







Elasticsearch实战—ES数据建模一对多模型Nested结构
文章目录
我们如何把Mysql的模型合理的在ES中去实现? 就需要你对要存储的数据足够的了解,及对应用场景足够的深入分析,才能建立一个合适的模型,便于你后期扩展
- 一对一 模型
- 一对多 模型
- 多对多 模型
上一篇,我们介绍了 一对多模型,采用Object对象存储的巨大缺陷,本篇文章,我们给出解决办法 就是采用Nested结构来存储数据, 但是Nested查询和读写需要有特定的语法,也就是一定程度上增加了读写的复杂性,但是数据的查询结果是正确的,所以说Nested 才是我们一对多 推荐的一种设计模型
1.ES 一对多模型Nested 结构模型实战
我们采用下面创建Index mapping结构,和上一篇大致一样的结构,把多个手机相同的分类信息,作为冗余字段 冗余到 手机基本信息中
差别就是 : 这次category字段,我们采用Nested结构,而不是Object结构,通过关键字 type:nested 来实现
索引库结构
PUT /phone_nested_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"productId": {
"type": "long"
},
"productName": {
"type": "keyword"
},
"productPrice": {
"type": "long"
},
"productNumber": {
"type": "long"
},
"category": {
"type": "nested",
"properties": {
"categoryName": {
"type": "keyword"
},
"categoryRemark": {
"type": "keyword"
}
}
}
}
}
}
同样的,插入数据, 下面我们给 phone_index 索引库插入数据, 插入 6条手机信息
put /phone_nested_index/_bulk
{"index":{"_id":1}}
{"productId":1,"productName":"P20","productPrice":4000,"productNumber":50,"category":{"categoryName":"华为手机","categoryRemark":"高端"}}
{"index":{"_id":2}}
{"productId":2,"productName":"Honor30","productPrice":2000,"productNumber":100,"category":[{"categoryName":"华为手机","categoryRemark":"很好"},{"categoryName":"荣耀手机","categoryRemark":"便宜"}]}
