







 该案例演示了如何使用Scrapy框架爬取传智教育网站上的教师信息,并将数据存储到MongoDB数据库中。Scrapy蜘蛛解析页面,提取教师的姓名、职位和简介,然后通过两个管道分别将数据写入JSON文件和MongoDB数据库。MongoDB是一个基于文档的NoSQL数据库,适合处理大型数据。案例还包括了MongoDB的安装和配置,以及使用RObo3T进行数据库管理。
该案例演示了如何使用Scrapy框架爬取传智教育网站上的教师信息,并将数据存储到MongoDB数据库中。Scrapy蜘蛛解析页面,提取教师的姓名、职位和简介,然后通过两个管道分别将数据写入JSON文件和MongoDB数据库。MongoDB是一个基于文档的NoSQL数据库,适合处理大型数据。案例还包括了MongoDB的安装和配置,以及使用RObo3T进行数据库管理。
1、案例介绍
本案例是爬取传智教育网站教师信息,这个页面也比较简单,不用登陆,页面源码里面就有需要的数据,我们重点放到如何保存MongoDB数据库。
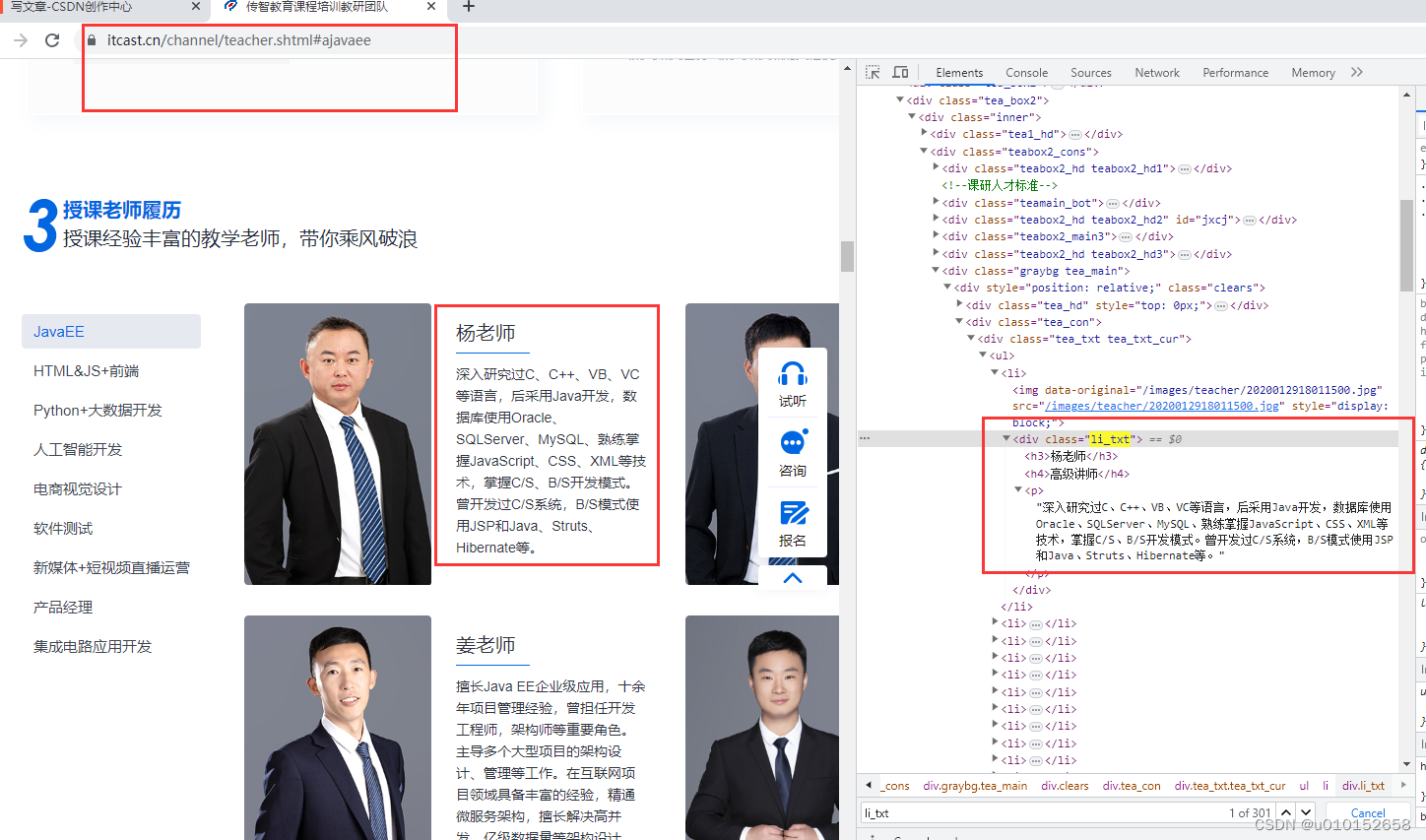
2、创建项目 scrapy startproject mycase 创建爬虫 scrapy genspider itcast itcast.cn itcast.py 文件内容如下。
import scrapy
from ..items import MycaseItem
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = ["https://www.itcast.cn/channel/teacher.shtml"]
def parse(self, response):
#print(response)
#print(response.text)
node_list = response.xpath("//div[@class='li_txt']")
for teacher in node_list:
item = MycaseItem()
name = teacher.xpath('./h3/text()').extract_first().strip()
# xpath返回的都是列表,元素根据匹配规则来(e.g. text())
title = teacher.xpath('./h4/text()').extract_first().strip()
info = teacher.xpath('./p/text()').extract_first().strip()
item['name'] = name
item['title'] = title
item['info'] = info
yield item
3、MongoDB数据库
MongoDB是一种基于文档的NoSQL数据库,它使用类似于JSON的文档(称为BSON)来存储数据。MongoDB具有高度的可扩展性和灵活性,能够处理大型数据集和高量级的数据读写操作。下载地址:Download MongoDB Community Server | MongoDB 安装简单,装完修改下环境变量,这个数据库默认随windows系统启动,不用手动打开服务。测试安装成功的方式如下。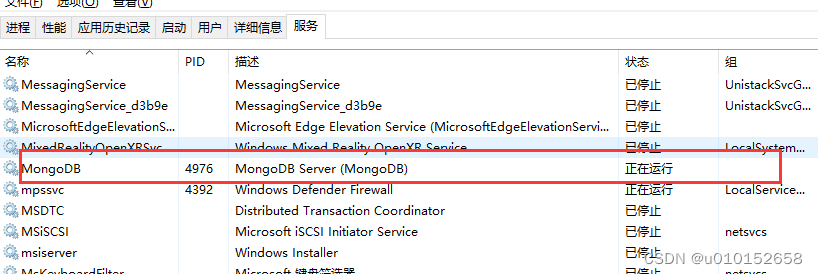
