







1 案例学习简介
1.1 数据采集
相信很多小伙伴对爬虫非常感兴趣,这也是数据科学中最基础的环节--数据采集,有了数据,后续才能做数据清洗、数据建模、数据分析、数据可视化。而爬虫正是数据采集环节最关键的一个部分。一般从三个方面获取数据,一是公司的生产数据,二是花钱购买,三就是不要钱从网上爬,一看不要钱顿时来精神了,所以学习爬虫就有了很大的动力。
1.2 爬虫框架
爬虫框架是一种可重复使用的软件工具,用于快速开发网络爬虫。它提供了常用的爬虫功能,例如请求管理、数据解析、数据存储等,让开发人员可以更加专注于爬虫的业务逻辑。常见的爬虫框架有Scrapy、BeautifulSoup、Requests等。
最初写爬虫是通过Requests、selenium实现的,Requests模块可以爬取不带登录验证码的相关网站,selenium爬取带有验证码等相关网站,这里不多说,后续我会找些我做过的一些案例代码发到博客上。尽管这些模块也能实现爬虫功能,但是我感觉还是不够专业不上档次,就好比别人出门都是开车,而我都是骑电动车,于是我重新用Scrapy框架来爬取一些数据。
1.3 Scrapy
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
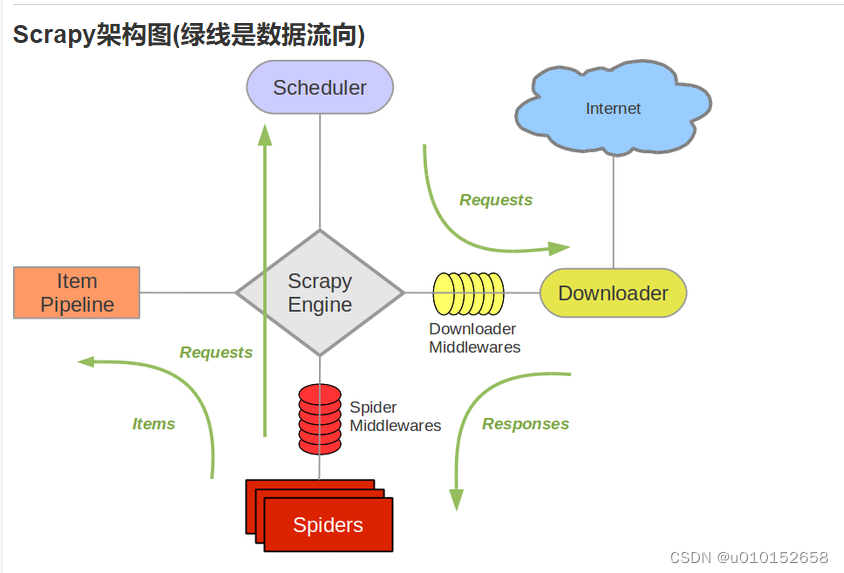
上图是Scrapy架构图,小伙伴们自己看,看不懂也没有关系,有个印象就行了额,不影响我们写代码。
1.4 情况说明
相信很多小伙伴并不是通过看文章来系统的学习技术,于是打开学习神站B站,搜索Scrapy爬虫,找个点击量较大的视频开始学习,《精通Scrapy爬虫框架,扒光一个网站(案例:豆瓣,京东)》我就不上链接了,总体这个学习视频还是可以的,但是视频时间太早了,经过几年的变化,很多案例已经不能使用了。主要原因有:
(1)网站网页结构变化了,静态页面变成动态加载(京东图书页面)
(2)html页面数据变成JSON数据(网易招聘、腾讯招聘)
(3)反爬技术实施(豆瓣频繁请求封IP,空气质量网禁用调试)
这几天我陆续把这些代码都给小伙伴补充完整,尽量实现所有的功能,亲测可用,个别还有点小问题的,欢迎大家批评指正。
2 爬取4399游戏网站
2.1 简介
这个网站基本没有什么问题,结构简单,静态页面,通过这个案例让小伙伴们熟悉Scrapy框架,实现爬取的数据写入Redis 数据库。网址:不写了,看截图吧我这里真不是广告。
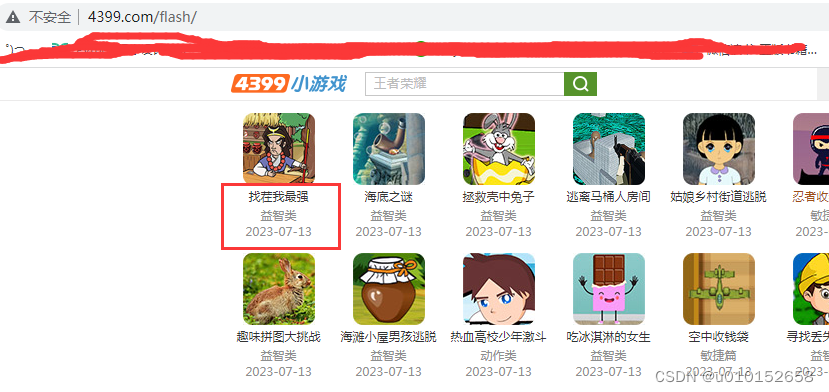
2.2 Scrapy项目流程
1、创建项目 scrapy startproject 项目名称
2、进入项目 (cd 项目名称)
3、创建爬虫 scrapy genspider 爬虫名字(game4399) 要爬取网站的域名
4、可能需要修改start_urls,修改成你要抓取的那个页面 5、对数据进行解析,在spider里面的parse(response)方法中进行解析 ,代码解释(game4399.py)
import scrapy
from game.items import GameItem
class Game4399Spider(scrapy.Spider):
name = "game4399" #爬虫的名字,通过scrapy genspider game4399 4399.com 命令创建
allowed_domains = ["4399.com"] #允许的域名
start_urls = ["http://www.4399.com/flash/"] #起始页面
def parse(self, response): #该方法是默认用来解析网页的
#print(response.text)
li_list = response.xpath('//ul[@class="n-game cf"]/li')
item = GameItem()
for li in li_list:
item['name'] = li.xpath("./a/b/text()").extract_first()
