







MySQL系列:innodb源码分析之基础数据结构
近一年来一直在分析关于数据库相关的源码,前段时间分析了levelDB的实现和BeansDB的实现,这两个数据库网络上分析的文章很多,也都比较分析的比较深,所以也就没有太多必要重复劳动。最近开始关注关系数据库和MYSQL,当然主要还是数据库存储引擎,首先我还是从innodb这个最流行的开源关系数据库引擎着手来逐步分析和理解。我一般分析源码的时候都是从基础的数据结构和算法逐步往上分析,遇到不明白的地方,自己按照源码重新输入一遍并做对应的单元测试,这样便于理解。对于Innodb这样的大项目,也应该如此,以后我会逐步将具体的细节和实现写到BLOG上。我分析Innodb是以MySQL-3.23为蓝本作为分析对象,然后再去比较5.6版本的改动来做分析的。这样做有个好处就是先理解相对基础的代码容易,在有了基本概念后再去理解最新的改动。以下是我对innodb基础的数据结构和算法的理解。
1.vector
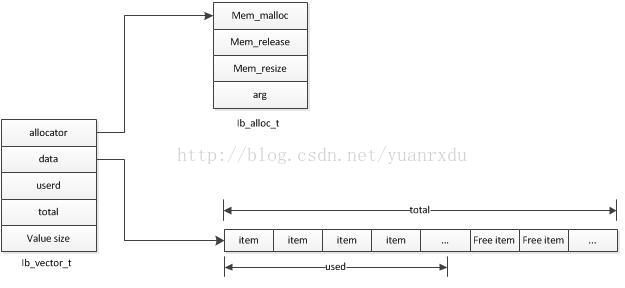
innodb的vector是个动态数组的数据结构,和c++的STL用法相似,值得一提的是vector的内存分配可以通过函数指针来指定是从heap内存池堆上分配内存还是用OS自带的malloc来分配内存。内存分配器的结构为:
- struct ib_alloc_t {
- ib_mem_alloc_t mem_malloc; //分配器的malloc函数指针
- ib_mem_free_t mem_release; //分配器的free函数指针
- ib_mem_resize_t mem_resize; //分配器的重新定义堆大小指针
- void* arg; //堆句柄,如果是系统的malloc方式,这个值为NULL
- style="white-space:pre"> </span>};
vector内存结构:
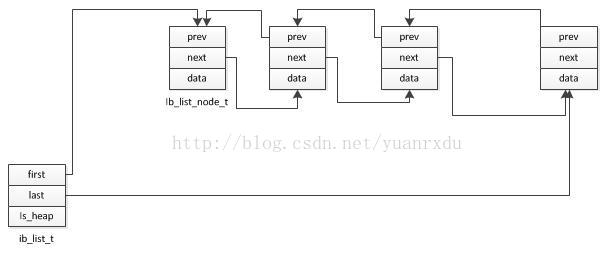
2.内存list
innodb的list数据结构是个标准的双向链表结构,ib_list_node_t当中有指向前一个node的prev和指向后一个
node的next,
list的内存分配可以通过heap内存堆来分配,也可以通过系统的malloc来分配。
就看是采用
ib_list_create_heap来创建list爱是永ib_list_create来创建list。但是内部的ib_list_node_t的内存分配是通过
heap来分配的。
ist的内存结构:
3.FIFO-queue
innodb的FIFO queue是个多线程的消息队列,可以有多个线程向queue中添加消息,可有多个线程同时读取queue中的消息并进行处理。queue的mutex是保证同时只有一个线程在操作(读或者写)queue的items链表,os_event是写线程完成后通知所有读线程可以进行queue的读事件,也就是说,只有向queue写完成一个消息,才会发送event信号给读线程。queue的消息缓冲区是采用ib_list_t来做存储的,一般写的时候写在list的最后,而读总是读取list的第一个。queue处理提供一直读取到消息为止的方法以外,也提供最长等待读取消息的方法,这样读取线程没有必要一直等待消息,可以在等待一段时间后去处理其他的任务。其C结构定义如下:
- struct ib_wqueue_t
- {
- ib_mutex_t mutex; /*互斥量*/
- ib_list_t* items; /*用list作为queue的载体*/
- os_event_t event; /*信号量*/
- };
4.哈希表
innodb中的哈希表的基本构造和传统的哈希表的构造是相似的,不同的就是innodb的哈希表采用的是自定义链式桶结构,而没有采用每个桶单元用传统的list来做碰撞管理。由于这个特性,innodb中的哈希表操作采用了一系列操作宏来做操作,这样做的目的是为了能泛型的对哈希表做操作,因为在innodb中,除了操作内存中的数据以外,还会操作隐射硬盘中的数据。以下是innodb的操作宏:
HASH_INSERT 插入操作
HASH_DELETE 删除操作
HASH_GET_FIRST 获取指定HASH key对应cell的第一个数据单元
HASH_GET_NEXT 获取cell_node对应的下一个单元
HASH_SEARCH 查找对应key的值
HASH_SEARCH_ALL 遍历整个hash table并将每个数据单元为参数执行ASSERTION操作
HASH_DELETE_AND_COMPACT 删除操作并且优化和调整heap堆上的内存分配布局,使得heap效率更高
HASH_MIGRATE 将OLD_TABLE的数据单元合并到NEW_TABLE当中
这些宏在调用的时候都会指定数据的类型和Next函数名。
innodb的哈希表在多线程并发模式下也提供cell级粒度的锁,有mutex类型的锁,也有rw_lock类型的锁。在hash_create_sync_obj_func函数调用过程中,会创建一个n_sync_obj的锁数据单元,n_sync_obj必须是2的N次方。也就是说如果n_sync_obj = 8, 哈希表的n_cells = 19,那就至少两个cell公用一个锁。这是其他哈希表无法比拟的。
以下是hash table的结构定义:
- struct hash_table_t
- {
- enum hash_table_sync_t type; /*hash table的同步类型*/
- ulint n_cells; /*hash桶个数*/
- hash_cell_t* array; /*hash桶数组*/
- #ifndef UNIV_HOTBACKUP
- ulint n_sync_obj;
- union{ /*同步锁*/
- ib_mutex_t* mutexes;
- rw_lock_t* rw_locks;
- }sync_obj;
- /*heaps的单元个数和n_sync_obj一样*/
- mem_heap_t** heaps;
- #endif
从物理意义上来讲,InnoDB表由共享表空间、日志文件组(redo文件组)、表结构定义文件组成。若将innodb_file_per_table设置为on,则系统将为每一个表单独的生成一个table_name.ibd的文件,在此文件中,存储与该表相关的数据、索引、表的内部数据字典信息。表结构文件则以.frm结尾,这与存储引擎无关。
以下为InnoDB的表空间结构图:

在InnoDB存储引擎中,默认表空间文件是ibdata1,初始化为10M,且可以扩展,如下图所示:















 4970
4970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









