







说明:Hadoop集群已经搭建完毕,集群上使用的Hadoop-2.5.0。
目的:在window10系统上利用Eclipse配置Hadoop开发环境,编写MapReduce关联Hadoop集群。
准备:JDK环境变量配置、Eclipse、hadoop-2.7.5.tar、hadoop-eclipse-plugin-2.7.3.jar、hadoop-common-2.7.3-bin-master.jar(hadoop-2.7.3的Hadoop不好找了,插件使用的2.7.3版本,如要版本统一可自行下载)
Hadoop-2.7.5下载地址:http://mirrors.shu.edu.cn/apache/hadoop/common/
hadoop-eclipse-plugin-2.7.3.jar下载地址:http://download.csdn.net/download/u010185220/10211976
hadoop-common-2.7.3-bin-master.jar下载地址:http://download.csdn.net/download/u010185220/10212069
一、环境搭建
第一步:JDK环境变量配置、Eclipse安装,略;
第二步:Hadoop环境配置
把下载好的Hadoop版本解压的本地一目录,本人使用的是Hadoop-2.7.5。添加系统环境变量:新建变量名HADOOP_HOME,值为Hadoop的解压路径,如D:\hadoop-2.7.5。添加到path中:%HADOOP_HOME%\bin。
第三步:把hadoop-eclipse-plugin-2.7.3.jar包复制到Eclipse目录下的pluguns目录中。重启Eclipse。打开Eclipse->Prefences。可以看到左侧多出了Hadoop Map/Reduce项。
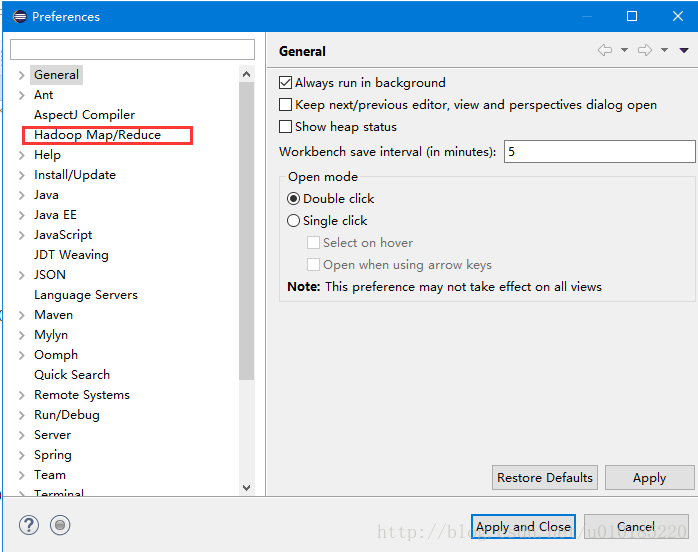
点击多出的Hadoop Map/Reduce项,添加Hadoop解压路径
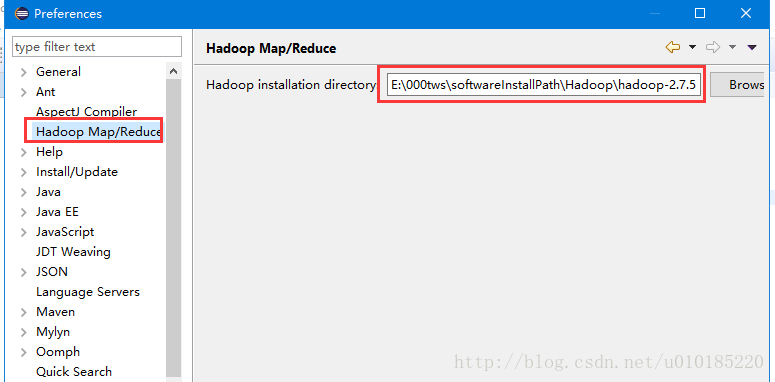
第四步:解压hadoop-common-2.7.3-bin-master.7z包,把解压得到的bin目录下的hadoop.dll、hadoop.exp、hadoop.lib、winutils.exe等所有文件复制到Hadoop-2.7.5的bin目录下。再把hadoop.dll复制到C:\Windows\System32目录下。
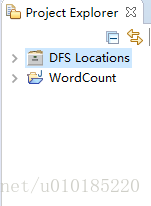
第五步:Eclipse中依次点击:Window->Open Perspective->Map/Reduce,项目结构中出现DFS Locations结构。
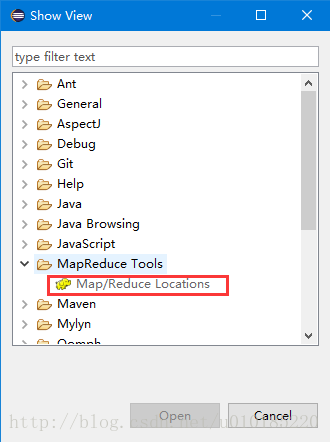
第六步:Eclipse中依次点击:Window->Show View ->Other->MapReduce Tools->Map/Reduce Locations。确定(open)
