









环境:
jdk1.7.0
Ubuntu 14.0.4
Hadoop 2.4.0
Hbase 0.98.3 for Hadoop2
“You need to run HBase on HDFS to ensure all writes are preserved.——Apache Hbase”
一开始就请登录root权限将可以省去很多麻烦。
1. 将下载的hbase压缩包解压,移到/usr/local路径下并添加软链:
tar xvf hbase-0.98.3-hadoop2
mv hbase-0.98.3-hadoop2 /usr/local
ln -s hbase-0.98.3-hadoop2 hbase
2. 打开conf/hbase-site.xml文件
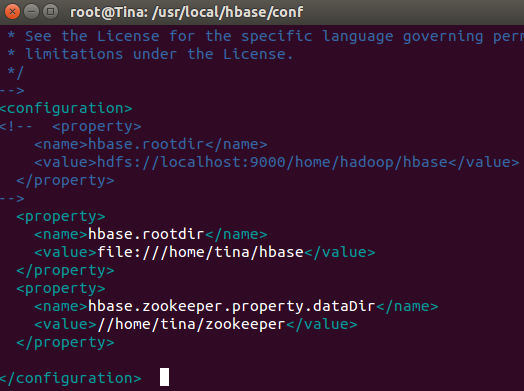
更改directory路径,默认的应该是在tmp文件夹下,Most operating systems clear /tmp on restart,所以最好换一个地方放。
3. 这里发现,hbase是需要zookeeper的。(HBase内置有ZooKeeper,也可以使用外部ZooKeeper。——百度百科)所以我又下载了一个zookeeper最新稳定版。
解压并移到/usr/local目录下且添加软链:
tar xvf zookeeper-3.4.6.tar.gz
mv zookeeper-3.4.6 /usr/local
ln -s zookeeper-3.4.6 zookeeper<strong>
</strong>“编写分布式应用是困难的,主要在于会出现Partial Failure。当一条消息在网络中两个节点之间传送时,如果出现网络错误,发送者无法知道接收者是否已经收到这条消息。接收者可能在出现网络错误之前就已经收到这条消息,也有可能没收到,又或接收者的进程已经死掉。发送者能够获得真实情况的唯一途径就是重新连接接收者,并向它发出询问。这就是部分失败:即我们甚至不知道一个操作是否已经失败。由于部分失败是分布式系统固有的特征,因此使用Zookeeper并不能根除部分失败,但它也不会隐藏部分失败。zookeeper可以提供一组工具,使你在构建分布式应用时能够对Partial Failure进行正确的处理。——Hadoop权威指南,Tom White”
4. 进入zookeeper的conf文件夹,新建一个名为zoo.cfg的文件
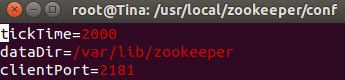
其中:
tickTime: the basic time unit in milliseconds used by ZooKeeper. It is used to do heartbeats and the minimum session timeout will be twice the tickTime.
dataDir: the location to store the in-memory database snapshots and, unless specified otherwise, the transaction log of updates to the database.
clientPort: the port to listen for client connections
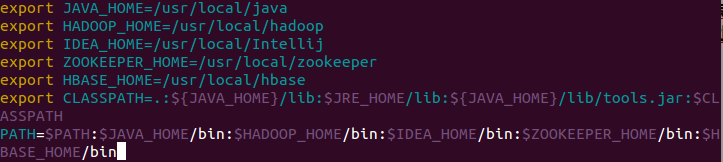
5. 根据个人习惯,修改环境变量(/etc/profile)
6. 可以启动zookeeper了
zkServer.sh start

可以使用口令ruok(are u ok?)检查zookeeper是否正在运行:
echo ruok | nc localhost 2181有回复,说明zookeeper已经启动。
7. 在第二步对Hbase的配置文件进行配置后,我们可以启动hbase了
start-hbase.sh
需要注意的是,因为我之前是刚安装的zookeeper所以它一直是启动着的。而hbase启动时又会去启动它,所以在启动hbase之前要把zookeeper先关掉不然会报错。
"HBase logs can be found in the logs subdirectory. Check them out especially if it seems HBase had trouble starting."
8. 单节点hbase就此配置完毕,我们可以启动hbase的shell
hbase shellCreate a table named test with a single column family named cf
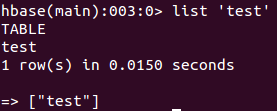
查看表test

给test表放入值:
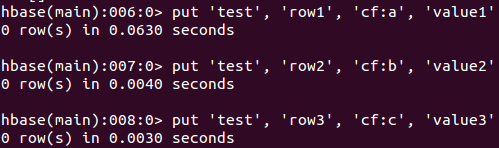
Verify the data insert by running a scan of the table as follows

从表中取值:

删除表(disable和drop同时)
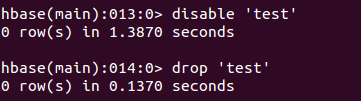
再exit命令退出命令行模式。
9. 退出hbase:
stop-hbase.sh=============================================================================================================================
今天主要试水了zookeeper和hbase。zookeeper顾名思义,主要用于管理分布式系统的各个节点,因为分布式编程相比单节点编程有更多的问题需要控制和管理。hbase可以单独作为一个数据库来使用,此时它是基于本地文件系统的(比如今天的尝试)。
但更多时候我们是让hbase写入hadoop的分布式文件系统即hdfs。这个我将在之后继续尝试探讨。另外,hbase本身的表格存储模式也值得继续研究。















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