{"index":{"_id":3}}
{"productId":3,"productName":"小米8","productPrice":2000,"productNumber":600,"category":{"categoryName":"小米手机","categoryRemark":"中端"}}
{"index":{"_id":4}}
{"productId":4,"productName":"红米10","productPrice":2500,"productNumber":300,"category":{"categoryName":"小米手机","categoryRemark":"发烧"}}
{"index":{"_id":5}}
{"productId":5,"productName":"小米Max","productPrice":4000,"productNumber":800,"category":{"categoryName":"小米手机","categoryRemark":"很好"}}
2.ES字段查询
我们要查询 华为手机 便宜的 标签,must 查询, 分类:华为手机,描述:便宜
Nested结构查询,需要特定的语法,需要加上查询路径,我们的就是 path:category 信息
2.1 非Nested 错误结构及错误查询
老的结构 非Nested phone_index 数据
get /phone_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"category.categoryName": "华为手机"
}
},
{
"match": {
"category.categoryRemark": "便宜"
}
}
]
}
}
}
查询结果 不是我们想要的, 是错误的
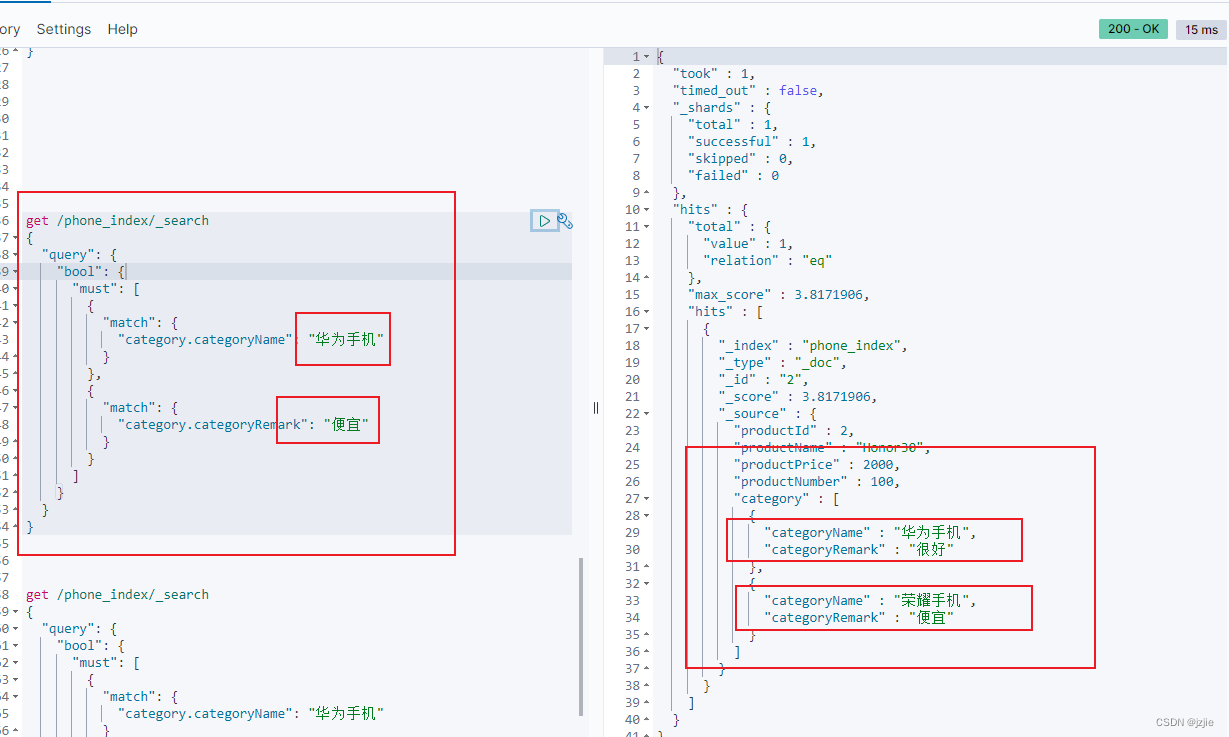
或者 我们再查询以下 华为手机-发烧的 场景, 按照我们的数据, 不存在任何数据把华为手机和发烧关联
must查询, 分类:华为手机, 标签:发烧
get /phone_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"category.categoryName": "华为手机"
}
},
{
"match": {
"category.categoryRemark": "发烧"
}
}
]
}
}
}
查询结果错误, 要查询 华为手机-发烧的数据,结果把 小米手机查询出来了,这是明显的错误