下面的控制台多出了Map/Reduce Locations试图。右键Map/Reduce Locations试图的空白处,选择新建,定义Hadoop集群的链接。Location name任起,Host填写Hadoop的mater的IP地址,port是对应的端口号,这个要与集群上core-site.xml文件中的参数一致,确保能连到集群,User name任起。
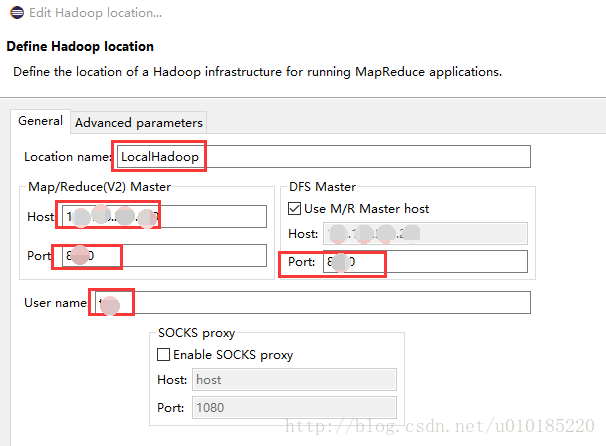
core-site.xml的位置根据自己的情况确定,我的在/etc/hadoop/2.5.0.0-1245/0/下,查看方式是:cat /etc/hadoop/2.5.0.0-1245/0/core-site.xml。
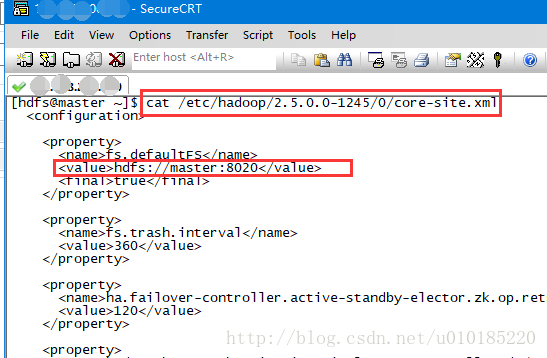
填写好以上参数后点击Finish。DFS Locations下出现定义的Hadoop连接信息。点开节点会看到集群上的文件信息。看不到这连接失败,检查上步IP地址及端口的配置是否有误。
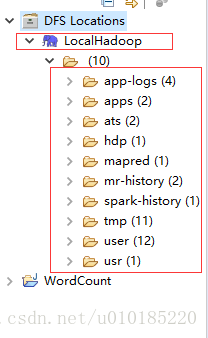
若有文件的话,点击其中的某节点中的文件确定能查看文件内容。
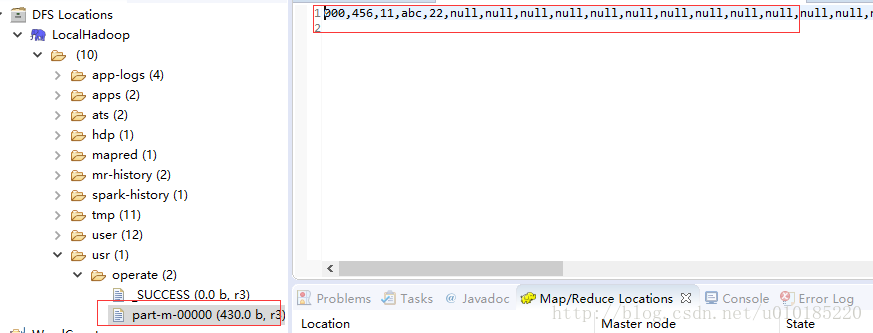
此时若不能查看文件内容,若提示是editor could not be initialized. org.eclipse.ui.workbench.texteditor类似的问题,则可能是C:\Windows\System32下的hadoop.dll版本和hadoop-2.7.5/bin下的hadoop.dll版本不一致的原因。
至此,window下Eclipse配置Hadoop开发环境搭建完毕。
二、WordCount示例
第一步、新建项目 :File->new->other->Map/Reduce Project
第二步、src下创建Package,Package下创建WordCount.java类
代码如下(可直接复制粘贴到你的WordCount类):
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
@SuppressWarnings("deprecation")
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
# Configure logging for testing:optionally with log file
#log4j.rootLogger=debug,appender
log4j.rootLogger=info,appender
#log4j.rootLogger=error,appender
#\u8F93\u51FA\u5230\u63A7\u5236\u53F0
log4j.appender.appender=org.apache.log4j.ConsoleAppender
