







Python 入门—1
初学python的时候,一定要记住“一切皆为对象,一切皆为对象的引用”这句话。
Python语言简介
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
- Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
- Python 是交互式语言: 这意味着,您可以在一个Python提示符,直接互动执行写你的程序。
- Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
- Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏
Python环境搭建
Python可应用于多平台包括 Linux 和 Mac OS X。
你可以通过终端窗口输入 “python” 命令来查看本地是否已经安装Python以及Python的安装版本。
使用linux操作系统自带有Python,可以查看Python输入,检查当前的系统安装的那些版本的Pyrhon.
运行Python,有三种方式可以运行Python:
- 交互式解释器
- 命令行脚本
- 集成开发环境(IDE:Integrated Development Environment): PyCharm
Python语法
Python标识符
在 Python 里,标识符由字母、数字、下划线组成,但不能以数字开头,区分大小写。 以下划线开头的标识符是有特殊意义的。
单下划线开头 _foo 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 而导入; 以双下划线开头的 foo 代表类的私有成员;
双下划线开头和结尾的 __foo 代表 Python 里特殊方法专用的标识,如 __init__() 代表类的构造函数。
Python行和缩进
学习 Python 与其他语言最大的区别就是:Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:test.py
if True:
print "Answer"
print "True"
else:
print "Answer"
# 没有严格缩进,在执行时会报错
print "False" Python其他语法
- 多行语句: 可以使用斜杠( \)将一行的语句分为多行显示
- 字符串:可以使用引号( ’ )、双引号( ” )、三引号( ”’ 或 “”” ) 来表示字符串
- 注释 : 单行注释采用 # 开头,多行注释使用三个单引号(”’)或三个双引号(“”“)
- 空行 : 函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。记住:空行也是程序代码的一部分。
多个语句构成代码组:
缩进相同的一组语句构成一个代码块,我们称之代码组。 像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。 我们将首行及后面的代码组称为一个子句(clause)。
if expression :
suite
elif expression :
suite
else :
suite 变量
变量赋值简单粗暴不需要声明类型, 灵活多变,非常好用。 Python中有5个标准的数据类型:Numbers(数字),String(字符串),List(列表),Tuple(元组),Dictionary(字典). 数字数据类是不可改变的数据类型,改变数字数据类型会分配一个新的对象。 数字型包括,长整型,浮点型,复数型。
字符串的操作有基本的功能不需要再自己进行拼接遍历的操作。
列表用 “[ ]” 标识类似 C 语言中的数组。
元组用 “( )” 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
字典用 “{ }” 标识。字典由索引 key 和它对应的值 value 组成。
非数字型的共同点:都可以切片,链接(+),重复(*),取值(a[])等相关运算;
非数字型的不同点:元组不可以赋值,字典按照dict[k]=v的方式赋值。
#变量赋值
var1 = 1
var2 = 10 # 赋值整型变量
del var1, var2 #使用del语句删除单个或多个对象的引用
miles = 1000.0 # 浮点型
str = 'Hello World!'