 pipelines.py文件内容如下 。下面定义了2个管道,一个是写入JSON文件的,一个是写入MongoDB的,注意拼写把,Mongo不要打成mango。
pipelines.py文件内容如下 。下面定义了2个管道,一个是写入JSON文件的,一个是写入MongoDB的,注意拼写把,Mongo不要打成mango。
from itemadapter import ItemAdapter
import json
from pymongo import MongoClient
class MycasePipeline:
def __init__(self):
self.file = open("itcast.json",'w')
def process_item(self, item, spider):
item = dict(item)
#print(type(item))
json_data= json.dumps(item,ensure_ascii=False) + ',\n'
self.file.write(json_data)
return item
def __del__(self):
self.file.close()
class MangoPipeline(object):
def open_spider(self,spider):
self.client = MongoClient('127.0.0.1',27017)
self.db = self.client['mydb']
self.col = self.db['itcast']
def process_item(self, item, spider):
data = dict(item)
self.col.insert_one(data)
return item
def close_spider(self,spider):
self.client.close()
ITEM_PIPELINES = {
"mycase.pipelines.MycasePipeline": 300,
"mycase.pipelines.MangoPipeline":301,
} 注意下settings文件将2个管道都打开的时候设置优先级,注释掉其中的一行就是关闭一个。
4、可以用RObo3T软件管理数据库,但是这个软件有限制,只能查看50条数据,我这里只是学习,不研究了,大家可以找其他的MongoDB管理软件。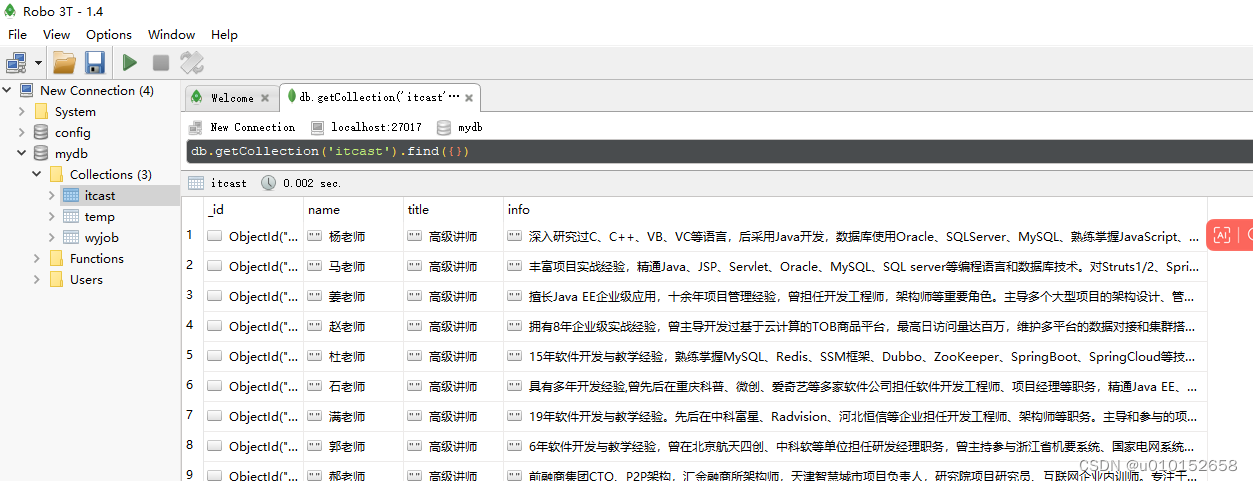
https://github.com/wangluixn/scrapy_itcast.git
本案例仅供学习使用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