#\u6837\u5F0F\u4E3ATTCCLayout
log4j.appender.appender.layout=org.apache.log4j.TTCCLayout
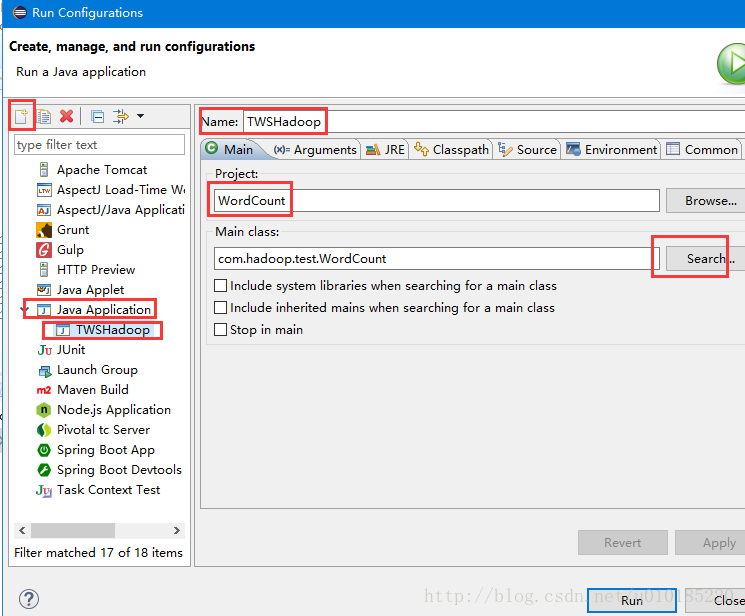
配置Argument标签参数。注意点在图上已经说明
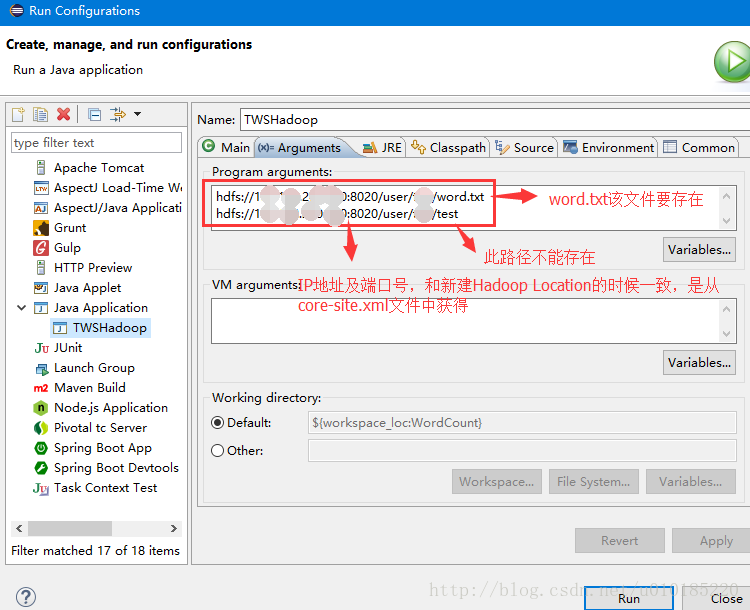
配置完成后点击Apply,Run。出现类似以下日志,成功。
[pool-6-thread-1] INFO org.apache.hadoop.mapred.Merger - Down to the last merge-pass, with 1 segments left of total size: 115 bytes
[pool-6-thread-1] INFO org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl - Merged 1 segments, 119 bytes to disk to satisfy reduce memory limit
[pool-6-thread-1] INFO org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl - Merging 1 files, 123 bytes from disk
[pool-6-thread-1] INFO org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl - Merging 0 segments, 0 bytes from memory into reduce
[pool-6-thread-1] INFO org.apache.hadoop.mapred.Merger - Merging 1 sorted segments
[pool-6-thread-1] INFO org.apache.hadoop.mapred.Merger - Down to the last merge-pass, with 1 segments left of total size: 115 bytes
[pool-6-thread-1] INFO org.apache.hadoop.mapred.LocalJobRunner - 1 / 1 copied.
[pool-6-thread-1] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
[pool-6-thread-1] INFO org.apache.hadoop.mapred.Task - Task:attempt_local1399589841_0001_r_000000_0 is done. And is in the process of committing
[pool-6-thread-1] INFO org.apache.hadoop.mapred.LocalJobRunner - 1 / 1 copied.
