







一、设计任务
1、把任务十中的文字字符转为国标码,计算共需要多少比特。
2、用你所学的方法(霍夫曼编码、游长编码或算数编码)压缩这些字符,得到的压缩码流共计多少比特。说明数据的冗余度在哪里。
3、手动编码也可以。最好编程实现压缩。
二、文字转国标码原理
1、汉字机内码、区位码、国标码简介
汉字的机内码是汉字在计算机汉字系统内部的表示方法,是计算机汉字系统的基础代码。
我国制定了“中华人民共和国国家标准信息交换汉字编码”,标准代号为GB2312—80,
这种编码又称为国标码。在国标码的字符集中共收录了一级汉字3755个,二级汉字3008
个,图形符号682个,三项字符总计7445个。
在国标GD2312—80中规定,所有的国标汉字及符号分配在一个94行、94列的方阵中,方阵的每一行称为一个“区”,编号为01区到94区;每一列称为一个“位”,编号为01位到94位,方阵中的每一个汉字和符号所在的区号和位号组合在一起形成的四个阿拉伯数字就是它们的“区位码”。区位码的前两位是它的区号,后两位是它的位号。用区位码就可以唯一地确定一个汉字或符号,反过来说,任何一个汉字或符号也都对应着一个唯一的区位码。如上所述,汉字区位码的区码和位码的取值均在1~94之间,如直接用区位码作为机内码 ,就会与基本ASCII码混淆。为了避免机内码与基本ASCII码的冲突,需要避开基本ASCII码中的控制码(00H~1FH),还需与基本ASCII码中的字符相区别。为了实现这两点,可以先在区码和位码分别加上20H,在此基础上再加80H(此处“H”表示前两位数字为十六进制数)。由于汉字的区码与位码的取值范围的十六进制数均为01H~5EH(即十进制的01~94), 所以汉字的高位字节与低位字节的取值范围则为A1H~FEH(即十进制的161~254)。
2、汉字机内码、区位码、国标码转换规则
区码 = 机内码高位字节 - 80H
位码 = 机内码低位字节 - 80H
国标码高字节 = 区码 + 20H
国标码低字节 = 位码 + 20H
3、汉字转换为国标码中的特殊处理
由于文本文件中含有数字、英文字母、空格等其它ASSIC码值小于等于160的英文字符,所以在将文本中中文字符转换为国标码时遇到的英文字符不应作处理,应直接存储起来,但这样会与其它中文字符转换后的国标码相混淆(因为汉字的国标码也小于160)。为此,在将文本内容转换为国标码的过程中,每遇到ASSIC码值小于等于160的英文字符时,则在该英文字符前插入一个ASSIC码值为0的空字符,作为原始文件中非汉字字符的标记,即此字符的ASSIC值非汉字转换后的国标码。
三、Huffman编码与解码原理
1、Huffman编码原理
霍夫曼(D.A.Huffman)于1952年提出一种编码方法,它完全依据字符出现概率来构造平均长度最短的异字码头,有时称之为最佳编码,一般叫做霍夫曼编码。
霍夫曼编码的基本思想是出现概率大的信源符号编写较短的码字,出现概率小的信源符号编写较长的码字,从而构造出平均长度最短的异字码头。
文本文件可以看做是由一串字节组成的字节流,因此可以把字节作为最基本的信源符号。文本文件也可以看做是由一串中文字符组成,因此也可以把中文字符作为最基本的信源符号。但以字节作为信源符号,比以中文字符作为信源符号具有如下优势:
1、 以字节作为信源符号编码,基本符号只有256种;以中文字符作为信源符号,基本符号高达上万种。因此以字节作为信源符号构造的Huffman树的节点数为256*2-1= 511个,远远小于以中文字符构造的Huffman树的节点个数,可以大大减少构造Huffman树和遍历Huffman树所需的时间。
2、 把中文字符映射为字节符号,不仅减少了信源符号个数,还使原本不想关的中文字
符之间建立了相关性,增大了数据之间的冗余性,因此可最大化的压缩数据。
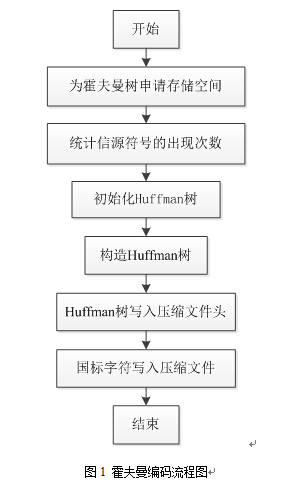
基于C++的霍夫曼编码的基本实现步骤如下:
1、 为霍夫曼树HT和单个信源符号的编码HC申请存储空间,HT= 512,HC = 256。
2、 统计信源符号的出现次数。
3、 初始化霍夫曼树HT的每个节点,前256个节点的权重为对应信源符号的出现次数,
其余节点权重为0。
4、按照信源符号出现概率构造Huffman树。
5、遍历Huffman树,遍历结果作为对应信源符号码字,存储在HC中。
5、将Huffman树写入压缩文件开始,作为Huffman解码的头文件。
6、读取转换后的国标文件,将相应字符的编码按位依次写入压缩文件。