print str[2:5] # 输出字符串中第三个至第五个之间的字符串
list = [ 'runoob', 786 , 2.23, 'john', 70.2 ]
print list[1:3] # 输出第二个至第三个的元素
tuple = ( 'runoob', 786 , 2.23, 'john', 70.2 )
print tuple[1:3] # 输出第二个至第三个的元素
tinydict = {'name': 'john','code':6734, 'dept': 'sales'}
print tinydict.keys() # 输出所有键
print tinydict.values() # 输出所有值运算符
- 算术运算: +(加 - 两个对象相加) ,-(减 - 得到负数或是一个数减去另一个数),(乘 - 两个数相乘或是返回一个被重复若干次的字符串), /(除 - x除以y) ,%(取模 - 返回除法的余数), *(幂 - 返回x的y次幂),//(取整除 - 返回商的整数部分)
- 比较运算: 等于,不等于(!= <>),大于,小于,大于等于,小于等于
- 赋值运算符: =, +=, -=, =, /=,%=, *=, //=
- 位运算: & | ~ ^ << >>
- 逻辑运算: and or not
- 成员运算符: in(如果在指定的序列中找到值返回 True,否则返回 False), not in
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a = 10
b = 20
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print "1 - 变量 a 在给定的列表中 list 中"
else:
print "1 - 变量 a 不在给定的列表中 list 中"
if ( b not in list ):
print "2 - 变量 b 不在给定的列表中 list 中"
else:
print "2 - 变量 b 在给定的列表中 list 中"
# 修改变量 a 的值
a = 2
if ( a in list ):
print "3 - 变量 a 在给定的列表中 list 中"
else:
print "3 - 变量 a 不在给定的列表中 list 中"- 身份运算符: is(is 是判断两个标识符是不是引用自一个对象), not is
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a = 20
b = 20
if ( a is b ):
print "1 - a 和 b 有相同的标识"
else:
print "1 - a 和 b 没有相同的标识"
if ( a is not b ):
print "2 - a 和 b 没有相同的标识"
else:
print "2 - a 和 b 有相同的标识"
# 修改变量 b 的值
b = 30
if ( a is b ):
print "3 - a 和 b 有相同的标识"
else:
print "3 - a 和 b 没有相同的标识"
if ( a is not b ):
print "4 - a 和 b 没有相同的标识"
else:
print "4 - a 和 b 有相同的标识"条件、循环和其他语句
条件
  Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。

Python 编程中 if 语句用于控制程序的执行,基本形式为:
if 判断条件:
执行语句……
else:
执行语句……  当判断条件为多个值时,可以使用以下形式:
if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4……  由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。
#!/usr/bin/python
num = 9
if num >= 0 and num <= 10: # 判断值是否在0~10之间
print 'hello'
# 输出结果: hello
num = 10
if num < 0 or num > 10: # 判断值是否在小于0或大于10
print 'hello'
else:
print 'undefine'
# 输出结果: undefine
num = 8
# 判断值是否在0~5或者10~15之间
if (num >= 0 and num <= 5) or (num >= 10 and num <= 15):
print 'hello'
else:
print 'undefine'
# 输出结果: undefine循环
Python提供了for循环和while循环(在Python中没有do..while循环)

while循环语句
while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务。其基本形式为:
while 判断条件:
执行语句……while 语句时还有另外两个重要的命令 continue,break 来跳过循环,continue 用于跳过该次循环,break 则是用于退出循环。
在 python 中,while … else 在循环条件为 false 时执行 else 语句块:
#!/usr/bin/python
count = 0
while count < 5:
print count, " is less than 5"
count = count + 1
else:
print count, " is not less than 5"附加:猜拳小游戏
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import random
while 1:
s = int(random.randint(1, 3))
if s == 1:
ind = "石头"
elif s == 2:
ind = "剪子"
elif s == 3:
ind = "布"
m = raw_input('输入 石头、剪子、布,输入"end"结束游戏:')
blist = ['石头', "剪子", "布"]
if (m not in blist) and (m != 'end'):
print "输入错误,请重新输入!"
elif (m not in blist) and (m == 'end'):
print "\n游戏退出中..."
break
elif m == ind :
print "电脑出了: " + ind + ",平局!"
elif (m == '石头' and ind =='剪子') or (m == '剪子' and ind =='布') or (m == '布' and ind =='石头'):
print "电脑出了: " + ind +",你赢了!"
elif (m == '石头' and ind =='布') or (m == '剪子' and ind =='石头') or (m == '布' and ind =='剪子'):
print "电脑出了: " + ind +",你输了!"for循环语句
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
for循环的语法格式如下:
for iterating_var in sequence:
statements(s)实例:
for letter in 'Python': # 第一个实例
print '当前字母 :', letter在 python 中,for … else 表示这样的意思,for 中的语句和普通的没有区别,else 中的语句会在循环正常执行完(即 for 不是通过 break 跳出而中断的)的情况下执行,while … else 也是一样。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
for num in range(10,20): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
print '%d 等于 %d * %d' % (num,i,j)
break # 跳出当前循环
else: # 循环的 else 部分
print num, '是一个质数'其他语句
break
Python break语句,就像在C语言中,打破了最小封闭for或while循环.
break语句用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
break语句用在while和for循环中。

continue
continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
continue语句用在while和for循环中。

例子:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
for letter in 'Python': # 第一个实例
if letter == 'h':
continue
print '当前字母 :', letter- pass
Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
当你在编写一个程序时,执行语句部分思路还没有完成,这时你可以用pass语句来占位,也可以当做是一个标记,是要过后来完成的代码。
for letter in 'Python':
if letter == 'h': #当循环到h时,没有想好干啥,可以先用pass占着位置
pass
print '当前字母 :', letter
print "Good bye!"Python Number(数字)
Number数据类型用于存储数值.