[pool-6-thread-1] INFO org.apache.hadoop.mapred.Task - Task attempt_local1399589841_0001_r_000000_0 is allowed to commit now
[pool-6-thread-1] INFO org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter - Saved output of task 'attempt_local1399589841_0001_r_000000_0' to hdfs://192.168.200.240:8020/user/tws/test/_temporary/0/task_local1399589841_0001_r_000000
[pool-6-thread-1] INFO org.apache.hadoop.mapred.LocalJobRunner - reduce > reduce
[pool-6-thread-1] INFO org.apache.hadoop.mapred.Task - Task 'attempt_local1399589841_0001_r_000000_0' done.
[pool-6-thread-1] INFO org.apache.hadoop.mapred.Task - Final Counters for attempt_local1399589841_0001_r_000000_0: Counters: 29
File System Counters
FILE: Number of bytes read=453
FILE: Number of bytes written=292149
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=81
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=9
Reduce shuffle bytes=123
Reduce input records=9
Reduce output records=9
Spilled Records=9
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=253231104
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
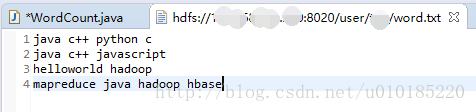
Bytes Written=81word.txt内容如下:
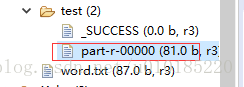
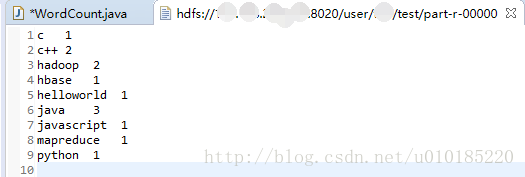
运行结果:

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