霍夫曼编码软件流程图如图1。
2、Huffman解码原理
Huffman解码是将Huffman编码文件还原为原始文本文件,但在解码时必须知道原始信源符号的Huffman编码,因此在编码过程中,需要将信源符号的编码值或是Huffman树一起写到压缩文件中,如果将信源符号的编码值写入压缩文件,在解码时需要挨个扫描对比解码值,这样势必浪费解码时间。如果将Huffman树写入压缩文件,解码时只需还原Huffman树,到时遍历Huffman树即可,相对于前一种来说具有较大优势。因此,在这里将Huffman树写入文件的开始,作为文件的编码头。这样压缩文件主要由两部分组成,第一部分是Huffman编码头,存储Huffman树,在解码时用来还原Huffman树;第二部分是压缩数据,解码时还原原始数据。
Huffman编码头是压缩文件中的额外开销,因此应尽可能的小,Huffman树的节点只有511个,所以Huffman树的左节点、右节点、父节点可以选择short long型存储,而Huffman树的权重只能用int型存数,这样整个编码头需要(2+2+2+4)*511= 5100个字节。考虑到遍历Huffman树时不需要知道Huffman树的父节点和权重值,只需要知道左节点、右节点的值,这样的话Huffman编码头中可以只存储左节点和右节点,这样整个编码头需要(2+2)*511 = 1022个字节。
在解码时,首先从压缩文件读取编码头,还原Huffman树,然后从压缩文件逐字节读取编码,并逐位的扫描,遍历Huffman树,当节点值小于256时,说明已经扫描结束,准备输出该节点序号值。如果该节点序号值等于0,说明后面的一个解码值是英文字符,则该节点值不输出,且下一个解码值不做处理直接输出。如果解码出的节点序号值不等于0,说明该解码值和后面解码值是国标码,应把国标码还原为机内码输出。
基于C++的Huffman解码具体步骤如下:
1、 读取压缩文件编码头(Huffman树),还原Huffman树。
2、 按字节读取压缩文件,遍历Huffman树,直到遍历到叶子节点。
3、 判断叶子节点值是否为0。
4、 叶子节点值为0说明后面的一个解码值是英文字符,则该节点值不输出;继续扫描到下一个解码值,且不做处理直接写入解压文件。
5、 叶子节点值不为0说明该解码值和下一个解码值是中文字符的国标码,则将这两个
解码值还原为机内码,写入解压文件。
霍夫曼解码软件流程图如图2。
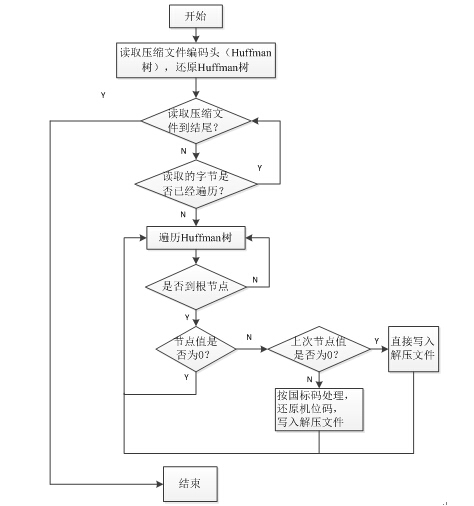
图2霍夫曼解码流程图
四、实验结果
经实际测试,本软件可以很好地完成课题的要求,软件除了可以压缩和解压课题中较少的文字外,也可以压缩和解压其他含有大量文字的文本文件,具有较好的适用性。但由于是基于对Huffman树遍历的算法,在压缩和解压文件时会消耗掉大量的时间,当文本较大时,甚至压缩和解压时间让人难以容忍。因此,如何使用新算法提高压缩和解压时间是本设计需要额外考虑的,而不是只局限于本课题的要求。
软件测试界面如图3。

图3 软件测试界面
由软件测试界面的列表框知道:
1、任务十中的文字转换为国标码后共有字节数为:214
2、Huffman压缩后得到的压缩码流共有字节数为:156
3、Huffman对此文本文档的压缩比为:1.371795
4、Huffman对此文本文档的编码效率为:0.995011
源文件内容如图4。

图4 源文件内容
解压文件内容如图5。

图5 解压文件内容
由图4和图5对比知道,此软件可以很好地将压缩文件还原为原始文件。
实验结果分析
由于此文本文档的信源符号是非等概率分布的,所以信源符号的平均编码长度大于信息熵,即存在压缩的可能性。由此可见,该文本信源符号的冗余度隐含在信源符号的非等概率分布之中,所以可以应用Huffman编码无损压缩此文件。
将中文字符映射为英文字符,减小了字符出现的区间范围,将本没有关系的中文字符中的一个字节映射为相同的ASSIC码值,这种映射关系使中文字符之间建立了联系,增大了数据之间的相关性,即数据间的冗余度变大了,因此可以大大提高压缩效率。且经试验验证,信源符号的平均编码长度接近信息熵。
C++源文件下载地址:http://download.csdn.net/detail/u010213393/6431963















 4049
4049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