数据类型是不允许改变的,这就意味着如果改变 Number 数据类型的值,将重新分配内存空间。
注:
1. 可变数据类型:列表list和字典dict;
不可变数据类型:整型int、浮点型float、字符串型string和元组tuple。
>>> x = 1
>>> id(x)
31106520
>>> y = 1
>>> id(y)
31106520
>>> x = 2
>>> id(x)
31106508
>>> y = 2
>>> id(y)
31106508
>>> z = y
>>> id(z)
31106508 上面这段程序都是对不可变数据类型中的int类型的操作,id()查看的是当前变量的地址值。
我们先来看x = 1和y = 1两个操作的结果,从上面的输出可以看到x和y在此时的地址值是一样的,也就是说x和y其实是引用了同一个对象,即1,也就是说内存中对于1只占用了一个地址,而不管有多少个引用指向了它,都只有一个地址值,只是有一个引用计数会记录指向这个地址的引用到底有几个而已。
  为什么称之为不可变数据类型呢?
  这里的不可变大家可以理解为x引用的地址处的值是不能被改变的,也就是31106520地址处的值在没被垃圾回收之前一直都是1,不能改变,如果要把x赋值为2,那么只能将x引用的地址从31106520变为31106508,相当于x = 2这个赋值又创建了一个对象,即2这个对象,然后x、y、z都引用了这个对象,所以int这个数据类型是不可变的,如果想对int类型的变量再次赋值,在内存中相当于又创建了一个新的对象,而不再是之前的对象。从下图中就可以看到上面程序的过程。
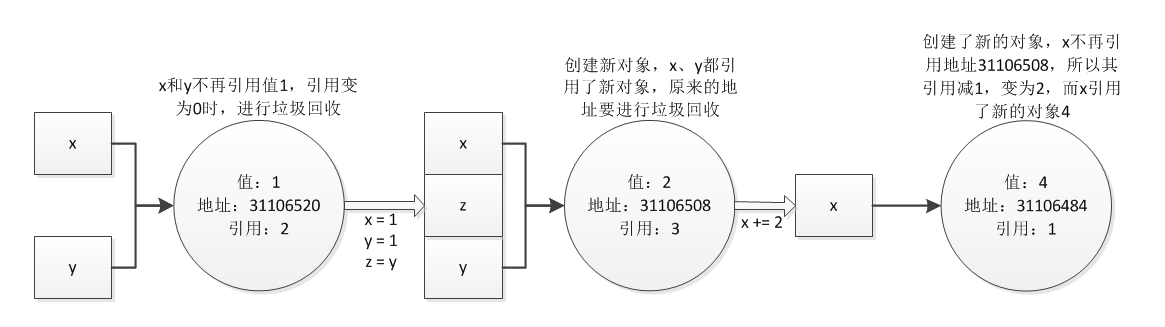
  不可变数据类型的优点就是内存中不管有多少个引用,相同的对象只占用了一块内存;
但是缺点就是当需要对变量进行运算从而改变变量引用的对象的值时,由于是不可变的数据类型,所以必须创建新的对象,这样就会使得一次次的改变创建了一个个新的对象,不过不再使用的内存会被垃圾回收器回收。
- 可变数据类型:
>>> a = [1, 2, 3]
>>> id(a)
41568816
>>> a = [1, 2, 3]
>>> id(a)
41575088
>>> a.append(4)
>>> id(a)
41575088
>>> a += [2]
>>> id(a)
41575088
>>> a
[1, 2, 3, 4, 2]   从上面程序中可看出,对a = [1, 2, 3]两次操作a引用的地址值是不同的,也就是说其实创建了两个不同的对象,这明显不同于不可变数据类型,所以对于可变数据类型来说,具有同样值的对象是不同的对象,即在内存中保存了多个同样值的对象,地址值不同。再看后面的操作,对列表进行添加操作,分别a.append(4)和a += [2],发现这两个操作使得a引用的对象值变成了上面的最终结果,但是a引用的地址依旧是41575088,也就是说对a进行的操作不会改变a引用的地址值,只是在地址后面又扩充了新的地址,改变了地址里面存放的值,所以可变数据类型的意思就是说对一个变量进行操作时,其值是可变的,值的变化并不会引起新建对象,即地址是不会变的,只是地址中的内容变化了或者地址得到了扩充。下图对这一过程进行了图示,可以很清晰地看到这一过程。
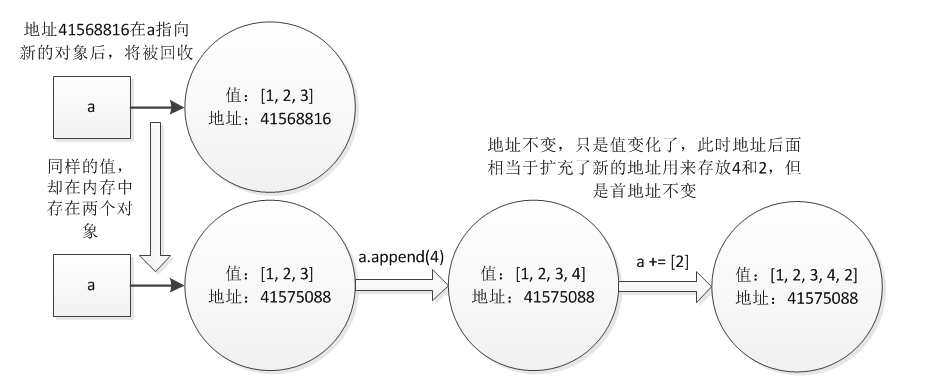
变量赋值时Number对象被创建:
var1 = 10; #创建对象10,并引用对象10,指向var1
var2 = 1 ;
#
#del语句删除一些Number对象引用
#del var1 [, var2, [....,varN]]
#
del var1
del var1, var2- 数值类型包括: Int, long integers, float point real values, complex numbers。
Number类型转换:
