







排序模型
推荐引擎模型架构
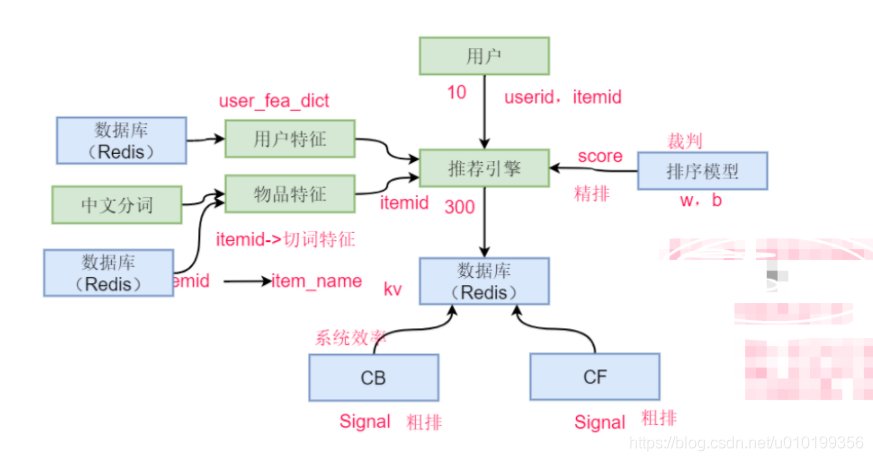
推荐系统实践:
(1)解析请求:userid,request_itemid
(2)加载模型:加载model.w model.b
(3)检索候选集合:分别利用cb和cf去redis里面检索数据库,得到item-> item item item推荐候选(300=200+100)
(4)获得用户特征:userid
(5)获得物品特征:itemid
(6)打分(sigmoid),排序
(7)top-n截断
(8)数据包装,itemid->name,返回(10)
解释
对指定用户进行推荐,这里我们必须明确两个重要的id,即userid和itemid。
1,推荐引擎获得userid和itemid,从数据库进行召回,形成推荐item列表,假如说这里召回300个item:score。
2,对于召回的item,我们通过基于内容和协同过滤的方式同时召回,而且这里召回的过程中有排序的过程,在这个阶段称之为粗排;但是此时两种不同方式召回的item可能存在重复,并且score不具有可比性;这个时候,就需要我们重新引入新的模型,按照统一的标准对召回的item重新打分、排序(这个阶段我们称之为精排),然后取数个item推荐给用户,假如这里取10个。
3,需要注意的是,当我们召回300个item之后,我们得到的是这些item的itemid和对应的score,那么我们应该如何根据模型进行打分呢?这里可以通过外部数据库通过userid和itemid来加载物品特征数据和用户特征数据。然后交给排序模型打分,从而得出最终的已经排序的推荐列表。
后续未完,待整理。。。。














 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









