







本文是用正向和逆向最大匹配算法进行中文分词的续篇,对上文分词的结果作一些分析。
一、结果分析:
1.程序运行结果,如下图所示:
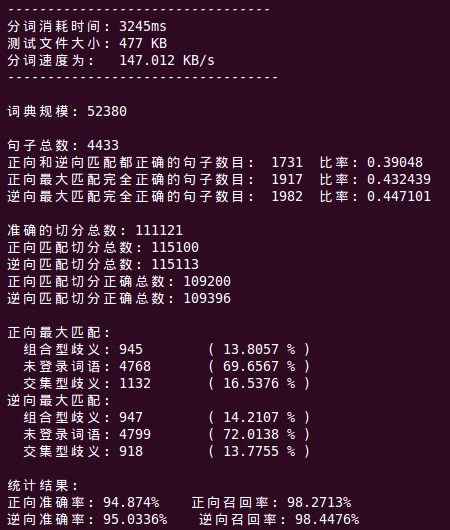
(1)正向和逆向匹配都正确的句子数目为 1731,占句子总数的39.0%
(2)正向最大匹配完全正确的句子数目为 1917,占句子总数的43.2%
(3)逆向最大匹配完全正确的句子数目为 1982,占句子总数的44.7%
(4)至少有一种方法分析正确的句子数为 2168,占句子总数的48.9%
3.逆向最大匹配比正向最大匹配的准确率和召回率都高。
4.错误分析
(1)未登录词导致的错误占大部分,约70%左右,是导致分词错误的主要因素。
(2)面对交集型歧义,正向最大匹配比逆向最大匹配更容易出错。
(3)面对组合型歧义,正向最大匹配和逆向最大匹配都无能为力。
二、主要问题分析:
1.准确率为什么低于召回率;
二者的计算公式如下:
准确率 = 切分正确的词 / 切分得到的词数
召回率 = 切分正确的词 / 准确的词数
从上述公式来看,他们的区别在于分母。通过对切分错误的汉字串的分析,发现未登录词在其中占了相当大的比例,大概四分之三左右。算法对于未登录词的处理方式是:将它们按照单字进行切分,这样势必导致切分出来的词的数量比真实值偏大。虽然也存在一些组合型歧义问题使切分出来的词的数量倾向于减少,但是这种情形较少,只占所有错误汉子串的十分之一左右。因此从总体上来看,实际切分得到的词的数目会比真实的词的数目要大,所以最终得到的准确率低于召回率。
2.逆向匹配的准确率和召回率为什么高于正向匹配?
逆向切分的错误较少。错误分三类:未登录词、组合型歧义、交集型歧义。其中未登录词对于两种切分方式来说是差不多的,组合型歧义也是相差无几。主要的区别在于交集型歧义问题,对于汉字串ABC,正向切分得到AB /C,逆向切分得到A/BC。在实际应用中,大多数的交集型歧义倾向于切分为A/BC这种形式。因此,正向匹配的错误数量相对来说较高。至于为什么汉语的交集型歧义倾向于切分为A/BC这种形式,那可能涉及到语言学的知识了。
3.错误分词的主要问题什么?主流的解决办法是什么?
从分词的结果来看,错误主要分为三类:
(1)组合型歧义,该切分而未切分的词。正向切分中大概占13.8%,逆向切分中大概占14.2%。
某些汉字串,它本身是词,切开来也是词,这就造成了组合型歧义。比如:比如“就是”,它本身是一个词,其中的“就”和“是”也都可以单独作为一个词。
组合型歧义同最大匹配的原则是相矛盾的。最大匹配法的实质是要求切分出来的词的数量尽可能地少,而组合型歧义切分问题的存在,却要求考虑将这样的词再切分一次的可能性。如果不利用句法以及更高层面上的知识,组合型歧义切分是很难解决的。要利用上下文的语境信息进行识别。
(2)交集型歧义。正向切分中大概占16.5%,逆向切分中大概占13.8%。
交集型歧义切分是指,一个汉字串中包含ABC三个子串,AB和BC都是词,到底应该切分为A/BC还是AB/C。按照最大匹配切分方式,正向切分得到AB /C,逆向切分得到A/BC。因此,对同一个汉字串同时进行正向切分和逆向切分,可以检查出一部分交集型歧义,但是未必能发现所有的交集型歧义。
解决交集型歧义,可以用统计学的手段计算出可能性最大的一种切分方式。可以利用最大概率法,基于支持向量机的方法,最大熵模型。
这两种歧义的区别为:交集型歧义的问题在于在哪里切分,组合型歧义的问题在于该不该切。
(3)未登录词。正向切分中大概占69.66%,逆向切分中大概占72.01%。
即词典中不存在的词。一些未登录词是比较生僻的、不常用的词,如糌粑。还有一些是专有名词、人名、地名等。
未登录词识别的基本方法主要采用的是:基于规则的方法和统计与规则相结合的方法。从目前的研究来看,多是对人名、地名、机构名等进行单独的识别研究。基于统计的方法是根据统计得到的各类用字的频度,加入构词可信度等概念进行识别。统计与规则相结合的方法是根据未登录词的用字规律和上下文特征,观察未登录词与标志位置的关系以及单词的左右结构,总结出适合绝大多数未登录词的识别规则,将规则应用于汉语文本的处理过程,从而识别未登录词。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