int(x [,base ]) 将x转换为一个整数
long(x [,base ]) 将x转换为一个长整数
float(x ) 将x转换到一个浮点数
complex(real [,imag ]) 创建一个复数
str(x ) 将对象 x 转换为字符串
repr(x ) 将对象 x 转换为表达式字符串
eval(str ) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s ) 将序列 s 转换为一个元组
list(s ) 将序列 s 转换为一个列表
chr(x ) 将一个整数转换为一个字符
unichr(x ) 将一个整数转换为Unicode字符
ord(x ) 将一个字符转换为它的整数值
hex(x ) 将一个整数转换为一个十六进制字符串
oct(x ) 将一个整数转换为一个八进制字符串
- 数学函数
abs(x) 返回数字的绝对值,如abs(-10) 返回 10
ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5
cmp(x, y) 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1
exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045
fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0
floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4
log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0
log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0
max(x1, x2,...) 返回给定参数的最大值,参数可以为序列。
min(x1, x2,...) 返回给定参数的最小值,参数可以为序列。
modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
pow(x, y) x**y 运算后的值。
round(x [,n]) 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。
sqrt(x) 返回数字x的平方根
- 随机函数:随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
choice(seq) 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。
randrange ([start,] stop [,step]) 从指定范围内,按指定基数递增的集合中获取一个随机数,基数缺省值为1
random() 随机生成下一个实数,它在[0,1)范围内。
seed([x]) 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。
shuffle(lst) 将序列的所有元素随机排序
uniform(x, y) 随机生成下一个实数,它在[x,y]范围内。
字符串
  字符串使用引号来创建,只要为变量分配一个值即可。
str = "hello Python!"; #创建字符串类型对象
str2 = "Python runoob"- 字符串访问方法
Python中不支持单字符类型,单字符也是作为字符串处理。访问子字符串使用方括号来截取字符串。如:
str1 = 'hello world!'
print "str[0]:",str1[0]
print "str1[1:5]", str[1:5]- 字符串更新
可以对已存在字符串进行修改,并进行赋值给另外一个变量,如:
var1 = "hello Python!"
