽时,它返回null。否则,可能导致无限循环读写问题。所以在1中的方法“generateFoo”需要在完成后返回null。
1. ItemReaderAdapter
@Bean
public ItemReaderAdapter itemReader() {
ItemReaderAdapter reader = new ItemReaderAdapter();
reader.setTargetObject(fooService());
reader.setTargetMethod("generateFoo");
return reader;
}
@Bean
public FooService fooService() {
return new FooService();
}2. ItemWriterAdapter
@Bean
public ItemWriterAdapter itemWriter() {
ItemWriterAdapter writer = new ItemWriterAdapter();
writer.setTargetObject(fooService());
writer.setTargetMethod("processFoo");
return writer;
}
@Bean
public FooService fooService() {
return new FooService();
}自定义ItemReader和ItemWriter
如果框架提供的读写组件不能满足业务需求的时候,可以通过实现ItemReader或者ItemWriter的方法自定义读写组件。例如,框架没有读写Excel的组件,此时如果需要操作基于Excel的批处理操作,则需要自己实现,可以使用easyexcel或者easypoi等开源框架,也可以自己封装poi。如下代码所示,是一个简单的自定义读写组件的例子,需要特别注意的是最好按照约定read()在读完所有记录后,返回null。如果项配置可以重启的读写组件,除了实现ItemReader或者ItemWriter外,还需要实现ItemStream。
public class CustomItemReader<T> implements ItemReader<T> {
List<T> items;
public CustomItemReader(List<T> items) {
this.items = items;
}
public T read() throws Exception, UnexpectedInputException,
NonTransientResourceException, ParseException {
if (!items.isEmpty()) {
return items.remove(0);
}
return null;
}
}
public class CustomItemWriter<T> implements ItemWriter<T> {
List<T> output = TransactionAwareProxyFactory.createTransactionalList();
public void write(List<? extends T> items) throws Exception {
output.addAll(items);
}
public List<T> getOutput() {
return output;
}
}框架提供了很多开箱即用的装饰器,可以参考文档
Item processing
如果想要在读写间间加入一些逻辑,有两种处理方式。
1. 读写的一种选择是使用复合模式:创建一个ItemWriter包含另一个的ItemWriter或一个ItemReader包含另一个的ItemReader。如下所示:
public class CompositeItemWriter<T> implements ItemWriter<T> {
ItemWriter<T> itemWriter;
public CompositeItemWriter(ItemWriter<T> itemWriter) {
this.itemWriter = itemWriter;
}
public void write(List<? extends T> items) throws Exception {
//Add business logic here
itemWriter.write(items);
}
public void setDelegate(ItemWriter<T> itemWriter){
this.itemWriter = itemWriter;
}
}2. 使用ItemProcess
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}
public class Foo {}
public class Bar {
public Bar(Foo foo) {}
}
public class FooProcessor implements ItemProcessor<Foo, Bar> {
public Bar process(Foo foo) throws Exception {
//Perform simple transformation, convert a Foo to a Bar
return new Bar(foo);
}
}
public class BarWriter implements ItemWriter<Bar> {
public void write(List<? extends Bar> bars) throws Exception {
//write bars
}
}
@Bean
public Job ioSampleJob() {
return this.jobBuilderFactory.get("ioSampleJob")
.start(step1())
.end()
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<Foo, Bar>chunk(2)
.reader(fooReader())
.processor(fooProcessor())
.writer(barWriter())
.build();
}当我们需要链式处理时,需要自定义一系列的ItemProcess,然后将其放到CompositeItemProcessor中即可。
@Bean
public Job ioSampleJob() {
return this.jobBuilderFactory.get("ioSampleJob")
.start(step1())
.end()
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<Foo, Foobar>chunk(2)
.reader(fooReader())
.processor(compositeProcessor())
.writer(foobarWriter())
.build();
}
@Bean
public CompositeItemProcessor compositeProcessor() {
List<ItemProcessor> delegates = new ArrayList<>(2);
delegates.add(new FooProcessor());
delegates.add(new BarProcessor());
CompositeItemProcessor processor = new CompositeItemProcessor();
processor.setDelegates(delegates);
return processor;
}框架提供了一些开箱即用的组件用于数据处理,如筛选记录、有效性检查、容错等。这些都可以在官方文档中找到实例,相对也比较简单。此处不再赘述。

















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