item['category'] = li.xpath("./em/a/text()").extract_first()
item['fx_date'] = li.xpath("./em/text()").extract_first()
yield item #不需要列表,不占内存,引擎来调用数据
part_url = response.xpath('//*[@id="pagg"]/a[last()]/@href').extract_first()
print(type(part_url))
if 'htm' in str(part_url):
part_url = response.urljoin(part_url)
print(part_url)
#构建请求对象
yield scrapy.Request(
url = part_url,
callback = self.parse,
)
else:
print('已经没有页面数据可以爬取!')这里是主要的代码做些简要的说明。
(1)、from game.items import GameItem 这个是将爬取的数据写入Scrapy框架自带的字典结构的变量,后面会把这些数据交给管道Pileline,由管道来保存数据。而GameItem类是在文件items.py中定义的。优点是数据不保存到列表,不用占内存。game.items是指这个items.py文件是放在game文件夹下面的。
import scrapy
class GameItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
category = scrapy.Field()
fx_date = scrapy.Field()
spider_name = scrapy.Field()
crawled = scrapy.Field()(2)、Xpath解析的问题,这里我就不一一详细的说了,通过谷歌浏览器的F12,elements获取相关的XPATH节点,大家注意的是这里面有一个翻页,翻页的URL通过Xpath来获取,part_url = response.xpath('//*[@id="pagg"]/a[last()]/@href'),这里是拿id="pagg最后一个a标签的href属性,就是页面元素button下一页,只要下一页有链接就获取这个链接,如果没有链接,就是没有‘htm’这几个字符,循环结束。
(3)、获取翻页的链接后,再构建请求对象,送给自己解析。这里是一个递归调用。最后将所有的数据通过yield item 传递给管道pipelines.py中的相关模块进行处理。
2.3 数据保存到Redis数据库
1、Redis
Redis 是一个开源的、使用 C 语言编写的 NoSQL 数据库。数据库的工作模式按存储方式可分为:硬盘数据库和内存数据库。Redis 将数据储存在内存里面,读写数据的时候都不会受到硬盘 I/O 速度的限制,所以速度极快。Redis作为基于内存运行的数据库,缓存是其最常应用的场景之一。除此之外,Redis常见应用场景还包括获取最新N个数据的操作、排行榜类应用、计数器应用、存储关系、实时分析系统、日志记录。下载:Redis中文网Redis中文网
2、安装使用Redis
安装完不是像Mysql自动启动,这个需要手动启动,进入安装目录执行redis-server.exe redis.windows.conf 成功启动见下图。
Redis 数据库也有GUI管理软件,大家可以使用RedisDesktopManager进行数据管理。这个数据库在Scrapy的相关配置是在Settings.py里面设置。后面会说。
3、pipelines.py
from scrapy_redis.spiders import RedisCrawlSpider
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from redis import Redis
from datetime import datetime
#管道默认是不生效的,需要启动
class GamePipeline:
#处理数据的专用方法
def process_item(self, item, spider):
item['spider_name'] = spider.name
item['crawled'] = datetime.strftime(datetime.utcnow(), "%Y-%m-%d")
print(item)
return item
class RedisPipeline(object):
conn = None
def open_spider(self, spider):
self.conn = Redis(host='127.0.0.1',port=6379)
def process_item(self, item, spider):
dic = dict(item)
self.conn.lpush('game1',str(dic))
return item
def close_spider(self, spider):
pass这里面定义了2个管道,第一个是显示数据,当然也可以这里实现把获取的数据写入文件都可以。第二个是保存到Redis数据库的模块,当然要使用首先导入相关的Python模块。这两个管道打开关闭以及优先级是在Settings.py文件中定义,数值越小优先级越高。
4 Settings.py
BOT_NAME = "game"
SPIDER_MODULES = ["game.spiders"]
NEWSPIDER_MODULE = "game.spiders"
LOG_LEVEL = 'WARNING'
ROBOTSTXT_OBEY = True
# scrapy-redis巧妙的利用redis 实现 request queue和 items queue,
# 利用redis的set实现request的去重,将scrapy从单台机器扩展多台机器,实现较大规模的爬虫集群
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# scrapy.dupefilters.RFPDupefilter在settings.py模块中默认是开启状态!
# 默认RFPDupeFilter基于使用该scrapy.utils.request.request_fingerprint
# 函数的请求指纹进行过滤。
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
SCHEDULER_PERSIST = True
#我们需要添加redis的地址,程序才能够使用redis
#REDIS_URL = "redis://127.0.0.1:6379"
#或者使用下面的方式
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
DOWNLOAD_DELAY = 1
ITEM_PIPELINES = {
"game.pipelines.GamePipeline": 300,
"game.pipelines.RedisPipeline": 301,
}
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
全部设置完毕,开始运行爬虫程序
scrapy crawl game4399
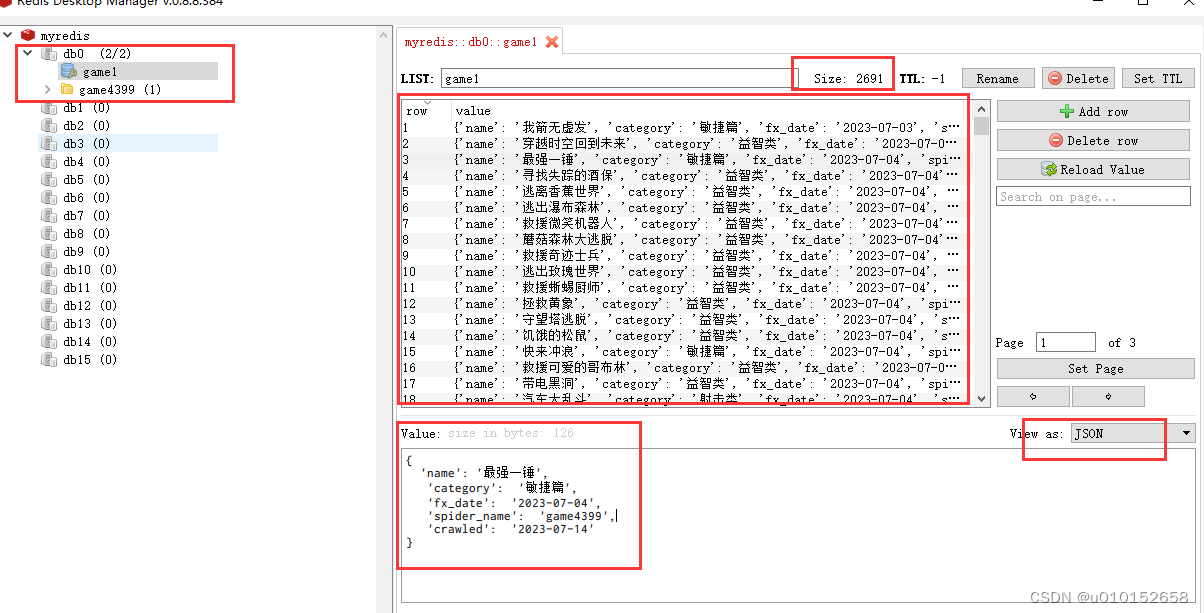
Redis数据库还有2个优点,第一就是不需要新建表,无需用户名,密码,直接写入;第二可以实现分布式爬取。这个后面再具体案例说明。这里看配置文件
# scrapy-redis巧妙的利用redis 实现 request queue和 items queue,
# 利用redis的set实现request的去重,将scrapy从单台机器扩展多台机器,实现较大规模的爬虫集群DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# scrapy.dupefilters.RFPDupefilter在settings.py模块中默认是开启状态!