print "update string:-", str[:6]+ "world!"- 字符串运算符
实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a + b 'HelloPython' |
| * | 重复输出字符串 | >>>a * 2'HelloHello' |
| [] | 通过索引获取字符串中字符 | >>>a[1]'e' |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4]'ell' |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>"H" in aTrue |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>"M" not in aTrue |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母”r”(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r'\n'\n |
- 字符串格式化
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
- 字符串复制
python中三引号可以将复杂的字符串进行复制:
python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
三引号的语法是一对连续的单引号或者双引号(通常都是成对的用)。
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
>>> hi = '''hi
there'''
>>> hi # repr()
'hi\nthere'
>>> print hi # str()
hi
there - 字符串内建函数
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
方法 描述 string.capitalize() 把字符串的第一个字符大写 string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 string.count(str, beg=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 string.decode(encoding=’UTF-8’, errors=’strict’) 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除 非 errors 指 定 的 是 ‘ignore’ 或 者’replace’ string.encode(encoding=’UTF-8’, errors=’strict’) 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ string.endswith(obj, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False string.expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 string.format() 格式化字符串 string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常. string.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False string.isdigit() 如果 string 只包含数字则返回 True 否则返回 False. string.islower() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 string.lstrip() 截掉 string 左边的空格 string.lower() 转换 string 中所有大写字符为小写. string.replace(str1, str2, num=string.count(str1)) 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. string.title() 返回”标题化”的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) string.upper() 转换 string 中的小写字母为大写
列表(List)
现在引入一个新的概念:数据结构.数据结构是通过某种方式(例如对元素进行编号)组织在一起的数据元素的集合,这些数据元素可以是数字或者字符,甚至可以其他的数据结构。
  Python中最基本的数据结构就是序列(sequence).序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
Python有6中内建的序列,最常见就是列表和元组;其他的序列是字符串、Unicode字符串、Buffer对象和xrange对象。
序列
- 序列都可进行的操作包括索引,切片,加,乘,检查成员。
- Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可
下面我们通过代码来看list相关知识。
#!/usr/bin/python
#创建列表
list01 = ['runoob', 786, 2.23, 'john', 70.2]; #列表中元素可以不同数据类型
list02 = [123, 'john']
# 列表截取
print list01[0];#使用下标索引访问列表中的值
print list01[-1];#-1代表倒数第一个
print list01[0:3]
print list01[1:]; #从第二个元素开始截取列表
#列表更新
#列表的数据项进行修改或更新,你也可以使用append()方法来添加列表项
list01[1] = 876; #list01中的第二个元素即是元素1 "786"换成"876 "
list01.append("Python")
#删除列表元素
#使用 del 语句来删除列表的的元素
del list01[-1]
#列表脚本操作符
# +号用于组合列表,*号用于重复列表
print list01 * 2
print list01+list02- 列表函数&方法
| 函数 | 功能 |
|---|---|
| cmp(list1,list2) | 比较两个列表的元素 |
| len(list) | 列表元素个数 |
| max(list) | 返回列表元素最大值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将元组转换成列表 |
| 方法 | 功能 |
|---|---|
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop(obj=list[-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort([func]) | 对原列表进行排序 |
元组
Python中元组和列表类似,不同之处在于元组的元素不能修改。
元组的创建使用小括号,并且使用逗号隔开。
#元组创建,使用小括号
tup1 = (); #创建一个空元组
tup2 = ('runoob', 786, 2.23, 'john', 70.2);
tup3 = (1,2,3,4,5,6,7,8);
#访问元组
print tup2[0]
print tup3[2:4]; #输出(3,4)
#修改元组
#元组中的元素值是不允许修改的,但是我们可以对元组进行连接组合
tup4 = tup2 + tup3; #创建新的元组
#删除元组
del tup1;
#元组运算符
# +号用于组合元组,*用于元组的复制
print tup3 * 2
#元组索引,截取
#元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素
tup4[3:]; #截取从第四个元素开始的元素| 函数 | 功能 |
|---|---|
| cmp(tuple1,tuple2) | 比较两个元组的元素 |
| len(tuple) | 元组元素个数 |
| max(tuple) | 返回元组元素最大值 |
| min(tuple) | 返回元组元素最小值 |
| tuple(seq) | 将列表转换成元组 |















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









