






工作流定义
工作流可以理解为一个DAG(有向无环图),工作流内部可以自由组织依赖关系并依次执行

工作流执行源码
代码附件
主进程:MasterSchedulerService.java
工作流执行线程:MasterExecThread.java
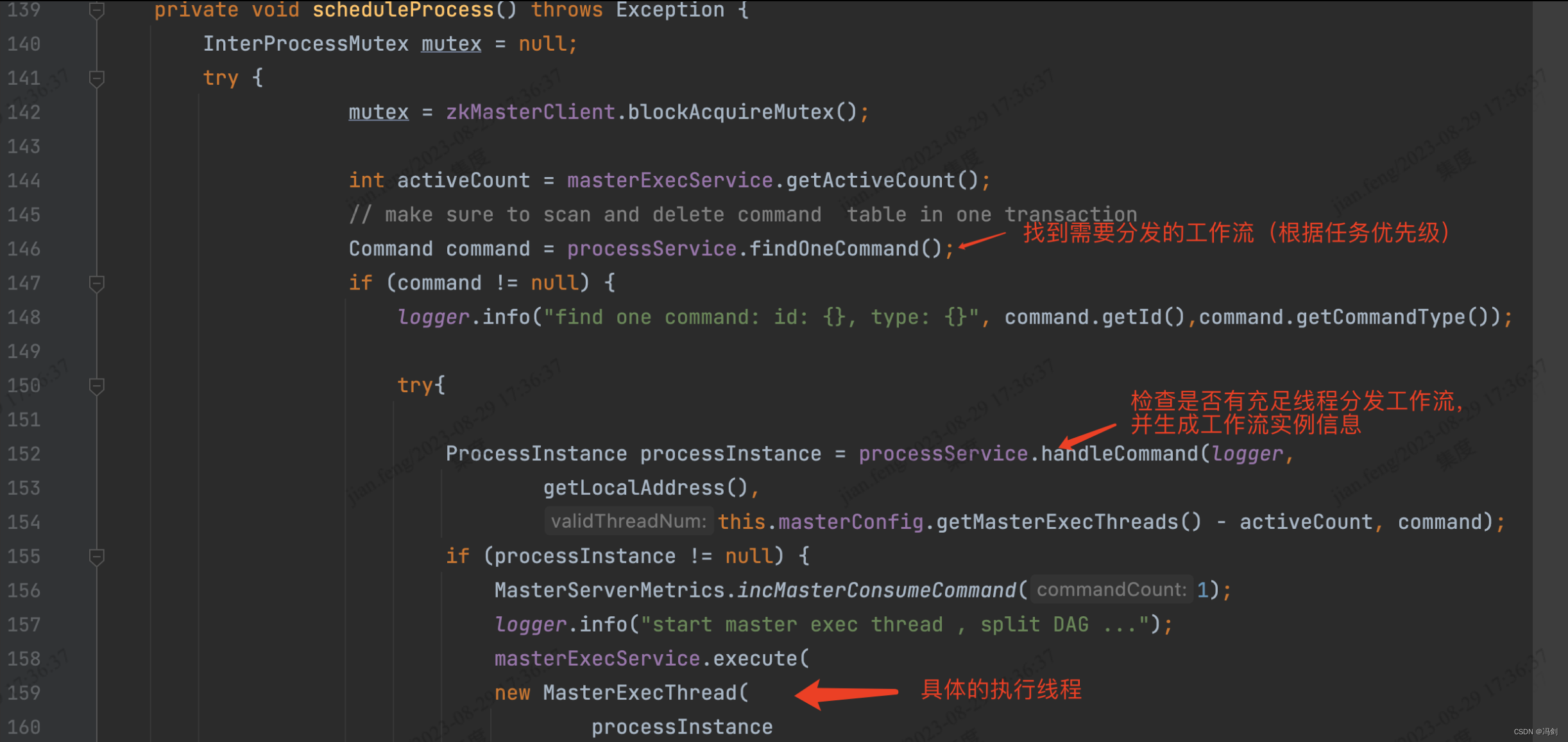
MasterSchedulerService.java 负责任务的分发
scheduleProcess()方法负责检查master是否有充足线程去分发,并且执行工作流