# 默认RFPDupeFilter基于使用该scrapy.utils.request.request_fingerprint
# 函数的请求指纹进行过滤。
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
SCHEDULER_PERSIST = True
如果已经运行过该爬虫项目并且数据已经保存Redis数据库,再次就不会再向数据库写入数据了。请忽略如下警告,并不影响项目运行。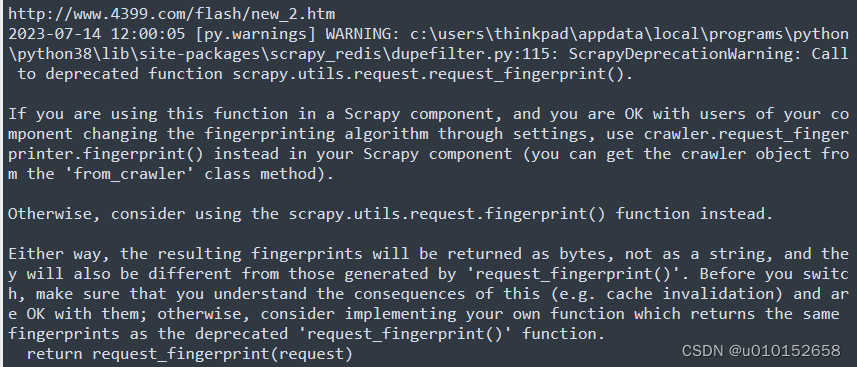
该警告的意思是:如果你在Scrapy组件中使用这个函数,并且你对组件的用户通过设置更改指纹识别算法没有意见,那么在Scrapy组件中使用crawler.request_fingerprint .fingerprint()代替(你可以从'from_crawler'类方法中获取爬虫对象)。否则,请考虑使用scrapy.utils.request.fingerprint()函数。
3、最后总结
(1)项目源码可以通过https://github.com/wangluixn/scrapy-game4399 来获取,这个网站经常返回不到数据,https://gitee.com/wang-luxin/scrapy-game4399.git 这是中国的git,速度很快。
(2)本案例是使用scrapy框架爬取4399小游戏上面的静态页面信息,并将数据写入Redis数据库。 本案例仅供学习使用,其他用途产生的后果自负。
(3)Scrapy的优点如下(小伙伴可以自己体会下)
1 Scrapy是异步的:Scrapy 使用了Twisted(aiohttp)异步网络框架来处理网络通讯,可以加快下载速度,并且包含了各种中间件接口,可以灵活的完成各种需求
2 采取可读性更强的XPath代替正则表达式:Xpath是XML Path的简介,基于XML树状结构,可以在整个树中寻找锁定目标节点。由于HTML文档本身就是一个标准的XML页面,因此我们可以使用XPath的语法来定位页面元素。
3 强大的统计和日志系统:日志记录是指使用内置的日志系统和定义的函数或类来实现应用程序和库的事件跟踪。 记录日志是一个即用型的程序库,它可以在Scrapy设置日志记录中的设置列表工作。LOG_LEVEL = 'WARNING' 大家如果想看日志信息,将settings文件的这行注释掉即可。
4 可同时在不同的URL上爬行,Scrapy可以并行的同时爬取多个页面。
5 支持shell方式,方便独立调试:Scrapy shell是一个交互式shell,您可以在此快速尝试和调试您的抓取代码,而无需运行爬虫程序。
6 方便写一些统一的过滤器;当我们在爬取网页的时候可能会遇到一个调转连接会在不同页面出现,这个时候如果我们的爬虫程序不能识别出该链接是已经爬取过的话,就会造成一种重复不必要的爬取。所以我们要对我们即将要爬取的网页进行过滤,把重复的网页链接过滤掉,Scrapy提供默认的指纹过滤器,此外也可以自定义过滤器对数据进行过滤。
7 通过管道的方式存入数据库:在Scrapy中,管道负责数据的清洗、保存。就是将每一个Item对象进行持久化的存储














 2847
2847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