2.2 Nested结构,正确查询
同样,我们采用Nested结构查询, 查询华为手机 且便宜的 信息
Nested结构查询,需要带上查询条件 path路径信息 “nested”: {“path”: “category”}
get /phone_nested_index/_search
{
"query": {
"nested": {
"path": "category",
"query": {
"bool": {
"must": [
{
"match": {
"category.categoryName": "华为手机"
}
},
{
"match": {
"category.categoryRemark": "便宜"
}
}
]
}
}
}
}
}
查询结果, 符合预期,并没有查询出 错误的结果, 查询结果为空
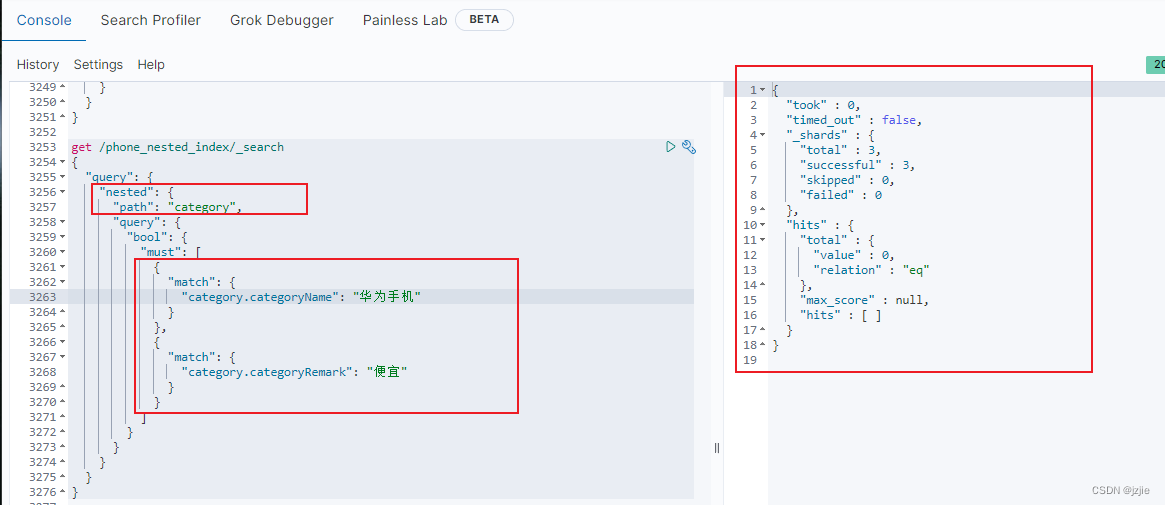
现在我们来查以下另一种场景, 华为手机-发烧 的查询语句,看看是否能够正确查询
get /phone_nested_index/_search
{
"query": {
"nested": {
"path": "category",
"query": {
"bool": {
"must": [
{
"match": {
"category.categoryName": "华为手机"
}
},
{
"match": {
"category.categoryRemark": "发烧"
}
}
]
}
}
}
}
}
同样的结果,查询结果没有数据, 也是符合我们预期的,是正确的查询结果
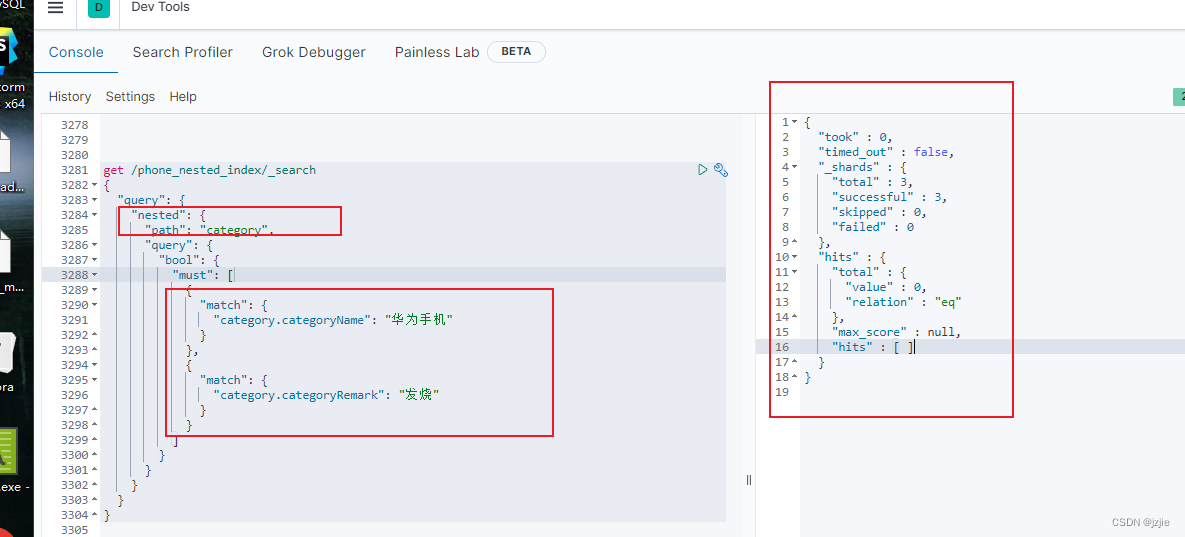
3.Nested结构原理
上面我们验证了采用Nested 结构,可以有效的解决 object对象存储, 错误的查询方式这种缺陷,那么原理是什么呢?
官方定义:官方释义:
- nested属于object类型的一种,是Elasticsearch中用于复杂类型对象数组的索引操作。Elasticsearch没有内部对象的概念
- ES在存储复杂类型的时候会把对象的复杂层次结果扁平化为一个键值对列表,
- 说明白点就是 把搜索条件指定到一个独立Object对象中,把搜索的条件指定到数组中某一个特定 object 数据中, 而不是分散在整个数组中
- 虽然读写操作复杂了,但是 查询结果是正确的,这是我们一对多 推荐的一种设计模型
这样就可以解决Object对象存储的问题















 1235
1235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