MasterExecThread.java 负责工作流执行和DAG组织
1.run()方法暂时只看executeProcess()

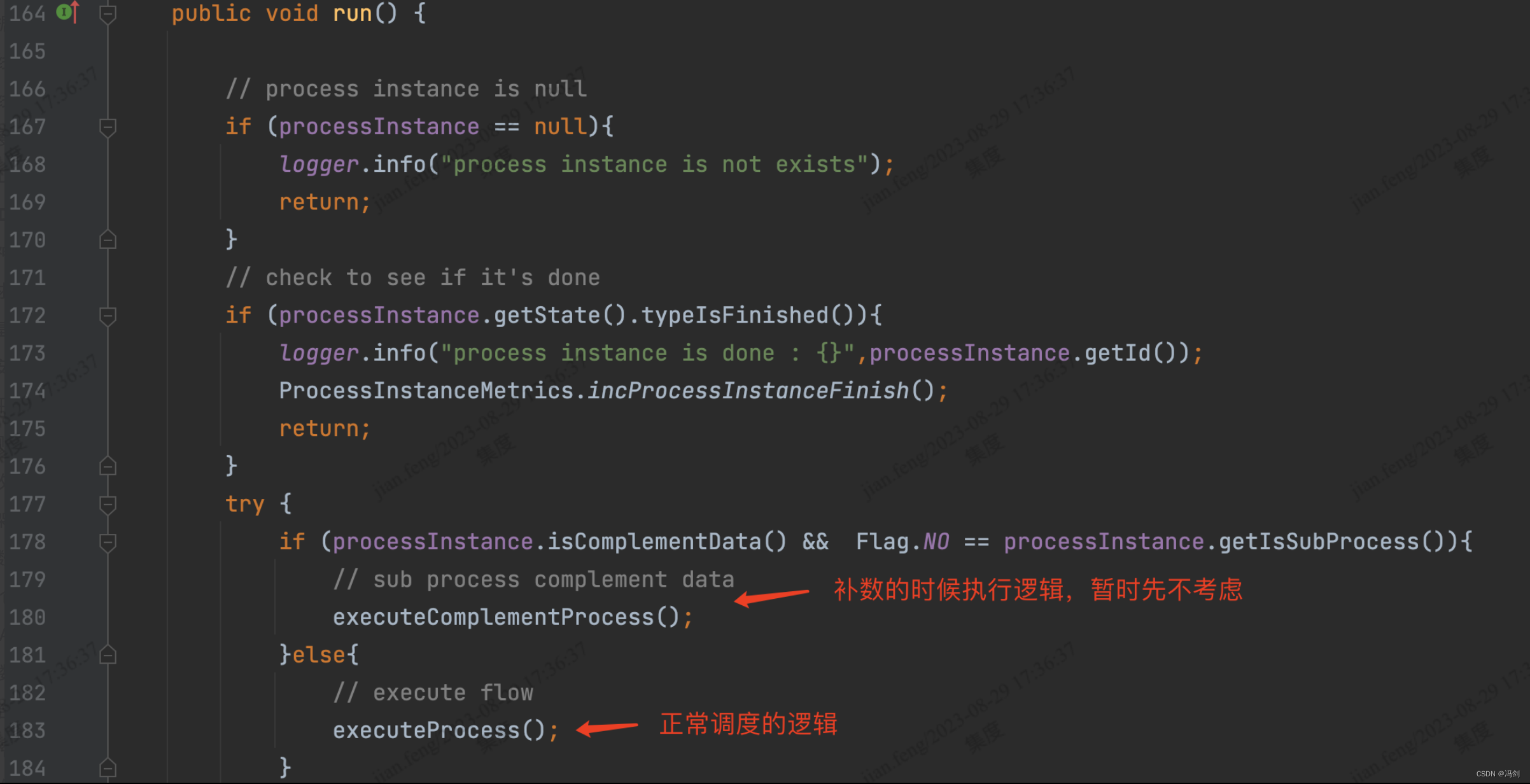 2.执行任务前的准备阶段
2.执行任务前的准备阶段


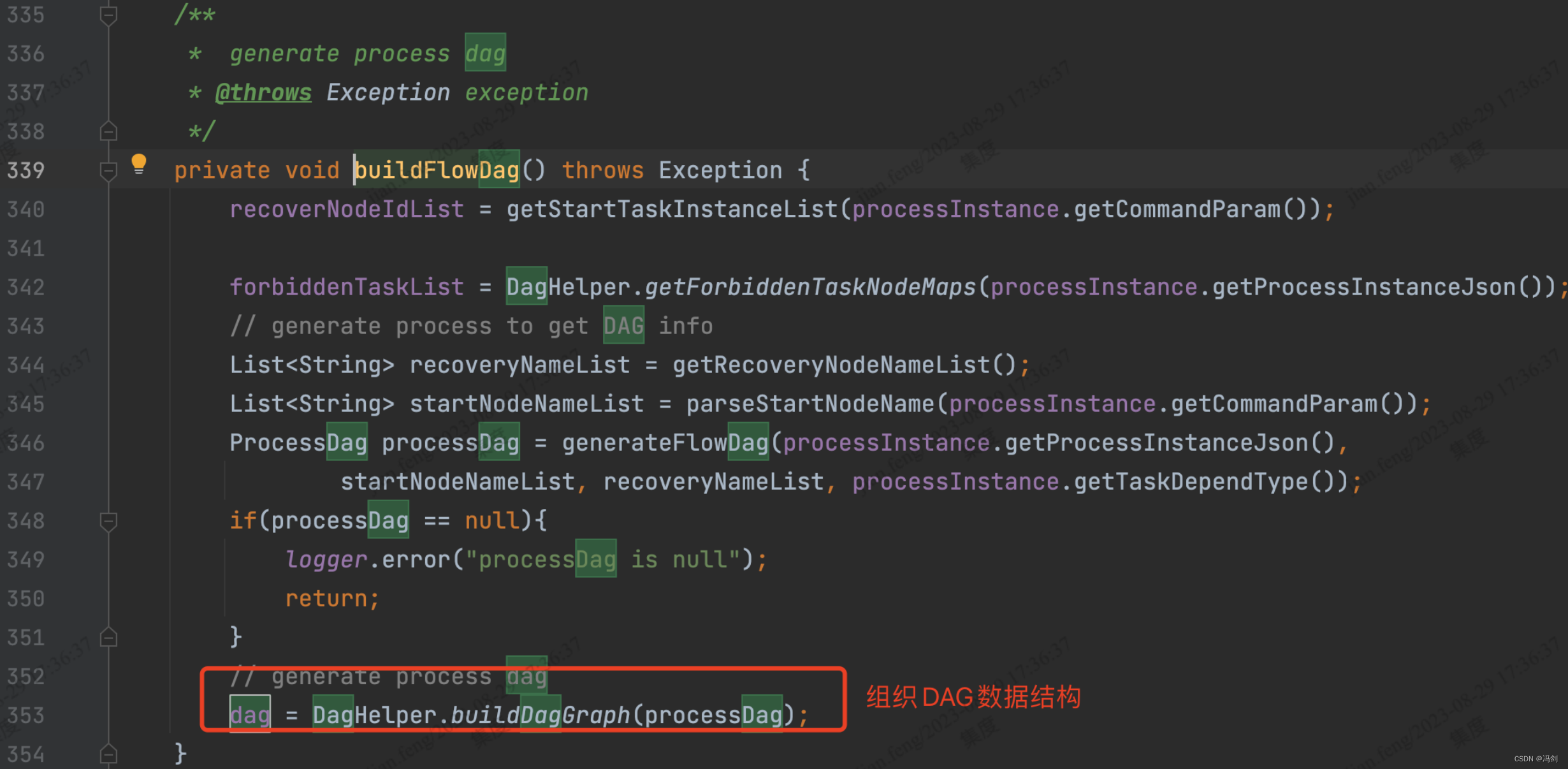
3.prepareProcess()中找到buildFlowDag方法


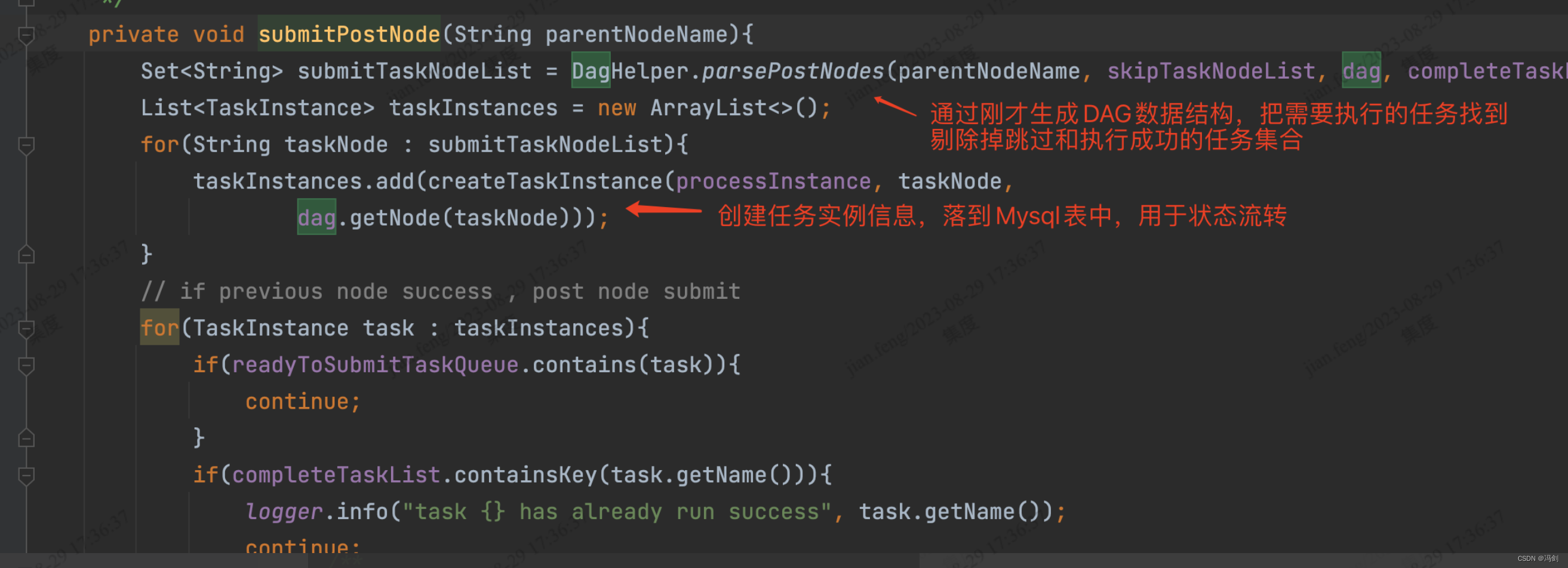
 4.runProcess()执行工作流内部任务节点
4.runProcess()执行工作流内部任务节点


5.submitPostNode通过DAG结构获取需要执行的任务节点(剔除掉跳过和成功的任务),并创建任务实例信息,并落地Mysql表用于状态流转

 工作流实例表与任务实例表存在一对多的情况,process_instance表的实例ID对应多个task_instance的实例ID
工作流实例表与任务实例表存在一对多的情况,process_instance表的实例ID对应多个task_instance的实例ID

6.任务队列依次执行


7.提交任务前会检测前置任务执行状态后,选择提交与否,并将队列中已完成的任务剔除掉,失败的加入失败列表等操作

总结:DS的功能真是非常实用,源代码结构逻辑清晰, 如果有小伙伴有想了解的源码解读,会再整理一次分享
















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









